本文共 3081 字,大约阅读时间需要 10 分钟。
转载自:
前言
新系统上线,由于测试环境机器配置太低,所以单独找了一台预发机做接口压测,但是QPS达到30时候cpu就满了,简直慌了,新系统这么垃圾的么~
背景介绍
新的账务系统,角色定位是内部户机构账,所以根据不同的金融交易场次会有一次记账请求中存在多借多贷,也就是一次请求会出现给18个账户在一个事务中做记账处理,可想这里面会有多少要注意的坑,详细的不做展开
找问题
top 命令

top -Hp pid 发现下面均是某个进程cpu使用率高
ps -mp pid -o THREAD,tid,time

printf ‘%x\n’ 12149 tid 转换16进制

jstack pid | grep tid 查看该线程信息。好了,不用往下瞅了,FullGC的进程~

jstat -gcutil pid 1000 10
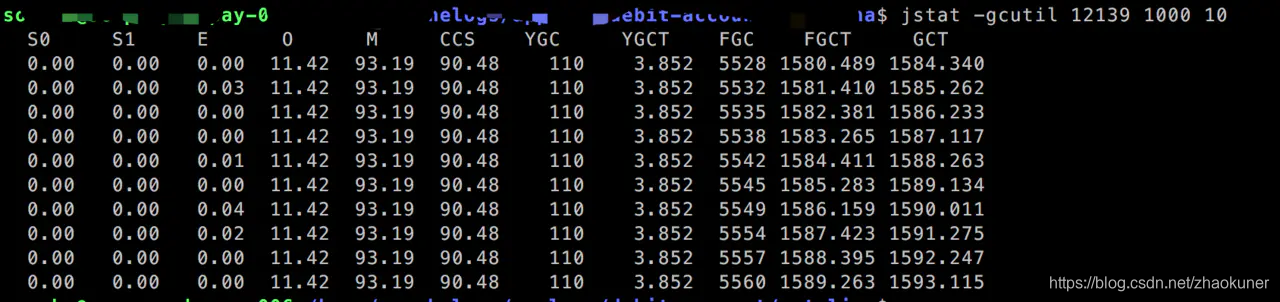
然后稀里糊涂的把堆详细信息都给打出来了~,看下依旧不是这块问题(使用率确实非常低)。
jmap -heap pid
Heap Configuration: MinHeapFreeRatio = 40 MaxHeapFreeRatio = 70 MaxHeapSize = 1073741824 (1024.0MB) NewSize = 235929600 (225.0MB) MaxNewSize = 235929600 (225.0MB) OldSize = 837812224 (799.0MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 134217728 (128.0MB) CompressedClassSpaceSize = 125829120 (120.0MB) MaxMetaspaceSize = 134217728 (128.0MB) G1HeapRegionSize = 0 (0.0MB)Heap Usage:New Generation (Eden + 1 Survivor Space): capacity = 212336640 (202.5MB) used = 0 (0.0MB) free = 212336640 (202.5MB) 0.0% usedEden Space: capacity = 188743680 (180.0MB) used = 0 (0.0MB) free = 188743680 (180.0MB) 0.0% usedFrom Space: capacity = 23592960 (22.5MB) used = 0 (0.0MB) free = 23592960 (22.5MB) 0.0% usedTo Space: capacity = 23592960 (22.5MB) used = 0 (0.0MB) free = 23592960 (22.5MB) 0.0% usedconcurrent mark-sweep generation: capacity = 837812224 (799.0MB) used = 95685920 (91.25320434570312MB) free = 742126304 (707.7467956542969MB) 11.420926701589877% used41909 interned Strings occupying 5041832 bytes.
还在一脸懵逼 ··· ···
这时候有个小伙伴提到了元空间内存满了,恍惚,回过头去查了下 M、CCS 明明是93.19%、90.48% 怎么就满了呢??
那么jstat -gcutil 命令展示列的 M、CCS 到底是啥? 好吧把定义贴出来:
column { header "^M^" /* Metaspace - Percent Used */ data (1-((sun.gc.metaspace.capacity - sun.gc.metaspace.used)/sun.gc.metaspace.capacity)) * 100 align right width 6 scale raw format "0.00" } column { header "^CCS^" /* Compressed Class Space - Percent Used */ data (1-((sun.gc.compressedclassspace.capacity - sun.gc.compressedclassspace.used)/sun.gc.compressedclassspace.capacity)) * 100 align right width 6 scale raw format "0.00" } 也就是说M是表示metaspace的使用百分比??事实证明并非如此~
通过jstat -gccapacity pid 看下具体的metaspace空间值,如下图:jstat -gccapacity pid

说明:下面两张图是预发环境配置修改后的数值,跟当时定位问题时候数值不一样,此处为了说明 MC\MU并不是jdk的环境变量配置的MetaspaceSize 。并且使用jstat -gcutil执行出来的结果M 的百分比并不代表触发 FullGC的阈值~


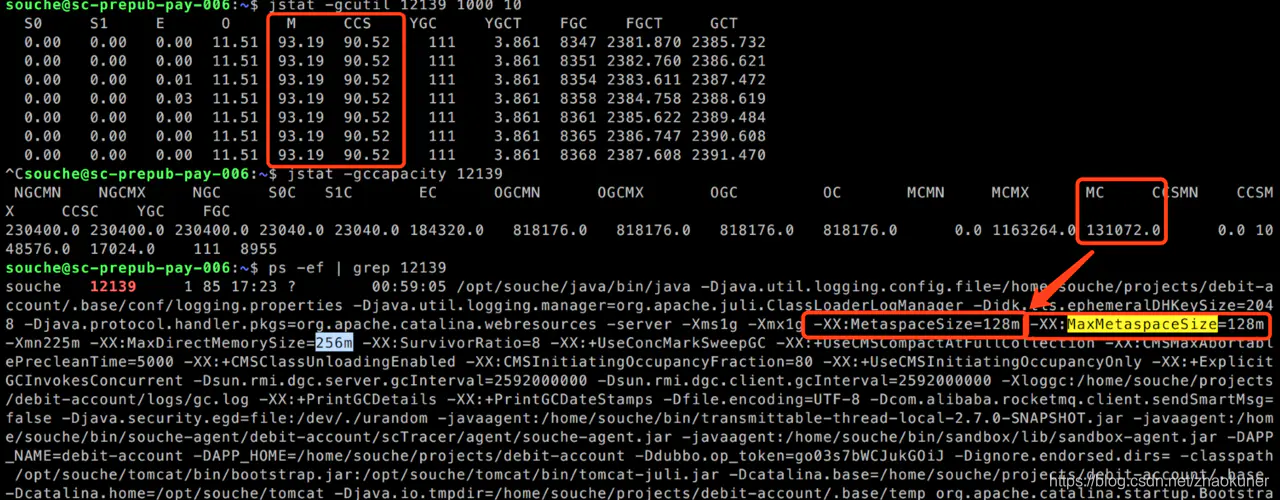
后来通过网上找到说jdk的环境变量的配置-XX:MetaspaceSize=128m 这才是触发元空间FullGC的条件,对比了下线上分配百分比,所以先找到运维把预发环境的环境变量-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m部分 都配置成256m(至于为啥是256,明天可以根环境据修改后的压测分时数据再做下说明),按照原来的并变量发数再压一次, 果然没有再出现堆使用率很低并且还在不配置停FullGC的现象。
转载地址:https://blog.csdn.net/zhaokuner/article/details/106937046 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
