本文共 8354 字,大约阅读时间需要 27 分钟。
9月,按照计划开始深入大数据,今天抽时间把Centos 6.5搭建Hadoop-2.7.3分布式集群的过程做个记录,主要分为如下几步:
- 0. 准备阶段
- 1. 安装jdk1.8.0_111
- 2. 安装配置hadoop-2.7.3
- 3. 格式化NameNode
- 4. 启动Hadoop
- 5. 查看Hadoop运行情况
- 6. 通过example测试Hadoop分布式集群功能是否正常
开始前,请准备好jdk1.8.0_111.tar.gz以及hadoop-2.7.3.tar.gz压缩安装包。
0. 准备阶段
0.1 准备Linux环境
0.1.0
点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:192.168.8.0 子网掩码:255.255.255.0 -> apply -> ok
- 回到windows --> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.8.100 子网掩码:255.255.255.0 -> 点击确定
- 在虚拟软件上 --My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok
vim /etc/sysconfig/network NETWORKING=yesHOSTNAME=master0.1.2 修改IP
两种方式: 第一种:通过Linux图形界面进行修改 进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.8.118 子网掩码:255.255.255.0 网关:192.168.1.1 -> apply 第二种:修改配置文件方式
vim /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE="eth0"BOOTPROTO="static"HWADDR="00:0C:29:3C:BF:E7"IPV6INIT="yes"NM_CONTROLLED="yes"ONBOOT="yes"TYPE="Ethernet"UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"IPADDR=192.168.8.118NETMASK=255.255.255.0GATEWAY=192.168.8.1DNS1=192.168.8.1DNS2=114.114.114.114
0.1.3 修改主机名和IP的映射关系
vim /etc/hosts 192.168.8.118 master0.1.4 关闭防火墙
#查看防火墙状态service iptables status#关闭防火墙service iptables stop#查看防火墙开机启动状态chkconfig iptables --list#关闭防火墙开机启动chkconfig iptables off0.1.5 重启Linux
reboot
0.2 创建用户组和用户
[root@master~]$ useradd hadoop & echo hadoop | passwd --stdin hadoop
0.3 设置新创建的用户为sudo权限用户
[root@master~]$ echo "hadoopALL=(ALL) NOPASSWD:ALL" >> /etc/sudoers
0.4 切换用户角色
[root@master~]$ su hadoop
0.5 配置ssh免登陆
#生成ssh免登陆密钥#进入到我的home目录cd ~/.sshssh-keygen -t rsa (四个回车)执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)将公钥拷贝到要免登陆的机器上ssh-copy-id localhost
博主习惯在linux系统的/usr/local/share/applications/目录下安装软件。接下来,默认各位已经把jdk和hadoop安装包移动到了/usr/local/share/applications目录下,开始安装:
1. 安装jdk1.8.0_111
[hadoop@master applications]$ tar -zxvf jdk1.8.0_111.tar.gz[hadoop@master applications]$ vim ~/.bash_profile
按I键进入编辑状态,做如下编辑:
JAVA_HOME=/usr/local/share/applications/jdk1.8.0_111CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarPATH=$JAVA_HOME/bin:$PATHexport JAVA_HOMEexport CLASSPATHexport PATH
编辑完成,Shift + : + wq + Enter键保存退出。通过如下命令使修改立即生效:
[hadoop@master applications]$ source ~/.bash_profile
验证jdk是否安装配置完成:
[hadoop@master applications]$ java -version[hadoop@master applications]$ javac -version
2. 安装配置hadoop-2.7.3
2.1 安装hadoop-2.7.3
新建一个目录hadoop以及hadoop需要用到的数据目录tmp,解压hadoop-2.7.3.tar.gz压缩包,并把解压好的hadoop-2.7.3文件夹移动到新建的hadoop目录下:
[hadoop@master applications]$ mkdir hadoop[hadoop@master applications]$ mkdir hadoop/tmp[hadoop@master applications]$ tar -zxvf hadoop-2.7.3.tar.gz[hadoop@master applications]$ mv hadoop hadoop-2.7.3 /hadoop
配置hadoop环境变量:
[hadoop@master applications]$ vim ~/.bash_profile
做如下编辑:
HADOOP_HOME=/usr/local/share/applications/hadoop/hadoop-2.7.3PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport HADOOP_HOMEexport PATH
同理,编辑完成,Shift + : + wq + Enter键保存退出。通过如下命令使修改立即生效:
[hadoop@master applications]$ source ~/.bash_profile2.2 配置hadoop-2.7.3
hadoop2.x的配置文件所在目录:$HADOOP_HOME/etc/hadoop
总共需要配置7个文件。首先进入到$HADOOP_HOME/etc/hadoop目录下:(我们当前在/usr/local/share/applications目录下)
[hadoop@master applications]$ cd /hadoop/hadoop-2.7.3/etc/hadoop
2.2.1 配置hadoop-env.sh
把文件中的 export JAVA_HOME=${JAVA_HOME} 替换掉:
在Terminal终端执行 vim hadoop-env.sh 命令编辑文件:export JAVA_HOME=/usr/local/share/applications/jdk1.8.0_1112.2.2 配置yarn-env.sh
把文件中的 export JAVA_HOME=/home/y/libexec/jdk1.6.0/ 替换掉:
在Terminal终端执行 vim yarn-env.sh 命令编辑文件:export JAVA_HOME=/usr/local/share/applications/jdk1.8.0_111/
2.2.3 配置core-site.xml
在Terminal终端执行 vim core-site.xml 命令编辑文件:fs.defaultFS hdfs://master:9000 io.file.buffer.size 131072 hadoop.tmp.dir /usr/local/share/applications/hadoop/tmp Abase for other temporary directories. hadoop.proxyuser.jangz.hosts * hadoop.proxyuser.jangz.groups *
2.2.4 配置hdfs-site.xml
在Terminal终端执行 vim hdfs-site.xml 命令编辑文件:dfs.namenode.secondary.http-address master:9001 view HDFS status by web page dfs.namenode.name.dir /usr/local/share/applications/hadoop/dfs/name dfs.namenode.data.dir /usr/local/share/applications/hadoop/dfs/data dfs.replication 2 Every block has 2 backup dfs.webhdfs.enabled true
2.2.5 配置mapred-site.xml
首先通过如下命令复制一份mapred-site.xml文件:
cp mapred-site.xml.template mapred-site.xml在mapred-site.xml文件中做如下配置:
在Terminal终端执行 vim mapred-site.xml 命令编辑文件:mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888
2.2.6 配置yarn-site.xml
在Terminal终端执行 vim yarn-site.xml 命令编辑文件:yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.aux-services.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.address master:18040 yarn.resourcemanager.scheduler.address master:18030 yarn.resourcemanager.resource-tracker.address master:18025 yarn.resourcemanager.admin.address master:18041 yarn.resourcemanager.webapp.address master:18088 yarn.nodemanager.resource.memory-mb 18192 yarn.log-aggregation-enable true
2.2.7 配置slaves文件
把所有的slave节点主机名加入进入即可,比如说我有三个slave节点,如下:
[hadoop@master hadoop]$ cat slaves slave1slave2slave3
需要做如下配置:
vim slavesslave #写上你自己的节点主机名即可,前提是在/etc/hosts文件中已经配置了IP和主机名的映射关系
比如说我的/etc/hosts文件中有如下内容:
[hadoop@master hadoop]$ cat /etc/hosts::1 localhost localhost.localdomain localhost6 localhost6.localdomain610.211.55.100 master10.211.55.101 slave110.211.55.102 slave210.211.55.103 slave310.211.55.104 slave4
2.2.8 复制hadoop文件到所有的slave从节点
我们需要复制的内容是完整的hadoop目录,不只是hadoop-2.7.3目录
[hadoop@master appliciations]$ scp -r hadoop slave:/usr/local/share/applications/3. 格式化NameNode
在Terminal终端执行如下命令:
[hadoop@master applications]$ hdfs namenode -format格式化期间,在终端打印出来的信息没有报错就表示格式化成功。
4. 启动Hadoop
因为我们之前已经配置过环境变量,直接在任意位置都可以执行hadoop命令了。
两种方式启动Hadoop。
方式一:(强烈推荐)
[hadoop@master applications]$ start-dfs.sh[hadoop@master applications]$ start-yarn.sh方式二:(不推荐)
[hadoop@master applications]$ start-all.sh5. 查看Hadoop运行情况
5.1 查看进程运行情况
[hadoop@master applications]$ jps17170 Jps2003 NameNode2597 ResourceManager2255 SecondaryNameNode如果可以看到NameNode、ResourceManager、SecondaryNameNode三个进程,就表示进程启动成功。
5.2 WEB UI查看集群是否成功启动
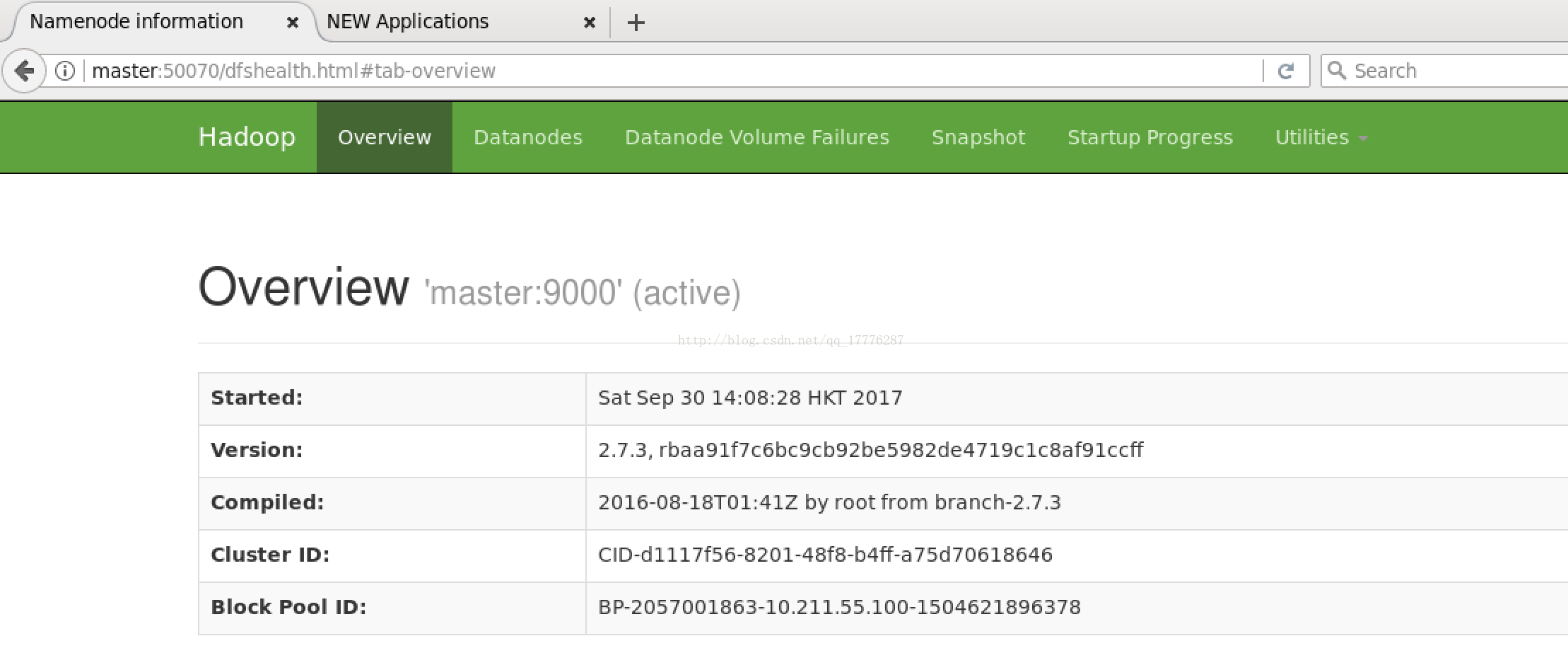
在 HadoopMaster 上启动 Firefox 浏览器,在浏览器地址栏中输入输入 http://master:50070/,检查namenode和datanode是否正常。UI页面如下图所示。
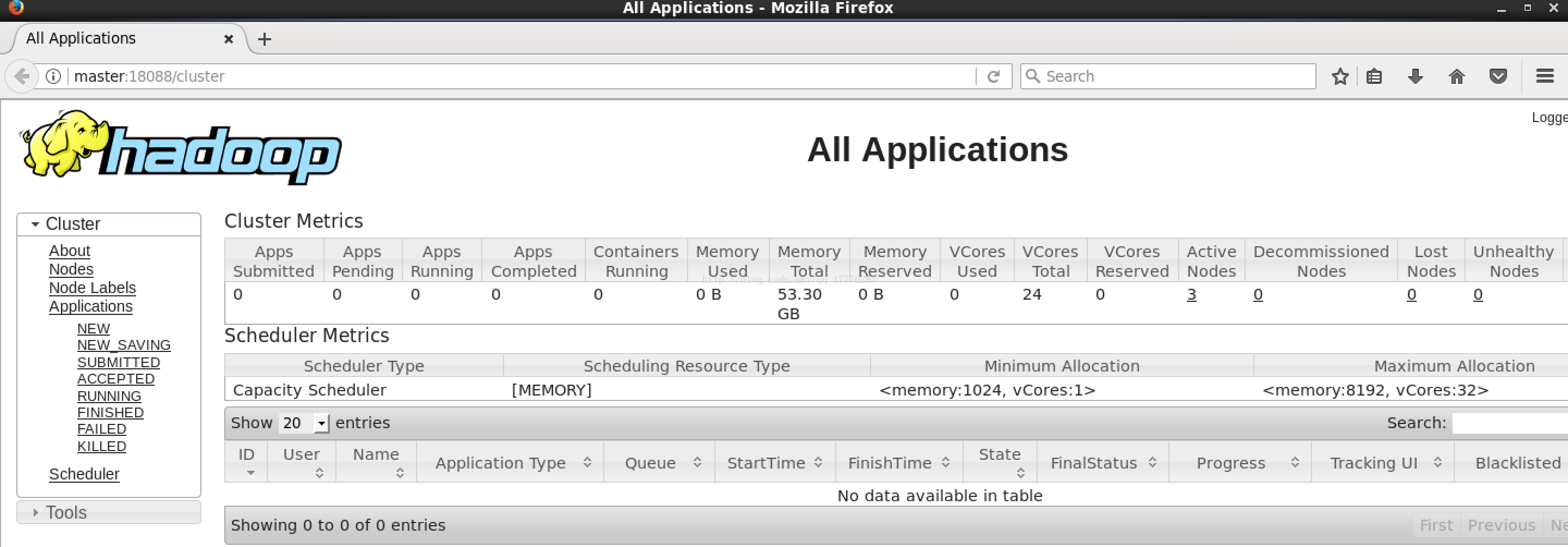
在 HadoopMaster 上启动 Firefox 浏览器,在浏览器地址栏中输入输入 http://master:18088/,检查Yarn 是否正常,页面如下图所示。
6. 通过example测试Hadoop分布式集群功能是否正常
[hadoop@master applications]$ cd /hadoop/hadoop-2.7.3/share/hadoop/mapreduce[hadoop@master mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.3.jar pi 10 10
会看到如下结果:

得出最终的结果如下:

以上3个验证步骤都没有问题,说明集群正常启动。
好了,Centos 6.5搭建Hadoop-2.7.3分布式集群就完成了。博主设计,仅供参考!
转载地址:https://buildupchao.blog.csdn.net/article/details/77847009 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
