本文共 13753 字,大约阅读时间需要 45 分钟。
一、实验原理
1、Huffman编码
Huffman Coding(哈夫曼编码)是一种无失真的编码方式,是可变字长编码(VLC)的一种。
Huffman编码基于信源的概率统计模型,它的基本思路是:出现概率大的信源符号编长码,出现概率小的信源符号编短码,从而使平均码长最小。
在程序实现时常使用一种叫树的数据结构实现Huffman编码,由它编出的码是即时码。
2、Huffman编码方法
- 统计符号发生的概率;
- 把频率按从小到大的顺序排列;
- 每一次选出最小的两个值,作为二叉树的两个叶子节点,将和作为它们的根节点,这两个叶子不再参与比较,新的根节点参与比较;
- 重复3,直到最后得到和为1的根节点;
- 将形成的二叉树的左节点标0,右节点标1,把从最上面的根节点到最下面的叶子节点途中遇到的0,1序列串起来,就得到了各个符号的编码。
3、二叉树数据结构
二叉树是每个节点最多有两个子树的树结构,子树有左右之分。哈夫曼树即最优二叉树,指带权路径长度最小的二叉树。
二叉树是递归定义的,一棵非空的二叉树由根结点及左、右子树这三个基本部分组成。根据对这三部分访问次序的不同,二叉树的遍历可分为三种情况。由于二叉树是非线性结构,树的遍历实质上是将二叉树的各个结点转换成为一个线性序列来表示。
例如,下面这棵二叉树,三种遍历的顺序为:
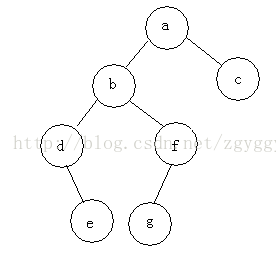
- 前序遍历:根节点->左子树->右子树 abdefgc
- 中序遍历:左子树->根节点->右子树 debgfac
- 后序遍历:左子树->右子树->根节点 edgfbca
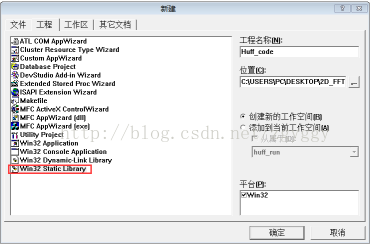
4、静态链接库的建立
本实验将Huffman编码的程序实现封装在一个静态链接库(Huffman_code)中,所谓静态链接库,就是生成一个lib文件,把要调用的函数或者过程链接到可执行文件中,成为可执行文件的一部分。通过在项目工程中添加lib库的头文件,就可以直接在主程序中调用静态链接库的函数即可。
静态链接库的建立方法如图:
项目工程列表如下:
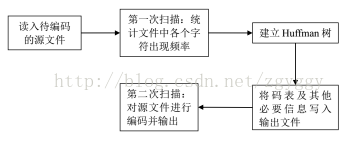
二、实验的流程分析
三、关键代码及分析
1、根据Huffman树的数据结构特点,我们可以定义一个huffman节点结构体和一个huffman码字节点结构体:
///定义Huffman节点结构体typedef struct huffman_node_tag{ unsigned char isLeaf;///是否为树叶节点 unsigned long count;///符号出现频数 struct huffman_node_tag *parent;///父节点指针 union///如果不是节点,此项为该节点左右孩子的指针;否则为某个信源符号 { struct { struct huffman_node_tag *zero, *one; }; unsigned char symbol; };} huffman_node; ///定义Huffman码字节点结构体typedef struct huffman_code_tag{ unsigned long numbits;///码字的长度 /* 码字,码字的第1位存于bits[0]的第1位 , 码字的第2位存于bits[0]的第2位, 码字的第8位存于bits[0]的第8位, 码字的第9位存于bits[1]的第1位*/ unsigned char *bits;} huffman_code; 由于要输出编码后的统计数据文件,我们可以定义一个编码结果统计数据结构体:
///定义编码结果统计数据结构体typedef struct huffman_statistics_result{ float freq[256];///每个符号的概率 unsigned long numbits[256];///符号对应码字的码长 unsigned char bits[256][100];///符号对应的码字}huffman_stat; 2、将文件以ASCII字符流的形式读入,每个字符用一字节保存,一共可能出现256种信源符号。
为了方便控制这256个节点结构体和码字节点结构体,可以分别定义一个节点结构体指针数组和一个码字节点结构体指针数组,数组内的元素为指向相应节点结构体的指针。这样虽然各个节点结构体在内存中是分散的,但是通过指针数组的指向将各个节点逻辑相连。
#define MAX_SYMBOLS 256///每个信源符号为一字节存储,则一共有256种符号typedef huffman_node* SymbolFrequencies[MAX_SYMBOLS];///定义一个指针数组,数组元素为指向huffman节点结构体的指针,数组大小即为符号种数256typedef huffman_code* SymbolEncoder[MAX_SYMBOLS];///定义指针数组,数组元素为指向码字节点结构体的指针,数组大小为符号种数256
3、第一遍扫描文件,建立树叶节点,得到每个符号的频数:
///第一遍扫描文件,从文件中读入信源符号,建立树叶节点static unsigned intget_symbol_frequencies(SymbolFrequencies *pSF, FILE *in){ int c;///定义文件依次读入的信源符号变量 unsigned int total_count = 0;///定义符号总个数,初始为0 init_frequencies(pSF);///初始化huffman节点指针数组 /* 第一遍扫描文件 */ while((c = fgetc(in)) != EOF)///依次读入符号 { unsigned char uc = c; if(!(*pSF)[uc])///如果是一个新符号,则新建一个该符号的树叶节点 (*pSF)[uc] = new_leaf_node(uc); ++(*pSF)[uc]->count;///将该树叶节点的频数+1 ++total_count;///总的符号数+1 } return total_count;///返回符号总数}
///初始化节点指针数组static voidinit_frequencies(SymbolFrequencies *pSF){ memset(*pSF, 0, sizeof(SymbolFrequencies));///将节点指针数组初始化为0} ///定义函数新建一个树叶节点static huffman_node*new_leaf_node(unsigned char symbol){ huffman_node *p = (huffman_node*)malloc(sizeof(huffman_node));///定义一个huffman节点指针,并开辟一块huffman节点结构体大小的内存 p->isLeaf = 1;///设置为树叶节点 p->symbol = symbol;///设置节点符号 p->count = 0;///将符号节点出现频数初始为0 p->parent = 0;///将父节点初始为0 return p;} 4、计算每个符号的概率并赋给编码结果统计数据结构体:
///计算每个符号的概率并赋给编码结果统计数据结构体int huffST_getSymFrequencies(SymbolFrequencies *SF, huffman_stat *st,int total_count){ int i,count =0; for(i = 0; i < MAX_SYMBOLS; ++i) { if((*SF)[i]) { st->freq[i]=(float)(*SF)[i]->count/total_count;///由符号频数除以总符号数计算每个符号的概率 count+=(*SF)[i]->count;///符号数依次累加 } else { st->freq[i]= 0; } } if(count==total_count) return 1; else return 0;} 5、建立huffman树并编码生成码树: ///建立huffman树并编码生成码树static SymbolEncoder*calculate_huffman_codes(SymbolFrequencies * pSF){ unsigned int i = 0; unsigned int n = 0; huffman_node *m1 = NULL, *m2 = NULL; SymbolEncoder *pSE = NULL; #if 1 printf("BEFORE SORT\n"); print_freqs(pSF); //添加预编译命令,查看排序前结果#endif qsort((*pSF), MAX_SYMBOLS, sizeof((*pSF)[0]), SFComp); //调用qsort函数对信源符号概率从小到大排序,比较函数为SFComp#if 1 printf("AFTER SORT\n"); print_freqs(pSF);//添加预编译命令,查看排序后结果#endif for(n = 0; n < MAX_SYMBOLS && (*pSF)[n]; ++n)///得到信源符号的种类总数 ; for(i = 0; i < n - 1; ++i)///建立Huffman树,需要合并n-1次,所以循环n-1次 { /* 将m1,m2置为频数最小的两个符号 */ m1 = (*pSF)[0]; m2 = (*pSF)[1]; /* 将m1,m2合并为一个huffman节点加入到数组中,左右孩子分别为m1,m2的地址,频数为m1,m2的频数之和*/ (*pSF)[0] = m1->parent = m2->parent = new_nonleaf_node(m1->count + m2->count, m1, m2); (*pSF)[1] = NULL; /* 在m1,m2合并后重新对数组排序 */ qsort((*pSF), n, sizeof((*pSF)[0]), SFComp); } /* 由建立的huffman树对每个符号生成码字 */ pSE = (SymbolEncoder*)malloc(sizeof(SymbolEncoder)); memset(pSE, 0, sizeof(SymbolEncoder)); build_symbol_encoder((*pSF)[0], pSE); return pSE;}
通过#if 1······#endif 预处理命令,可以查看中间结果。如果不输出中间结果,直接修改成#if 0······#endif 即可。
排序前:
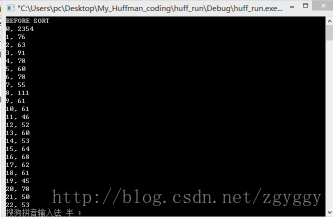
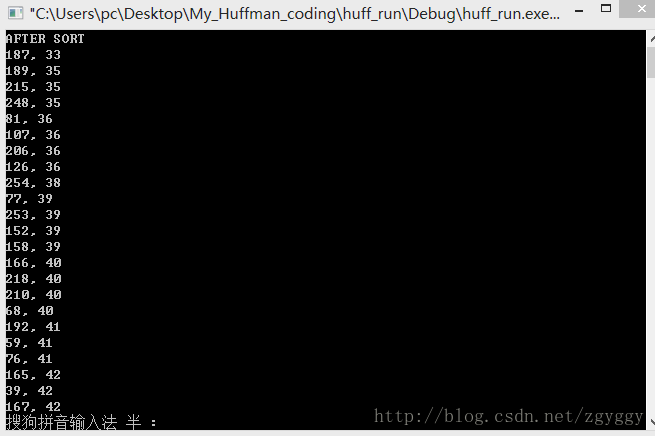
排序后:
///定义qsort函数排序要用到的比较函数static intSFComp(const void *p1, const void *p2){ ///将两个指针参数分别赋给两个节点指针 const huffman_node *hn1 = *(const huffman_node**)p1; const huffman_node *hn2 = *(const huffman_node**)p2; if(hn1 == NULL && hn2 == NULL)///如果两指针均为空,返回0(即相等) return 0; if(hn1 == NULL)///因为空指针不参与排序,所以应该将空指针排到所有符号序列之后。 return 1;///如果hn1为空,则返回1(即hn1排在hn2之后) if(hn2 == NULL)///如果hn2为空,则返回-1 return -1; if(hn1->count > hn2->count)///如果hn1的频数大于hn2,则返回1(即hn1排在hn2之后) return 1; else if(hn1->count < hn2->count)///如果hn1的频数小于hn2,则返回-1 return -1; return 0;} Huffman树的建立是从树叶节点开始,由底往上逐层建立的。即每次排序后将概率最小的两个节点m1,m2合并成一个中间节点,替换掉原来的m1,并将另一个节点置成空节点,再重新排序合并。这样最后数组中只剩下(*pSF)[0]一个元素,即根节点指针,它的概率为1。 ///定义函数新建一个中间节点static huffman_node*new_nonleaf_node(unsigned long count, huffman_node *zero, huffman_node *one)///读入频数、左右节点参数,并对节点结构体内各变量进行设置{ huffman_node *p = (huffman_node*)malloc(sizeof(huffman_node)); p->isLeaf = 0; p->count = count; p->zero = zero; p->one = one; p->parent = 0; return p;} 编码采用递归和前序遍历算法,从根节点开始一直访问左子树直到左子树为树叶节点,对其编码,再访问小树的右子树,对所有树叶节点进行编码。
前序遍历示意图如图:

///递归遍历Huffman树,对每个符号编码static voidbuild_symbol_encoder(huffman_node *subtree, SymbolEncoder *pSF){ if(subtree == NULL)///判断是否到了空节点,是则编码结束 return; if(subtree->isLeaf)///判断是否为树叶节点 (*pSF)[subtree->symbol] = new_code(subtree);///调用new_code函数为树叶节点编码 else { /*采用递归和前序遍历算法,若不是树叶节点, 则沿着huffman树一直访问它的左侧子节点, 直到出现左子节点为树叶节点进行编码,再访问右侧子节点*/ build_symbol_encoder(subtree->zero, pSF); build_symbol_encoder(subtree->one, pSF); }} ///对树叶节点编码static huffman_code*new_code(const huffman_node* leaf)///因为Huffman码为即时码,则只对树叶节点编码{ unsigned long numbits = 0;///定义码长,并初始为0 unsigned char* bits = NULL;///定义码字指针 huffman_code *p;///定义一个码字节点 while(leaf && leaf->parent)///判断是否为树叶节点且它的父节点不为0 { huffman_node *parent = leaf->parent;///定义父节点指针 unsigned char cur_bit = (unsigned char)(numbits % 8);///定义变量控制码字字节中的bit移位 unsigned long cur_byte = numbits / 8;///定义码字字节变量 if(cur_bit == 0)///若码字bit位拼够一个字节 { size_t newSize = cur_byte + 1;///定义变量等于初始字节长度+1 bits = (char*)realloc(bits, newSize);///重新为码字指针分配实际字节长度的内存 /*注意realloc函数与malloc不同,它在保持原有数据不变的情况下重新分配新的空间, 原有数据保存在新空间的的前面部分(空间的地址可能有变化)*/ bits[newSize - 1] = 0; ///将新增的字节中码字初始化为0 } if(leaf == parent->one)///若该树叶节点为右节点,将对应码字bit位编码为1 bits[cur_byte] |= 1 << cur_bit;///将当前字节码字与0000 0001或运算,并左移到当前bit位 ++numbits;///码字长度+1 leaf = parent;///将该父节点又赋给下一个树叶节点,准备下一层的编码 } if(bits) reverse_bits(bits, numbits);///将所编码字逆序得到最终码字 p = (huffman_code*)malloc(sizeof(huffman_code)); p->numbits = numbits; p->bits = bits; return p;///将最终码字赋给码字节点,并返回} 由于编码时是从树叶节点开始向上到根节点依次编码,而最后译码结果是从根节点向下到树叶节点依次读取码字,所以需要对所编码字做逆序处理。 ///定义对码字逆序操作的函数static voidreverse_bits(unsigned char* bits, unsigned long numbits){ unsigned long numbytes = numbytes_from_numbits(numbits);///获取码字字节长度 unsigned char *tmp = (unsigned char*)alloca(numbytes);///定义tmp指针变量,并开辟一块缓冲区用于存放逆序后的码字 unsigned long curbit;///定义变量对位操作 long curbyte = 0;///定义变量对字节操作 memset(tmp, 0, numbytes);///将tmp指向的缓冲区初始置0 for(curbit = 0; curbit < numbits; ++curbit)///对码字的每个位循环操作 { unsigned int bitpos = curbit % 8;///定义移位变量 if(curbit > 0 && curbit % 8 == 0) ++curbyte;///当bit位拼够一个字节时,字节数加1 tmp[curbyte] |= (get_bit(bits, numbits - curbit - 1) << bitpos); /*依次获取相应bit位并将其移到逆序后对应位置, 再与前一bit位逆序后所得字节或运算,得到逆序后码字*/ } memcpy(bits, tmp, numbytes);///将缓冲区内逆序后码字存回bits码字变量} ///定义由码长bit位计算存储字节的函数static unsigned longnumbytes_from_numbits(unsigned long numbits){ return numbits / 8 + (numbits % 8 ? 1 : 0);}
///定义函数获取码字的第i位static unsigned charget_bit(unsigned char* bits, unsigned long i){ return (bits[i / 8] >> i % 8) & 1; /*码字的第i位位于第(i/8)个字节的第(i%8)位, 将第(i/8)个字节向右移(i%8)位后,即将码字第i位移到该字节最低位, 再与0000 0001与运算,取出第i位码字*/} 例如:原码字bits为11 00101101,码长numbits为10,curbit初始为0,bitpos=0%8=0,curbyte初始为0,tmp[0]初始为0000 0000。第一次循环get_bit(bits, numbits - curbit - 1)获得第10-0-1=9位(最高位)码字,即0000 0001,左移0位后还是0000 0001,tmp[0]与其或运算变为0000 0001; 第二次循环curbit为1,bitpos=1%8=1,get_bit函数获得第10-1-1=8位码字,即0000 0001,左移1位后变为0000 0010,tmp[0]=0000 0001,与其或运算后得0000 0011。同理依次对码字循环操作后,实现对码字逆序。
6、将每个符号的码长和码字赋给编码结果统计数据结构体:
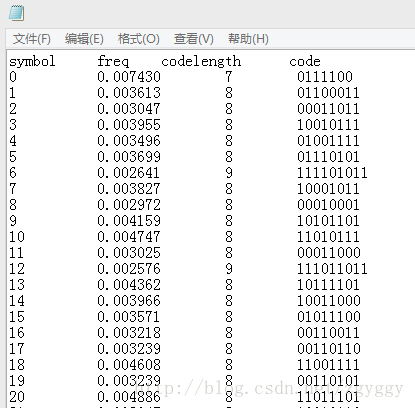
///将每个符号的码长和码字赋给编码结果统计数据结构体int huffST_getcodeword(SymbolEncoder *se, huffman_stat *st){ unsigned long i,j; for(i = 0; i < MAX_SYMBOLS; ++i) { huffman_code *p = (*se)[i]; if(p) { unsigned int numbytes; st->numbits[i] = p->numbits;///码长 numbytes = numbytes_from_numbits(p->numbits); for (j=0;j bits[i][j] = p->bits[j];///码字 } else st->numbits[i] =0; } return 0;} 7、将统计数据写入编码结果文件:编码结果文件可存为.txt文本格式,以列表方式显示字符、字符概率、码长、码字统计信息。 ///将统计数据写入编码结果文件void output_huffman_statistics(huffman_stat *st,FILE *out_Table){ int i,j; unsigned char c; fprintf(out_Table,"symbol\t freq\t codelength\t code\n");///表头 for(i = 0; i < MAX_SYMBOLS; ++i)///依次写入符号、概率、码长 { fprintf(out_Table,"%d\t ",i); fprintf(out_Table,"%f\t ",st->freq[i]); fprintf(out_Table,"%d\t ",st->numbits[i]); if(st->numbits[i]) { for(j = 0; j < st->numbits[i]; ++j) { c =get_bit(st->bits[i], j); fprintf(out_Table,"%d",c);///写入码字 } } fprintf(out_Table,"\n"); }} 8、为了压缩后的编码文件能够顺利解码,需要将码表一同写入输出文件。
输出文件格式如图:
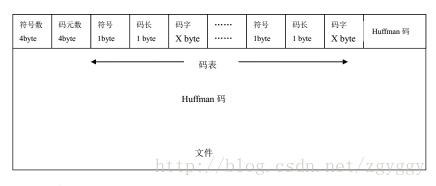
///将Huffman码表写入文件static intwrite_code_table(FILE* out, SymbolEncoder *se, unsigned int symbol_count){ unsigned long i, count = 0; /* 计算实际符号种类数 */ for(i = 0; i < MAX_SYMBOLS; ++i) { if((*se)[i]) ++count; } i = htonl(count);///将实际符号种类数转换成big-endian序保存 /*在网络传输中,采用big-endian序,对于0x0A0B0C0D ,传输顺序就是0A 0B 0C 0D , 因此big-endian作为network byte order,little-endian作为host byte order。 little-endian的优势在于unsigned char/short/int/long类型转换时,存储位置无需改变*/ if(fwrite(&i, sizeof(i), 1, out) != 1)///将实际符号种类数写入文件 return 1; symbol_count = htonl(symbol_count);///将符号总数转换成big-endian序保存 if(fwrite(&symbol_count, sizeof(symbol_count), 1, out) != 1)///将符号总数写入文件 return 1; /* 将码表写入文件 */ for(i = 0; i < MAX_SYMBOLS; ++i) { huffman_code *p = (*se)[i]; if(p) { unsigned int numbytes; fputc((unsigned char)i, out);///写入符号(一字节) fputc(p->numbits, out);///写入码长(一字节) numbytes = numbytes_from_numbits(p->numbits);///计算码长所占字节长度 if(fwrite(p->bits, 1, numbytes, out) != numbytes)///写入码字 return 1; } } return 0;} 9、第二次扫描文件,对文件查表进行huffman编码,并写入输出文件: ///第二次扫描文件,对文件查表进行huffman编码,并写入输出文件static intdo_file_encode(FILE* in, FILE* out, SymbolEncoder *se){ unsigned char curbyte = 0; unsigned char curbit = 0; int c; while((c = fgetc(in)) != EOF)///从文件中依次取出字符 { unsigned char uc = (unsigned char)c; huffman_code *code = (*se)[uc];///查表 unsigned long i; /*将码字写入文件*/ for(i = 0; i < code->numbits; ++i) { curbyte |= get_bit(code->bits, i) << curbit;///由get_bit函数依次取得第i位码字左移到相应位置后与当前字节或运算,得到码字 if(++curbit == 8)///若码字bit位拼够了一个字节,将该字节写入文件,并将curbyte,curbit重置为0 { fputc(curbyte, out); curbyte = 0; curbit = 0; } } } if(curbit > 0)///将最后不够一字节的码字也写入文件 fputc(curbyte, out); return 0;} 10、按编码实现流程依次调用相关函数即可实现编码,Huffman编码函数如下: ///huffman编码函数inthuffman_encode_file(FILE *in, FILE *out, FILE *out_Table){ SymbolFrequencies sf; SymbolEncoder *se; huffman_node *root = NULL; int rc; unsigned int symbol_count; huffman_stat hs; symbol_count = get_symbol_frequencies(&sf, in); ///第一遍扫描文件,建立树叶节点,得到每个符号的频数,并返回总符号数 huffST_getSymFrequencies(&sf,&hs,symbol_count);///计算每个符号的概率并赋给编码结果统计数据结构体 se = calculate_huffman_codes(&sf);///建立huffman树并编码生成码树 root = sf[0]; huffST_getcodeword(se, &hs);///将每个符号的码长和码字赋给编码结果统计数据结构体 output_huffman_statistics(&hs,out_Table);///将统计数据写入编码结果文件 rewind(in);///将输入文件位置指针重新指向文件开头 rc = write_code_table(out, se, symbol_count);///将码表写入文件 if(rc == 0) rc = do_file_encode(in, out, se);///第二次扫描文件,对文件查表进行huffman编码,并写入输出文件 free_huffman_tree(root); free_encoder(se); return rc;} 11、在主程序中调用getopt函数解析命令行参数:
/* 解析命令行参数 */ while((opt = getopt(argc, argv, "i:o:cdhvmt:")) != -1) { switch(opt) { case 'i': file_in = optarg; break; case 'o': file_out = optarg; break; case 'c': compress = 1; break; case 'd': compress = 0; break; case 'h': usage(stdout); return 0; case 'v': version(stdout); return 0; case 'm': memory = 1; break; case 't':///添加选项用于输出编码结果文件 file_out_table = optarg; break; default: usage(stderr); return 1; } }
命令行参数设置如下:
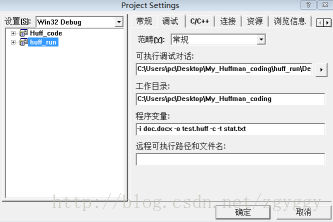
四、实验结果分析
1、以二进制形式打开一个输出文件如下:


绿色框显示的是文件中符号总数,即文件总字节数:00 01 6D 65,转换成十进制为93541B=92KB。
黑色框和灰色框交替显示的是码表部分,每组数据对应显示字符(一字节,00至FF)、码长(一字节)、码字。
蓝色框显示的是文件Huffman压缩编码后的数据。
2、编码结果文件:
3、对不同格式类型的文件进行压缩编码,得到输出比特流文件,并进行压缩效率分析:
| 文件类型 | doc | jpg | avi | mp4 | excel | mpg | ppt | rar | gif | |
| 平均码长 | 7.4390 | 7.9888 | 7.2787 | 7.9512 | 7.8617 | 1.5397 | 7.9545 | 6.2437 | 7.99998 | 7.8475 |
| 信源熵(bit/sym) | 7.4089 | 7.9652 | 7.2490 | 7.9224 | 7.8328 | 0.9333 | 7.9348 | 6.2268 | 7.99914 | 7.8185 |
| 原文件大小(KB) | 17 | 92 | 903 | 4682 | 15 | 4775 | 249 | 255 | 1241 | 117 |
| 压缩后文件大小(KB) | 16 | 92 | 823 | 1192 | 15 | 920 | 248 | 200 | 1242 | 116 |
| 压缩比=原文件大小/压缩后文件大小 | 1.06 | 1.00 | 1.10 | 3.93 | 1.00 | 5.19 | 1.00 | 1.275 | 0.999 | 1.01 |
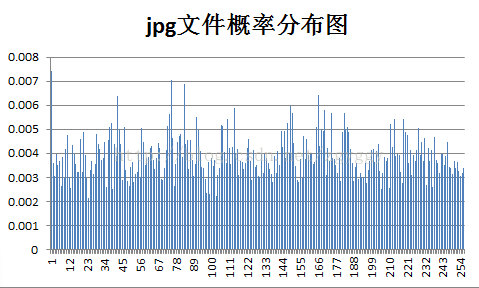
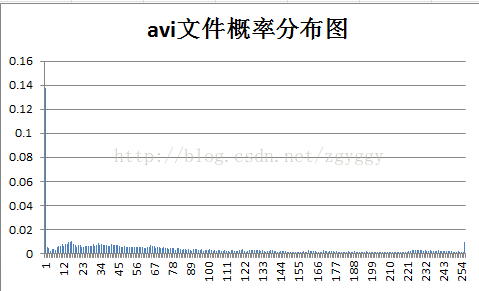
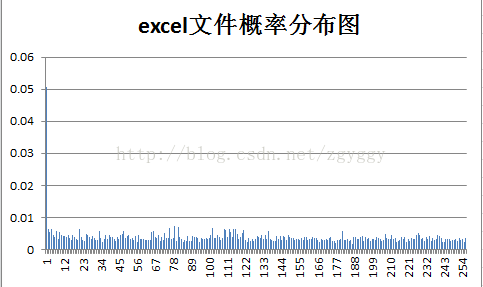
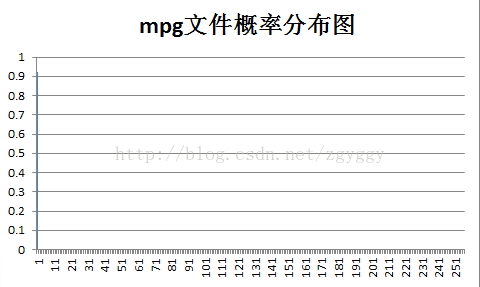
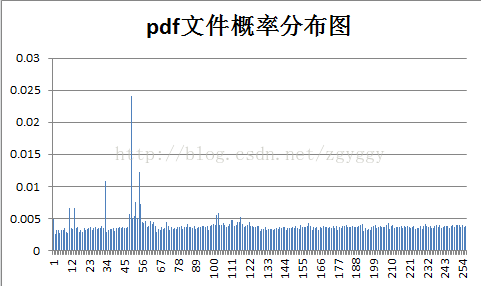
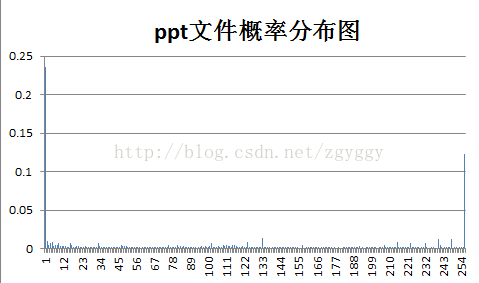
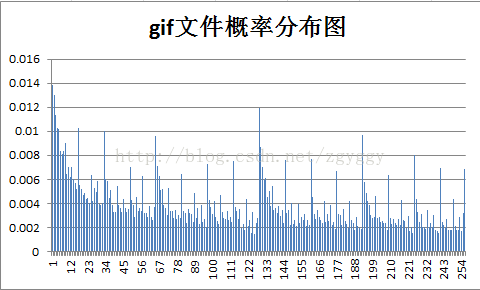
各样本文件的概率分布如下:
 |  |
 |  |
 |  |
 |  |
 |  |
可以看出,Huffman编码的平均码长接近于信源熵,符合平均码长界限定理。
Huffman编码对于信源符号概率分布不均匀的信源压缩效果好,例如实验中用的mpg文件,视频文件画面较单一,

图像大部分区域均为黑色,即信源符号为0的概率接近于1。

按照Huffman编码准则,概率大的符号编短码,将符号0用一位码编码,使得平均码长大大减小,压缩比达到最高。
而对于信源符号概率分布较为均匀的文件,例如测试中的rar文件,本就是压缩过后的文件,对它再进行Huffman编码,由于符号数据间冗余度较小,可压缩的空间不大,况且我们还需要在压缩文件中增加其他信息和码表,反而使得文件编码后变大了。
五、实验结论
1、Huffman编码算法看似简单,但在工程应用实现上却不容易。虽然编码后平均码长可以达到最小,但是在信源个数较多的情况下,码表所占内存较大,不利于传输。
2、对一种数据结构进行操作,应该从逻辑结构和存储结构两方面分析。将Huffman节点、码字定义成结构体的形式,在结构体中设置成员说明是否为树叶节点,符号频数,父节点指针,左右子节点指针等信息,通过指针指向将Huffman树各节点联系起来。
在存储结构方面,定义指针数组,按序存储指向每个节点结构体的指针,通过数组操作能够快速找到对应节点结构体信息,对其进行合并、编码、输出等操作。
转载地址:https://blog.csdn.net/zgyggy/article/details/70344757 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
