本文共 15900 字,大约阅读时间需要 53 分钟。
java表达式
最基本的组成单元,各种表达式是Java程序员最司空见惯的内容, 只是在这些简单用法背后,依然有一些很容易让人出错的陷阱。 1. 字符串
String java = new String("疯狂Java");
上面语句实际上创建了 2个字符串对象,一个是“疯狂Java”这个直接量对应的字符串对象,一个是由new String()构造器返回的字符串对象。
Java程序中创建对象的常见方式有如下4种:
- 通过new调用构造器创建Java对象。
- 通过Class对象的newInstance()方法调用构造器创建Java对象。
- 通过Java的反序列化机制从IO流中恢复Java对象。
- 通过Java对象提供的clone()方法复制一个新的Java对象。
- 除此之外,对于字符串以及Byte、Short、Integer、Long、Character、Float、Double和Boolean这些基本类型的包装类,Java还允许以直接量的方式来创建Java对象,例如如下语句所示。 String str = “abc”; Integer in = 5; 除此之外,也可通过简单的算法表达式、连接运算来创建Java对象,例如如下语句所示。 String str2 = “abc” + “xyz”; Long price = 23 + 12;
System提供的identityHashCode()静态方法用于获取某个对象唯一的hashCode值,这个identityHashCode()的返回值与该类是否重写了hashCode()方法无关。只有当两个对象相同时,它们的identityHashCode值才会相等。
对于String类而言,它代表字符串序列不可改变的字符串,因此如果程序需要一个字符序列会发生改变的字符串,那应该考虑使用StringBuilder或StringBuffer。很多资料上都推荐使用StringBuffer,那是因为这些资料都是JDK1.5问世之前的——过时了。
实际上通常应该优先考虑使用StringBuilder。StringBuilder与StringBuffer唯一的区别在于,StringBuffer是线程安全的,也就是说StringBuffer类里绝大部分方法都增加了synchronized修饰符。对方法增加synchronized修饰符可以保证该方法线程安全,但会降低该方法的执行效率。在没有多线程的环境下,应该优先使用StringBuilder类来表示字符串。
2. 表达式类型的陷阱
Java语言规定:当一个算术表达式中包含多个基本类型的值时,整个算术表达式的数据类型将发生自动提升。Java语言中的自动提升规则如下。
- 所有byte型、short型和char型将被提升到int型。
- 整个算术表达式的数据类型自动提升到与表达式中最高等级操作数同样的类型。操作数的等级排列如图5.4所示,
位于箭头右边的等级高于箭头左边类型的等级。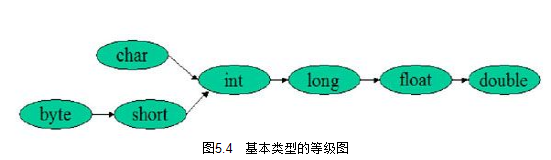
short sValue = 5; sValue = sValue - 2; //一个int类型的值赋给short类型的变量(sValue)时导致了编译错误short sValue = 5;sValue -= 2; //正常
Java语言几乎允许所有的双目运算符和=一起结合成符合赋值运算符,如+=、-=、*=、/=、%=、<<=、>>=、>>>=、&=、^=和|=等。根据Java语言规范,复合赋值运算符包含了一个隐式的类型转换,也就是说,下面两条语句并不等价。
a = a + 5;a += 5;
实际上,a += 5等价于a = (a的类型)(a + 5);,这就是复合赋值运算符中包含的隐式类型转换。
也就是说,复合赋值运算符会自动地将它计算的结果值强制类型转换为其左侧变量的类型。如果结果的类型与该变量的类型相同,那么这个转型不会造成任何影响。 如果结果值的类型比该变量的类型要大,那么复合赋值运算符将会执行一次强制类型转换,这个强制类型转换将有可能导致高位“截断”。
3.输入法导致的陷阱
小心把输入法切换到了全角状态 编译该程序将会提示“非法字符:\12288”的错误。
4. 注解
大部分时候,Java编译器会直接忽略到注释部分,但有一种情况例外:Java要求注释部分的所有字符必须是合法的字符。
Java程序并没有完全忽略注释部分的内容。编译器在上面程序的粗体字部分检测到一个非法字符,Java程序允许直接使用\uXXXX的形式代表字符,它要求\u后面的4个字符必须是0~F字符,而上面注释中包含了\unit5,这不符合Java对Unicode转义字符的要求。5. 转义字符的陷阱
学习过《疯狂Java讲义》的读者应该还记得,Java程序提供了3种方式来表示字符:
- 直接使用单引号括起来的字符值,如’a’;
- 使用转义字符,如’\n’;
- 使用Unicode转义字符,如’\u0062’。
Java对待Unicode转义字符时不会进行任何处理,它会将Unicode转义字符直接替换成对应的字符,这将给Java程序带来一些潜在的陷阱。
6.慎用字符的Unicode转义形式
理论上,Unicode转义字符可以代表任何字符(不考虑那些不在Unicode码表内的字符),因此很容易想到:所有字符都应该可以使用Unicode转义字符的形式。
System.out.println("abc\u000a".length()); 上面程序试图计算“abc\u000a”字符串的长度,表面上看这个程序将输出4,但编译该程序将发现程序无法通过编译,
引起这个编译错误的原因是Java对Unicode转义字符不会进行任何特殊的处理,它只是简单地将Unicode转义字符替换成相应的字符。对于\u000a而言,它相当于一个换行符(相当于\n),因此对Java编译器而言,上面程序相当于如下程序。System.out.println("abc ".length()); 7. 中止行注释的转义字符
//\u000a代表一个换行符 char c = 0x000a;
ava编译器会将程序中的\u000a替换成换行符
8. 泛型可能引起的错误
泛型是JDK 1.5新增的知识点,它允许在使用Java类、调用方法时传入一个类型实参,这样就可以让Java类、调用方法动态地改变类型。
原始类型变量的赋值
在严格的泛型程序中,使用带泛型声明的类时应该总是为之指定类型实参,但为了与老的Java代码保持一致,Java也允许使用带泛型声明的类时不指定类型参数。如果使用带泛型声明的类时没有传入类型实参,那么这个类型参数默认是声明该参数时指定的第一个上限类型,这个类型参数也被称为raw type(原始类型)。
当尝试把原始类型的变量赋给带泛型类型的变量时,会发生一些有趣的事情。示例如下。
public class RawTypeTest { public static void main(String[] args) { //创建一个RawType的List集合 List list = new ArrayList(); //为该集合添加3个元素 list.add("疯狂Java讲义"); list.add("轻量级Java EE企业应用实战"); list.add("疯狂Ajax讲义"); //将原始类型的list集合赋给带泛型声明的List集合 List intList = list; //遍历intList集合的每个元素 for (int i = 0 ; i < intList.size() ; i++) { System.out.println(intList.get(i)); } } } 上面程序中先定义了一个不带泛型信息List集合,其中所有集合元素都是String类型。接着,尝试将该List集合赋给一个List<Integer>变量
尝试编译上面程序,一切正常,可以通过编译;尝试运行上面程序,也可以正常输出intList集合的3个元素:它们都是普通字符串。
通过上面介绍可以看出当程序把一个原始类型的变量赋给一个带泛型信息的变量时,只要它们的类型保持兼容——例如将List变量赋给List,无论List集合里实际包含什么类型的元素,系统都不会有任何问题。
不过需要指出的是,当把一个原始类型的变量(如List变量)赋给带泛型信息的变量(如List)时会有一个潜在的问题:JVM会把集合里盛装的所有元素都当做Integer来处理。上面程序遍历List<Integer>集合时,只是简单地输出每个集合元素,并未涉及集合元素的类型,因此程序并没有出现异常;否则,程序要么在运行时出现ClassCastException,要么在编译时提示编译错误。
- 当程序把一个原始类型的变量赋给一个带泛型信息的变量时,
总是可以通过编译——只是会提示一些警告信息; - 当程序试图访问带泛型声明的集合的集合元素时,编译器总是把集合元素当成泛型类型处理——它并不关心集合里集合元素实际类型;
- 当程序试图访问带泛型声明的集合的集合元素时,JVM会遍历每个集合元素
自动执行强制转型,如果集合元素的实际类型与集合所带的泛型信息不匹配,运行时将引发ClassCastException。
原始类型带来的擦除
当把一个具有泛型信息的对象赋给另一个没有泛型信息的变量时,所有在尖括号之间的类型信息都将被丢弃。比如,将一个List类型的对象转型为List,则该List对集合元素的类型检查变成了类型变量的上限(即Object)。下面程序示范了这种擦除。
class Apple{ T size; public Apple() { } public Apple(T size) { this.size = size; } public void setSize (T size) { this.size = size; } public T getSize() { return this.size; } public List getApples() { List list = new ArrayList (); for (int i = 0; i < 3 ; i++ ) { list.add(new Apple (10 * i).toString()); } return list; } } public class ErasureTest { public static void main(String[] args) { Apple a = new Apple (6); //① //a 的getSize方法返回Integer对象 Integer as = a.getSize(); //把a对象赋给Apple变量,会丢失尖括号里的类型信息 Apple b = a; //② //b 只知道size的类型是Number Number size1 = b.getSize(); //下面代码将引起编译错误 Integer size2 = b.getSize(); //③ // for (String apple : a. getApples() ) { System.out.println(apple); } //将a变量赋给一个没有泛型声明的变量 //系统将擦除所有泛型信息,也就是擦除所有尖括号里的信息 //也就是说,b对象调用getAppleSizes()方法不再返回List //而是返回List for (String apple : b.getApples()) //② { System.out.println(apple); } } }
上面程序里定义了一个带泛型声明的Apple类,其类型形参的上限是Number,这个类型形参用来定义Apple类的size属性。程序在①处创建了一个Apple对象,该Apple对象传入了 Integer作为类型实参,所以调用a的getSize()方法时返回Integer类型的值。
不带泛型信息的b变量时,编译器就会丢失a对象的泛型信息,即所有尖括号里的信息都被丢失;但因为Apple的类型形参的上限是Number类,所以编译器依然知道b的getSize方法返回Number类型,但具体是Number的哪个子类就不清楚了。 从上面程序可以看出,当把一个带泛型信息的Java对象赋给不带泛型信息的变量时,Java程序会发生擦除,这种擦除不仅会擦除使用该Java类时传入的类型实参,而且会擦除所有的泛型信息,也就是擦除所有尖括号里的信息。
它提供了一个getApples()方法,该方法的返回类型是List,该方法的返回值带有泛型信息。
包括getApples()方法的返回值类型List<String>里的尖括号信息。因此,b.getApples()代码处遍历getApples()方法时将提示“不兼容的类型”编译错误。 9. 创建泛型数组的陷阱
DK虽然支持泛型,但不允许创建泛型数组。假设Java能支持创建List<String>[] lsa = new List<String>[10]; 这样的泛型数组对象
//下面代码实际上是不被允许的 List[] lsa = new List [10]; //向上转换为一个Object数组 List[] oa = lsa; //创建一个List集合 List li = new ArrayList (); li.add(new Integer(3)); //将List 对象作为oa的第二个元素 //下面代码没有任何警告 oa[1] = li; //下面代码也不会有任何警告,但将引起ClassCastException异常 String s = lsa[1].get(0); //①
经过中间系列的程序运行,势必在①行代码处引起运行时异常,这就违背了 Java泛型的设计原则:如果一段代码在编译时系统没有产生“[unchecked]未经检查的转换”警告,则程序在运行时不会引发“ClassCastException”异常。
public class GenericArray{ class A { // T foo; } public GenericArray() { //试图创建内部类A的数组 A[] as = new A[10]; //编译出错 Error:(52, 26) java: 创建泛型数组 } }
看到这个错误,可能会让人感到困扰:只是创建了A[]数组,并未创建所谓的泛型数组,为何编译器会提示“创建泛型数组”的错误?这只能说是JDK的设计非常谨慎。上面程序虽然没有任何问题,但由于内部类A可以直接使用T类型形参 比如注解的 T foo; 这就违背了Java不能创建泛型数组的原则。
10. 正则表达式的陷阱
String str = "java.is.funny.www.crazyit.org"; //将这个字符串以点号(.)分割成多个字符 String[] strArr = str.split("."); for (String s : strArr ) //数组leng =0 { System.out.println(s); } 对于上面程序的运行结果,要注意如下两点:
- String提供的split(String regex)方法需要的参数是正则表达式;
- 正则表达式中的点号(.)可匹配任意字符。
了解上面这两点规律之后,不难理解运行上面程序后为何没有看到希望的分割结果:因为正则表达式中的点号(.)可以匹配任意字符,所以上面程序实际上不是以点号(.)作为分割符,而是以任意字符作为分隔符。为了实现以点号(.)作为分割符的目的,必须对点号进行转义 String[] strArr = str.split("\\.");。
从JDK 1.4开始,Java加入了对正则表达式的支持,String类也增加了一些方法用于支持正则表达式,具体有如下方法。
- matches(String regex) :判断该字符串是否匹配指定正则表达式。
- String replaceAll(String regex, String replacement) :将字符串中所有匹配指定正则表达式的子串替换成replacement后返回。
- String replaceFirst(String regex, String replacement) :将字符串中第一个匹配指定正则表达式的子串替换成replacement后返回。
- String[] split(String regex) :以regex正则表达式匹配的子串作为分割符来分割该字符串。 以上4个方法都需要一个regex参数,这个参数就是正则表达式,因此使用这些方法时要特别小心。String提供了一个与replaceAll功能相当的方法,如下所示。
- replace(CharSequence target, CharSequence replacement) :将字符串中所有target子串替换成replacement后返回。 这个普通replace()方法不支持正则表达式,开发中必须区别对待replaceAll和replace()两个方法。
String clazz = "org.crazyit.auction.model.Item"; //使用replace就比较简单 String path1 = clazz.replace("." , "\\"); System.out.println(path1); //使用replaceAll复杂多了 String path2 = clazz.replaceAll("\\." , "\\\\"); 11. 多线程的陷阱
从JDK 1.5开始,Java提供了3种方式来创建、启动多线程:
- 继承Thread类来创建线程类,重写run()方法作为线程执行体;
- 实现Runnable接口来创建线程类,重写run()方法作为线程执行体;
- 实现Callable接口来创建线程类,重写call()方法作为线程执行体。
其中,第1种方式的效果最差,它有2点坏处:
- 线程类继承了Thread类,无法再继承其他父类;
- 因为每条线程都是一个Thread子类的实例,因此多个线程之间共享数据比较麻烦。
对于第2种和第3种方式,它们的本质是一样的,只是Callable接口里包含的call()方法既可以声明抛出异常,也可以拥有返回值。
除此之外,如果采用继承Thread类的方式来创建多线程,程序还有一个潜在的危险。public class InvokeRun extends Thread { private int i ; //重写run方法,run方法的方法体就是线程执行体 public void run() { for ( ; i < 100 ; i++ ) { //直接调用run方法时,Thread的this.getName返回该对象名字 //而不是当前线程的名字 //使用Thread.currentThread().getName()总是获取当前线程名字 System.out.println(Thread.currentThread().getName() + " " + i); } } public static void main(String[] args) { for (int i = 0; i < 100; i++) { //调用Thread的currentThread方法获取当前线程 System.out.println(Thread.currentThread().getName() + " " + i); if (i == 20) { //直接调用线程对象的run方法 //系统会把线程对象当成普通对象,把run方法当成普通方法 //所以,下面两行代码并不会启动2条线程,而是依次执行2个run方法 new InvokeRun().run(); new InvokeRun().run(); } } } } 上面程序始终只有一条线程,并没有启动任何新线程,关键是因为代码调用了线程对象的run()方法,而不是start()方法——启动线程应该使用start()方法,而不是run()方法。
如果程序从未调用线程对象的start()方法来启动它,那么这个线程对象将一直处于“新建”状态,它永远也不会作为线程获得执行的机会,它只是一个普通的Java对象。当程序调用线程对象的run()方法时,与调用普通Java对象的普通方法并无任何区别,因此绝对不会启动一条新线程。
静态的同步方法
Java提供了synchronized关键字用于修饰方法,使用synchronized修饰的方法被称为同步方法。当然,synchronized关键字除了修饰方法之外,还可以修饰普通代码块,使用synchronized修饰的代码块被称为同步代码块。
Java语法规定,任何线程进入同步方法、同步代码块之前,必须先获取同步方法、同步代码块对应的同步监视器。
对于同步代码块而言,程序必须显式为它指定同步监视器;
对于同步非静态方法而言,该方法的同步监视器是this—即调用该方法的Java对象; 对于静态的同步方法而言,该方法的同步监视器不是this,而是该类本身。 下面程序提供了一个静态的同步方法及一个同步代码块。同步代码块使用this作为同步监视器,即这两个同步程序单元并没有使用相同的同步监视器,因此它们可以同时并发执行,相互之间不会有任何影响。
class SynchronizedStatic implements Runnable { static boolean staticFlag = true; public static synchronized void test0() { for (int i = 0; i < 100 ; i++ ) { System.out.println("test0:" + Thread.currentThread().getName() + " " + i); } } public void test1() { // synchronized (SynchronizedStatic.class) synchronized (this) { for (int i = 0; i < 100 ; i++ ) { System.out.println("test1:" + Thread.currentThread().getName() + " " + i); } } } public void run() { if (staticFlag) { staticFlag= false; test0(); } else { staticFlag= true; test1(); } } public static void main(String[] args) throws Exception { SynchronizedStatic ss = new SynchronizedStatic(); new Thread(ss).start(); //保证第一条线程开始运行 Thread.sleep(10); new Thread(ss).start(); } } 定义了一个SynchronizedStatic类,该类实现了Runnable接口,因此可作为线程的target来运行。SynchronizedStatic类通过一个staticFlag旗标控制线程使用哪个方法作为线程执行体
静态初始化块启动新线程执行初始化
下面程序代表一种非常极端的情况,主要用于考察线程的join方法和类初始化机制。
public class StaticThreadInit { static { //创建匿名内部类来启动新线程 Thread t = new Thread() { //启动新线程将website属性设置为www.leegang.org public void run() { System.out.println("进入run方法"); System.out.println(website); website = "www.leegang.org"; System.out.println(" 退出run方法"); } }; t.start(); try { //加入t线程 t.join(); } catch (Exception ex) { ex.printStackTrace(); } } //定义一个静态field,设置其初始值为www.crazyit.org static String website = "www.crazyit.org"; public static void main(String[] args) { System.out.println("main:"+StaticThreadInit.website); } } 程序的结果将非常清晰:
静态初始化先将website field的值初始化为www.leegang.org, 然后是初始化机制再将website的值赋值为www.crazyit.org。但上面程序的静态初始化块并不是简单地将website赋为www.leegang.org,而是“别出心裁”地启动了一条新线程来执行初始化操作,
尝试编译该程序,可以正常编译结束;尝试运行该程序,程序访问StaticThreadInit.website时,并没有直接输出www.crazyit.org,只是简单地打印了“进入run方法”之后,即无法继续向下执行。
程序总是从main方法开始执行,main方法只有一行代码,访问StaticThreadInit类的website静态field的值。
当某个线程试图访问一个类的静态field时,根据该类的状态可能出现如下4种情况。- 该类尚未被初始化:当前线程开始对其执行初始化。
- 该类正在被当前线程执行初始化:这是对初始化的递归请求。
- 该类正在被其他线程执行初始化:当前线程暂停,等待其他线程初始化完成。
- 这个类已经被初始化:直接得到该静态field的值。
main线程试图访问StaticThreadInit.website的值,此时StaticThreadInit尚未被初始化,因此main线程开始对该类执行初始化。
初始化过程主要完成如下两个步骤。 (1)为该类所有静态field分配内存。 (2)调用静态初始化块的代码执行初始化。因此,main线程首先会为StaticThreadInit类的website field分配内存空间,此时的website的值为null。
接着,main线程开始执行StaticThreadInit类的静态初始化块。该代码块创建并启动了一条新线程,并调用了新线程的join()方法, 这意味着main线程必须等待新线程执行结束后才能向下执行。 新线程开始执行之后,首先执行System.out.println(“进入run方法”);代码,这就是运行该程序时看到的第一行输出。 接着,程序试图执行System.out.println(website);,问题出现了:StaticThreadInit类正由main线程执行初始化, 因此新线程会等待main线程对StaticThreadInit类执行初始化结束。这时候满足了死锁条件:两个线程互相等待对方执行,因此都不能向下执行。因此程序执行到此处就出现了死锁,程序没法向下执行,也就是运行该程序时看到的结果。
经过上面分析可以看出,上面程序出现死锁的关键在于程序调用了t.join(),这导致了main线程必须等待新线程执行结束才能向下执行。下面将t.join()代码注释掉但是注解掉 t.join 执行结果:
main:www.crazyit.org进入run方法www.crazyit.org 退出run方法
其实不然,main线程进入Static ThreadInit的静态初始化块之后,同样也是创建并启动了新线程。由于此时并未调用新线程的join()方法,因此主线程不会等待新线程,也就是说,此时新线程只是处于就绪状态,还未进入运行状态。main线程继续执行初始化操作,它会将website的值初始化为www.crazyit.org,至此Static ThreadInit类初始化完成。System.out.println(StaticThreadInit.website);代码也可以执行完成了,程序输出www.crazyit.org。
接下来新线程才进入运行状态,依次执行run()方法里每行代码,此时访问到的website的值依然是www.crazyit.org; run()方法最后将website的值改为www.leegang.org,但程序已经不再访问它了。
很明显,产生上面运行结果的原因是调用一条线程start()方法后,该线程并不会立即进入运行状态,它将只是保持在就绪状态。
为了改变这种状态,再次改变Static ThreadInit类的静态初始化块代码,
在start() 增加Thread.sleep(1); 新线程的start()方法启动新线程后,立即调用Thread.sleep(1)暂停当前线程(main 线程),使得新线程立即获得执行的机会 进入run方法www.crazyit.org 退出run方法main:www.leegang.org
即使让新线程立即启动,新线程为website指定的值 依然没有起作用(本人测试jre1.8 已经起作用了 )
这依然和类初始化机制有关。当main线程进入Static ThreadInit类的静态初始化块后,main线程创建、启动一条新线程,然后主线程调用Thread.sleep(1)暂停自己,使得新线程获得执行机会,于是看到运行结果第一行输出“进入run方法”。然后,新线程试图执行System.out.println(website);来输出website的值,但由于Static ThreadInit类还未初始化完成,因此新线程不得不放弃执行。线程调度器再次切换到main线程,main线程于是将website初始化为www.crazyit.org,至此Static ThreadInit类初始化完成。 通常main线程不会立即切换回来执行新线程,它会执行main方法里的第一行代码,也就是输出website的值,于是看到输出第一行www.crazyit.org。
main线程执行完后,系统切换回来执行新线程,新线程访问website时也会输出www.crazyit.org,于是看到输出第二行www.crazyit.org。run()方法最后将website的值改为www.leegang.org,但程序已经不再访问它了。
这里实际上有一个问题:静态初始化块里启动多线程对静态field所赋的值根本不是初始值,它只是一次普通的赋值。将代码改为: final static String website;静态初始化块启动的新线程根本不允许为website赋值 这表明,新线程为website的赋值根本不是初始化操作,只是一次普通的赋值。
转载地址:https://blog.csdn.net/ynchyong/article/details/112284472 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
