本文共 1933 字,大约阅读时间需要 6 分钟。
1.什么是二分查找
数据的查找在计算机的操作中非常常见,那么我们应该怎样在计算机中实现查找操作呢?
最简单的一种方法:“傻找”,也就是一个一个的找,我们把数组中的每个元素都和我们想要查找的目标元素进行比对,看一下列表中是否有和这个元素相同的元素,如果我们想要寻找的那个目标元素在列表中出现了,那么就宣告查找成功,这种算法写成代码是这个样子的:
#假设我们想要在0-100之间来寻找某个元素item = int(input("请输入你想查找的元素: ")) #输入的元素默认格式为str类型,要先转成int类型item_index = 0 # 目标元素在数组中的位置temp = -1for i in range(100): if i == item: item_index = i + 1 temp = 1 break else: temp = -1if temp == 1: print("数组中有你想要找的元素,它的位置在:{}".format(item_index))else: print("数组中没有你想要找的元素!") 这就是简单查找,我们这里用的是一个有序列表,在实际情况中,我们更多碰到是无序列表(当然我们也可以先用排序算法先排好序,再进行查找),但无论有序还是无序的列表,这种算法的时间复杂度都为O(n),即我们每次寻找目标元素都要进行遍历(一个一个地找),当数据量非常庞大的时候,这种算法就会显得效率极低。
2.什么是二分查找
既然简单查找的效率非常低,那我们有没有更好的办法来进行查找操作呢?
当然是有的,那就是二分查找了。二分查找是一种比简单查找高效的多的查找方法,为什么这么讲呢?二分查找的实现逻辑是:当你想让我猜某个数字在不在列表中的时候,我每次都猜列表最中间的那个数字,然后用这个最中间的数字来和要猜数字进行比较,这样的好处就在于每次猜测都可以排除掉一半的元素,就像下图这样:
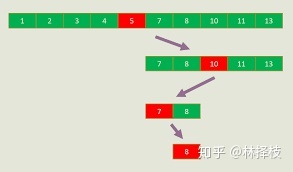
这样就极大的提升了效率,看一下代码:
def binary_search(list,item): low = 0 #数组的开头 high = len(list) - 1 #数组的结尾 while low <= high: mid = (low + high) // 2 guess = list[mid] if guess == item: return "列表中存在此元素" if guess > item: high = mid - 1 else: low = mid + 1 return "列表中没有此元素"nums = list(range(100))item = int(input("请输入想要查找的数字:"))print(binary_search(nums,item)) tips:这个代码中return的部分是为了方便理解,一般情况下是要return个True或者False的
这就是二分查找,二分查找的算法时间复杂度相比简单查找有了很大提升,时间复杂度为O(logn),这个算法时间复杂度相比于简答查找就快了很多,当数据量非常大的时候,就可以看出区别。100个元素时,简单查找就要进行100步操作,而二分查找就只要进行log10(100)次,即7次就可以找到那个元素,当数据量越大,二分查找算法就越有优势:
我们假设计算机每进行一步操作要花费一毫秒
简单查找 二分查找
100个元素 100毫秒 7毫秒
10000个元素 10秒 14毫秒
1000000000个元素 11天 30毫秒
3.为何二分查找如此强大
这里的关键就在于理解对数的概念,log 10 (100)就相当于在问,多少个10相乘等于100。我们都知道指数增长的非常快,而对数作为指数的逆运算,自然而然的会让数量级的下降速度变得非常快,这个下降速度就相当于指数的增长速度。
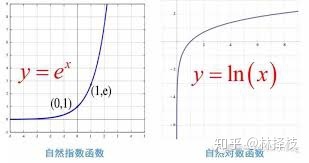
这也就是为什么二分查找如此高效的根本原因。由此也可以看出数学对于计算机的重要性,历史几乎所有的计算机科学家都首先是数学家,例如巴贝奇、图灵、冯-诺依曼这些计算机的底层原理构建者。
如果有人告诉你,你数学好对你的计算机学习会有一些帮助,那么这个人一定是在胡扯,因为计算机所有的底层原理都可以追溯到数学方法,算法从某种程度上也可以说是用计算机语言将数学方法实现出来了。数学没了计算机依然可以发展,而计算机没了数学就会不复存在。
转载地址:https://blog.csdn.net/weixin_34237125/article/details/113330515 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
