

 如果我们构建自定义REST-API作为机器学习模型的终点,则可以避免这些问题。特别是,本文将使用基于Python的Flask Web框架来为模型构建API,然后将这个flask应用程序整齐地集成到Docker映像中来进行部署。Docker显然适合解决这个问题,因为应用程序的所有依赖项都可以打包在容器中,并且可以通过必要时刻简单地部署更多容器来实现可伸缩性。这种部署架构本质上是可扩展的、成本有效的和便携的。
如果我们构建自定义REST-API作为机器学习模型的终点,则可以避免这些问题。特别是,本文将使用基于Python的Flask Web框架来为模型构建API,然后将这个flask应用程序整齐地集成到Docker映像中来进行部署。Docker显然适合解决这个问题,因为应用程序的所有依赖项都可以打包在容器中,并且可以通过必要时刻简单地部署更多容器来实现可伸缩性。这种部署架构本质上是可扩展的、成本有效的和便携的。 Docker:Docker是一种开源的容器化技术,允许开发人员将应用程序与依赖库打包在一起,并将其与底层操作系统隔离开来。与VM不同,docker不需要每个应用程序的Guest虚拟机操作系统,因此可以维护轻量级资源管理系统。与容器相比,虚拟机更重量级,因此容器可以相对快速地旋转,同时具有较低的内存占用,这有助于将来我们的应用程序和模型的可伸缩性。
Docker:Docker是一种开源的容器化技术,允许开发人员将应用程序与依赖库打包在一起,并将其与底层操作系统隔离开来。与VM不同,docker不需要每个应用程序的Guest虚拟机操作系统,因此可以维护轻量级资源管理系统。与容器相比,虚拟机更重量级,因此容器可以相对快速地旋转,同时具有较低的内存占用,这有助于将来我们的应用程序和模型的可伸缩性。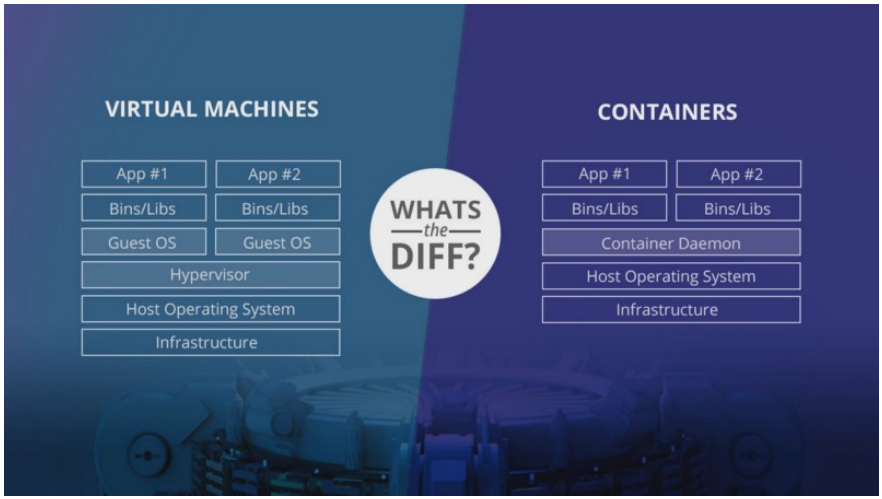 Jenkins:Jenkins可能是最受欢迎的持续集成和持续交付工具,大约拥有1400个插件,可自动构建和部署项目。Jenkins提供了一个在其管道中添加GitHub web-hook的规定,这样每次开发人员将更改推送到GitHub存储库时,它都会自动开始为修改后的模型运行验证测试,并构建docker镜像来进行部署。ngrok:ngrok是一个免费工具,可将公共URL传送到本地运行的应用程序它会生成一个可以在GitHub web-hook中用于触发推送事件的URL。Flask:Flask是一个用Python编写的开源Web框架,内置开发服务器和调试器。虽然有许多可以替代Web框架来创建REST API,但Flask的简单性备受青睐。部署 你可能想知道“我进入了什么样的环状土地?”但我保证接下来的步骤将变得简单实用。到目前为止,我们已经了解了部署体系结构中的不同组件以及每个组件的功能的简要说明。在本节中,将介绍部署模型的详细步骤。
Jenkins:Jenkins可能是最受欢迎的持续集成和持续交付工具,大约拥有1400个插件,可自动构建和部署项目。Jenkins提供了一个在其管道中添加GitHub web-hook的规定,这样每次开发人员将更改推送到GitHub存储库时,它都会自动开始为修改后的模型运行验证测试,并构建docker镜像来进行部署。ngrok:ngrok是一个免费工具,可将公共URL传送到本地运行的应用程序它会生成一个可以在GitHub web-hook中用于触发推送事件的URL。Flask:Flask是一个用Python编写的开源Web框架,内置开发服务器和调试器。虽然有许多可以替代Web框架来创建REST API,但Flask的简单性备受青睐。部署 你可能想知道“我进入了什么样的环状土地?”但我保证接下来的步骤将变得简单实用。到目前为止,我们已经了解了部署体系结构中的不同组件以及每个组件的功能的简要说明。在本节中,将介绍部署模型的详细步骤。 部署过程可以暂时分为四个部分:构建和保存模型、使用REST API公开模型,将模型打包在容器内以及配置持续集成工具。 在继续下一步之前,使用以下命令将GitHub存储库复制到本地计算机。 此存储库包含所有代码文件,可用作部署自定义模型的参考。
部署过程可以暂时分为四个部分:构建和保存模型、使用REST API公开模型,将模型打包在容器内以及配置持续集成工具。 在继续下一步之前,使用以下命令将GitHub存储库复制到本地计算机。 此存储库包含所有代码文件,可用作部署自定义模型的参考。 git clone git@github.com:EkramulHoque/docker-jenkins-flask-tutorial.git
注:虽然以上提到的步骤适用于Windows操作系统,但修改这些命令以在Mac或Unix系统上运行应该是很简单的。
训练和保存模型 在本例中,使用来自scikit-learn的鸢尾花数据集来构建我们的机器学习模型。在加载数据集后,提取用于模型训练的特征(x)和目标(y)。为了进行预测,先创建一个名为“labels”的字典,其中包含目标的标签名称,这里将决策树分类器用作模型。你可以在sklearn随意尝试其他分类器 ,通过调用模型上的方法来生成测试数据的预测标签。 我们使用pickle库将模型导出为pickle文件,并将模型保存在磁盘上。从文件加载模型后,我们将样本数据作为模型的输入并预测其目标变量。#!/usr/bin/env python# coding: utf-8import picklefrom sklearn import datasetsiris=datasets.load_iris()x=iris.datay=iris.target#labels for iris datasetlabels ={ 0: "setosa", 1: "versicolor", 2: "virginica"}#split the data setfrom sklearn.model_selection import train_test_splitx_train,x_test,y_train,y_test=train_test_split(x,y,test_size=.5)#Using decision tree algorithmfrom sklearn import treeclassifier=tree.DecisionTreeClassifier()classifier.fit(x_train,y_train)predictions=classifier.predict(x_test)#export the modelpickle.dump(classifier, open('model.pkl','wb'))#load the model and test with a custom inputmodel = pickle.load( open('model.pkl','rb'))x = [[6.7, 3.3, 5.7, 2.1]]predict = model.predict(x)print(labels[predict[0]]) 构建REST API:
Flask web框架帮助我们创建与模型通信所需的HTTP端点,我们使用pickle.load()方法从磁盘读取保存的模型。 Flask提供了一个route()装饰器,它告诉应用程序哪个URL应该调用相关的函数。它接受2个参数,即“rule”和“options”。 'rule'参数表示绑定到函数的URL,'options'是要转发到Rule对象的参数列表。 在示例中,'/ api'URL绑定到predict()函数。因此,当我们发出POST请求时,它会调用以JSON格式接收特征向量的函数。然后将“特征”向量传递到模型中,该模型对”特征”向量进行预测,然后以JSON格式返回标签。 请注意,Flask类的run()方法是在本地开发服务器上运行应用程序。在这里,将主机传递为'0.0.0.0',以便在docker容器中公开它。你可以在docker配置设置中查看更多相关信息。from flask import Flask, request, jsonifyimport jsonimport pickleimport pandas as pdimport numpy as npapp = Flask(__name__)# Load the modelmodel = pickle.load(open('model.pkl','rb'))labels ={ 0: "versicolor", 1: "setosa", 2: "virginica"}@app.route('/api',methods=['POST'])def predict(): # Get the data from the POST request. data = request.get_json(force=True) predict = model.predict(data['feature']) return jsonify(predict[0].tolist())if __name__ == '__main__':app.run(debug=True,host='0.0.0.0') 打包
为了允许Docker托管我们的API,我们需要指定一组允许Docker构建映像的指令。这组指令可以保存在Dockerfile中,该文件包含了可在命令行上调用来创建Docker镜像的所有命令。 现在开始创建Dockerfile,先打开文本编辑器并将其另存为“Dockerfile”,不带后缀或前缀。FROM ubuntu:16.04FROM python:3.6.5RUN apt-get update -y && \ apt-get install -y python-pip python-dev# We copy just the requirements.txt first to leverage Docker cacheCOPY ./requirements.txt /app/requirements.txtWORKDIR /appRUN pip install -r requirements.txtCOPY . /appCMD python /app/model.py && python /app/server.py
工作目录现包含以下文件:
•model.py用于训练和构建模型; •server.py来管理请求和服务器; •Dockerfile包含docker镜像的说明; •requirements.txt包含API所需的库;持续集成 到目前为止,我们已经创建了Flask API,完成了一个Dockerfile并将项目推送到git存储库中。作为先决条件,需要安装这3个应用程序--Docker,Ngrok和Jenkins。本节中的将演示之前在架构图中提到的整个过程。结论 在这篇博客中,我们深入研究了使用Docker,Flask和Jenkins部署机器学习模型的过程。 我们希望对你在生产中部署自己的机器学习模型时有所帮助。可以在此处找到本文中提供的代码的GitHub。 本文为云栖社区原创内容,未经允许不得转载。