6 聚合
聚合就是,通过处理数据得到一些计算结果。聚合操作可以分组,在Mongodb中聚合可以分为3中:聚合管道(aggregation pipeline),map-reduce,单一目的的聚合方法或者命令
6.1聚合介绍
和查询一样,都是查询collection的文档,不过聚合还要计算,通过计算得到结果
6.1.1聚合方式
6.1.1.1 聚合管道(aggregation pipeline)
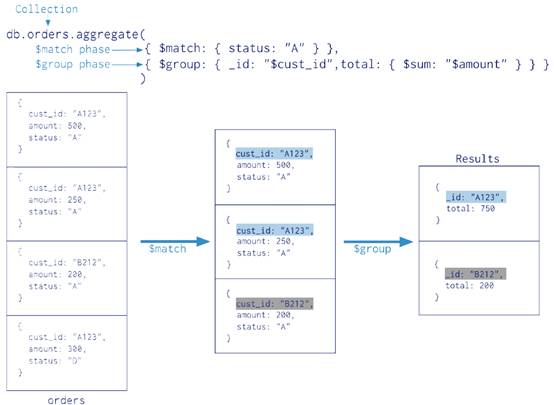
聚合管道,通过多个阶段的管道计算,来得到结果。最基本的就是过滤,和查询的过来一样。其他的管道,提供分组的工具,可以计算平均值,sum等。
6.1.1.2 map-reduce
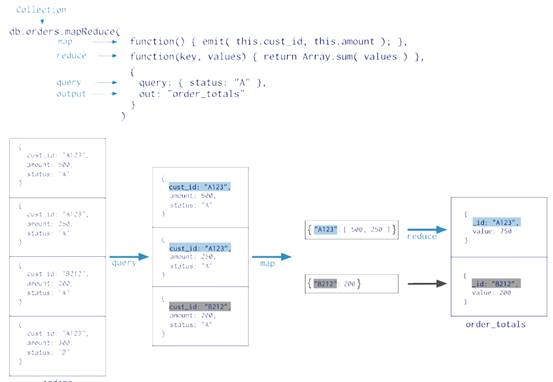
map-reduce分为2个阶段,map阶段,处理每个文档,通过emits发到下个阶段。reduce阶段,输出map阶段的输出组合。map-reduce可以通过finalize阶段处理最后的结果。map-reduce,也可以限制输入条件,也可以排序限制输出结果。
map-reduce的每个阶段都是由javascript脚本写成的函数。javascript提供的很好的灵活性,但是更加复杂和低效。
map-reduce,输出可以超过16MB
6.1.1.3单一目的的聚合操作
单一目的的聚合操作,比如返回行数,distinct等,都来至于同一个collection,但是和map-reduce和聚合管道而言,缺少了灵活性。

6.1.2其他的特性和能力
聚合管道和map-reduce可以在shard集群上使用,map-reduce还可以输出到集群中。
聚合管道,可以通过索引来提高性能。
6.2聚合概述
详细介绍聚合管道,map-reduce,单一目的的聚合操作之间的特性和限制。
6.2.1聚合管道
聚合管道是一个数据聚合模型框架的概念,数据处理管道,通过多个阶段,来计算出聚合结果。
很多情况下由于灵活性,map-reduce是首选但是复杂性很难让人接受。
6.2.1.1 管道
理论上,collection中的文档通过管道来转化计算数据。collection的文档一个一个的通过管道转化,但是并不是每个输入都会有输出。
6.2.1.2 管道表达式
每个管道都有表达式,表达式指定了数据要如何转化。管道只能操作当前文档。一般管道表达式没有当前状态,除了一些特殊的,比如求最大,最小值。
6.2.1.3聚合管道特性
聚合管道把一个collection的数据都丢到管道中转化,这些操作时可以被索引优化的。
管道操作和索引
$match,$sort,$limit,$skip这些操作时可以利用索引的,只要在管道的最开始出,比一下任何操作早就可以了,$project,$unwind,$group
2.4版本中,$geoNear也可以使用地理性的索引,但是必去出现在第一阶段。
简单过滤
若聚合只处理collection的子集,就可以使用一下操作过滤,$match,$limit,$skip,然后放到pipeline的开头可以使用合适的索引。
如果$match放在$sort的后面,那么只有$sort可以使用索引。
其他特性
聚合管道,mongodb提供了内部优化各个管道的顺序,提高执行的性能。
6.2.2 Map-Reduce
map-reduce是处理数据量的范例,在map阶段,应用每个数据,然后搞成k-v对分发出去,在reduce阶段,收集计算聚合数据,然后存放在collection中,最后还要通过finalize函数来输出。
map-reduce内的阶段都是js函数,所以可以在map阶段之前做任何的排序,限制操作。
6.2.2.1 Map-Reduce的Javascript函数
使用javascript在map中形成k-v对,然后在reduce中处理。在现实情况中,map可以又多个key,也可以没有key。
6.2.2.2 Map-Reduce的特性
mongodb中Map-Reduce的结果可以写入collection也可以直接输出。如果直接输出有BSON的大小限制,16MB,Map-Reduce也支持写入到shard的collection中。
6.2.3单一目的的聚合操作
只能用于指定功能。
6.2.3.1 Coutn
返回文档的数量可以是db.collection.count(),也可以是cursor.count()
6.2.3.2 Distinct
查看某个列的distinct值。
db.collection.distinct("cust_id")
6.2.3.3 Group
把查询结果作为输入,通过一些计算然后把结果以数组方式输出。
db.records.group( {
key: { a: 1 },
cond: { a: { $lt: 3 } },
reduce: function(cur, result) { result.count += cur.count },
initial: { count: 0 }
} )
6.2.4聚合机制
本节介绍,聚合管道的优化,聚合管道的限制,聚合管道和shard集群,map-reduce和shard集群,map-reduce并发
6.2.4.1聚合管道优化
聚合管道有个优化阶段,把所有的管道重新排列
管道顺序优化
$sort+$skip+$limit顺序优化:如果你的顺序是$sort,$skip,$limit,那么$limit会被提到$skip上面。如:
{ $sort: { age : -1 } },
{ $skip: 10 },
{ $limit: 5 }
优化后
{ $sort: { age : -1 } },
{ $limit: 15 }
{ $skip: 10 }
$limit+$skip+$limit+$skip顺序优化:一样还是会把limit放到skip上面,但是limit之间,skip之间会合并,如:
{ $limit: 100 },
{ $skip: 5 },
{ $limit: 10},
{ $skip: 2 }
第一步优化后会把limit放到上面
{ $limit: 100 },
{ $limit: 15},
{ $skip: 5 },
{ $skip: 2 }
第二步优化合并
{ $limit: 15 },
{ $skip: 7 }
porjection优化
如果$project里面指定的是include,MongoDB会把这个projection应用到pipeline的头上。
6.2.4.2聚合管道的限制
类型限制
聚合管道不允许操作一下数据类型:Symbol,MinKey,MaxKey,DBRef,Code,CodeWScope
结果大小限制
不能操作BSON结果大小16MB
内存限制
聚合使用内存超过内存的10%,过程会报错退出。
一般只有累计操作次才会出现,即要全部输入才会出结果的操作,内存超过5%就会开始告警,并写入日志,超过10%报错退出。
6.2.4.3 聚合管道和shard collection
聚合管道支持在shard collection上运行
在shard collection上的聚合操作
第一步,聚合管道会把$group,$sort操作发布到每个shard,然后第二个管道再到mongos上运行,这个管道会组合之前的$group,$sort,继续执行。
$group从shard获得子结果,然后组合起来
聚合管道再mongos上的影响
聚合管道会给mongos带来巨大的cpu消耗,如果在shard集群中有大量的聚合管道操作,建议更换体系结构。
6.2.4.4 Map-Reduce和shard集群
Map-Reduce输入输出都支持shard。
shard集群作为输入
如果shared collection作为数据,mongos会自发的把map-reduce的操作发布到每个shard。
shard集群作为输出
如果map-reduce输出带有shard值,mongodb会使用_id作为shard key进行shard。
输出到shard collection的条件:
1.如果输出的collection不存在,会根据_id创建shard
2.如果一个空的shard,在map-reduce的第一阶段的结果来是初花shard的chunks
3.monogos并发的调度map-reduce的任务到shard中,处理任务的时候,shard会获取自己需要的chunk然后保存
6.2.4.5 Map-Reduce的并发
map-reduce是一个任务组合,包括读输入,执行map,执行reduce,输出
在执行map-reduce的时候会产生以下的锁:
1.读阶段,产生读锁,每100个文档就会释放一次
2.插入到一个零食collection写锁
3.如果collection不存在,创建一个写锁
4.如果collection存在,写入输出写锁
6.3聚合例子
6.3.1邮编的数据集上使用聚合
6.3.1.1数据模型
{
"_id": "10280",
"city": "NEW YORK",
"state": "NY",
"pop": 5574,
"loc": [
-74.016323,
40.710537
]
}
id:邮编,city:城市,state:州,pop:人口,loc:经纬
6.3.1.2返回人口超过100万的州
db.zipcodes.aggregate( { $group :
{ _id : "$state",
totalPop : { $sum : "$pop" } } },
{ $match : {totalPop : { $gte : 10*1000*1000 } } } )
1.group,为每个state创建一个文档,sum 人口
2.然后,通过match过滤人口
6.3.1.3 每个州的平均城市人口
db.zipcodes.aggregate( { $group :{ _id : { state : "$state", city : "$city" },pop : { $sum : "$pop" } } },
{ $group :{ _id : "$_id.state",avgCityPop : { $avg : "$pop" } } } )
1.group对state,city人口进行sum
2.对state人口进行平均
6.3.1.4 返回最大和最小城市
db.zipcodes.aggregate(
{ $group:{ _id: { state: "$state", city: "$city" },pop: { $sum: "$pop" } } },{ $sort: { pop: 1 } },
{ $group:{ _id : "$_id.state",biggestCity: { $last: "$_id.city" },biggestPop: { $last: "$pop" },
smallestCity: { $first: "$_id.city" },
smallestPop: { $first: "$pop" } }
},
// the following $project is optional, and
// modifies the output format.
{ $project:{ _id: 0,state: "$_id",biggestCity: { name: "$biggestCity", pop: "$biggestPop" },
smallestCity: { name: "$smallestCity", pop: "$smallestPop" } } }
)
1.对state,city人口进行sum,并进行排序
2.根据排序获取人口最多,和人口最少的城市
3.通过project修改字段名
6.3.2 用户爱好数据聚合
6.3.2.1数据模型
{
_id : "jane",
joined : ISODate("2011-03-02"),
likes : ["golf", "racquetball"]
}
{
_id : "joe",
joined : ISODate("2012-07-02"),
likes : ["tennis", "golf", "swimming"]
}
6.3.2.2 文档排序
db.users.aggregate(
[
{ $project : { name:{$toUpper:"$_id"} , _id:0 } },
{ $sort : { name : 1 } }
])
6.3.2.3 根据加入的月份排序
db.users.aggregate(
[
{ $project : { month_joined : {$month : "$joined"},name : "$_id",_id : 0},
{ $sort : { month_joined : 1 } }
])
6.3.2.4 每月加入的总人数
db.users.aggregate(
[
{ $project : { month_joined : { $month : "$joined" } } } ,
{ $group : { _id : {month_joined:"$month_joined"} , number : { $sum : 1 } } },
{ $sort : { "_id.month_joined" : 1 } }
])
6.3.2.5前五最受欢迎的爱好
db.users.aggregate(
[
{ $unwind : "$likes" },
{ $group : { _id : "$likes" , number : { $sum : 1 } } },
{ $sort : { number : -1 } },
{ $limit : 5 }
])
1.使用unwind对likes进行拆分
2.group对爱和统计,并计数
3.排序
4 前5
6.3.3 Map-Reduce例子
Map-Reduce主要针对以下数据模型:
{
_id: ObjectId("50a8240b927d5d8b5891743c"),
cust_id: "abc123",
ord_date: new Date("Oct 04, 2012"),
status: 'A',
price: 25,
items: [ { sku: "mmm", qty: 5, price: 2.5 },
{ sku: "nnn", qty: 5, price: 2.5 } ]
}
6.3.3.1 返回每个用户的所有订单价格
1.定义map函数,map price和cust_id并emits
var mapFunction1 = function() {
emit(this.cust_id, this.price);
};
2.定义reduce 函数,2个参数,keycustid和valuesPrices,valuesPrices是一个数组,所以:
var reduceFunction1 = function(keyCustId, valuesPrices) {
return Array.sum(valuesPrices);
};
3.执行map-reduce,输出指定map_reduce_example如果已经存在会替换原先的collection
db.orders.mapReduce(
mapFunction1,
reduceFunction1,
{ out: "map_reduce_example" }
)
6.3.3.2 计算订单平均商品数量
var mapFunction2 = function() {
for (var idx = 0; idx < this.items.length; idx++) {
var key = this.items[idx].sku;
var value = {count: 1,qty: this.items[idx].qty};
emit(key, value);
}};
var reduceFunction2 = function(keySKU, countObjVals) {
reducedVal = { count: 0, qty: 0 };
for (var idx = 0; idx < countObjVals.length; idx++) {
reducedVal.count += countObjVals[idx].count;
reducedVal.qty += countObjVals[idx].qty;
}
return reducedVal;
};
var finalizeFunction2 = function (key, reducedVal) {
reducedVal.avg = reducedVal.qty/reducedVal.count;
return reducedVal;
};
db.orders.mapReduce( mapFunction2,reduceFunction2,
{
out: { merge: "map_reduce_example" },
query: { ord_date:{ $gt: new Date('01/01/2012') }},
finalize: finalizeFunction2
}
)
out,merge输出会合并到map_reduce_example
6.3.4 增量执行map-reduce
如果map-reduce的数据集会一直增加,那么不需要对所有的执行map-reduce,最对增加的部分执行即可。
1.在现有的collection上执行map-reduce
2.增加数据,在query中指定新数据的条件,在out中指定reduce,合并已有数据
6.3.4.1 数据
db.sessions.save( { userid: "a", ts: ISODate('2011-11-03 14:17:00'), length: 95 } );
db.sessions.save( { userid: "b", ts: ISODate('2011-11-03 14:23:00'), length: 110 } );
db.sessions.save( { userid: "c", ts: ISODate('2011-11-03 15:02:00'), length: 120 } );
db.sessions.save( { userid: "d", ts: ISODate('2011-11-03 16:45:00'), length: 45 } );
db.sessions.save( { userid: "a", ts: ISODate('2011-11-04 11:05:00'), length: 105 } );
db.sessions.save( { userid: "b", ts: ISODate('2011-11-04 13:14:00'), length: 120 } );
db.sessions.save( { userid: "c", ts: ISODate('2011-11-04 17:00:00'), length: 130 } );
db.sessions.save( { userid: "d", ts: ISODate('2011-11-04 15:37:00'), length: 65 } );
6.3.4.2 初始化执行Map-Reduce
var mapFunction = function() {
var key = this.userid;
var value = {userid: this.userid,
total_time: this.length,
count: 1,
avg_time: 0
};
emit( key, value );
};
var reduceFunction = function(key, values) {
var reducedObject = {
userid: key,
total_time: 0,
count:0,
avg_time:0
};
values.forEach( function(value) {
reducedObject.total_time += value.total_time;
reducedObject.count += value.count;
});
return reducedObject;
};
var finalizeFunction = function (key, reducedValue) {
if (reducedValue.count > 0)
reducedValue.avg_time = reducedValue.total_time / reducedValue.count;
return reducedValue;
};
db.sessions.mapReduce( mapFunction,
reduceFunction,
{
out: { reduce: "session_stat" },
finalize: finalizeFunction
}
)
6.3.4.3顺序新增数据
db.sessions.save( { userid: "a", ts: ISODate('2011-11-05 14:17:00'), length: 100 } );
db.sessions.save( { userid: "b", ts: ISODate('2011-11-05 14:23:00'), length: 115 } );
db.sessions.save( { userid: "c", ts: ISODate('2011-11-05 15:02:00'), length: 125 } );
db.sessions.save( { userid: "d", ts: ISODate('2011-11-05 16:45:00'), length: 55 } );
db.sessions.mapReduce( mapFunction,
reduceFunction,
{
query: { ts: { $gt: ISODate('2011-11-05 00:00:00') } },
out: { reduce: "session_stat" },
finalize: finalizeFunction
}
);
6.3.5 Map函数TroubleShooting
1.定义map函数
var map = function() {
emit(this.cust_id, this.price);
};
2.定义reduce函数
var emit = function(key, value) {
print("emit");
print("key: " + key + " value: " + tojson(value));
}
3.调用map函数
var myDoc = db.orders.findOne( { _id: ObjectId("50a8240b927d5d8b5891743c") } );
map.apply(myDoc);
4.验证输出
emit
key: abc123 value:250
5.多文档调用
var myCursor = db.orders.find( { cust_id: "abc123" } );
while (myCursor.hasNext()) {
var doc = myCursor.next();
print ("document _id= " + tojson(doc._id));
map.apply(doc);
print();
}
6.验证结果
6.3.6Reduce函数Troubleshooting
1.确定返回的数据类型,和传入的数据类型一致
2.数组的顺序,不影响结果
3.多次执行不影响结果
6.4聚合指南
查看手册p308
