zookeeper理论基础
发布日期:2021-06-29 05:04:02
浏览次数:2
分类:技术文章
本文共 4888 字,大约阅读时间需要 16 分钟。
zookeeper简介
- Zookeeper有雅虎研究院开发,后来捐赠给apache。zookeeper是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于Paxos算法的ZAB协议完成的。
- 官网:
一致性
zk通过以下特点保证一致性
- 顺序一致性
- 同一个客户端发起的多个事务请求(写操作请求),最终会严格按照其发起顺序记录到zk
- 原子性
- 所有事务请求的结果在集群中所有的server上的应用情况是一致的。要么全部应用成功,要么全部没有成功
- 单一视图
- 客户端连接集群中的任意一台server,其读取到的数据模型中的数据都是一致的
- 可靠性
- 一旦某事务被成功应用到zk,则会一直被保留下来,直到另一个事务将其修改
- 最终一致性
- 某事务被成功应用到zk后,zk可以保证在一段较短的时间内,客户端最终一定能够从服务端集群中的任意一个节点中读取到最新数据。单不能保证实时读取到。
Paxos算法
算法简介
- Paxos算法是莱斯利·兰伯特(Leslie Lamport)于1990年提出的一种基于消息传递的、高容错性的一致性算法。这个算法被认为是类似算法中最有效的。
- Paxos算法是用于解决什么问题的呢?Paxos算法要解决的问题是,在分布式系统中如何就某个协议达成一致。
Paxos和拜占庭将军问题
- 拜占庭将军问题是由Paxos算法作者提出的点对点通信中的基本问题。该问题要说明的含义是,在不可靠信道上试图通过消息传递的方式达到一致性是不可能的。所以,Paxos算法的前提是***不存在拜占庭将军问题***,即***信道是安全的、可靠的,集群节点间的传递的消息是不会被篡改的***
- 一般情况下,分布式系统中各个节点间采用两种通信模型:
- 共享内存(shared memory)
- 消息传递(message passing)
- Paxos是基于消息传递通讯模型的。
算法描述
三种角色
在Paxos算法中有三种角色,分别具有三种不同的行为。单很多时候,一个进程可能同时充当着多种角色。
- Proposer:提案者
- Acceptor:表决者
- Learner:同步者
Paxos算法一致性的体现
- 每个提案者在提出提案时都会获取到一个具有全局唯一性的、递增的提案编号N,即在整个集群中是唯一的编号N,然后将编号赋予其要提出的提案。
- 每个表决者在accept某提案后,会将该提案的编号N记录到本地,这样每个表决者中保存的已经被accept的提案中会存在一个编号最大的提案,其编号假设是maxN。每个表决者仅会accept编号大于本地maxN的提案。
- 在众多提案中最终只能有一个提案被选定
- 一旦一个提案被选定,其它服务器会主动同步(learn)该提案到本地。
- 没有提案被提出则不会有提案被选定
算法描述过程
Paxos算法执行过程分为两个阶段:准备阶段prepare与接受阶段accept
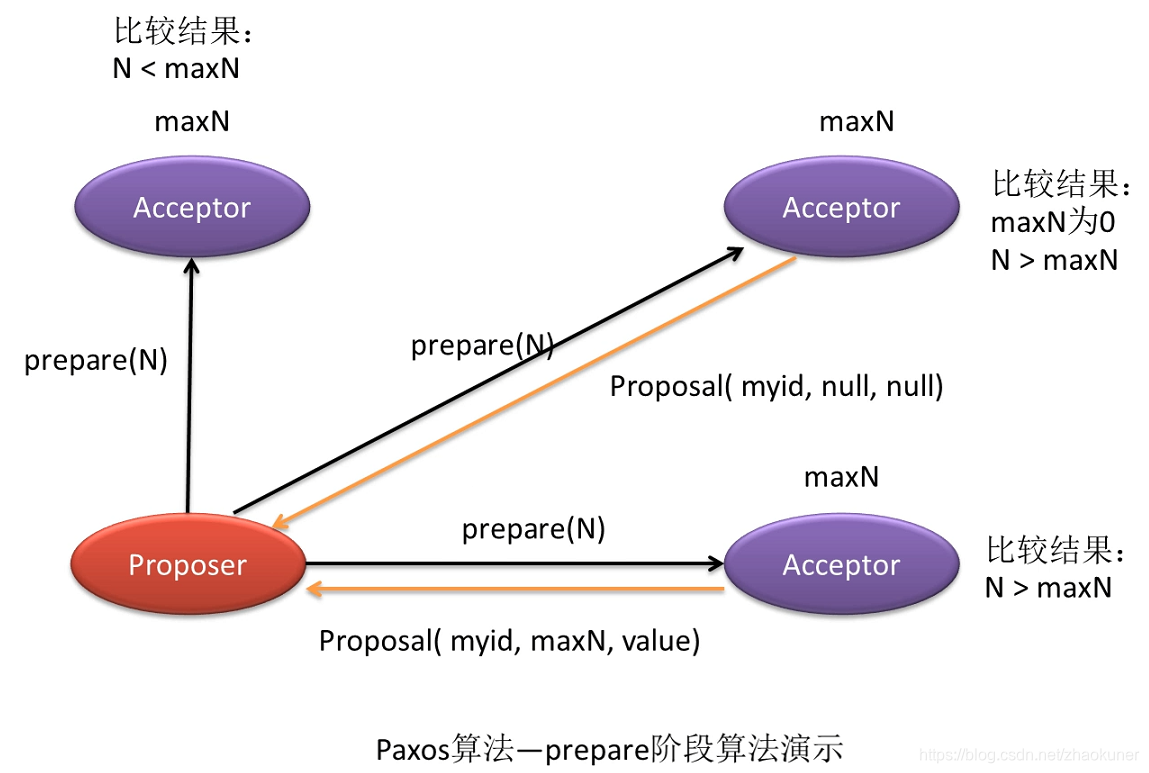
- 1、prepare阶段
- 提案者Propeser准备提交一个编号为N的提议,于是其向所有表决者Acceptor发出prepare(N)请求,用于试探集群是否支持该编号的提议。
- 每个表决者Acceptor中都保存着自己曾经accept过的提议中的最大编号maxN。当一个表决者Acceptor接收到其他主机发来的prepare(N)请求时,其会比较N与maxN的值,有以下几种情况”
- a) 若N小于maxN,则说明该协议已经过时,当前表决者采取不回应或回应Error的方式来拒绝该prepare请求
- b) 若N大于maxN,则说明该提议可以接受,当前表决者会将N记录下来,并将其曾经已经accept的编号最大的提案Proposal(myid,maxN,value)反馈给提案者,以向提案者展示自己支持的提案意愿。 其中,第一个参数myid表示表决者的标识id,第二个参数表示其曾接受的提案的最大提案编号maxN,第三个参数表示该提案的真正内容value。 当然 ,若当前表决者还未曾accept过任何提议,则会将Proposal(myid,null,null)反馈给提案者。
- c) 在prepare阶段N不可能等于maxN,这是由N的生成机制决定的。要获取N的值,其必定会在原来数值的基础上采用同步锁的方式增一。
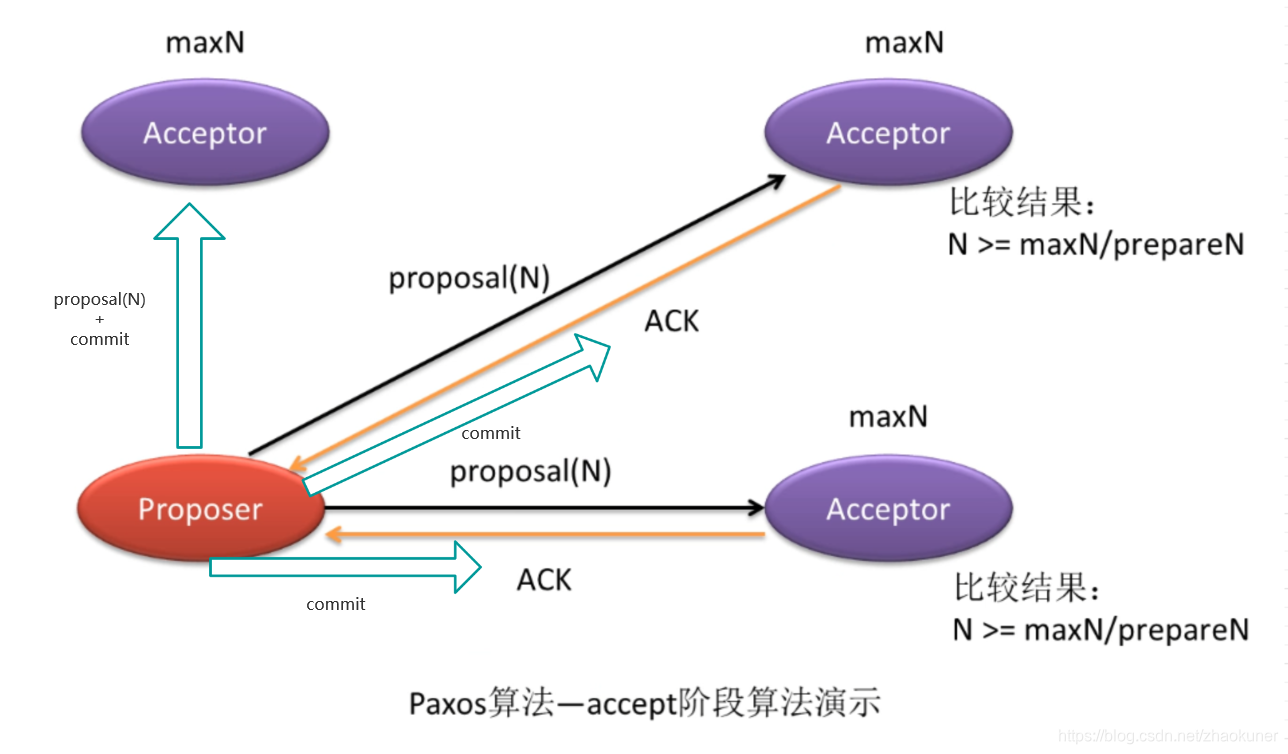
- 2、accept阶段
- a) 当提案者Proposer发出prepare(N)后,若收到半数的表决者的反馈,那么该提案者就会将其真正的提案Proposal(myid,N,value)发个所有的表决者。
- b) 当表决者收到提案者发送的Proposal(myid,N,value)提案后,会再次拿曾经accept过的提议中的最大编号maxN,或曾经记录下的prepare的最大编号,让N与它们进行比较,若N大于等于这两个编号,则当前表决者accept该提案,并反馈给提案者。若N小于这两个编号,则表决者采取不回应或回应Error的方式来拒绝提议。
- c) 若提案者没有接收到超过半数的表决者的accept反馈,则有两种可能的结果产生。一是放弃该提案,不再提出;二是重新进入prepare阶段,递增提案号,重新提出prepare请求。
- d) 若提案者接受到反馈数量超过半数,则其会向外广播两类信息:
- 向曾accept其提案的表决者发送“可执行数据同步信号”,即让它们执行其曾接收到的提案。
- 向未曾向其发送accept反馈的表决者发送“提案+可执行数据同步信号”,即让它们接受到该提议后马上执行。
- 问题
- 问题1:在prepare阶段已经比较过了,并且已经通过了,为什么在Accept阶段还需要进行比较?
- 答:主旨是防止并发。在同一时间,可能会有两个节点同时成为提案者发起prepare,这时就会有一个proposal失效。
- 问题2:在prepare和accept阶段都进行了比较,为什么在发送commit时无需进行比较?
- 答:角色加状态来解决,即收到accept的节点进行lock,lock时,不接受其他事物请求。如果提案者的提案最终没有通过,会通知这些节点unlock。
- 问题1:在prepare阶段已经比较过了,并且已经通过了,为什么在Accept阶段还需要进行比较?
Paxos算法的活锁问题
- 前边所描述的paxos算法在实际的工程应用过程中,根据不同的实际需求存在诸多不便之处。所以,也就出现了很多对于基本paxos算法的优化算法,以对paxos算法进行改进,例如:multi paxos、fast paxos、epaxos。
- paxos算法存在“活锁问题”,fast paxos算法进行了改进:只允许一个进程提交提案,即该进程具有对N的唯一操作权。该方式解决了“活锁”问题。
死锁问题
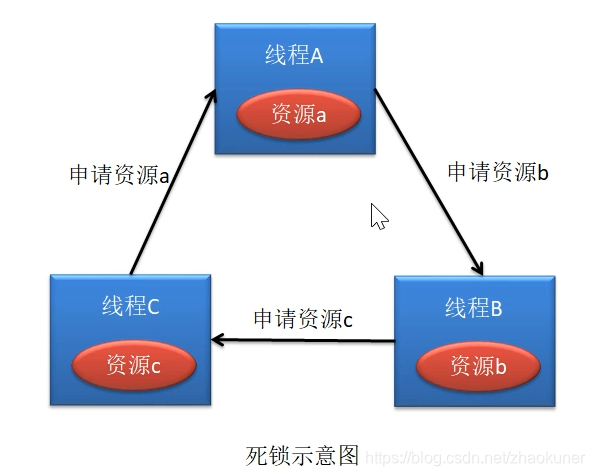
- 互斥条件:一个资源每次仅能被一个进程使用
- 请求与保持条件:一个进程因请求资源而堵塞时,对以获得的资源保持不放
- 不剥夺条件:进程以获得的资源,在未使用完之前,不能强行剥夺
- 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系
活锁问题
活锁指的是任务或者执行者没有被阻塞,由于某些条件没有满足,导致一直重复尝试—失败—尝试—失败的过程。
处于活锁的实体是在不断的改变状态,活锁有可能自行解开。Paxos活锁问题产生
多个提案者同时发起提案如A(1)、B(2), 1和2都时提案编号N
在prepare阶段发生了并发,这样其中N小的那个accept会失败,即A(1)会失败,B(2)进入accept阶段, 但是此时A重新进行了prepare变成A(3),那么,B(2)在accept阶段进行比较时,B(2) < 3,accept失败。 如果B也重新进行prepare,A(3)的accept阶段和B(4)的prepare并发,又会可能造成A(3)的accept失败。 如此往复,就会出现活锁问题。Fast Paxos算法进行了改进:只允许一个进程提交提案,即该进程具有对N的唯一操作权。
ZAB协议
ZAB协议简介
- ZAB,ZooKeeper Atomic Broadcast,zk原子消息广播协议,是专为zk设计的一种支持崩溃恢复的原子广播协议,在zk中,主要依赖ZAB协议来实现分布式数据一致性。
- ZooKeeper使用单一主进程来接收并处理客户端的所有事物请求,即写请求。当服务器数据的状态发生变更后,集群采用ZAB原子广播协议,以事物提案proposal的形式广播到所有的副本进程上。ZAB协议能够保证一个全局的变更序列,即可以为每一个事物提供一个全局的递增编号xid。
- 当zk客户端连接到一个zk集群中的一个节点后,若客户端提交的是读请求,那么当前节点就直接根据自己保存的数据对其进行响应;如果是写请求且当前节点不是leader,那么节点就会将该写请求转发给leader。leader会以提案的方式广播该写操作,只要有超过半数节点同意该写操作,则该写操作请求会被提交。然后leader会再次广播给所有订阅者,即learner,通知他们同步数据。
ZAB与Paxos的关系
- ZAB协议是Paxos算法的一种工业实现算法。但是两者的设计目标不太一样。ZAB协议主要用于构建一个高可用的分布式数据主从系统,即follower是leader的从机,leader挂了,可以马上选举出一个新的leader,但平时它们都对外提供服务。而fast paxos算法则是用于构建一个分布式一致性状态机系统,确保系统中的每个节点状态都是一致的。
三类角色
为了避免zk的单点问题,zk也是以集群形式存在的。zk集群中角色主要有以下三类:
- Leader :事务请求的唯一处理者,也可以处理读请求
- Follower:可以直接处理客户端读请求,并向客户端响应;但其不会处理事务请求,其只会将客户端事务请求转发给leader来处理;对leader发起的事务提案具有表决权;同步leader中的事务处理结果;leader选举过程的参与者,具有选举权和被选举权。:
- Observer:可以理解为不参与leader选举的follower,在leader选举中没有选举权和被选举权;同时,对于leader的提案没有表决权。用于协助follower处理更多客户端读请求。Observer的增加,会提高集群读请求的处理速度,但不会增加事务请求的通过压力,不会增加leader选举的压力。
这三类角色在不同的情况下又有一些不同的名称:
- learner:学习者,即从leader中同步数据的server。learner = follower+observer
- QuorumServer:法定服务器,法定主机,参与者。在集群正常服务状态下,具有表决权的服务器(quorumPeer);在leader选举过程中,具有选举和被选举权的服务器(participant)。QuorumServer = leader+follower
三种数据
- zxid:其为一个64位长度的Long类型,其中高32位表示epoch,低32位表示xid。
- epoch:(年号、时期)每一个leader都会生成一个不同的epoch值。Leader选举结束后,生成一个epoch值,并通知到所有服务器节点,包括follower和observer
- xid:事务id,每一个写事务请求都会有一个编号,即其为流水号。
三种模式
ZAB协议中对zk Server的状态描述有三种模式。这三种模式并没有十分明显的界限,他们相互交织在一起。
- 恢复模式:在集群启动过程中或leader崩溃后,系统都会进入恢复模式,以恢复系统对外提供服务的能力。其包含两个阶段:leader选举和初始化同步。
- 广播模式:其分为两类:初始化广播与更新广播。
- 同步模式:其分为两类:初始化同步与更新同步。
四种状态
zk集群中的每一台主机,在不同阶段会处于不同状态。每个主机具有以下状态:
- LOOKING:选举状态
- FOLLOWING:follower的正常工作状态
- OBSERVING:observer的正常工作状态
- LEADING:leader的正常工作状态
转载地址:https://blog.csdn.net/zhaokuner/article/details/106667721 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
初次前来,多多关照!
[***.217.46.12]2024年04月04日 08时48分36秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
一线 IT 公司开发转管理,我是怎么从 0 到 1 的?
2019-04-29
四平方和
2019-04-29
交换瓶子
2019-04-29
报纸页数
2019-04-29
打印方格
2019-04-29
冰雹数
2019-04-29
网友年龄
2019-04-29
今天百度终于收录了主页-开心-记录一下
2019-04-29
C#实现一直疯狂get访问一个网站
2019-04-29
阿里大牛分享程序员5年的职业生涯指南
2019-04-29
程序员迷茫:毕业时就已26,工作4年就已大龄,码农出路在哪? ...
2019-04-29
新生活方式品牌植治完成数百万种子轮融资, Ventech China领投 ...
2019-04-29
BMIP002协议介绍
2019-04-29
2017-12-22 日语编程语言"抚子"-第三版实现初探
2019-04-29
DataWorks数据服务V2.0全新发布
2019-04-29
vue开发环境搭建Mac版
2019-04-29
揭秘:小米做大家电背后的原因
2019-04-29
网站策划:一个好的网页设计有那些注意事项
2019-04-29
瑞幸咖啡完成1.5亿美元B+轮融资, 贝莱德领投
2019-04-29
Spring Cloud 分布式应用跟踪
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309382128 位访客
访问时间: 2024-04-30 16:15:00
访问IP: 18.191.235.210
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版