一、实验背景介绍
大数据计算服务(MaxCompute,原名 ODPS)是一种快速、完全托管的 GB/TB/PB 级数据仓库解决方案。MaxCompute 向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。本实验结合实际数据和案例,深入浅出的演示了如何使用MaxCompute的内置函数。
完成此实验后,可以掌握的内置函数有:
- 窗口函数;
2. 聚合函数;3. 其他函数;
二、实验环境架构
实验环境架构:阿里云大数据计算服务MaxCompute
第 1 章:实验准备
1.1 申请MaxCompute资源
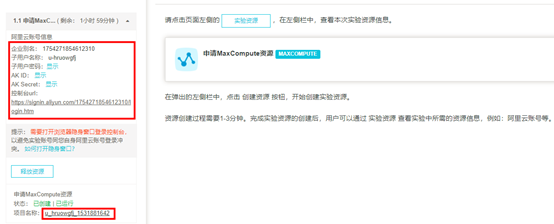
请点击页面左侧的 ,在左侧栏中,查看本次实验资源信息。 maxcompute申请MaxCompute资源 MAXCOMPUTE 在弹出的左侧栏中,点击 创建资源 按钮,开始创建实验资源。 资源创建过程需要1-3分钟。完成实验资源的创建后,用户可以通过 实验资源 查看实验中所需的资源信息,例如:阿里云账号等。
1.2 开通服务
(本实验用到odps客户端,创建资源之前确保本地安装了java8或者以上版本) Java下载地址: 1)点击【实验资源】,查看本次实验资源信息(MaxCompute资源)。 2)在弹出的左侧栏中,点击 【创建资源】按钮,开始创建实验资源。 如下图:
注意:实验环境一旦开始创建则进入计时阶段,建议学员先基本了解实验具体的步骤、目的,真正开始做实验时再进行创建。 3)创建资源,如下图:(创建资源需要几分钟时间,请耐心等候……) 4)资源创建成功后,可通过【实验资源】查看实验中所需的实验资源信息。如下图:
注意:在本地保存下阿里云账号信息,包括资源中的项目名称、企业别名、子用户名称、子用户密码、AK ID、AK Secret等信息。 沙箱实验环境说明:
企业别名:即主账号ID;
子用户名称和子用户密码:登录实验环境的账号;
AK ID和AK Secret:系统为当前用户分配的登录验证密钥信息,配置odps客户端时需要;
控制台url:登录实验开发环境的地址; 5)点击页面左侧的【控制台url】,复制链接,在新的窗口打开,跳转到登录页。 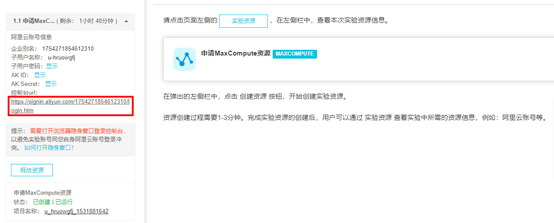 6)在登录页,输入【实验资源】中提供的账号,格式为:子用户名称@企业别名,再点击【下一步】。 7)输入【实验资源】中提供的的“子用户密码”,点击【登录】 8)登陆后,进入【管理控制台】界面, 点击左侧菜单栏 【大数据(数加)】,再点击【DataWorks】,进入数据开发概览页。
6)在登录页,输入【实验资源】中提供的账号,格式为:子用户名称@企业别名,再点击【下一步】。 7)输入【实验资源】中提供的的“子用户密码”,点击【登录】 8)登陆后,进入【管理控制台】界面, 点击左侧菜单栏 【大数据(数加)】,再点击【DataWorks】,进入数据开发概览页。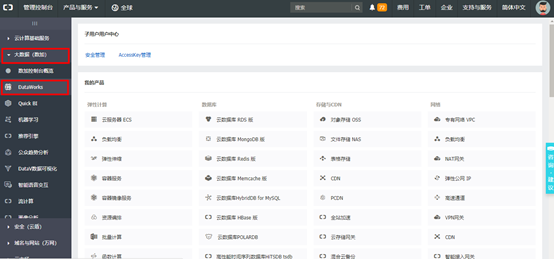
1.3 创建项目
沙箱环境已经默认创建完项目,点击【进入数据开发】即可。 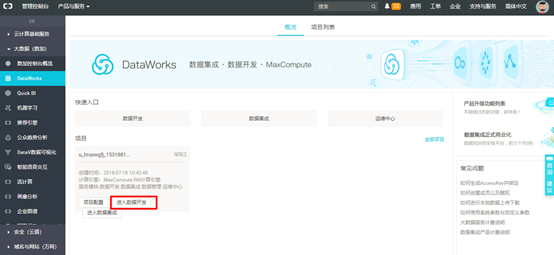
 本小节以下步骤供使用个人账号实验参考。
本小节以下步骤供使用个人账号实验参考。
开通MaxCompute后,点击【管理控制台】 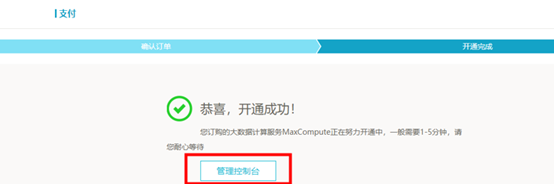 选中MaxCompute服务,选择【按量付费】,然后点击【下一步】
选中MaxCompute服务,选择【按量付费】,然后点击【下一步】 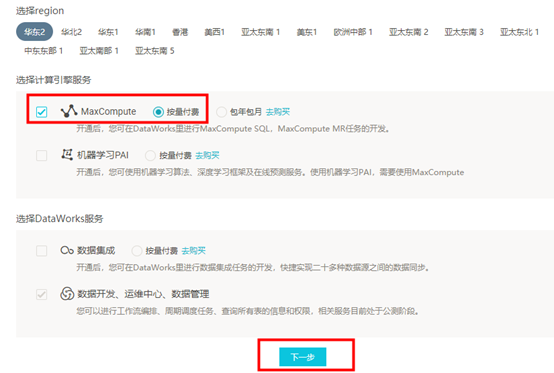 填写项目相关信息:输入“项目名称”(全局唯一)、“显示名”以及“项目描述” 信息,然后点击【创建项目】。
填写项目相关信息:输入“项目名称”(全局唯一)、“显示名”以及“项目描述” 信息,然后点击【创建项目】。  项目创建成功后,点击【进入数据开发】:】
项目创建成功后,点击【进入数据开发】:】 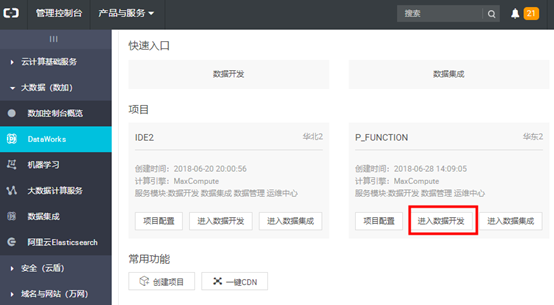 打开【数据开发】页面:
打开【数据开发】页面: 
1.4 安装配置odpscmd客户端
步骤1:客户端下载 (本实验已经提供好客户端,自行下载附件)
步骤2:解压odpscmd_public.zip 到本地目录,密码:aca21104 如:解压至E:\ODPS_DEMO
步骤3:查看本次实验课用到的介质,可以看到如下的文件夹: 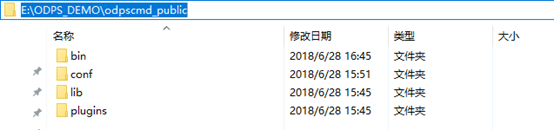 步骤4:在conf文件夹中有odps_config.ini文件。鼠标右键编辑此文件,配置相关信息:
步骤4:在conf文件夹中有odps_config.ini文件。鼠标右键编辑此文件,配置相关信息: 
说明:project_name= <对应实验资源中的项目名称> access_id= <对应实验资源中的ak id> access_key= <对应实验资源中的ak secret> end_point=http://service.odps.aliyun.com/api(默认)tunnel_endpoint=http://dt.odps.aliyun.com (默认)log_view_host=http://logview.odps.aliyun.com(默认) https_check=true (默认)
 步骤5:修改好配置文件后,鼠标双击运行bin目录下的odpscmd(在Linux系统下是./bin/odpscmd,Windows下运行./bin/odpscmd.bat),现在可以运行 MaxCompute 命令,如:
步骤5:修改好配置文件后,鼠标双击运行bin目录下的odpscmd(在Linux系统下是./bin/odpscmd,Windows下运行./bin/odpscmd.bat),现在可以运行 MaxCompute 命令,如:  注意:项目可以随时根据情况切换,上图表示环境设置成功.
注意:项目可以随时根据情况切换,上图表示环境设置成功.
1.5 测试表dual准备
在【临时查询】页面,点击【新建】,然后点击【QDPS SQL】 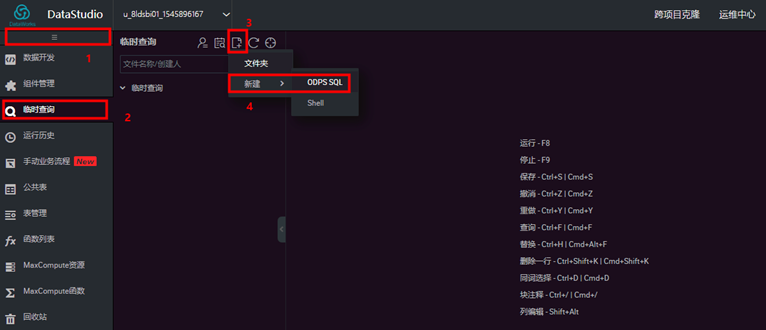 输入“节点名称”,选择“目标文件夹”,然后点击【提交】。
输入“节点名称”,选择“目标文件夹”,然后点击【提交】。 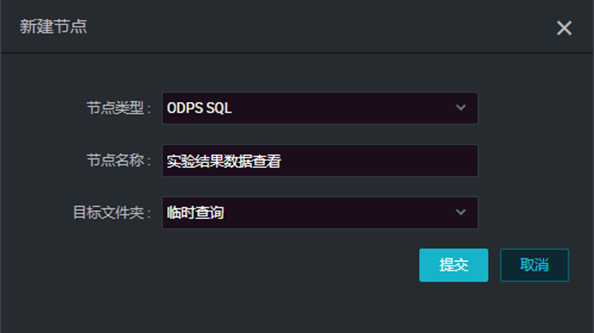 进入脚本编辑页面,进行脚本开发,创建实验测试表dual,点击【运行】。
进入脚本编辑页面,进行脚本开发,创建实验测试表dual,点击【运行】。
SQL语句:
CREATE TABLE dual (
id BIGINT
)
LIFECYCLE 10000;
然后查看运行日志日志显示测试表创建成功。 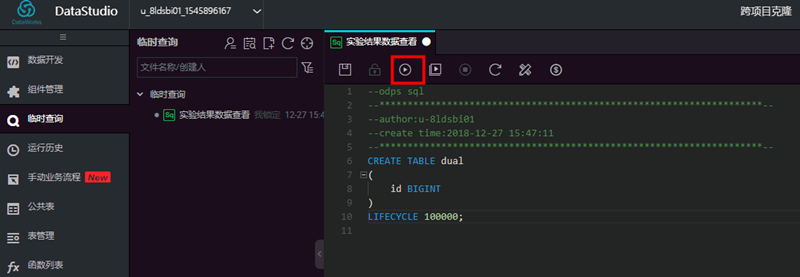
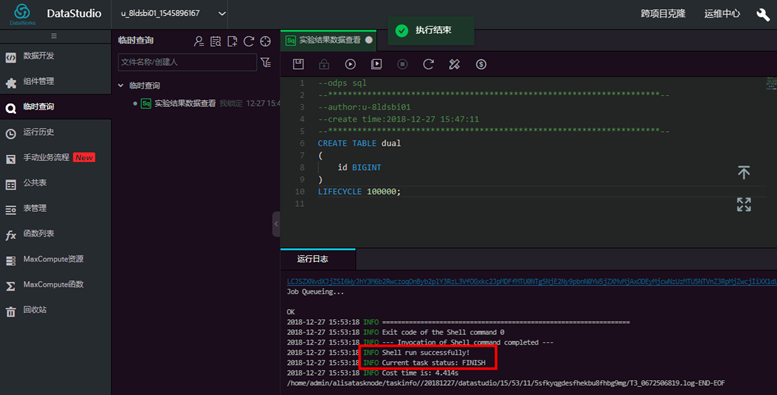 往测试表里插入一条数据,输入SQL语句,点击【运行】。
往测试表里插入一条数据,输入SQL语句,点击【运行】。
insert into table dual select count(1) from dual;
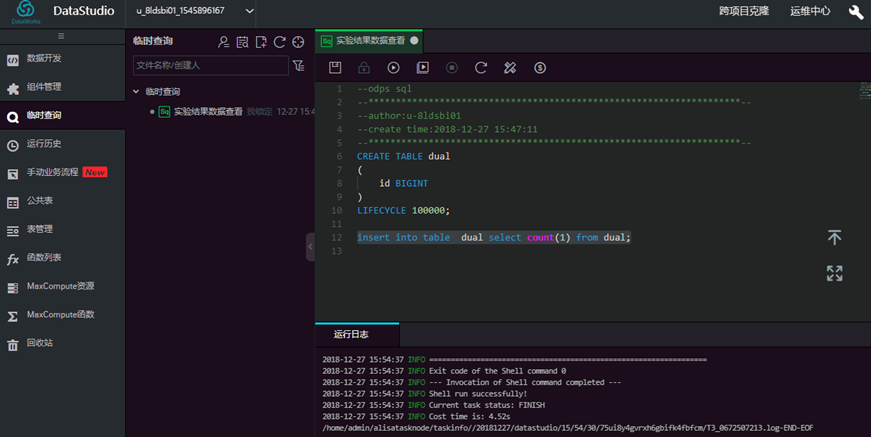 查看测试表数据内容,输入SQL语句,点击【运行】。:
查看测试表数据内容,输入SQL语句,点击【运行】。:
select * from dual limit 10;
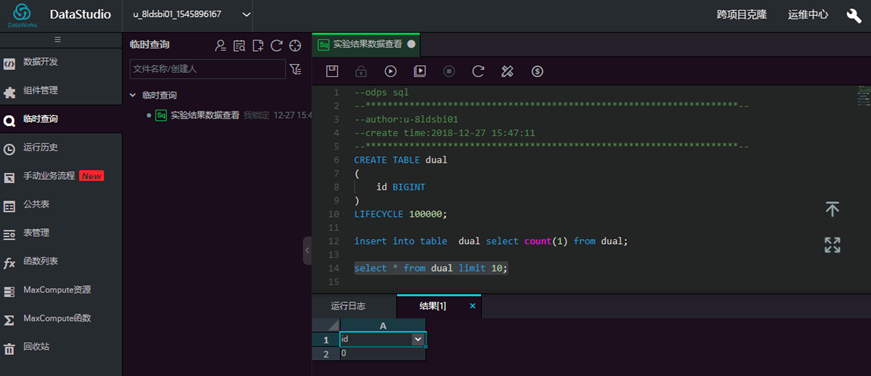
1.6 测试表t_dml准备
进入脚本编辑页面,进行脚本开发,创建实验测试表t_dml,点击【运行】
create table t_dml (
detail_id bigint,
sale_date datetime,
province string,
city string,
product_id bigint,
cnt bigint,
amt double
);
然后查看运行日志显示测试表创建成功。 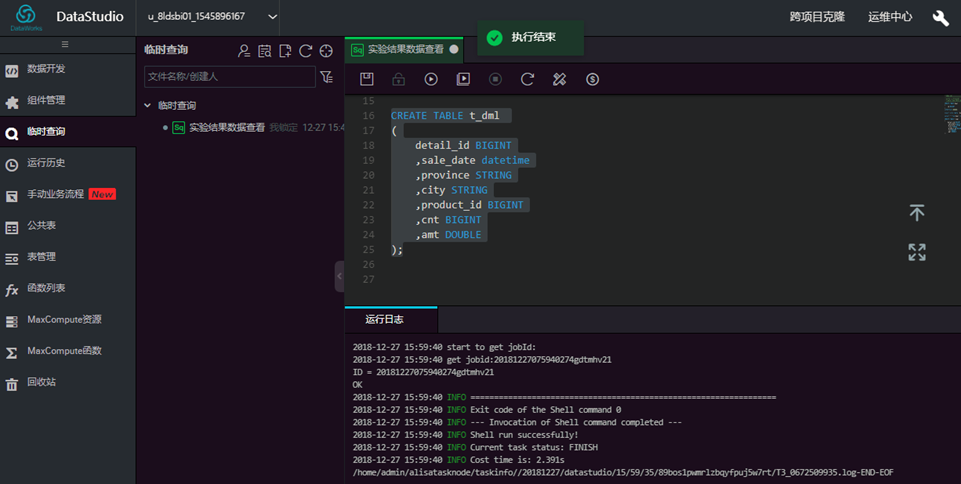 打开odpscmd客户端交互界面
打开odpscmd客户端交互界面  执行命令,加载数据 t_dml.csv,(注意修改数据文件存放路径):
执行命令,加载数据 t_dml.csv,(注意修改数据文件存放路径):
tunnel upload f:\data\t_dml.csv t_dml; 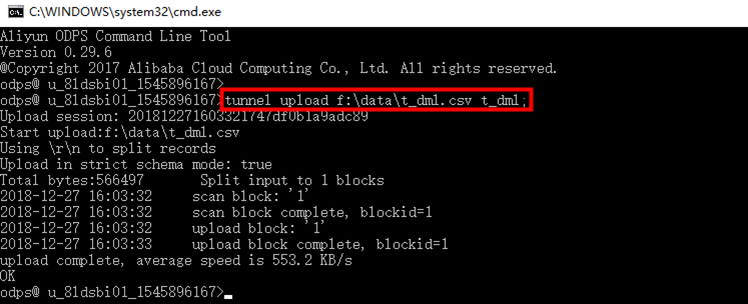 查看数据表数据:输入sql语句,点击【运行】,查看结果。
查看数据表数据:输入sql语句,点击【运行】,查看结果。
select * from t_dml limit 10; 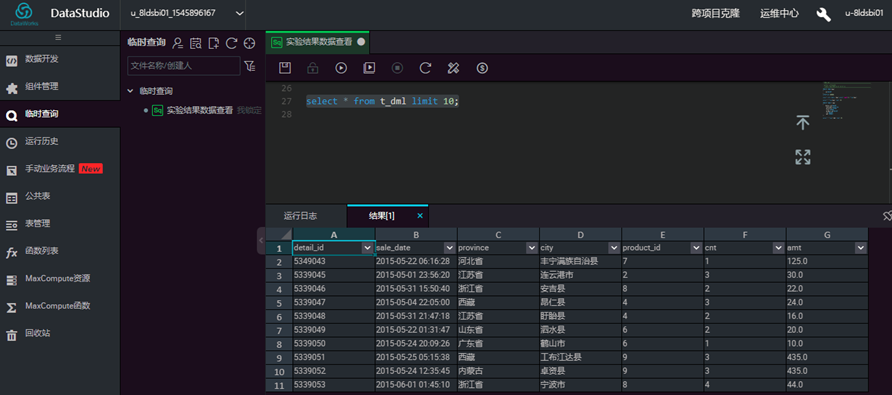
1.7 测试表t_product准备
进入脚本编辑页面,进行脚本开发,创建实验测试表t_product,点击【运行】。
create table t_product
(product_id bigint, product_name string, category_id bigint, category_name string, price double);
然后查看运行日志显示测试表创建成功。 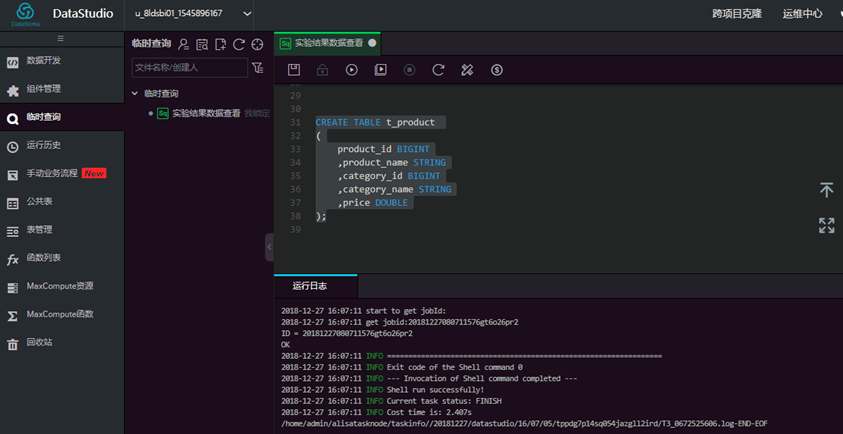 打开odpscmd客户端交互界面
打开odpscmd客户端交互界面  加载数据 t_product.csv,注意文件路径:
加载数据 t_product.csv,注意文件路径:
tunnel upload f:\data\t_product.csv t_product; 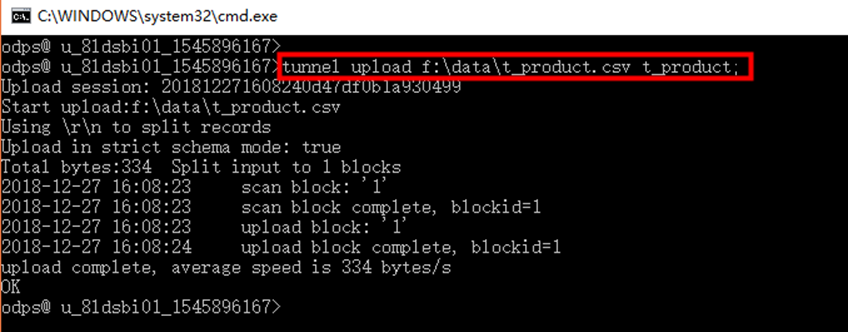 查看数据表数据,输入sql,点击【运行】。
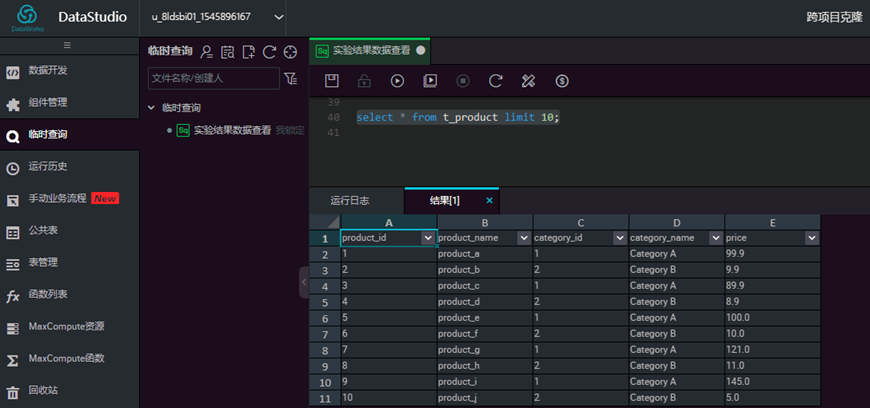
查看数据表数据,输入sql,点击【运行】。
select * from t_product limit 10;
1.8 测试表t_sign准备
进入脚本编辑页面,进行脚本开发,创建实验测试表t_sign,点击【运行】。
create table t_sign (id bigint, name string, height double, is_female boolean, birth_day datetime);
测试表创建成功 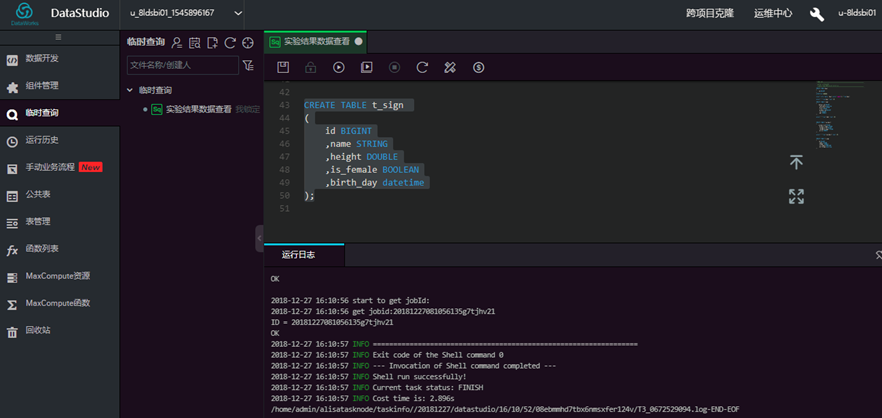 进入odpscmd客户端交互界面 执行命令,加载数据 t_sign.csv:
进入odpscmd客户端交互界面 执行命令,加载数据 t_sign.csv:
tunnel upload f:\data\t_sign.csv t_sign;
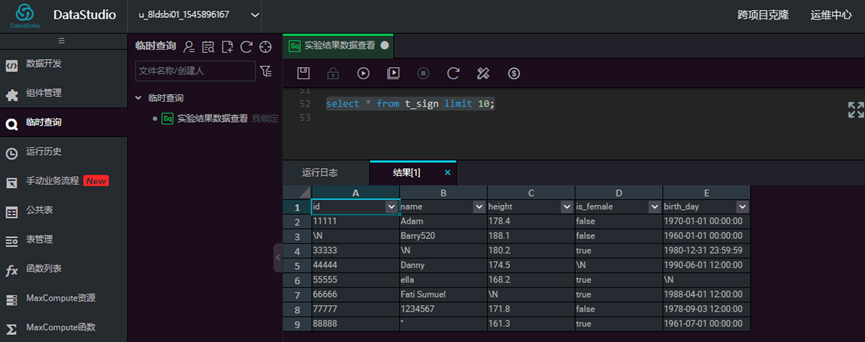
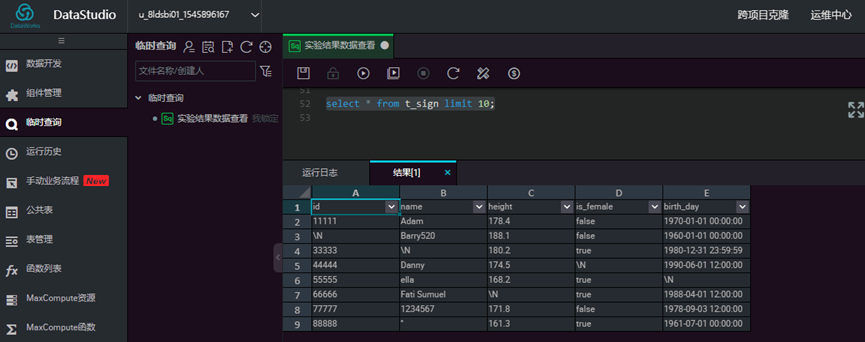 查看数据表数据,输入sql, 点击【运行】
查看数据表数据,输入sql, 点击【运行】
select * from t_sign limit 10;
第 2 章:实验详情
2.1 窗口函数
(1) 统计量类:
根据5月份销售数据,统计出日销量波动最小的产品(即标准差最小) 。在【临时查询】工作区,点击【新建QDPS SQL】,输入相关信息,然后点击【提交】 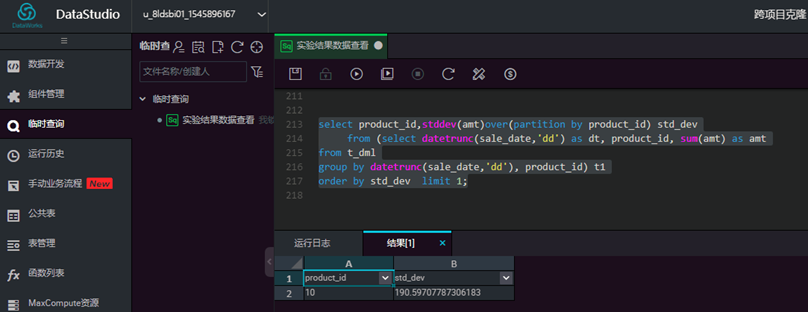 输入脚本,点击【运行】,查看结果
输入脚本,点击【运行】,查看结果
select product_id,stddev(amt)over(partition by product_id) std_dev
from (select datetrunc(sale_date,'dd') as dt, product_id, sum(amt) as amt
from t_dml
group by datetrunc(sale_date,'dd'), product_id) t1
order by std_dev limit 1;
(2) 排名类:
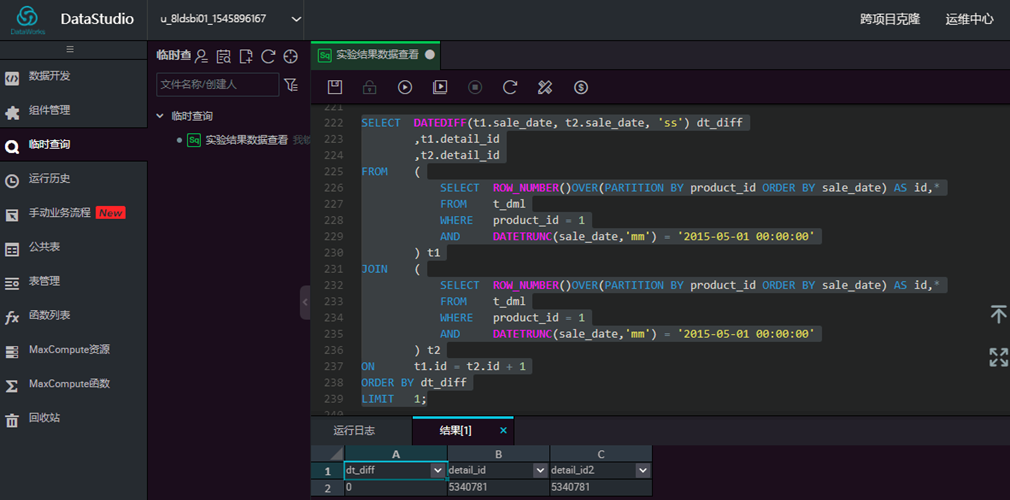
根据5月份销售数据,统计出同一产品成交最短时间间隔(以产品1为例,列出两次成交时间差最小的记录)。
select datediff(t1.sale_date, t2.sale_date, 'ss') dt_diff,
t1.detail_id, t2.detail_id
from (select row_number()over(partition by product_id order by sale_date)
as id, * from t_dml where product_id=1
and datetrunc(sale_date,'mm')='2015-05-01 00:00:00') t1
join (select row_number()over(partition by product_id order by sale_date) as id, *
from t_dml where product_id=1
and datetrunc(sale_date,'mm')='2015-05-01 00:00:00') t2
on t1.id = t2.id+1 order by dt_diff limit 1;
输入脚本,点击【运行】,查看结果
 (3) 带 rows 的开窗:
(3) 带 rows 的开窗: 在做时序分析(Time Series Analysis)时,对于长期趋势(Trend)的分析最常见的是使用移动平均法(Moving Average method),是通过逐期移动时间序列,并计算一系列扩大时间间隔后的序时平均数,最终形成一个新时间序列的方法。优点是由其它因素而引起的变动影响被削弱了,对原序列起到了修匀的作用,从而更清晰地呈现出现象的变动趋势。通常MA是由专业的挖掘算法来实现,我们可以尝试使用带rows的开窗函数来实现:
以4天作为一个平滑窗口的宽度(前2后1),即取n-2天到n+1天作为一个平滑窗口,计算连续四天内的均值作为第n天的代表值。对产品1和产品2的销售金额和销售量进行平稳化。做趋势图,分别做横向(不同产品的趋势图)和纵向(同一产品平滑前后的趋势图)比较。
select dt, product_id, avg(amt) over(partition by product_id order by dt rows between 2
preceding and 1 following),
avg(cnt) over(partition by product_id order by dt rows between 2
preceding and 1 following)
from (select to_char(sale_date,'yyyymmdd') as dt, product_id,
sum(cnt) as cnt, sum(amt) as amt
from t_dml where product_id in (1,2)
group by to_char(sale_date,'yyyymmdd'),product_id) t;
输入脚本,点击【运行】,查看结果 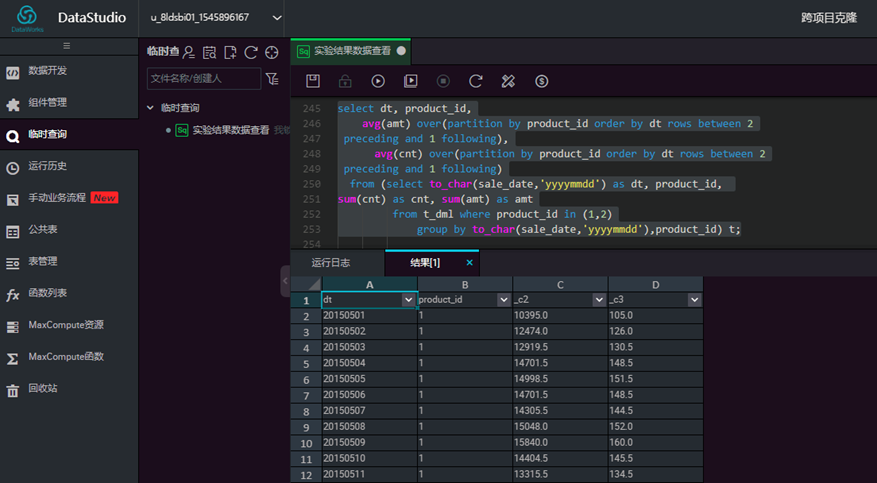
2.2 聚合函数
(1) 统计量类:
给出销售信息表t_dml中的不同产品的销售金额的基本统计信息。
select product_id, count(*), min(amt), max(amt), sum(amt), avg(amt),
median(amt), stddev(amt), stddev_samp(amt)
from t_dml
group by product_id;
输入脚本,点击【运行】,查看结果 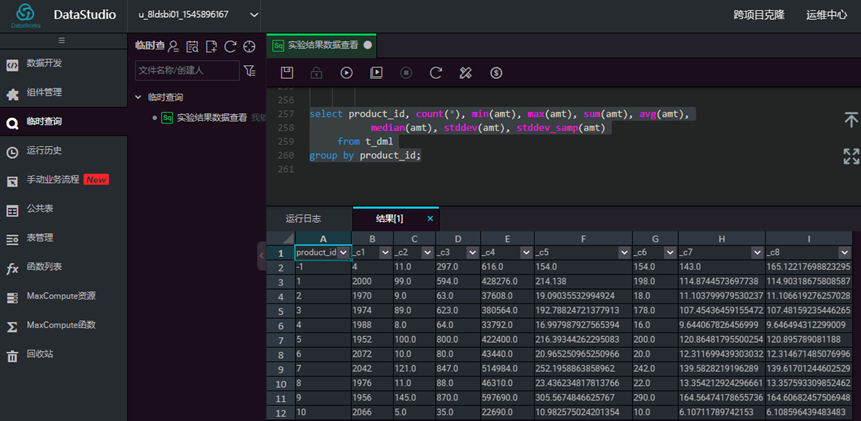 (2) 字符串类:
(2) 字符串类:
将产品标称单价在50-100元的,生成一个清单,不同产品名称之间用|分隔开。
select wm_concat('|',product_name)
from t_product where price >=50 and price<=100;
输入脚本,点击【运行】,查看结果 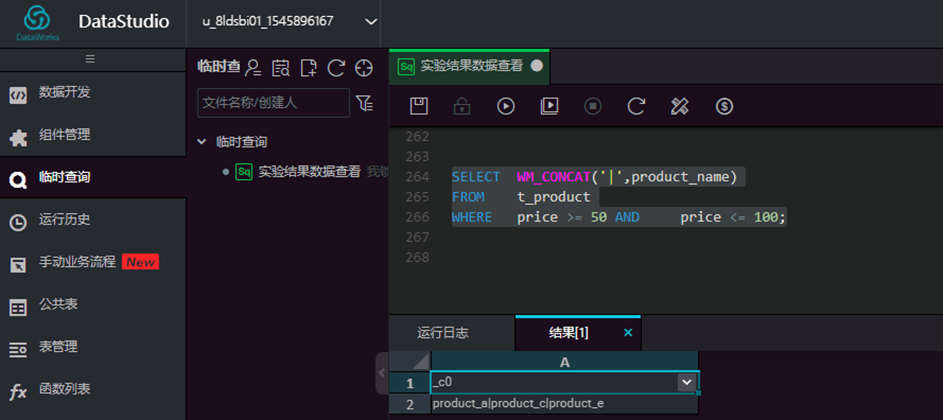
2.3 其他函数
(1) COALESCE 处理NULL值:
将 t_sign 中的名字(name)和生日(birth_day)拼成一个串
select concat(coalesce(name,'unknown'),coalesce(birth_day,'unknown'))
from t_sign;
输入脚本,点击【运行】,查看结果 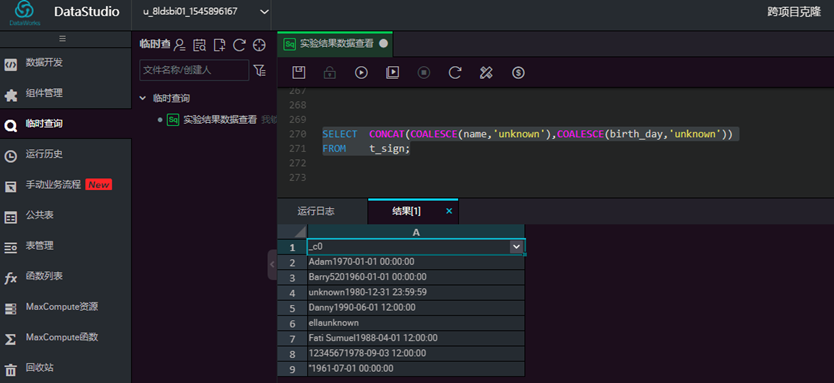 (2) decode 分支函数
(2) decode 分支函数
将销售记录t_dml中浙江、上海和北京的销量单独统计出来:
select decode(province,'浙江省', '浙', '上海市', '沪', '北京市', '京','其他'),
sum(cnt)
from t_dml
group by decode(province,'浙江省','浙', '上海市', '沪', '北京市', '京','其他');
输入脚本,点击【运行】,查看结果 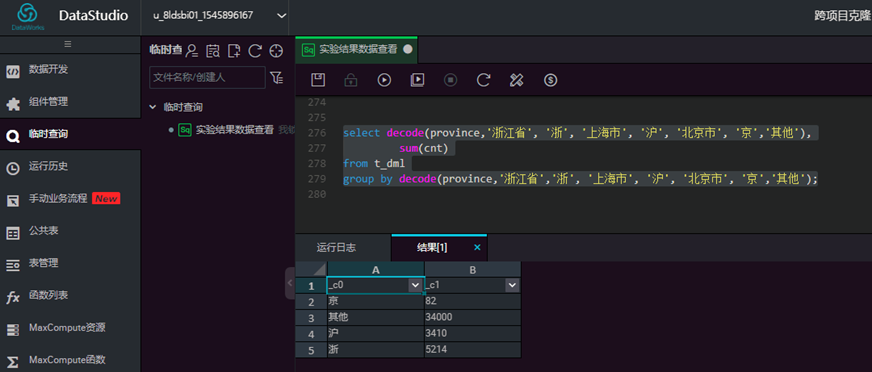 (3) ordinal 有序位置函数:
(3) ordinal 有序位置函数:
顺序统计量(Ordered Statistics,也称次序统计量)是非参统计的重要组成部分,适用于整体分布不能由有限个参数表示的情况。利用ordinal函数,可以方便的计算顺序统计相关的一些基础统计量:
最小顺序统计量 X(1),最大顺序统计量 X(n),极差 R=X(n) -X (1) ,四分卫极差:
IQL= X(0.75n) -X (0.25n)
select ordinal(8,1,2,3,4,6,5,8,7,9,0)- ordinal(3,1,2,3,4,6,5,8,7,9,0) as IQL
from dual;
输入脚本,点击【运行】,查看结果
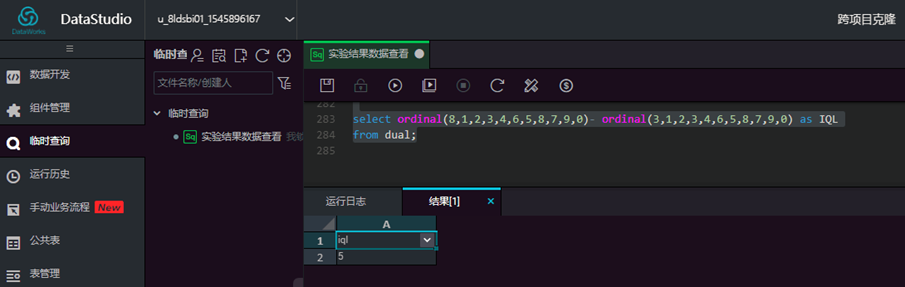 (4) sample 采样函数:
(4) sample 采样函数:
通过采样分析的手段,从销售记录表t_dml中得到1/100的数据,分析采样样本,试着推断总体的销售金额的平均值、标准差、极值、极差等,然后从总体中计算出这些统计量进行验证。调整采样比例,重复上述推断过程,找到一个准确程度和样本体量的平衡点,进一步思考:这个平衡点有多大参考价值?
// 1/100比例的样本的推断值
select avg(amt) as Average,stddev_samp(amt) as Standard_Dev,
min(amt) as Min_Val, max(amt) as Max_Val, max(amt) - min(amt) as Range_Val,count(*) as Sample_size
from (select amt from t_dml where sample(100,1,detail_id)=true) t;
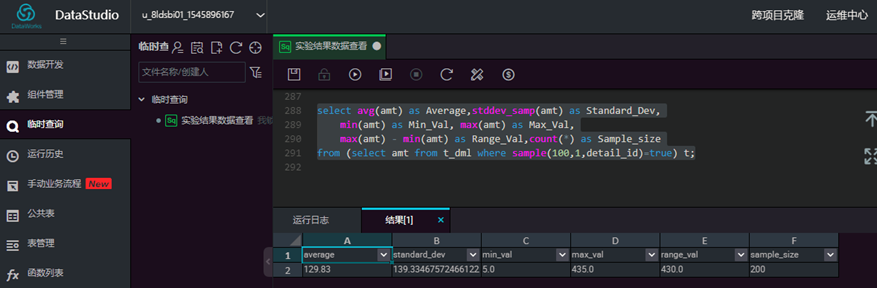 // 1/10比例的样本的推断值
// 1/10比例的样本的推断值
select avg(amt) as Average,stddev_samp(amt) as Standard_Dev,
min(amt) as Min_Val, max(amt) as Max_Val, max(amt) - min(amt) as Range_Val,count(*) as Sample_size
from (select amt from t_dml where sample(10)=true) t; 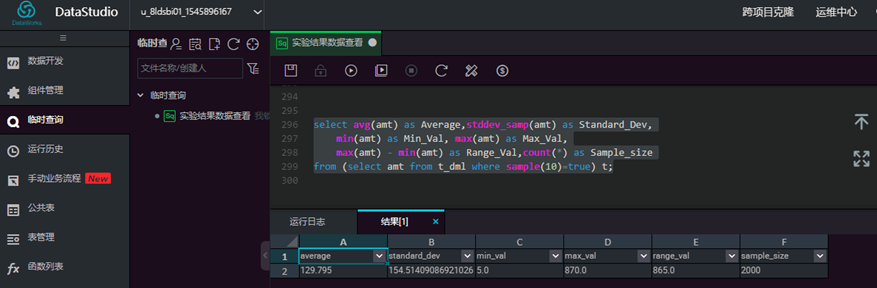 //总体实际值
//总体实际值
select avg(amt) as Average,stddev_samp(amt) as Standard_Dev,
min(amt) as Min_Val, max(amt) as Max_Val, max(amt) - min(amt) as Range_Val,count(*) as Sample_size
from t_dml;
输入脚本,点击【运行】,查看结果 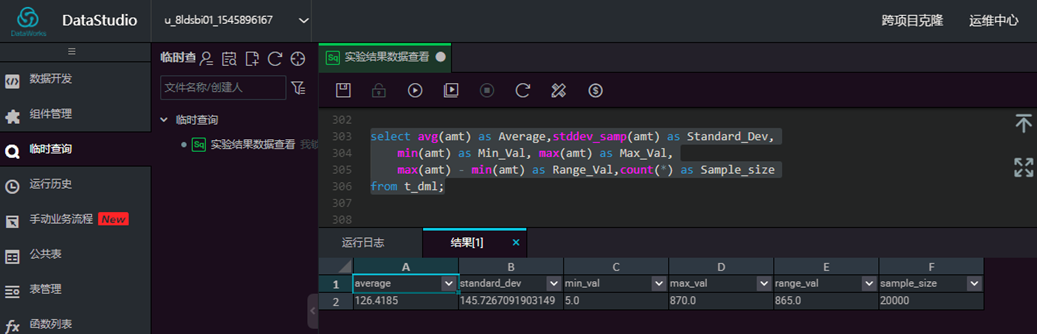
第 3 章:实验总结
3.1 实验总结
MaxCompute的这几类函数基本覆盖了我们日常工作的绝大多数数据处理需求。通过灵活熟练的使用这些函数,
可以提升开发效率,若仍有无法满足的需求,还可以考虑自定义函数。
第 4 章:课后任务
4.1 课后任务
1、根据t_dml表,统计输出各个省成交额最大的城市及其成交额
2、根据t_dml表,统计输出各个城市有交易的天数及其平均成交额
3、根据t_product表,输出各类别下价格最大的产品及其价格
