本文共 4932 字,大约阅读时间需要 16 分钟。
日常工作中,为满足业务需求,要写个多表连接查询SQL,对大多数SQLer来说是很容易的,多表连接查询的语法如下:
select table1.column,table2.columnfrom table1 [inner | left | right | full ] join table2 on table1.column1 = table2.column2;inner join 表示内连接;left join表示左外连接;right join表示右外连接;full join表示完全外连接;on子句 用于指定连接条件。
根据这个语法,运行基本上就查询出需要的数据,如果效率较低,还需要做个语句优化,然后就可以交差的,但是你是否曾经有过疑问呢?
1,on 子句中的连接条件只能使用‘=’吗?除此之外还能不能使用其他比较运算?比如:<、<=、>、>= 2,on 子句其实有着过滤记录的功能,那么on 子句 和 where 子句 又有什么区别? 3,表连接类型有内连接,外链接,那们在数据库中是如何实现关联?一,on 子句中的连接条件只能使用‘=’吗?除此之外还能不能使用其他比较运算?比如:<、<=、>、>=
on 子句 中不仅可以使用等值连接,还是可以使用非等值连接,其实on 子句就是个连接条件,table1 和 table2 中满足这个条件的记录就可以关联起来。平时的实际应用中,表之间更多的是靠主键-外键的形式关联,所以更多的使用等值连接,而且用于关联的字段通常都建立索引,非等值连接中的 <、<=、>、>= 会导致索引失效,影响效率。
例1:匹配每个员工的薪资等级
salgrade 中有每个等级的薪资范围。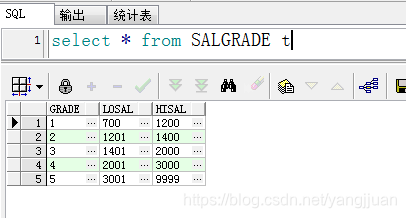
select e.* ,s.grade from EMP eleft join salgrade s on e.sal between s.losal and s.hisal --根据范围划分等级,
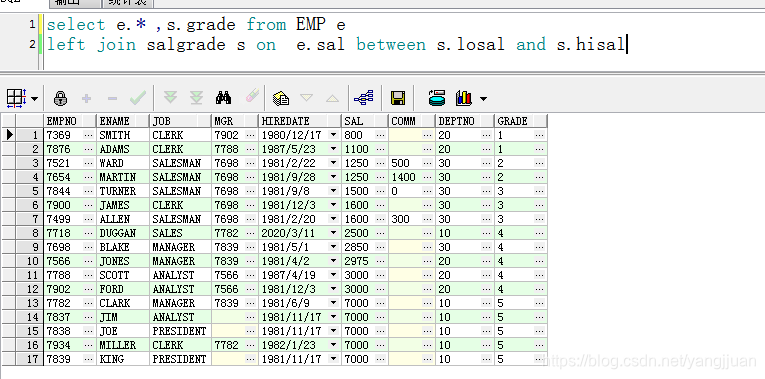
SELECT *FROM scWHERE score = (SELECTt1.scoreFROM sc t1JOIN sc t2 ON t1.score <= t2.score GROUP BY t1.scoreHAVING COUNT(DISTINCT t2.score) = 2) -- 以取第二大的为例子
原理很简单,通过自连接找到大于等于当前记录的记录数n,当 n=k时,则该条记录就是需要查找的第k大值;
可以参考博文:https://blog.csdn.net/yangjjuan/article/details/104905052二,on 子句其实有着过滤记录的功能,那么on 子句 和 where 子句 又有什么区别?
其实SQL和其他编程语言一样,都有自己的一套语法标准,比如SQL89、SQL92、SQL99,每种标准的语法就有所不同,具体大家可以找找看,不过Oracle 好像都支持。
在SQL92多个查询的表在from后边,使用逗号连接查询条件在where后边,多个连接条件使用and连接,并且带上过滤条件,也是说where 子句 承包了连接条件 和 筛选条件。
在SQL92 中的 外连接是如下:不带(+) 的为主表,带(+)为辅助表select * from emp ,dept where emp.deptno=dept.deptno(+) --左外连接select * from emp ,dept where emp.deptno(+) = dept.deptno; --右外连接
在SQL99多个查询表在from中写第一个,后边使用INNER JOIN 加上连接的第一个表名 ,然后ON后边加上前边两个表的连接条件和筛选条件,还可以在where中再增加筛选条件。
在SQL99中的 外连接是如下:select * from emp left join dept on emp.deptno=dept.deptno --左外连接select * from emp right join dept on emp.deptno=dept.deptno --右外连接
当做多表关联,oracle中大概的写法如下:
-- SQL92 易于书写,不容易阅读select 内容 (别名,连接符,去除重读,oracle函数,逻辑运算)from 表名1,表名2,表名3...where 条件(连接条件,普通筛选条件)group by 分组字段having 多行函数筛选order by排序-- SQL99 易于理解,不易书写select 内容 from 表名1,inner join 表名2 on 连接条件left join 表名3 on 连接条件where 普通筛选条件group by 分组条件having 多行函数筛选order by 排序
on 和 where 区别
1,执行顺序,on 在 where 之前,根据 on 中的 关联条件和筛选条件对from 后面的表进行关联产生中间表,然后在根据where子句过滤中间表数据得到最后结果。
2,返回结果,不管on上的条件是否为真都会返回left或right表中的记录,full则具有left和right的特性的并集。 而inner jion没这个特殊性,则条件放在on中和where中,返回的结果集是相同的。 3,速度:因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的。where 和 having 区别
1,使用条件,having只能和group by一起使用,而where 并没有这样的限制。
2,执行顺序,where 在 having 之前执行,过滤筛选结果,然后在执行聚合函数,再经过having过滤。 3,聚合函数,where 子句中没法使用聚合函数,having 中可以使用聚合函数,并且聚合函数在having之前执行。总结
ON、WHERE、HAVING的主要差别是其子句中限制条件起作用时机引起的,**ON是在生产临时表之前根据条件筛选记录,WHERE是从生产的临时表中筛选数据,而HAVING是对临时表中满足条件的数据,进行计算分组之后,通过HAVING限制语句筛选分组,**返回结果是满足HAVING子句限制的分组
三,表连接类型有内连接,外链接,那们在数据库中是如何实现关联?
在编写SQL时,常用到left join 、right join 、join,但是这些连接类型在数据库中是如何实现的呢?可以通过执行计划来查看具体的连接方式。

1,驱动表与匹配表
JOIN 关键字用于将两张表作连接,一次只能连接两张表,JOIN 操作的各步骤一般是串行的(在读取做连接的两张表的数据时可以并行读取),首先读取的是驱动表,然后在根据条件去匹配表中匹配记录。
驱动表(Driving Table): 表连接时首先存取的表,又称外层表(Outer Table),如果驱动表返回较多的行数据,则对所有的后续操作执行效率有所影响,故一般选择小表(应用Where限制条件后返回较少行数的表)作为驱动表。 匹配表(Probed Table): 又称为内层表(Inner Table),从驱动表获取一行具体数据后,再根据连接条件到内层表中查询,所以内层表一般为大表,这样不需要查询整个大表,只需根据条件查询。2,连接方式
表连接的几种方式: CARTESIAN PRODUCT(笛卡尔积) SORT MERGE JOIN(排序-合并连接) NESTED LOOPS(嵌套循环) HASH JOIN(哈希连接)
2.1 CARTESIAN PRODUCT(笛卡尔积)
有如下查询:select a.*,d.* from emp a,dept d
这种连接方式,比较简单粗暴,将emp 中的每条记录都与dept中的每条记录进行关联,假设 emp有n条记录, dept有m条,则最终查询的结果中有n x m 行记录。这种连接方式一般都很少用到,
2.2 SORT MERGE JOIN(排序-合并连接)
以求第K大值为例子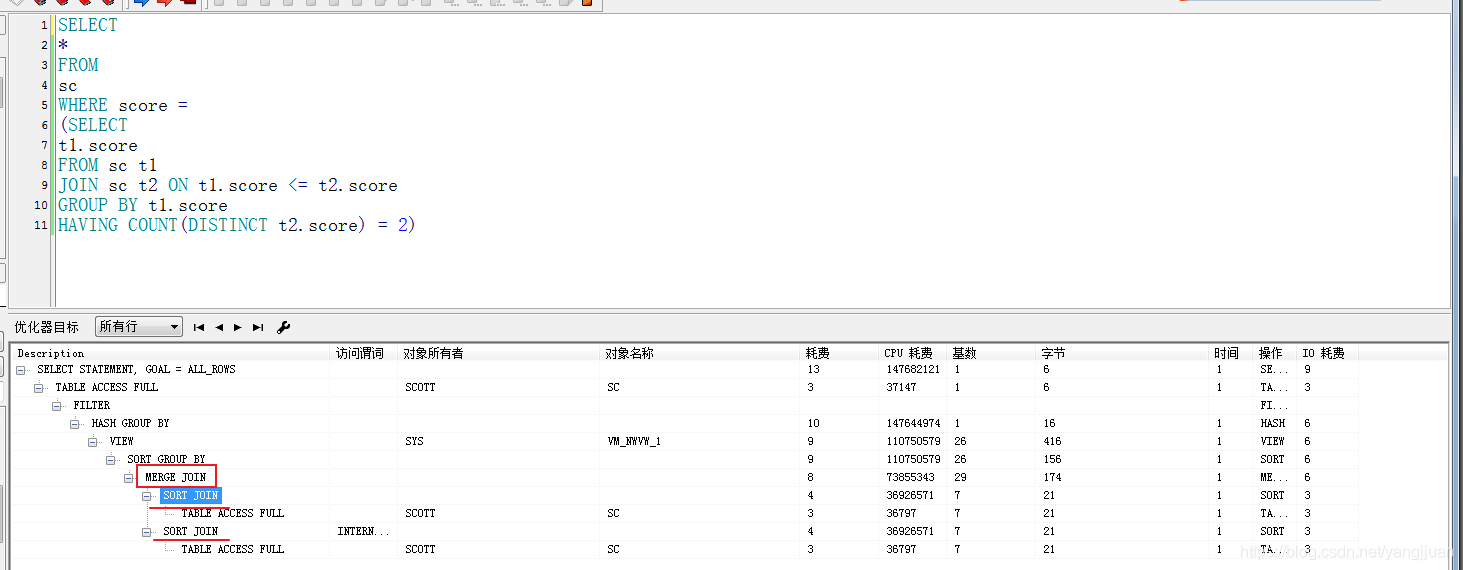 内部连接过程: a) 生成 row source 1 需要的数据,按照连接操作关联列(如示例中的t1.score)对这些数据进行排序 b) 生成 row source 2 需要的数据,按照与 a) 中对应的连接操作关联列(t2.score)对数据进行排序 c) 两边已排序的行放在一起执行合并操作(对两边的数据集进行扫描并判断是否连接)
内部连接过程: a) 生成 row source 1 需要的数据,按照连接操作关联列(如示例中的t1.score)对这些数据进行排序 b) 生成 row source 2 需要的数据,按照与 a) 中对应的连接操作关联列(t2.score)对数据进行排序 c) 两边已排序的行放在一起执行合并操作(对两边的数据集进行扫描并判断是否连接) 延伸:
如果示例中的连接操作关联列t1.score,t2.score之前就已经被排过序了的话,连接速度便可大大提高,因为排序是很费时间和资源的操作,尤其对于有大量数据的表。 故可以考虑在 t1.score,t2.score上建立索引让其能预先排好序。不过遗憾的是,由于返回的结果集中包括所有字段,所以通常的执行计划中,即使连接列存在索引,也不会进入到执行计划中,除非进行一些特定列处理(如仅仅只查询有索引的列等)。 排序-合并连接的表无驱动顺序,谁在前面都可以; 排序-合并连接适用的连接条件有: < <= = > >= ,不适用的连接条件有: <> like2.3 NESTED LOOPS(嵌套循环)
内部连接过程: a) 取出 row source 1 的 row 1(第一行数据),遍历 row source 2 的所有行并检查是否有匹配的,取出匹配的行放入结果集中 b) 取出 row source 1 的 row 2(第二行数据),遍历 row source 2 的所有行并检查是否有匹配的,取出匹配的行放入结果集中 c) …… 若 row source 1 (即驱动表)中返回了 N 行数据,则 row source 2 也相应的会被全表遍历 N 次。 因为 row source 1 的每一行都会去匹配 row source 2 的所有行,所以当 row source 1 返回的行数尽可能少并且能高效访问 row source 2(如建立适当的索引)时,效率较高。延伸:
嵌套循环的表有驱动顺序,注意选择合适的驱动表。 应尽可能使用限制条件(Where过滤条件)使驱动表(row source 1)返回的行数尽可能少,同时在匹配表(row source 2)的连接操作关联列上建立唯一索引(UNIQUE INDEX)或是选择性较好的非唯一索引,此时嵌套循环连接的执行效率会变得很高。若驱动表返回的行数较多,即使匹配表连接操作关联列上存在索引,连接效率也不会很高。2.4 HASH JOIN(哈希连接)
哈希连接只适用于等值连接(即连接条件为 = ) 哈希连接 其实 使用 哈希表查找算法 哈希查找也叫散列查找,整个散列查找过程大概分两步: (1)在存储时通过散列函数计算记录的散列地址,并按此散列地址存储该记录。 (2)当查找时,一样通过散列函数计算记录的散列地址,然后访问散列地址的记录。内部连接过程简述:
a) 取出 row source 1(驱动表,在HASH JOIN中又称为Build Table) 的数据集,然后将其构建成内存中的一个 Hash Table(Hash函数的Hash KEY就是连接操作关联列),创建Hash位图(bitmap)。 b) 取出 row source 2(匹配表)的数据集,对其中的每一条数据的连接操作关联列使用相同的Hash函数并找到对应的 a) 里的数据在 Hash Table 中的位置,在该位置上检查能否找到匹配的数据。补充:
关于连接方式详细内容可以参考 https://www.cnblogs.com/Dreamer-1/p/6076440.html转载地址:https://blog.csdn.net/yangjjuan/article/details/106477306 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
