本文共 2600 字,大约阅读时间需要 8 分钟。
网站架构机器演变过程
1.1 软件的三大类型
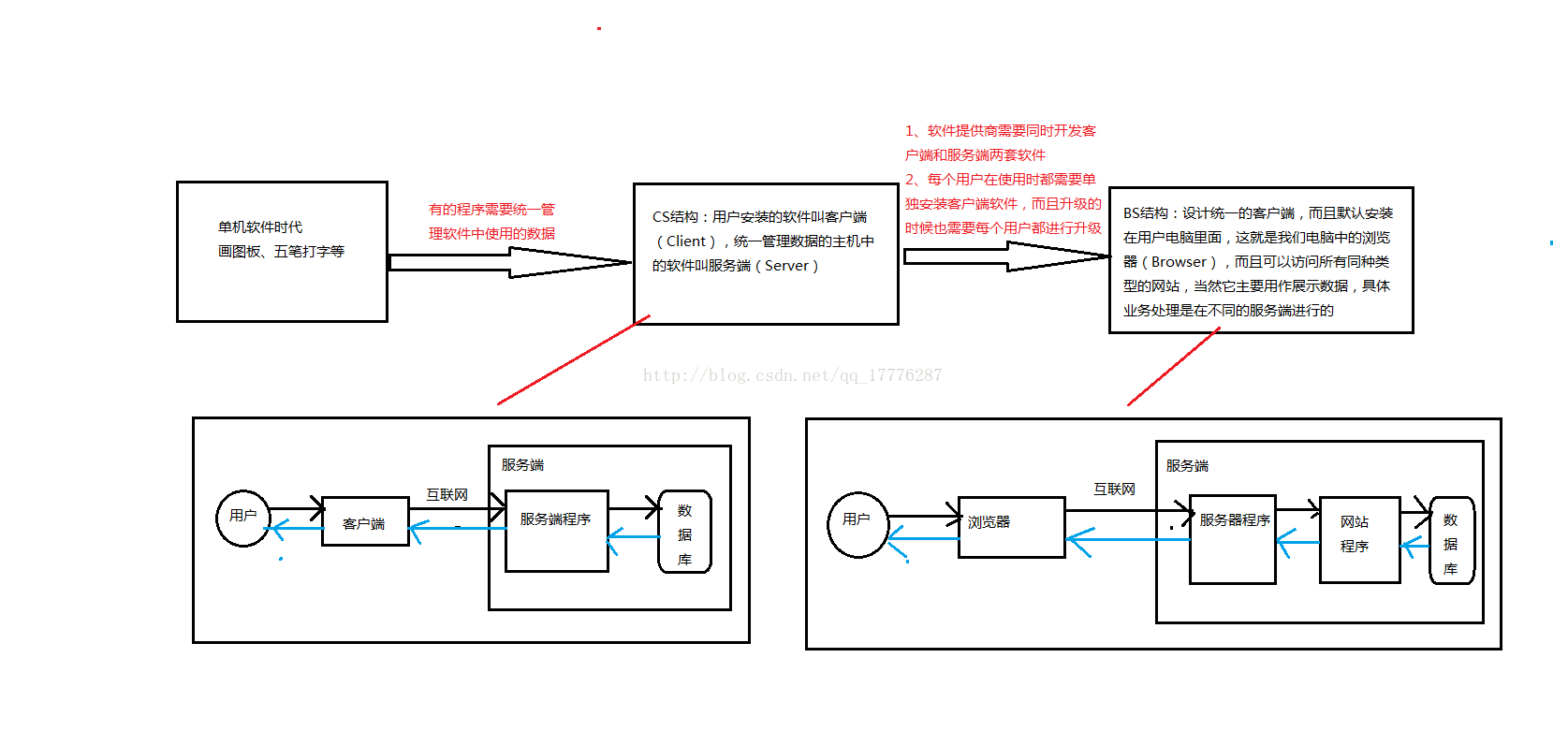
1.2 基础的结构并不简单
BS结构是最基础的结构,不过即使这种最基础的结构的底层实现也不简单,因为它需要通过互联网传输数据,而互联网是一个错综复杂的网络,其中包括的节点不计其数,而且每两个节点之间的距离以及连接的线路都是不确定的,数据在传输的过程中还可能会丢失,所以非常复杂。
所有问题都有它对治的方法,对于复杂问题的对治方法就是将其分解成多个简单的问题,然后通过解决每个简单的问题,最终解决复杂问题。BS结构网络传输的分解方式有两种:一种是标准的OSI参考模型,另一种是TCP/IP参考模型。它们的分层方式及对应关系如图所示:
OSI参考模型一共分7层,不过它主要用户教学,实际使用中更多的是TCP/IP的4层模型。对于TCP/IP的4层模型可以简单地理解为:
- 网络接入层:将需要相互连接的节点接入网络中,从而为数据传输提供条件。
- 网际互连层:找到要传输数据的目标节点。
- 传输层:实际传输数据。
- 应用层:使用接受到的数据。
由于网络传输应用非常广泛,所以需要大家都遵守规矩,不过网络传输中的这些规矩并不是强制性的,所以不叫制度也不叫标准而叫协议,其实TCP/IP参考模型也可以看作一种协议。
BS结构中TCP/IP模型中的网络接入层没有相应协议,网际互连层是IP协议,传输层是TCP协议,应用层是HTTP协议。
1.3 架构演变的起点
基础结构中服务端就一台主机,其中存储了应用程序和数据库,刚上线时时没有问题的,当数据和流量变得越来越大的时候就难以应付了,这时候就需要将应用程序和数据库分别放到不同的主机上,如图所示:
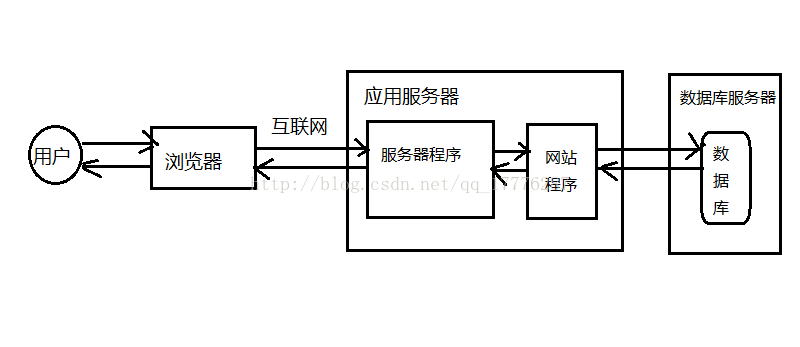
1.4 海量数据的解决方案
1.4.1 缓存和页面静态化
数据量大这个问题最直接的解决方案就是使用缓存,缓存就是将从数据库中获取的结果暂时保存起来,在下次使用的时候无需重新到数据库中获取,这样可以大大降低数据库的压力。
缓存的使用方式可以分为通过程序直接保存到内存中和使用缓存框架两种方式。
程序直接操作主要是使用Map,尤其是ConcurrentHashMap。
常用的缓存框架:Ehcache、Memcache和Redis等。
缓存在使用过程中最重要的问题是什么时候创建缓存和缓存的失效机制(还有粗粒度失效和细粒度失效)。
页面静态化可以在程序中使用模版技术生成,如常用的Freemarker和Velocity都可以根据模版生成静态页面,
另外也可以使用缓存服务器在应用服务器的上一层缓存生成的页面,如可以使用Squid,另外Nginx也提供了相应的功能。
1.4.2 数据库优化
表结构优化、SQL语句优化、分区、分表、索引优化、使用存储过程代替直接操作
1.4.3 分离活跃数据
虽然有些数据总量非常大,但是活跃数据并不多,这种情况就可以将活跃数据单独保存起来,从而提高处理效率。
1.4.4 批量读取和延迟修改
批量读取和延迟修改的原理都是通过减少操作的次数来提高效率,如果使用得恰当,效率将会呈数量级提升。
1.4.5 读写分离
读写分离的本质是对数据库进行集群,这样就可以在高并发的情况下将数据库的操作分配到多个数据库服务器去处理,从而降低单台服务器的压力,不过由于数据库的特殊性——每台服务器所保存的数据都需要一致,所以数据同步就成了数据库集群中最核心的问题。
如果多台服务器都可以写数据,那么数据同步将变得非常复杂,所以一般情况下是将写操作交给专门的一台服务器处理,这台专门负责写的服务器叫做主服务器。
当主服务器写入(增删改)数据后,从底层同步到别的服务器(从服务器),读数据的时候到从服务器读取,从服务器可以有多台,这样就可以实现读写分离,并且将读请求分配到多个服务器处理。
主服务器向从服务器同步数据时,如果从服务器数据很多,那么可以让主服务器先向其中一部分从服务器同步数据,第一部分从服务器接收到数据后再向另外一部分同步。
注:主/从服务器以及数据同步过程,有些类似于HDFS内的NameNode和DataNode
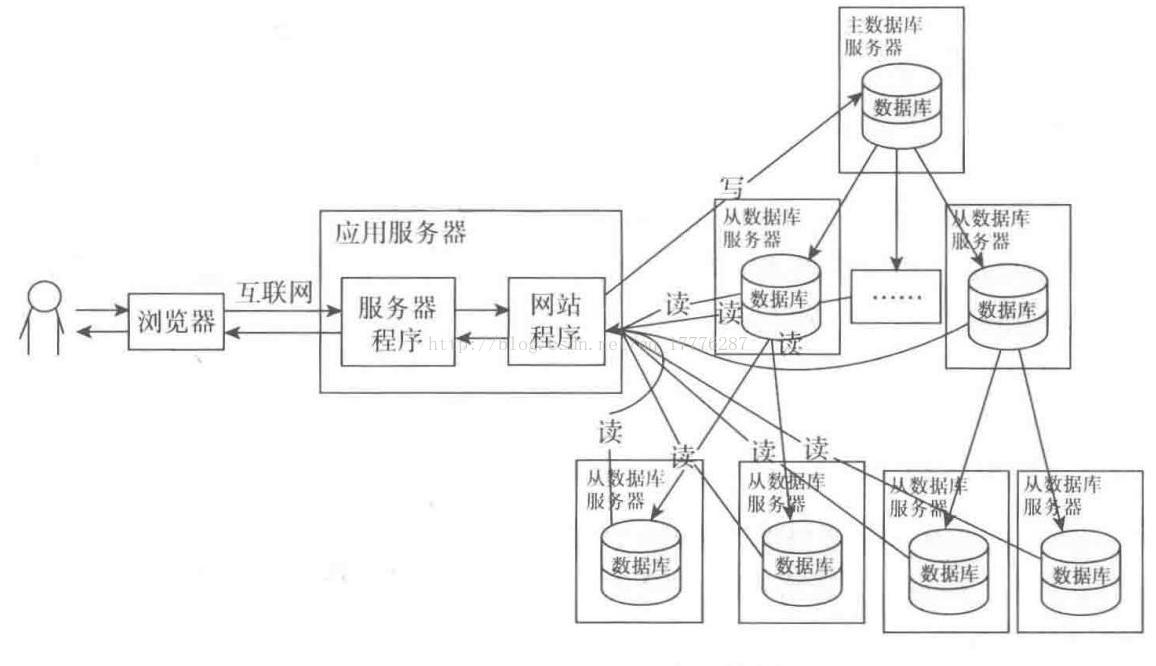
既然是集群,就会涉及到负载均衡问题,负载均衡和读写分离的操作一般采用专门程序处理,而且对应用系统来说是透明的。
1.4.6 分布式数据库
分布式数据库是将不同的表存放到不同的数据库中,然后再放到不同的服务器。这样在处理请求时,如果需要调用多个表,则可以让多台服务器同时处理,从而提高处理速度。
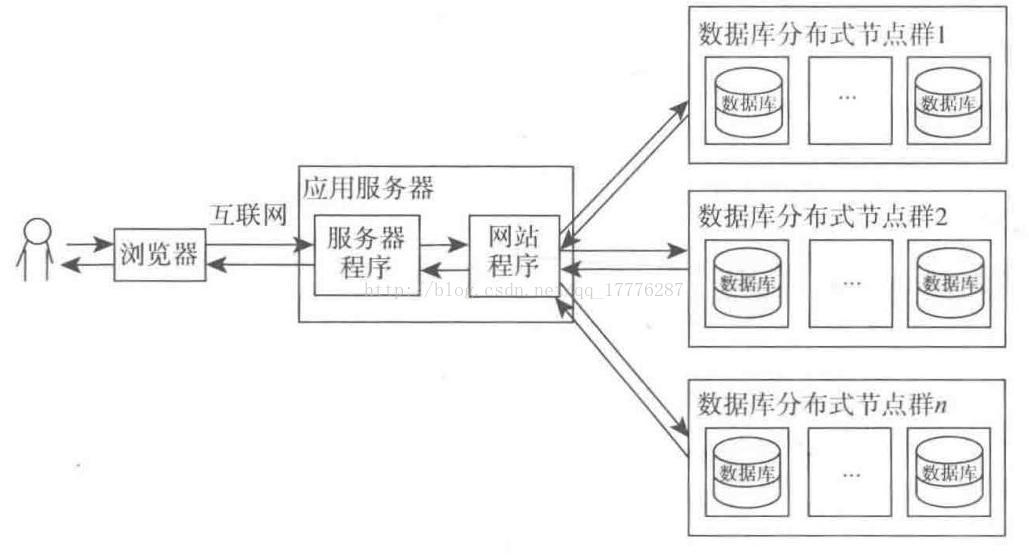
数据库集群的作用是将多个请求分配到不同的服务器处理,从而减轻单台服务器的压力。
分布式数据库是解决单个请求本身就非常复杂的问题,它可以将单个请求分配到多个服务器处理,使用分布式后的每个节点还可以同时使用读写分离,从而组成多个节点群。
1.4.7 NoSQL和Hadoop
因为NoSQL通过多个块存储数据的特点,其操作大数据的速度也非常快。
Hadoop对数据的处理是先对每一块的数据找到相应的节点并进行处理,然后再对每一个处理的结果进行处理,最后生成最终的结果。(Map-Reduce、分而治之的思想)
1.5 高并发的解决方案
除了数据量大,另一个常见的问题就是并发量高,很多架构就是针对这个问题设计出来的。
- 应用和静态资源分离:静态文件(图片、视频、JS、CSS等)放在专门的服务器上
- 页面缓存(Nginx服务器、Squid服务器)
- 集群和分布式
- 反向代理
反向代理指的是客户端直接访问的服务器并不真正提供服务,它从别的服务器获取资源,然后将结果返回给用户的。
反向代理服务器和代理服务器的区别:
- 代理服务器的作用是代我们获取想要的资源,然后将结果返回给我们,其中所要获取的资源是我们主动告诉代理服务器的。
- 反向代理服务器是我们正常访问一台服务器时,服务器自己调用了别的服务器的资源,并将结果返回给我们,我们自己并不知道。
- CDN
- 底层的优化:网络传输协议
Summary
1、网站架构的整个演变过程主要是围绕大数据和高并发这两个问题展开的,解决方案主要分为使用缓存和使用多资源两种方式。
2、要想设计出合理的架构,首先需要理解每种架构所针对的问题和它背后的本质,只有这样才能真正把架构用作解决问题的工具,而不是为了架构而架构,最后问题不一定能解决,还浪费了资源。
3、在使用复杂框架之前,一定要先将自己的业务优化好,这是基础中的基础,非常重要!
好了,时间不早了,博主设计,仅供参考!
转载地址:https://buildupchao.blog.csdn.net/article/details/78031808 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
