Apache Kafka 集群架构
发布日期:2021-06-29 01:24:42
浏览次数:2
分类:技术文章
本文共 629 字,大约阅读时间需要 2 分钟。
Kafka的集群图:
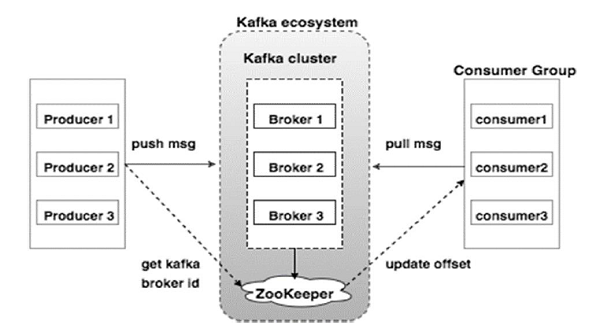
下表描述了上图中显示的每个组件。
| S.No | 组件和说明 |
|---|---|
| 1 | Broker(代理) Kafka集群通常由多个代理组成以保持负载平衡。 Kafka代理是无状态的,所以他们使用ZooKeeper来维护它们的集群状态。 一个Kafka代理实例可以每秒处理数十万次读取和写入,每个Broker可以处理TB的消息,而没有性能影响。Kafka经纪人领导选举可以由ZooKeeper完成。 |
| 2 | ZooKeeper ZooKeeper用于管理和协调Kafka代理。 ZooKeeper服务主要用于通知生产者和消费者Kafka系统中存在任何新代理或Kafka系统中代理失败。 根据Zookeeper接收到关于代理的存在或失败的通知,然后产品和消费者采取决定并开始与某些其他代理协调他们的任务。 |
| 3 | Producers(生产者) 生产者将数据推送给经纪人。 当新代理启动时,所有生产者搜索它并自动向该新代理发送消息。 Kafka生产者不等待来自代理的确认,并且发送消息的速度与代理可以处理的一样快。 |
| 4 | Consumers(消费者) 因为Kafka代理是无状态的,这意味着消费者必须通过使用分区偏移来维护已经消耗了多少消息。 如果消费者确认特定的消息偏移,则意味着消费者已经消费了所有先前的消息。 消费者向代理发出异步拉取请求,以具有准备好消耗的字节缓冲区。 消费者可以简单地通过提供偏移值来快退或跳到分区中的任何点。 消费者偏移值由ZooKeeper通知。 |
转载地址:https://blog.csdn.net/ytp552200ytp/article/details/88665071 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过按个爪印,很不错,赞一个!
[***.219.124.196]2024年04月17日 10时06分46秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
同城社交APP软件有哪些优点?
2019-04-29
Python反爬虫的四种常见方式-JS逆向方法论
2019-04-29
Python爬取《冰雪奇缘2》豆瓣影评
2019-04-29
Python递归爬取今日头条指定用户一个月内发表的所有文章,视频,微头条
2019-04-29
Python爬取620首虾米歌曲,揭秘五月天为什么狂吸粉?!
2019-04-29
Python-根据照片信息获取用户详细信息(微信发原图或泄露位置信息)
2019-04-29
用python重新定义【2019十大网络流行语】
2019-04-29
Python爬取腾讯视频的评论
2019-04-29
Python爬虫实战:批量下载网站图片
2019-04-29
Python走心的42个代码例子
2019-04-29
Python使用openpyxl操作excel表格
2019-04-29
Python 分析电影《南方车站的聚会》
2019-04-29
使用 Scrapy 爬取去哪儿网景区信息
2019-04-29
Python抓取4A级猎头公司数据
2019-04-29
Python爬虫实战:selenium爬取电商平台商品数据
2019-04-29
Python爬虫实战:爬取股票信息
2019-04-29
简短的爬虫程序,14行Python代码轻松实现爬取网站视频
2019-04-29
pycharm的十个小技巧,让你写代码效率翻倍
2019-04-29
python数据可视化神器,我就服它
2019-04-29
Python爬虫如何实用xpath爬取豆瓣音乐
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309317511 位访客
访问时间: 2024-04-30 10:35:34
访问IP: 3.141.27.244
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版