本文共 14056 字,大约阅读时间需要 46 分钟。
一.spark原理
1.spark和mapReduce的区别
MapReduce 计算模型最大的问题在于,所有操作之间的数据交换都以磁盘为媒介。例如,两个 Map 操作之间的计算,以及 Map 与 Reduce 操作之间的计算都是利用本地磁盘来交换数据的。
spark是两个 Map 操作之间的计算利用本地内存交换数据, Map 与 Reduce 操作之间的计算利用本地磁盘来交换数据的。
2.性能调优的本质

3.RDD:弹性分布式数据集
RDD 作为 Spark 对于分布式数据模型的抽象,是构建 Spark 分布式内存计算引擎的基石。
RDD 的核心特征和属性:
RDD 具有 4 大属性,分别是 partitions、partitioner、dependencies 和 compute 属性。正因为有了这 4 大属性的存在,让 RDD 具有分布式和容错性这两大最突出的特性。
- RDD 的 partitions 属性对应着 RDD 分布式数据实体中所有的数据分片;
- partitioner 属性则定义了划分数据分片的分区规则,如按哈希取模或是按区间划分等。
- RDD 的 dependencies 属性记录了生成 RDD 所需的“数据源”,术语叫做父依赖(或父 RDD);
- compute 方法则封装了从父 RDD 到当前 RDD 转换的计算逻辑。
RDD 的 4 大属性又可以划分为两类,横向属性(partitions、partitioner)和纵向属性(dependencies 、compute)。
- 横向属性 partitions 和 partitioner 锚定数据分片实体,并且规定了数据分片在分布式集群中如何分布;
- 纵向属性 dependencies 和 compute 用于在纵深方向构建 DAG,通过提供重构 RDD 的容错能力保障内存计算的稳定性。

4.DAG与流水线:到底啥叫“内存计算”
Spark 的内存计算都有两层含义:
-
第一层含义:分布式数据缓存:
RDD cache :Spark 允许开发者将分布式数据集缓存到计算节点的内存中,从而对其进行高效的数据访问。 -
第二层含义:Stage 内部的流水线式计算模式
在 Spark 的 DAG 中,顶点是一个个 RDD,边则是 RDD 之间通过 dependencies 属性构成的父子关系。
从开发者的视角出发,DAG 的构建是通过在分布式数据集上不停地调用算子来完成的。 一句话来概括从 DAG 到 Stages 的转化过程,那应该是:以 Actions 算子为起点,从后向前回溯 DAG,以 Shuffle 操作为边界去划分 Stages。流水线计算模式指的是:在同一 Stage 内部,所有算子融合为一个函数,Stage 的输出结果由这个函数一次性作用在输入数据集而产生。
- 总结: 所谓内存计算,不仅仅是指数据可以缓存在内存中,更重要的是让我们明白了,通过计算的融合来大幅提升数据在内存中的转换效率,进而从整体上提升应用的执行性能。
5.Spark调度系统:“数据不动代码动”
Spark 调度系统的核心职责是,先将用户构建的 DAG 转化为分布式任务,结合分布式集群资源的可用性,基于调度规则依序把分布式任务分发到执行器 Executors;
Spark 调度系统的核心原则是,尽可能地让数据呆在原地、保持不动,同时尽可能地把承载计算任务的代码分发到离数据最近的地方(Executors 或计算节点),从而最大限度地降低分布式系统中的网络开销。
Spark 调度系统的工作流程包含如下 5 个步骤:
- 将 DAG 拆分为不同的运行阶段 Stages;
- 创建分布式任务 Tasks 和任务组 TaskSet;
- 获取集群内可用的硬件资源情况;
- 按照调度规则决定优先调度哪些任务 / 组;
- 依序将分布式任务分发到执行器 Executor。
Spark 调度系统包含 3 个核心组件,分别是 DAGScheduler、TaskScheduler 和 SchedulerBackend。这 3 个组件都运行在 Driver 进程中,它们通力合作将用户构建的 DAG 转化为分布式任务,再把这些任务分发给集群中的 Executors 去执行。
调度系统流程中 5 个步骤的对应关系总结在了下表中:
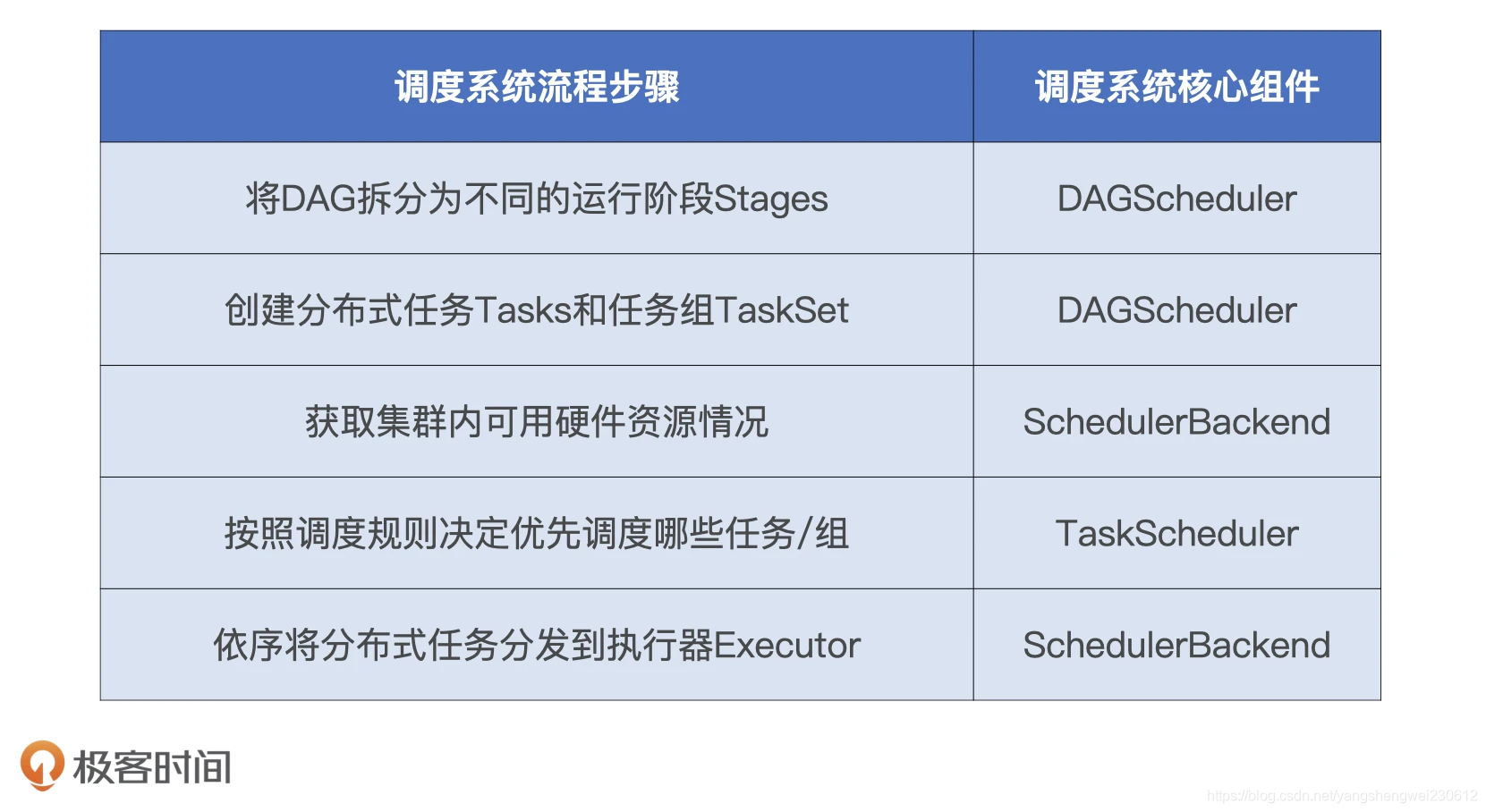
- DAGScheduler DAGScheduler 的主要职责有二:
- 一是把用户 DAG 拆分为 Stages;
- 二是在 Stage 内创建计算任务 Tasks,这些任务囊括了用户通过组合不同算子实现的数据转换逻辑。
- SchedulerBackend
在分发任务之前,调度系统得先判断哪些节点的计算资源空闲,然后再把任务分发过去。调度系统是怎么判断节点是否空闲的呢?
SchedulerBackend 就是用来干这个事的,它是对于资源调度器的封装与抽象,为了支持多样的资源调度模式如 Standalone、YARN 和 Mesos,SchedulerBackend 提供了对应的实现类。在运行时,Spark 根据用户提供的 MasterURL,来决定实例化哪种实现类的对象。MasterURL 就是你通过各种方式指定的资源管理器,如 --master spark://ip:host(Standalone 模式)、–master yarn(YARN 模式)。
- TaskScheduler 左边有需求,右边有供给,如果把 Spark 调度系统看作是一个交易市场的话,那么中间还需要有个中介来帮它们对接意愿、撮合交易,从而最大限度地提升资源配置的效率。在 Spark 调度系统中,这个中介就是 TaskScheduler。TaskScheduler 的职责是,基于既定的规则与策略达成供需双方的匹配与撮合。
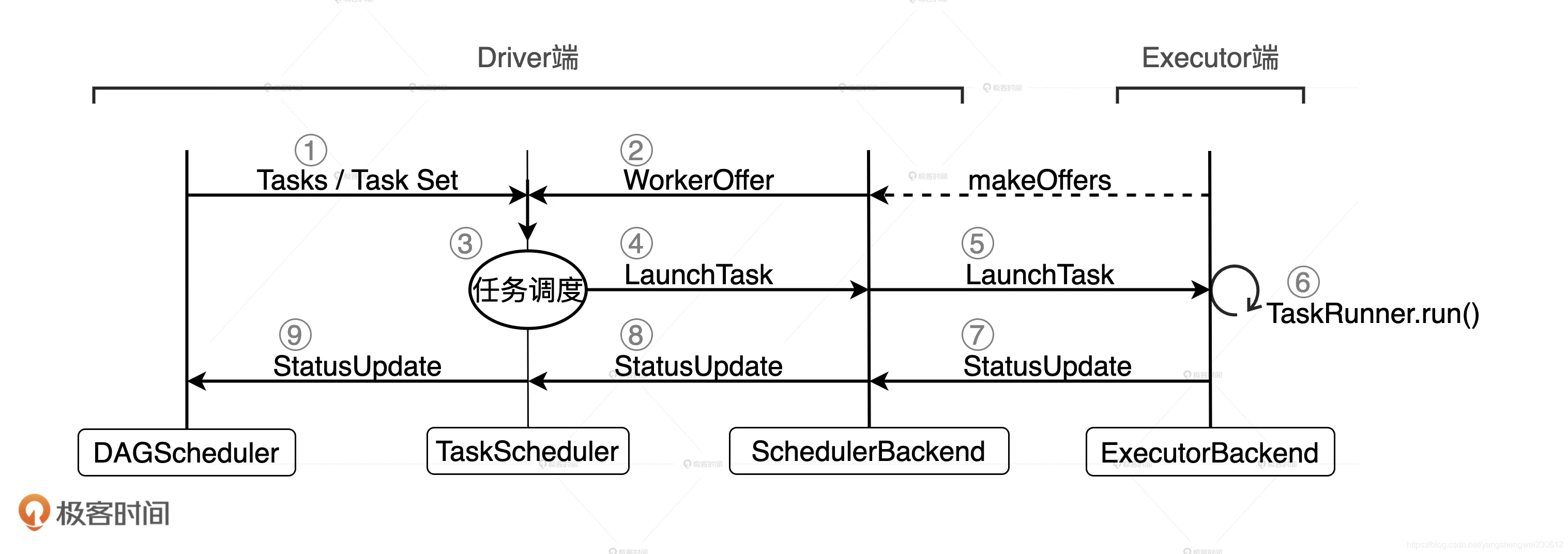
-
不同 Stages 之间的调度优先级:
多个 Stages,如果它们彼此之间不存在依赖关系、互相独立,在面对同一份可用计算资源的时候,它们之间就会存在竞争关系。不同Stages 之间的任务调度,TaskScheduler 提供了 2 种调度模式,分别是 FIFO(先到先得)和 FAIR(公平调度)。 -
同一个 Stages 内部不同任务之间的调度优先级:
Stages 内部的任务调度相对来说简单得多。当 TaskScheduler 接收到来自 SchedulerBackend 的 WorkerOffer 后,TaskScheduler 会优先挑选那些满足本地性级别要求的任务进行分发。众所周知,本地性级别有 4 种:Process local < Node local < Rack local < Any。从左到右分别是进程本地性、节点本地性、机架本地性和跨机架本地性。从左到右,计算任务访问所需数据的效率越来越差。
6.Spark存储系统:空间换时间,还是时间换空间
Spark 存储系统用于存储 3 个方面的数据
Spark 存储系统用于存储 3 个方面的数据,分别是 RDD 缓存、Shuffle 中间文件、广播变量。
这 3 个服务对象是 Spark 应用性能调优的有力“抓手”,而它们又和存储系统有着密切的联系,
1. RDD 缓存
RDD 缓存指的是将 RDD 以缓存的形式物化到内存或磁盘的过程。对于一些计算成本和访问频率都比较高的 RDD 来说,缓存有两个好处:- 一是通过截断 DAG,可以降低失败重试的计算开销;
- 二是通过对缓存内容的访问,可以有效减少从头计算的次数,从整体上提升作业端到端的执行性能。 2. Shuffle 中间文件
Shuffle的计算过程可以分为 2 个阶段:
- Map 阶段:Shuffle writer 按照 Reducer 的分区规则将中间数据写入本地磁盘;
- Reduce 阶段:Shuffle reader 从各个节点下载数据分片,并根据需要进行聚合计算。
Shuffle 中间文件实际上就是 Shuffle Map 阶段的输出结果,这些结果会以文件的形式暂存于本地磁盘。在 Shuffle Reduce 阶段,Reducer 通过网络拉取这些中间文件用于聚合计算,如求和、计数等。
3. 广播变量
在日常开发中,广播变量往往用于在集群范围内分发访问频率较高的小数据。**利用存储系统,广播变量可以在 Executors 进程范畴内保存全量数据。**这样一来,对于同一 Executors 内的所有计算任务,应用就能够以 Process local 的本地性级别,来共享广播变量中携带的全量数据了。
存储系统的两个重要组件:MemoryStore 和 DiskStore
MemoryStore 用来管理数据在内存中的存取,DiskStore 用来管理数据在磁盘中的存取。
广播变量由 MemoryStore 管理,Shuffle 中间文件的落盘和访问要经由 DiskStore,而 RDD 缓存因为会同时支持内存缓存和磁盘缓存两种模式,所以两种组件都有可能用到。
7.内存管理基础:Spark如何高效利用有限的内存空间?
内存的管理模式
在管理方式上,Spark 会区分堆内内存(On-heap Memory)和堆外内存(Off-heap Memory)。这里的“堆”指的是 JVM Heap,因此堆内内存实际上就是 Executor JVM 的堆内存;堆外内存指的是通过 Java Unsafe API,像 C++ 那样直接从操作系统中申请和释放内存空间。
内存区域的划分
堆外内存:
堆外内存有两个天然的优势:一是对于内存占用的估算更精确,二来不需要像 JVM Heap 那样反复执行垃圾回收。
Spark 把堆外内存划分为两块区域:一块用于执行分布式任务,如 Shuffle、Sort 和 Aggregate 等操作,这部分内存叫做 Execution Memory;一块用于缓存 RDD 和广播变量等数据,它被称为 Storage Memory。堆内内存:
堆内内存的划分方式和堆外差不多,Spark 也会划分出用于执行和缓存的两份内存空间。 此外,Spark 在堆内还会划分出一片叫做 User Memory 的内存空间,它用于存储开发者自定义数据结构, 除此之外,Spark 在堆内还会预留出一小部分内存空间,叫做 Reserved Memory,它被用来存储各种 Spark 内部对象,例如存储系统中的 BlockManager、DiskBlockManager 等等。堆内、外内存不同内存区域的划分如图:
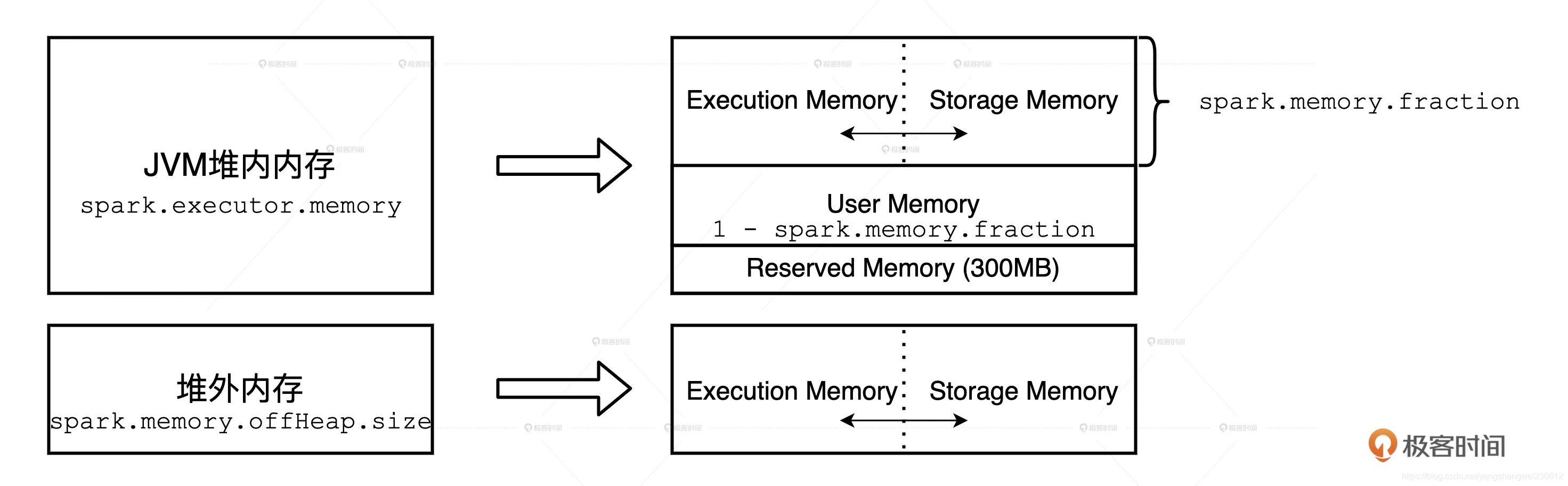 对于性能调优来说, Execution memory、Storage memory 和 User memory这三块内存的利用率上有比较大的发挥空间,因为业务应用主要消耗的就是它们。
对于性能调优来说, Execution memory、Storage memory 和 User memory这三块内存的利用率上有比较大的发挥空间,因为业务应用主要消耗的就是它们。 不同内存区域的划分与计算如下表格:

执行与缓存内存
内存区域中,最重要的无疑是缓存内存和执行内存,而内存计算的两层含义也就是数据集缓存和 Stage 内的流水线计算,对应的就是 Storage Memory 和 Execution Memory。
在 Spark 1.6 版本之前,Execution Memory 和 Storage Memory 内存区域的空间划分是静态的,一旦空间划分完毕,不同内存区域的用途就固定了。
在 1.6 版本之后,Spark 推出了统一内存管理模式。统一内存管理指的是 Execution Memory 和 Storage Memory 之间可以相互转化,尽管两个区域由配置项 spark.memory.storageFraction 划定了初始大小,但在运行时,结合任务负载的实际情况,Storage Memory 区域可能被用于任务执行(如 Shuffle),Execution Memory 区域也有可能存储 RDD 缓存。
Execution Memory 和 Storage Memory 之间的抢占规则,一共可以总结为 3 条:
Execution Memory抢占内存的优先级高于 Storage Memory
- 如果对方的内存空间有空闲,双方就都可以抢占;
- 对于 RDD 缓存任务抢占的执行内存,当执行任务有内存需要时,RDD 缓存任务必须立即归还抢占的内存,涉及的 RDD 缓存数据要么落盘、要么清除;
- 对于分布式计算任务抢占的 Storage Memory 内存空间,即便 RDD 缓存任务有收回内存的需要,也要等到任务执行完毕才能释放。
代码看内存消耗
val dict: List[String] = List(“spark”, “scala”)val words: RDD[String] = sparkContext.textFile(“~/words.csv”)val keywords: RDD[String] = words.filter(word => dict.contains(word))keywords.cachekeywords.countkeywords.map((_, 1)).reduceByKey(_ + _).collect
不同代码与其消耗的内存区域,我都整理到了下面的表格如下:

二.通用性能调优
8.应用代码开发三原则
原则一:利用 Spark 为我们提供的“性能红利”
通过设置相关的配置项,或是调用相应的 API 去充分享用 Spark 自身带来的性能优势。
充分利用 Spark 为我们提供的“性能红利”,如钨丝计划、AQE、SQL functions 等等- 钨丝计划: 钨丝计划可以通过对数据模型与算法的优化,把 Spark 应用程序的执行性能提升一个数量级吗,官方显示执行性能可以提升 16 倍。
- 在数据结构方面,Tungsten 自定义了紧凑的二进制格式。
- Tungsten 利用 Java Unsafe API 开辟堆外(Off Heap Memory)内存来管理对象。
如何利用钨丝计划: 想要利用好 Tungsten 的优势,只要抛弃 RDD API,采用 DataFrame 或是 Dataset API 进行开发就可了
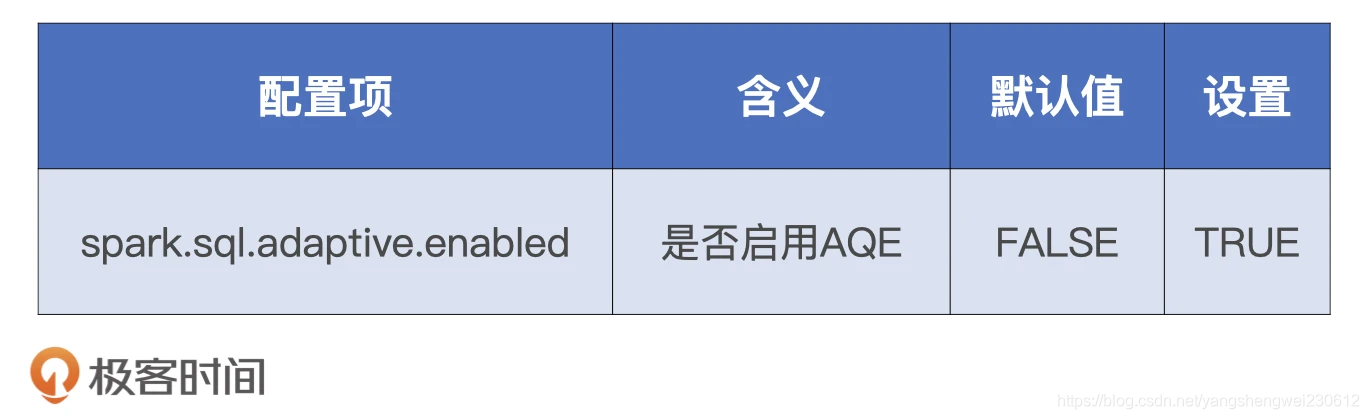
- AQE( Spark 3.0 版本发布的新特性——AQE Adaptive Query Execution)全称“自适应查询执行”
AQE 可以让 Spark 在运行时的不同阶段,结合实时的运行时状态,周期性地动态调整前面的逻辑计划,然后根据再优化的逻辑计划,重新选定最优的物理计划,从而调整运行时后续阶段的执行方式。
开启AQE优势:
自动分区合并、数据倾斜和 Join 策略调整。
如何开启AQE
AQE 功能默认是关闭的,如果我们想要充分利用自动分区合并、自动数据倾斜处理和 Join 策略调整,需要把相关的配置项打开
SQL functions
除A钨丝计划和AQE之外,类似的技巧还有用 SQL functions 或特征转换算子去取代 UDF 等等。
原则二:数据能省则省、shuffle能拖则拖
实现起来我们可以分 3 步进行:
- 尽量把能节省数据扫描量和数据处理量的操作往前推;
- 尽力消灭掉 Shuffle,省去数据落盘与分发的开销;
- 如果不能干掉 Shuffle,尽可能地把涉及 Shuffle 的操作拖到最后去执行。
原则三:避免单机思维模式代码
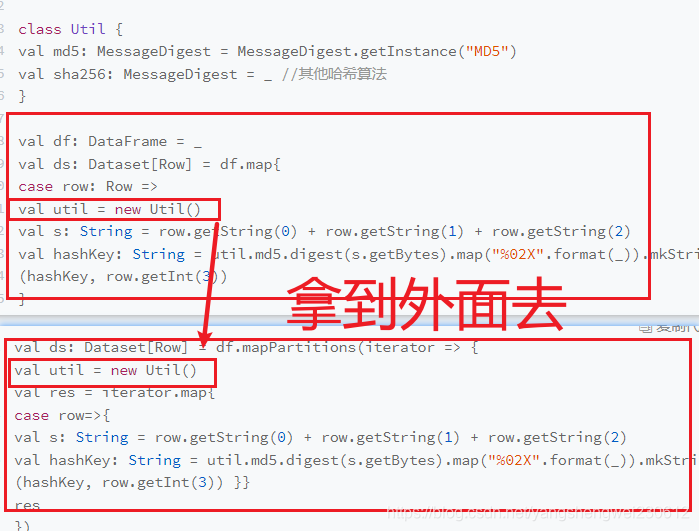
9.配置项速查手册
重要名词:
并行度:
并行度指的是分布式数据集被划分为多少份,从而用于分布式计算。 并行度决定了数据粒度,数据粒度决定了分区大小,分区大小则决定着每个计算任务的内存消耗。 在同一个 Executor 中,多个同时运行的计算任务“基本上”是平均瓜分可用内存的,每个计算任务能获取到的内存空间是有上限的,因此并行计算任务数会反过来制约并行度的设置。并行计算任务数:
集群中可以同时运行的任务数。 单个Executor 中并行计算任务数的上限= spark.executor.cores * spark.task.cpus 集群并行计算任务数的上限= Executors的数量 * spark.executor.cores * spark.task.cpus
自动数据倾斜处理有关配置项

与 Join 策略调整有关配置项

 AQE 的 Join 策略调整是一种动态优化机制,对于刚才的两张大表,AQE 会在数据表完成过滤操作之后动态计算剩余数据量,当数据量满足广播条件时,AQE 会重新调整逻辑执行计划,在新的逻辑计划中把 Shuffle Joins 降级为 Broadcast Join。再者,运行时的数据量估算要比编译时准确得多,因此 AQE 的动态 Join 策略调整相比静态优化会更可靠、更稳定。
AQE 的 Join 策略调整是一种动态优化机制,对于刚才的两张大表,AQE 会在数据表完成过滤操作之后动态计算剩余数据量,当数据量满足广播条件时,AQE 会重新调整逻辑执行计划,在新的逻辑计划中把 Shuffle Joins 降级为 Broadcast Join。再者,运行时的数据量估算要比编译时准确得多,因此 AQE 的动态 Join 策略调整相比静态优化会更可靠、更稳定。 启用动态 Join 策略调整还有个前提,也就是要满足 nonEmptyPartitionRatioForBroadcastJoin 参数的限制。这个参数的默认值是 0.2,大表过滤之后,非空的数据分区占比要小于 0.2,才能成功触发 Broadcast Join 降级。
举个例子。假设,大表过滤之前有 100 个分区,Filter 操作之后,有 85 个分区内的数据因为不满足过滤条件,在过滤之后都变成了没有任何数据的空分区,另外的 15 个分区还保留着满足过滤条件的数据。这样一来,这张大表过滤之后的非空分区占比是 15 / 100 = 15%,因为 15% 小于 0.2,所以这个例子中的大表会成功触发 Broadcast Join 降级。
如果大表过滤之后,非空分区占比大于 0.2,那么剩余数据量再小,AQE 也不会把 Shuffle Joins 降级为 Broadcast Join。因此,如果你想要充分利用 Broadcast Join 的优势,可以考虑把这个参数适当调高。
12.广播变量(一):克制Shuffle
普通广播变量
广播变量封装的是 Driver 端创建的普通变量:字符串列表
val dict = List(“spark”, “tune”)//声名广播变量val bc = spark.sparkContext.broadcast(dict)val words = spark.sparkContext.textFile(“~/words.csv”)val keywords = words.filter(word => bc.value.contains(word))keywords.map((_, 1)).reduceByKey(_ + _).collect
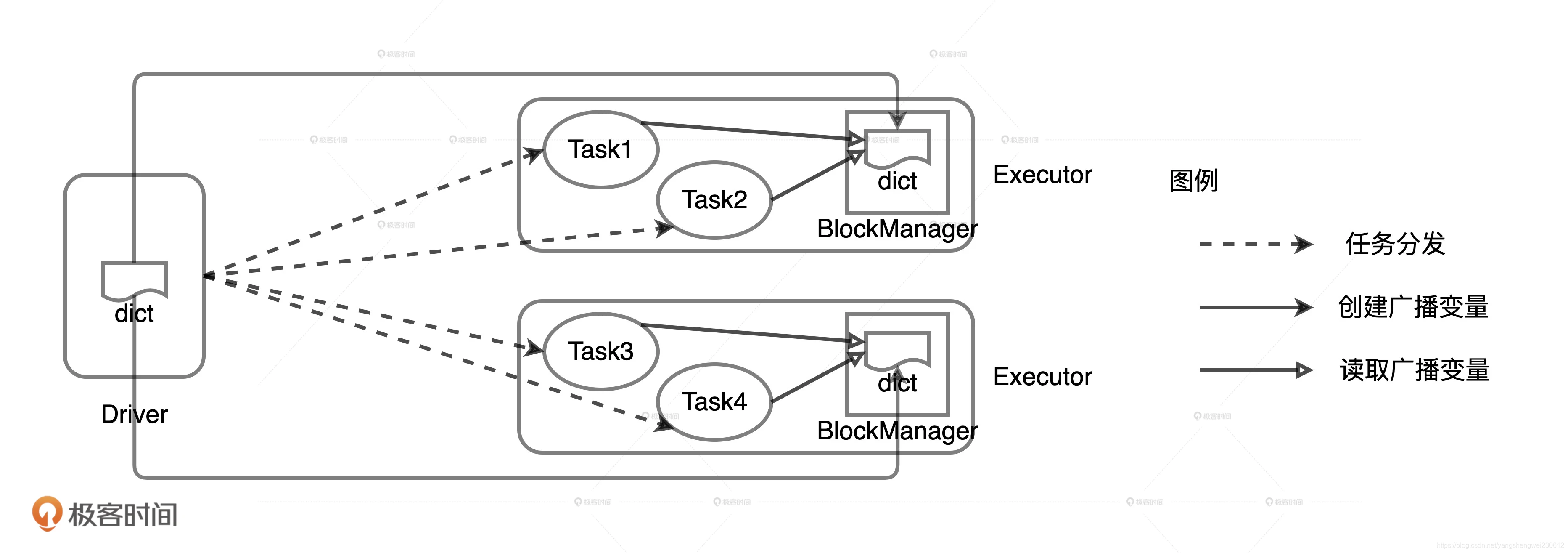
在广播变量的运行机制下,封装成广播变量的数据,由 Driver 端以 Executors 为粒度分发,每一个 Executors 接收到广播变量之后,将其交给 BlockManager 管理。
分布式广播变量
广播变量也可以封装分布式数据集
以 Parquet 文件格式存储在 HDFS 文件系统中,业务部门需要我们读取用户数据并创建广播变量
val userFile: String = “hdfs://ip:port/rootDir/userData”val df: DataFrame = spark.read.parquet(userFile)val bc_df: Broadcast[DataFrame] = spark.sparkContext.broadcast(df)
从普通变量创建广播变量,由于数据源就在 Driver 端,因此,只需要 Driver 把数据分发到各个 Executors,再让 Executors 把数据缓存到 BlockManager 就好了。但是,从分布式数据集创建广播变量就要复杂多了,具体的过程如下图所示。
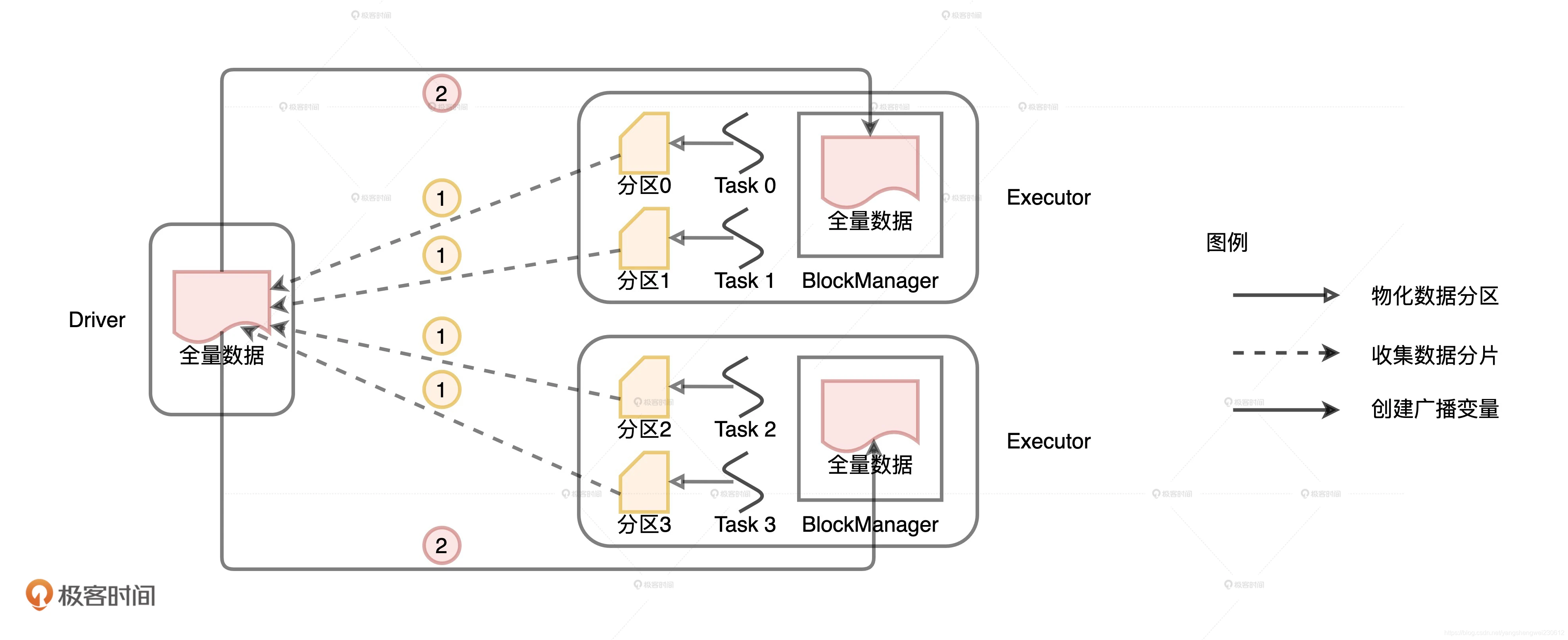 与普通变量相比,分布式数据集的数据源不在 Driver 端,而是来自所有的 Executors。Executors 中的每个分布式任务负责生产全量数据集的一部分,也就是图中不同的数据分区。因此,步骤 1 就是 Driver 从所有的 Executors 拉取这些数据分区,然后在本地构建全量数据。步骤 2 与从普通变量创建广播变量的过程类似。 Driver 把汇总好的全量数据分发给各个 Executors,Executors 将接收到的全量数据缓存到存储系统的 BlockManager 中。
与普通变量相比,分布式数据集的数据源不在 Driver 端,而是来自所有的 Executors。Executors 中的每个分布式任务负责生产全量数据集的一部分,也就是图中不同的数据分区。因此,步骤 1 就是 Driver 从所有的 Executors 拉取这些数据分区,然后在本地构建全量数据。步骤 2 与从普通变量创建广播变量的过程类似。 Driver 把汇总好的全量数据分发给各个 Executors,Executors 将接收到的全量数据缓存到存储系统的 BlockManager 中。 使用广播变量克制 Shuffle
在做数据关联的时候,把 Shuffle Joins 转换为 Broadcast Joins,就可以用小表广播来代替大表的全网分发,真正做到克制 Shuffle。
13.广播变量(二):如何让Spark SQL选择Broadcast Joins
以广播阈值配置为主、强制广播为辅
利用配置项强制广播

它的含义是,对于参与 Join 的两张表来说,任意一张表的尺寸小于 10MB,Spark 就在运行时采用 Broadcast Joins 的实现方式去做数据关联。另外,AQE 在运行时尝试动态调整 Join 策略时,也是基于这个参数来判定过滤后的数据表是否足够小,从而把原本的 Shuffle Joins 调整为 Broadcast Joins。
想要有效地利用 Broadcast Joins,我们需要把参数值调大,一般来说,2GB 左右是个不错的选择。
一份数据要注意磁盘存储数据大小要小于在内存中的大小
准确地预估一张表在内存中的存储大小
使用广播阈值配置项让 Spark 优先选择 Broadcast Joins 的关键,就是要确保至少有一张表的存储尺寸小于广播阈值。
Spark 内置的 SizeEstimator 去预估分布式数据集的存储大小,SizeEstimator 的估算结果是存储在磁盘中表的大小,不是内存中表的大小所以不准确。
推荐方法:第一步,把要预估大小的数据表缓存到内存,比如直接在 DataFrame 或是 Dataset 上调用 cache 方法;第二步,读取 Spark SQL 执行计划的统计数据。这是因为,Spark SQL 在运行时,就是靠这些统计数据来制定和调整执行策略的。
val df: DataFrame = _df.cache.count val plan = df.queryExecution.logicalval estimated: BigInt = spark.sessionState.executePlan(plan).optimizedPlan.stats.sizeInBytes
利用 API 强制广播
可以使用Join Hints 或是 SQL functions 中的 broadcast 函数,来强制 Spark SQL 在运行时采用 Broadcast Joins 的方式做数据关联。这两种方式是等价的,并无优劣之分。
用 Join Hints 强制广播
例子,假设有两张表,一张表的内存大小在 100GB 量级,另一张小一些,2GB 左右。在广播阈值被设置为 2GB 的情况下,并没有触发 Broadcast Joins,但我们又不想花费时间和精力去精确计算小表的内存占用到底是多大。在这种情况下,我们就可以用 Join Hints 来帮我们做优化,仅仅几句提示就可以帮我们达到目的。
val table1: DataFrame = spark.read.parquet(path1)val table2: DataFrame = spark.read.parquet(path2)table1.createOrReplaceTempView("t1")table2.createOrReplaceTempView("t2") val query: String = “select /*+ broadcast(t2) */ * from t1 inner join t2 on t1.key = t2.key”val queryResutls: DataFrame = spark.sql(query) 只要在 SQL 结构化查询语句里面加上一句/*+ broadcast(t2) */提示,我们就可以强制 Spark SQL 对小表 t2 进行广播,在运行时选择 Broadcast Joins 的实现方式。提示语句中的关键字,除了使用 broadcast 外,我们还可以用 broadcastjoin 或者 mapjoin,它们实现的效果都一样。
也可以在 DataFrame 的 DSL 语法中使用 Join Hints。
table1.join(table2.hint(“broadcast”), Seq(“key”), “inner”)
不过,Join Hints 也有个小缺陷。如果关键字拼写错误,Spark SQL 在运行时并不会显示地抛出异常,而是默默地忽略掉拼写错误的 hints,假装它压根不存在。因此,在使用 Join Hints 的时候,需要我们在编译时自行确认 Debug 和纠错。
用 broadcast 函数强制广播
如果你不想等到运行时才发现问题,想让编译器帮你检查类似的拼写错误,那么你可以使用强制广播的第二种方式:broadcast 函数。
import org.apache.spark.sql.functions.broadcasttable1.join(broadcast(table2), Seq(“key”), “inner”)
14.CPU视角:如何高效地利用CPU?
Spark 中 CPU 与内存的平衡,其实就是 CPU 与执行内存之间的协同与配比。
在同一个 Executor 中,当有多个(记为 N)线程尝试抢占执行内存时,需要遵循 2 条基本原则:
- 执行内存总大小(记为 M)为两部分之和,一部分是 Execution Memory 初始大小,另一部分是 Storage Memory 剩余空间
- 每个线程分到的可用内存有一定的上下限,下限是 M/N/2,上限是 M/N,也就是均值
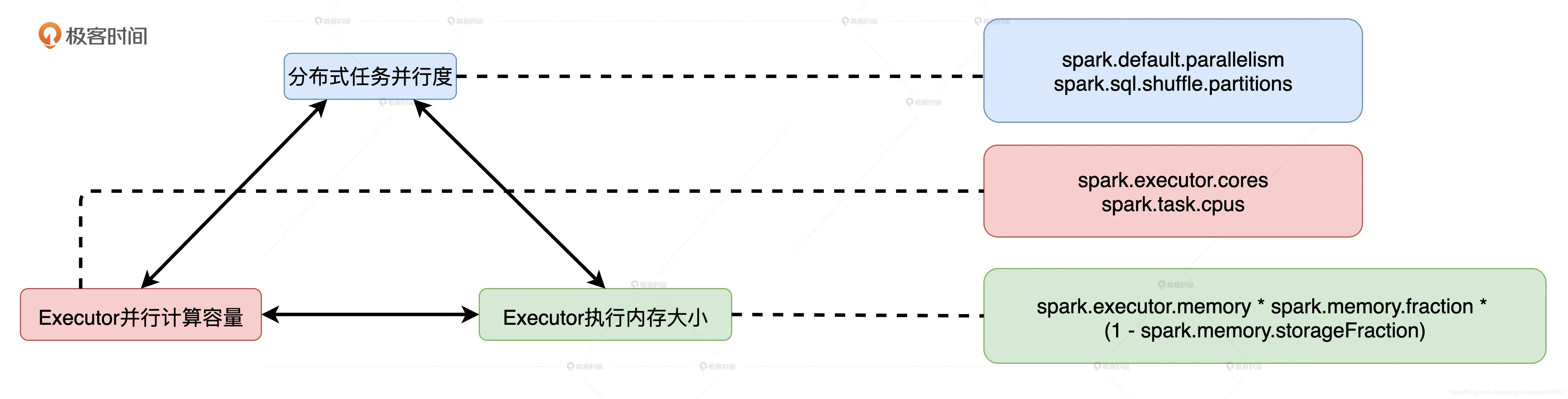
并行度、并发度与执行内存之间的协同与配比
并行度:
并行度指的是为了实现分布式计算,分布式数据集被划分出来的份数。并行度明确了数据划分的粒度:并行度越高,数据的粒度越细,数据分片越多,数据越分散。并行度可以通过两个参数来设置,分别是 spark.default.parallelism 和 spark.sql.shuffle.partitions。前者用于设置 RDD 的默认并行度,后者在 Spark SQL 开发框架下,指定了 Shuffle Reduce 阶段默认的并行度。
并发度:
并发度是同一时间内,一个 Executor 内部可以同时运行的最大任务数量。又因为,spark.task.cpus 默认数值为 1,并且通常不需要调整,所以,并发度基本由 spark.executor.cores 参数敲定。
内存:
分布式任务由 Driver 分发到 Executor 后,Executor 将 Task 封装为 TaskRunner,然后将其交给可回收缓存线程池(newCachedThreadPool)。线程池中的线程领取到 TaskRunner 之后,向 Execution Memory 申请内存,然后开始执行任务。
执行内存,堆内执行内存的初始值由很多参数共同决定,具体的计算公式是:spark.executor.memory * spark.memory.fraction * (1 - spark.memory.storageFraction) 。
相比之下,堆外执行内存的计算稍微简单一些:spark.memory.offHeap.size * (1 - spark.memory.storageFraction) 。可分配的执行内存总量会随着缓存任务和执行任务的此消彼长,而动态变化。但无论怎么变,可用的执行内存总量,都不会低于配置项设定的初始值。
CPU 低效原因之一:线程挂起
线程挂起原因:在给定线程池大小和执行内存的时候,并行度较低、数据分片较大容易导致 CPU 线程挂起,线程频繁挂起不利于提升 CPU 利用率
Spark 用 HashMap 数据结构,以(Key,Value)的方式来记录每个线程消耗的内存大小,并确保所有的 Value 值都不超过 M/N。在一些极端情况下,有些线程申请不到所需的内存空间,能拿到的内存合计还不到 M/N/2。这个时候,Spark 就会把线程挂起,直到其他线程释放了足够的内存空间为止。
线程连 M/N/2 的内存都拿不到原因:
- 动态变化的执行内存总量 M
- 动态变化的并发度 N~
- 分布式数据集的数据分布
如果分布式数据集的并行度设置得当,因任务调度滞后而导致的线程挂起问题就会得到缓解。
CPU 低效原因之二:调度开销
线程挂起的问题得到缓解,CPU 利用率就会有所改善。既然如此,是不是把并行度设置到最大,每个数据分片就都能足够小,小到每个 CPU 线程都能申请到内存,线程不再挂起就万事大吉了呢?
当然不是,并行度足够大,确实会让数据分片更分散、数据粒度更细,因此,每个执行任务所需消耗的内存更少。但是,数据过于分散会带来严重的副作用:调度开销骤增。
数据过于分散,分布式任务数量会大幅增加,但每个任务需要处理的数据量却少之又少,就 CPU 消耗来说,相比花在数据处理上的比例,任务调度上的开销几乎与之分庭抗礼。显然,在这种情况下,CPU 的有效利用率也是极低的。
如何优化 CPU 利用率?
并行度低了不行,容易让 CPU 线程挂起;高了也不行,调度开销太大,CPU 有效利用率也不高。
在给定执行内存 M、线程池大小 N 和数据总量 D 的时候,想要有效地提升 CPU 利用率,我们就要计算出最佳并行度 P,计算方法是让数据分片的平均大小 D/P 坐落在(M/N/2, M/N)区间。这样,在运行时,我们的 CPU 利用率往往不会太差。
M、N是针对Executor的,也就是Executor的执行内存M、并发度大小N。
D和P不一样,它指的是你的分布式数据集,D是数据总量,比如20GB;而P指的是这份数据集的并行度,比如200,那么你的每个数据分片的大小D/P,就是20GB/200 = 100MB。
如果你的M是2GB,也就是2GB的执行内存,N是20,也就是20个线程,那么这个时候,M/N就是100MB。那么,你的D/P就刚好坐落在(M/N/2, M/N)这个区间里。
对 CPU 利用率来说,并行度、并发度与执行内存的关系就好像是一尊盛满沸水的三足鼎,三足齐平则万事大吉,但凡哪一方瘸腿儿,鼎内的沸水就会倾出伤及无辜。
示例
1. 给定cpu和内存资源,计算数据分片大小
假设给定:executor memory为9G,executor的off heap memory也为9G,executor cores为5个,executor instances为30个。数据分片的大小就应该在(9G+9G)/5/2=1.8G到(9G+9G)/5=3.6,即数据分片在(1.8G,3.6G)的范围内
在Spark UI里,找到第一个读取parquet的任务,看shuffle read size这个指标,如果在(1.8G,3.6G)这个区间之内,说明就是可以的
2.给定数据分片大小计算cpu 和内存资源大小
以上根据给定cpu和内存资源,计算数据分片大小为(1.8G,3.6G)确实太大了,一般分片大小在200MB左右,是比较合适的,推荐把分片大小设定在这个范围。 如果用200MB分片大小反推过来的话,其实你可以考虑降低Executors的内存配置,或是提高它的CPU cores配置,这样把内存与CPU做到一个均衡配比,相比现在一个task要处理3GB的数据,效果要更好。假设数据分片大小为200M(0.2GB),数据总量为20G, 根据,数据分片=总是的数据量 / 并行度,计算 并行度= 100,
(M/N/2+M/N)/2=0.2 => M/N = 2/30 根据这比例来调整单个Executor 并发度和单个Executor的执行内存
15. 内存视角(一):如何最大化内存的使用效率
转载地址:https://blog.csdn.net/yangshengwei230612/article/details/117947766 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
