本文共 2976 字,大约阅读时间需要 9 分钟。
参考文章:
一、索引定义和分类
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。比如说课本的目录就是一个索引,我们要找某个知识点时,不必从头到尾每页都翻,只需要在目录中查找到该知识点的所在页数,直接翻到即可,这就加快了查找的效率。
索引的实现通常是采用B树或者B+树。
索引分类:唯一索引、主键索引、聚集索引。
1、唯一索引:
唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。
2、主键索引:
数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。 在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
3、聚集索引:
聚集索引存储记录是物理上连续存在,而非聚集索引是逻辑上的连续,物理存储并不连续。在数据库的一个表中只能有一个聚集索引,但是可以有多个非聚集索引。
举例:在查字典时,我们可以根据拼音来查,也可以根据偏旁来查。因为正文中的字的顺序和拼音的顺序是一样的,因此拼音查询就是聚集索引;但偏旁查询使,有同一个偏旁的字,一般会分散在正文中的不同位置,并不是同一个偏旁的按顺序在一起,所以偏旁查询就是非聚集索引。
二、索引的存储
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致,其实理解起来非常简单,还是举字典的例子:如果按照拼音查询,那么都是从a-z的,是具有连续性的,a后面就是b,b后面就是c, 聚集索引就是这样的,他是和表的物理排列顺序是一样的,例如有id为聚集索引,那么1后面肯定是2,2后面肯定是3,所以说这样的搜索顺序的就是聚集索引。非聚集索引就和按照部首查询是一样是,可能按照偏房查询的时候,根据偏旁‘弓’字旁,索引出两个汉字,张和弘,但是这两个其实一个在100页,一个在1000页,(这里只是举个例子),他们的索引顺序和数据库表的排列顺序是不一样的,这个样的就是非聚集索引。
原理明白了,那他们是怎么存储的呢?在这里简单的说一下,聚集索引就是在数据库被开辟一个物理空间存放他的排列的值,例如1-100,所以当插入数据时,他会重新排列整个整个物理空间,而非聚集索引其实可以看作是一个含有聚集索引的表,他只仅包含原表中非聚集索引的列和指向实际物理表的指针。他只记录一个指针,其实就有点和堆栈差不多的感觉了
索引的存储结构一般是B树或者B+树。这样存储是为了加快查找某个索引的位置,有点类似在一个数组中用二分查找来确定某个数字的位置。用这种方式可以使查找索引的时间复杂度为logn(n为索引项的个数)。查找到索引后,就可以确定所需数据的位置,直接定位即可。三、索引的优缺点
创建索引可以大大提高系统的性能。(优点)
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。(缺点)
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
四、索引的适用条件一般来说,应该在这些列上创建索引:
1、在经常需要搜索的列上,可以加快搜索的速度;
2、在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
3、在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
4、在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
5、在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
6、在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
一般来说,不应该创建索引的的这些列具有下列特点:
1、对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
2、对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
3、对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
4、当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
五、索引的应用
在数据库中创建索引:
1、创建索引的语法:
CREATE [UNIQUE][CLUSTERED | NONCLUSTERED] INDEX index_name
ON {table_name | view_name} [WITH [index_property [,....n]]
说明:
UNIQUE: 建立唯一索引。
CLUSTERED: 建立聚集索引。
NONCLUSTERED: 建立非聚集索引。
Index_property: 索引属性。
UNIQUE索引既可以采用聚集索引结构,也可以采用非聚集索引的结构,如果不指明采用的索引结构,则SQL Server系统默认为采用非聚集索引结构。
2、删除索引语法:
DROP INDEX table_name.index_name[,table_name.index_name]
说明:table_name: 索引所在的表名称。
index_name : 要删除的索引名称。
操作系统中磁盘分页的索引:
在分页系统中,允许将进程的各个页离散地存储在内存不同的物理块中,但系统应该保证进程的正确运行,即能在内存中找到每个页面所对应的物理块。系统又为每个进程建立了一张页表,其记录着相应页在内存中对应的物理块号。进程在执行时,通过查找页表找到内存中对应的物理块号。这个页表就是一个索引,通过查找页表,能够找到所需页在内存中的地址,进而存取数据。分页如下图所示:
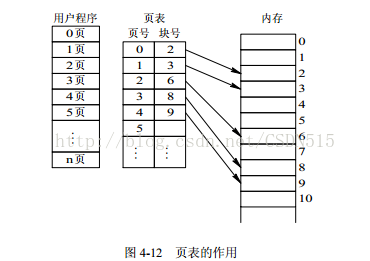
(目前学到这里,以后再补充)
转载地址:https://blog.csdn.net/zhj_fly/article/details/74387407 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
