本文共 6993 字,大约阅读时间需要 23 分钟。
03基于机器学习的文本分类
机器学习是对能通过经验自动改进的计算机算法的研究。机器学习通过历史数据训练出模型对应于人类对经验进行归纳的过程,机器学习利用模型对新数据进行预测对应于人类利用总结的规律对新问题进行预测的过程。
1.学习目标
- 学会TF-IDF的原理和使用
- 使用sklearn的机器学习模型完成文本分类
2.文本表示方法 Part1
在自然语言领域,文本是不定长度的,文本分类的第一步是将不定长的文本转换到定长的空间内,这种把文本表示成计算机能够运算的数字或向量的方法一般称为词嵌入(Word Embedding)方法。
2.1 One-hot
与数据挖掘任务中的操作一致,将每一个单词使用一个离散的向量表示。将每个字/词编码一个索引,然后根据索引进行赋值。
One-hot表示方法的例子如下:
句子1:我 爱 北 京 天 安 门句子2:我 喜 欢 上 海
首先对所有句子的字进行索引,即将每个字确定一个编号:
{ '我': 1, '爱': 2, '北': 3, '京': 4, '天': 5, '安': 6, '门': 7, '喜': 8, '欢': 9, '上': 10, '海': 11} 在这里共包括11个字,因此每个字可以转换为一个11维度稀疏向量:
我:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] 爱:[0, 1, 0, 0, 0, 0, 0, 0, 0, 0,0] ... 海:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
2.2 Bag of Words
Bag of Words(词袋表示),也称为Count Vectors,每个文档的字/词可以使用其出现次数来进行表示。
句子1:我 爱 北 京 天 安 门句子2:我 喜 欢 上 海
直接统计每个字出现的次数,并进行赋值:
句子1:我 爱 北 京 天 安 门转换为 [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]句子2:我 喜 欢 上 海转换为 [1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
在sklearn中可以直接CountVectorizer来实现这一步骤:
from sklearn.feature_extraction.text import CountVectorizercorpus = [ 'This is the first document.', 'This document is the second document.', 'And this is the third one.', 'Is this the first document?',]vectorizer = CountVectorizer()vectorizer.fit_transform(corpus).toarray()#等价于下面三行#vectorizer.fit(corpus)#vectorizer_fit = vectorizer.transform(corpus)#vectorizer_fit.toarray()

vectorizer.get_feature_names()#列表形式呈现词典
[‘and’, ‘document’, ‘first’, ‘is’, ‘one’, ‘second’, ‘the’, ‘third’, ‘this’]
vectorizer.vocabulary_ #字典形式呈现词典
{‘this’: 8, ‘is’: 3, ‘the’: 6, ‘first’: 2, ‘document’: 1, ‘second’: 5, ‘and’: 0, ‘third’: 7, ‘one’: 4}
2.3 N-gram
N-gram与Count Vectors类似,不过加入了相邻单词组合成为新的单词,并进行计数。
如果N取值为2,则句子1和句子2就变为:
句子1:我爱 爱北 北京 京天 天安 安门句子2:我喜 喜欢 欢上 上海
2.4 TF-IDF
TF即词语频率(Term Frequency),IDF即逆文档频率(Inverse Document Frequency)
- TF(t) = 该词语在当前文档出现的次数 / 当前文档中词语的总数
- IDF(t) = log_e (文档总数 / 出现该词语的文档总数)
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
3.基于机器学习的文本分类
3.1 Count Vectors + RidgeClassifier
import pandas as pdfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.linear_model import RidgeClassifierfrom sklearn.metrics import f1_scoretrain_df = pd.read_csv('./train_set.csv', sep='\t')#加载所有训练数据vectorizer = CountVectorizer(max_features=3000)train_test = vectorizer.fit_transform(train_df['text'])clf = RidgeClassifier()clf.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = clf.predict(train_test[10000:])print(f1_score(train_df['label'].values[10000:], val_pred, average='macro')) 
- 如果每个class的样本数量差不多,那么宏平均和微平均没有太大差异
- 如果每个class的样本数量差异很大
- 更注重样本量多的class:使用微平均
- 更注重样本量少的class:使用宏平均
- 如果微平均大大低于宏平均,检查样本量多的class
- 如果宏平均大大低于微平均,检查样本量少的class
3.2 TF-TDF + RidgeClassifier
import pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.linear_model import RidgeClassifierfrom sklearn.metrics import f1_scoretrain_df = pd.read_csv('./train_set.csv', sep='\t',nrows=15000)tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)train_test = tfidf.fit_transform(train_df['text'])clf = RidgeClassifier()clf.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = clf.predict(train_test[10000:])print(f1_score(train_df['label'].values[10000:], val_pred, average='macro')) 0.87193721737
其中,TfidfVectorizer = CountVectorizer + TfidfTransformer.
CountVectorizer将文本中的词语转换为词频矩阵:
- fit_transform(),计算各个词语出现的次数
- get_feature_names(),所有文本的关键词
- toarray(),词频矩阵
TfidfTransformer用于统计vectorizer中每个词语的TFIDF值。
TfidfVectorizer
- ngram_range:tuple(min_n,max_n) 将text分成长度为min,min+1,min+2,…max 的词组 如’Python is useful’: ngram_range(1,3):‘Python’ ‘is’ ‘useful’ ‘Python is’ ‘is useful’ 和’Python is useful’ ngram_range (1,1) :‘Python’ ‘is’和’useful’
- max_features:int 或 None(默认值) 如果不是None,则建立一个词汇表,仅用词频排序的前max_features个词创建语料库。 如果vocabulary不是None,则忽略此参数。
- stop_words:string {‘english’},list,或None(默认) “english”,使用内置的英语停用词表。 “list”,如果是一个列表,则被假定为包含停用词,那么所有列表中的词都将从结果标记中删除。只适用于analyzer == ‘word’ “None”,不会处理停用词。可以将max_df设置为范围 [0.7,1.0)中的一个值,以根据术语内部语料库文档频率自动检测和过滤停用词
- max_df:float(在[ 0.0,1.0 ]内),或int,默认值= 1.0 在构建词汇时忽略文档频率严格高于给定阈值(语料库特定停用词)的词语。如果为float,则该参数表示文档的比例,即整数绝对计数。 如果vocabulary不是None,则忽略此参数。
4.作业
1、尝试改变TF-IDF的参数,并验证精度
手动改了几个参数,有一定的提高,结果如下 max_features=5000 0.883918924212 stop_words={‘3750’,‘900’,‘648’} 0.889925904142GridSearchCV网格搜索
AttributeError: lower not found
import pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.linear_model import RidgeClassifierfrom sklearn.model_selection import GridSearchCVfrom sklearn.pipeline import Pipelinepipeline = Pipeline([('tfidf',TfidfVectorizer()),('clf',RidgeClassifier()),]);parameters = { 'tfidf__max_features': (None, 5000, 10000), 'tfidf__ngram_range':((2,2),(1,3)),}grid_search=GridSearchCV(pipeline,param_grid=parameters)grid_search.fit(train_df['text'].values[0:10000], train_df['label'].values[0:10000])print("Best score: %0.3f" % grid_search.best_score_) 
best_parameters = grid_search.best_estimator_.get_params()for param_name in sorted(parameters.keys()): print("\t%s: %r" % (param_name, best_parameters[param_name])) 
from sklearn.metrics import f1_scoretfidf = TfidfVectorizer(ngram_range=(2,2))train_test = tfidf.fit_transform(train_df['text'])clf = RidgeClassifier()clf.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = clf.predict(train_test[10000:])print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
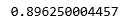
2、 尝试使用其他机器学习模型,完成训练和验证
from sklearn.svm import SVCfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics import f1_scoretfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)train_test = tfidf.fit_transform(train_df['text'])clf = SVC()clf.fit(train_test[:10000], train_df['label'].values[:10000])val_pred = clf.predict(train_test[10000:])print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))

| RidgeClassifier | SVM |
|---|---|
| 0.87193721737 | 0.8761851818808672 |
ngram_range=(1,3), max_features=3000的情况下,两种分类器的精度相差不大。
from sklearn.svm import SVCfrom sklearn.pipeline import Pipelinefrom sklearn.model_selection import ShuffleSplitfrom sklearn.model_selection import GridSearchCVfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.feature_extraction.text import TfidfVectorizerpipe_steps = [ ('tfidf',TfidfVectorizer()), ('svc', SVC())]pipeline = Pipeline(pipe_steps)cv_split = ShuffleSplit(n_splits=5, train_size=0.7)param_grid = { 'tfidf__max_features': (3000, 5000), 'tfidf__ngram_range':((2,2),(1,3)), #'svc__cache_size' : [100, 200, 400], 'svc__C': [1, 10], 'svc__kernel' : ['rbf','linear'],}grid = GridSearchCV(pipeline, param_grid, cv=cv_split)grid.fit(train_df['text'].values[0:10000], train_df['label'].values[0:10000]) 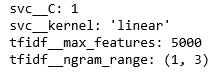
estimator = grid.best_estimator_val_pred1 = estimator.predict(train_df['text'][10000:])print(f1_score(train_df['label'].values[10000:], val_pred1, average='macro'))
| RidgeClassifier | SVM |
|---|---|
| 0.896250004457 | 0.882655808439 |
参考资料:
Datawhale零基础入门NLP赛事 - Task3 基于机器学习的文本分类 h转载地址:https://blog.csdn.net/x___xxxx/article/details/107555143 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
