本文共 2058 字,大约阅读时间需要 6 分钟。
- 牛顿法
求解![]()
当用消元法无法得到解的时候,就需要考虑数值解,常用的解决方法就有牛顿法
以下为推导过程
先进行泰勒展开
![]()
当![]() 的时候,即
的时候,即![]() ,有
,有
![]()
即:
![]()
也因此得到了牛顿法的公式
![]()
- 最优问题
通常的最优问题为
![]()
即求方程
![]()
利用牛顿法就是
![]()
- 多维问题
以上优化的是单变量,当我们遇到方程组的时候,优化变得复杂起来
![]()
其中![]()
先回顾以下雅可比矩阵

而海塞矩阵为:

非线性方程组的最优化问题可以写成
![]()
当我们的目标函数为

则梯度方向上的分量为:

Hessian矩阵的元素则直接在梯度向量的基础上求导

高斯牛顿法省略了二次偏导,即:

把雅可比矩阵和黑塞矩阵带入就有:
![]()
![]()
于是,非线性方程组的迭代形式为:
![]()
- Levenberg-Marquardt算法
来问贝格-马库特方法是对上述方法做了简单的修改,迭代形式变成了
![]()
当我们取较小的λ![]() ,它就是高斯牛顿法,而取较大的λ
,它就是高斯牛顿法,而取较大的λ![]() ,则更像梯度下降法
,则更像梯度下降法
- 梯度下降法
在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率。
在多变量函数中,梯度是一个方向,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向
梯度迭代的公式如下:
![]()
其中,![]() 表示多维向量,
表示多维向量,![]() 表示学习率。
表示学习率。
到这里我们可以发现Levenberg-Marquardt算法,在λ![]() 取较大值的时候,λ
取较大值的时候,λ![]() 就变成了学习率,Levenberg-Marquardt算法就近似为梯度下降法
就变成了学习率,Levenberg-Marquardt算法就近似为梯度下降法
- 神经网络
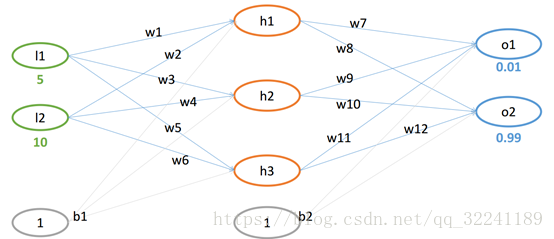
如图所示为一个神经网络,绿色一层为输入层,中间一层为隐藏层,最后一层为输出层
-
- 神经元
首先关注一下单个神经元的输入

其中,n为上一层神经元的个数(说明以下,这里的写法仅是全连接的写法),wi![]() 对应为上一层第i个神经元对于下一层神经元的权重,xi
对应为上一层第i个神经元对于下一层神经元的权重,xi![]() 上一层第i个神经元的输出,b为偏置
上一层第i个神经元的输出,b为偏置
然就就有激活函数,所谓激活函数f,就是对y进行处理之后,作为该神经元的输出,有些模型里面有阈值θj![]() ,有些就没有,这里我们认为没有
,有些就没有,这里我们认为没有
所以该神经元的输出就是
![]()
-
- 激活函数
为了在优化求解的时候,能够找到最大梯度,所以,对应的激活函数必须可微,就是我们能求得倒数,常用的激活函数有以下几种:
-
-
- Sigmod函数
-
![]()

-
-
- Tanh函数
-


-
-
- ReLU函数
-
![]()

这个ReLU函数可能会存在一些问题,首先是如果进到负数区域,就是输入为负数的时候,你对它求导,它始终为负数,这就麻烦了,优化就停了
-
- 单个神经元的梯度下降
假如我们所做的工作为分类工作,就假设为二分类,就只有最简单的三层,输入的训练数据类型为
![]()
其中,X为n维向量,在实际中,它是n个特征,Y对应我们的类型,这里我们简单的认为是0或者1
按照神经元模型,我们的隐藏层的输入为

隐藏层的输出为
![]()
好了,走到这里,我们前向传播了一次,那么这次结果如何呢?我们将它与给定的Y进行比较,则有,这里假设只有一个训练数据,则有
![]()
我们想要的结果是让loss最小,这就回到了梯度下降法,则有
![]()
我们把w和x扩展为W=(w b),X=(x 1),现在考虑Wi![]() ,则有
,则有
![]()
这里就求得了![]() ,还差一个学习率δ
,还差一个学习率δ![]() ,这个属于超参,不可以在BP里面做优化,不过,总有厉害的人想尽办法做优化,所以除了梯度下降法,又有人利用梯度的变化,例如Momentum就是利用历史梯度信息,对当前的梯度进行修改,引入了动力参数α
,这个属于超参,不可以在BP里面做优化,不过,总有厉害的人想尽办法做优化,所以除了梯度下降法,又有人利用梯度的变化,例如Momentum就是利用历史梯度信息,对当前的梯度进行修改,引入了动力参数α![]() ,NAG如出一辙,其实我自己认为这两个没有什么本质的区别,就是对于各种算法的组合
,NAG如出一辙,其实我自己认为这两个没有什么本质的区别,就是对于各种算法的组合
那么对于Wi=Wi-δ∆Wi![]() 就完成了更新
就完成了更新
上面我们只讨论了一个输入的二分类,那么多个输入的怎么做呢,训练过程中唯一有变化的就是Loss函数

仅此而已,这里就不得不提有人对优化器做的另外一种修改,就是在训练量上面下文章,列如BGD就是把总体训练量分为多个批次,每次输入一个批次,进行训练,SGD(随机梯度下降法)就是从n个样本中随机选取一个样本,进行训练,这样子以一个样本训练的单次计算减少,但是训练的次数会增加
-
- 自适应学习率优化器
这里讲到优化器,有一类没有讲到,就是关于稀疏分类的,训练的时候,有些类型的数据量很少,有些很多,这样训练出来的模型是不健康的,所以有人就提出里很厉害的AdaGrad、RMSProp、Adam、AdaDelta算法
-
-
- AdaGrad算法
-

gti![]() 表示第t时刻,即第t次的关于w的梯度,ϵ
表示第t时刻,即第t次的关于w的梯度,ϵ![]() 表示一个极小值,而η0
表示一个极小值,而η0![]() 表示学习率,i=1tgi2
表示学习率,i=1tgi2![]() 表示第i类在t时刻以前梯度平方的累计,这种算法有个好处是,对应不同类,它的学习率不同,训练量比较少的类学习率可以比较高,而训练量比较大的类型,它越往后学习率越低
表示第i类在t时刻以前梯度平方的累计,这种算法有个好处是,对应不同类,它的学习率不同,训练量比较少的类学习率可以比较高,而训练量比较大的类型,它越往后学习率越低
-
-
- RMSPrpp算法
-

这里最突出的变化在于对累计梯度和当前梯度进行α![]() 加权,并对前面的梯度值取了均值,避免了学习效率越来越低的问题
加权,并对前面的梯度值取了均值,避免了学习效率越来越低的问题
-
-
- AdaDelta算法
-

其中wi![]() 表示第i次迭代的模型参数,gt
表示第i次迭代的模型参数,gt![]() 表示代价函数关于W的梯度,从这里可以看到它每次的更新来自前面的权值和累计的梯度以及当前梯度,这可以算是真正没了全局学习率
表示代价函数关于W的梯度,从这里可以看到它每次的更新来自前面的权值和累计的梯度以及当前梯度,这可以算是真正没了全局学习率
-
-
- Adm算法
-

这里去了一阶矩和二阶矩,他们对于超参数具有相当的鲁棒性,但是真的没想明白,嗯,这个时候就安静等候有个时刻能恍然大悟
转载地址:https://blog.csdn.net/zhouzhouasishuijiao/article/details/85173442 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
