本文共 3330 字,大约阅读时间需要 11 分钟。
最近大数据学习使用了Flume、Kafka等,今天就实现一下Flume实时读取日志数据并写入到Kafka中,同时,让Kafka的ConsoleConsumer对日志数据进行消费。
1、Flume
Flume是一个完善、强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说明不再详细赘述。
Flume包含Source、Channel、Sink三个最基本的概念,其相应关系如下图所示:
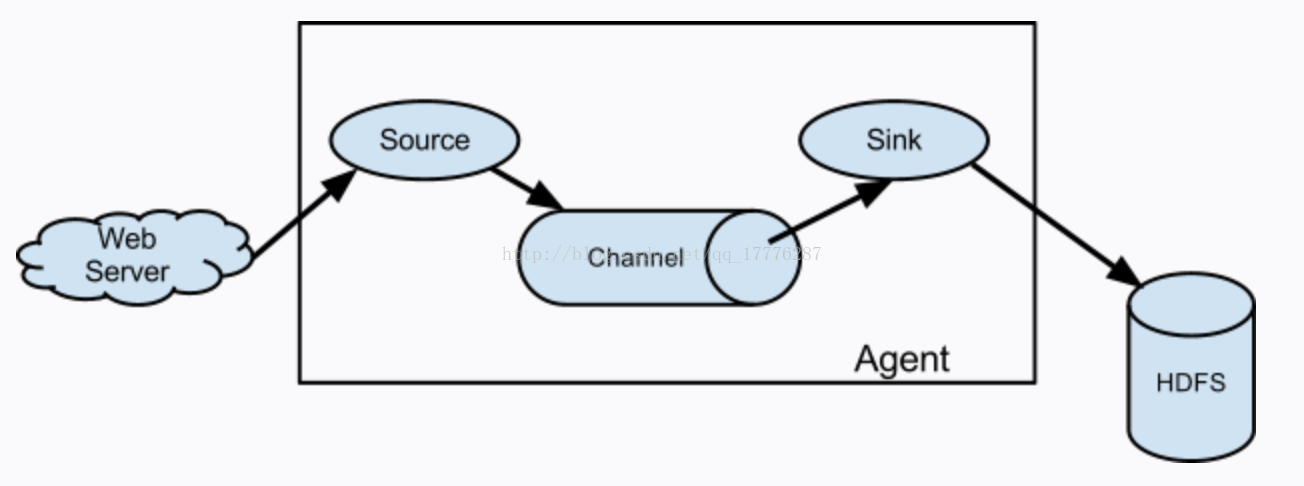
注:
Source——日志来源,其中包括:Avro Source、Thrift Source、Exec Source、JMS Source、Spooling Directory Source、Kafka Source、NetCat Source、Sequence Generator Source、Syslog Source、HTTP Source、Stress Source、Legacy Source、Custom Source、Scribe Source以及Twitter 1% firehose Source。
Channel——日志管道,所有从Source过来的日志数据都会以队列的形式存放在里面,它包括:Memory Channel、JDBC Channel、Kafka Channel、File Channel、Spillable Memory Channel、Pseudo Transaction Channel、Custom Channel。
Sink——日志出口,日志将通过Sink向外发射,它包括:HDFS Sink、Hive Sink、Logger Sink、Avro Sink、Thrift Sink、IRC Sink、File Roll Sink、Null Sink、HBase Sink、Async HBase Sink、Morphline Solr Sink、Elastic Search Sink、Kite Dataset Sink、Kafka Sink、Custom Sink。
基于Flume的日志采集是灵活的,即,我们可以将多个管道处理串联起来。
2、前期准备
2.1 软件安装位置
flume: /usr/local/share/applications/apache-flume-1.7.0-bin
kafka: /usr/local/share/applications/kafka_2.10-0.10.1.1
(节点数这个无所谓,最少两个吧,master & slave,博主有5个结点,哈哈)
2.2 编写用于实时产生日志的shell文件
在/usr/local/share/applications/目录下执行如下操作:
创建一个临时存放日志文件的目录:
mkdir testdata
mkdir -p tmp/flumetokafka/logs/
接下来开始编写shell文件:
vim output.sh在output.sh文件中,首先通过shift + : + i进入编辑模式,编写如下代码:
for((i=5612; i<6000; i++));do touch $PWD/testdata/20170913-jangzhangz-$i.log echo 'When we will see you again. Put a little sunshine in your life.----'+$i >> $PWD/testdata/20170913-jangzhangz-$i.log mv $PWD/testdata/20170913-jangzhangz-$i.log $PWD/tmp/flumetokafka/logs/done这里需要说明一下:tmp/flumetokafka/logs/就是flume进行监听日志文件的数据目录
3、为flume构建agent
首先进入flume所在目录下的conf目录,编写构建agent的配置文件(flume2kafka.properties):
通过vim flume2kafka.properties命令编辑文件,同样通过shift + : + i进入编辑模式,在文件中写入如下配置信息:
Flume2KafkaAgent.sources=mysourceFlume2KafkaAgent.channels=mychannelFlume2KafkaAgent.sinks=mysinkFlume2KafkaAgent.sources.mysource.type=spooldirFlume2KafkaAgent.sources.mysource.channels=mychannelFlume2KafkaAgent.sources.mysource.spoolDir=/usr/local/share/applications/tmp/flumetokafka/logsFlume2KafkaAgent.sinks.mysink.channel=mychannelFlume2KafkaAgent.sinks.mysink.type=org.apache.flume.sink.kafka.KafkaSinkFlume2KafkaAgent.sinks.mysink.kafka.bootstrap.servers=master:9092,slave1:9092,slave2:9092,slave3:9092Flume2KafkaAgent.sinks.mysink.kafka.topic=flume-dataFlume2KafkaAgent.sinks.mysink.kafka.batchSize=20Flume2KafkaAgent.sinks.mysink.kafka.producer.requiredAcks=1Flume2KafkaAgent.channels.mychannel.type=memoryFlume2KafkaAgent.channels.mychannel.capacity=30000Flume2KafkaAgent.channels.mychannel.transactionCapacity=100然后通过shift + : wq保存文件。
4、求证成果
4.1 启动flume agent
在flume根目录下:
bin/flume-ng agent -c conf -f conf/flume2kafka.properties -n Flume2KafkaAgent -Dflume.root.logger=INFO,console4.2 启动kafka消费者
在kafka根目录下执行:
bin/kafka-console-consumer.sh --zookeeper master:2181 --topic flume-data --from-beginning或者在kafka的bin目录下执行:
./kafka-console-consumer.sh --zookeeper master:2181 --topic flume-data --from-beginning
4.3 生成日志
在/usr/local/share/applications/下,执行如下命令:
./output.sh4.4 查看terminal显示的消费记录情况
正常执行后,结果会出现类似情况:

5、踩坑记录
针对flume的配置文件,如果要实现flume读取的日志数据写入kafka,则必须要配置Bootstrap Server信息。
总结
1、了解如何构建flume读取日志数据并能够写入kafka的架构
2、能够借助于shell文件的编写,从而简化工作量,并能友好的监测到实时数据
3、flume配置文件的编写,source —— channel —— sink
4、启动服务,进行成果检测
5、踩坑记录
希望对各位有帮助,博主设计,仅供参考!又到这个时间点了,睡觉了,晚安!
转载地址:https://buildupchao.blog.csdn.net/article/details/77972711 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
