本文共 2713 字,大约阅读时间需要 9 分钟。
MapReduce作业执行流程
0 准备阶段
0.1 回顾hadoop配置文件mapred-site.xml
mapreduce.framework.name yarn
Hadoop 2.x引入了一种新的执行机制。这种新机制(MR 2)建立在一个名为YARN的系统上。而用于执行的框架通过 “mapreduce.framework.name” 属性进行设置。
mapreduce.framework.name取值:
- local: 表示本地的作业运行器
- classical: 表示经典的MR框架(也称MR 1,它使用一个 jobtracker 和多个 tasktracker)
- yarn: 表示新的框架
关于YARN,在此不做展开介绍,后续会专门撰写YARN系列博文。
0.2 角色介绍
资源管理器: 即 Resource Manager(RM),负责管理所有应用程序计算资源的分配。
应用管理器: 即 Application Master(AM),每一个应用程序的AM负责相应的调度和协调。
容器: 即 Containers, YARN为将来的资源隔离而提出的框架,每一个任务对应一个Container,且只能在该Container中运行。
节点监视器: 即 Node Manager,管理每个节点上的资源和任务,主要有两个作用:定期向AM汇报该节点的资源使用情况和各个Container的运行状态;接收并处理AM的任务启动、停止等请求。
1 MR运行机制
1.1 YARN上的MR 角色实体
Client: 提交MapReduce作业
ResourceManger: 协调集群上的计算资源分配
NodeManager: 启动和监视集群中机器上的计算容器(Container)
ApplicationMaster: 负责协调运行MR作业的任务。它和MR任务在NM的Container中运行,这些容器由ResourceManager分配并由NodeManager进行管理
HDFS: 保存作业的数据、配置信息等
1.2 作业的运行过程
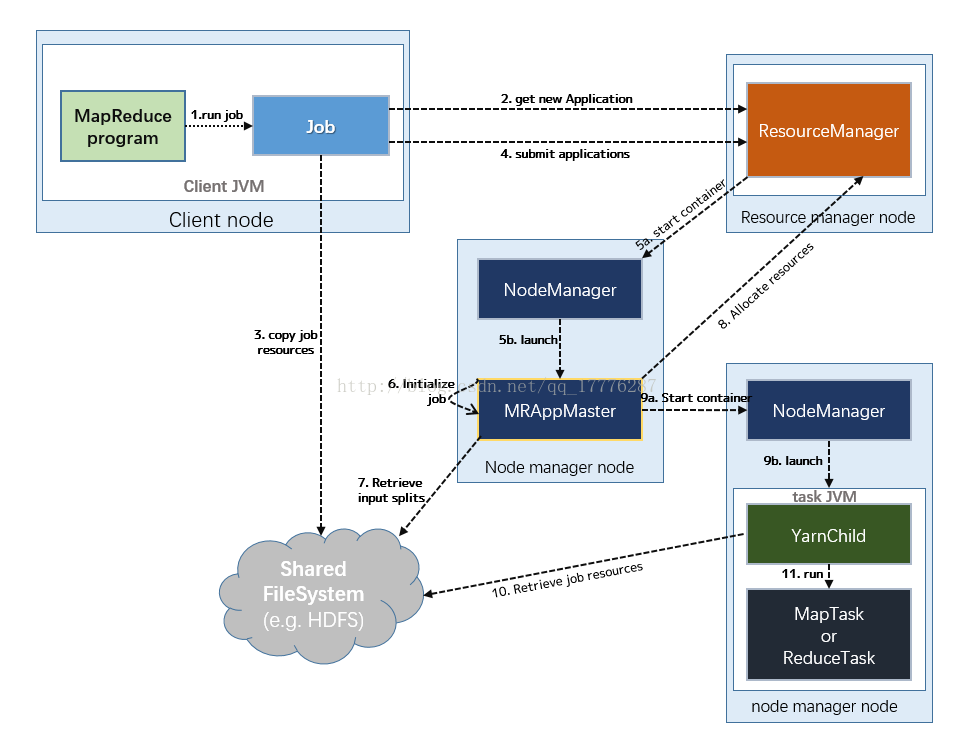
动态展示流程图:
(1)提交作业
Client提交Job:
- Client编写好Job后,调用Job实例的Sumit() 或者 waitForCompletion() 方法提交作业;
- 从RM(而不是Jobtracker)获取新的作业ID,在YARN命名法中它是一个Application ID(步骤2)。
Job提交到RM:
- Client检查作业的输出说明,计算输入分片,并将作业资源(包括作业JAR、配置和分片信息)复制到HDFS(步骤3);
- 调用RM的 submitApplication() 方法提交作业(步骤4)。
(2)作业初始化
给作业分配ApplicationMaster:
- RM收到调用它的 submitApplication() 消息后,便将请求传递给 scheduler (调度器);
- scheduler分配一个 Container,然后 RM在该 NM的管理下在 Container中启动 ApplicationMaster(步骤5a & 5b)。
ApplicationMaster初始化作业:
- MR作业的ApplicationMaster 是一个Java应用程序,它的主类是 MRAppMaster。它对作业进行初始化:通过创建多个薄记对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告(步骤6);
- ApplicationMaster 从HDFS中获取 在Client 计算的输入分片(map、reduce任务数)(步骤7)【对每一个分片创建一个 map 任务对象以及由 mapreduce.job.reduces 属性确定的多个 reduce 任务对象】。
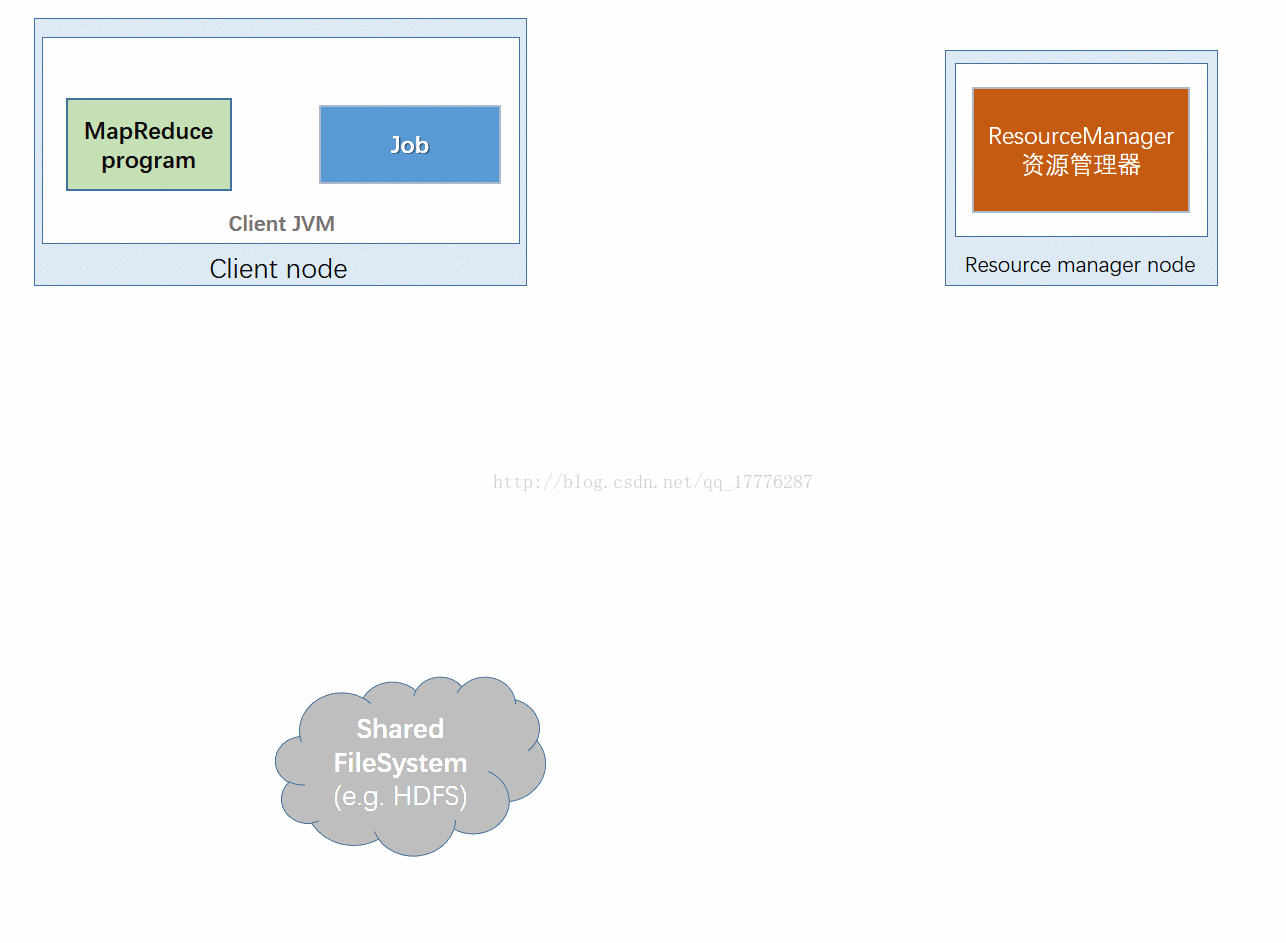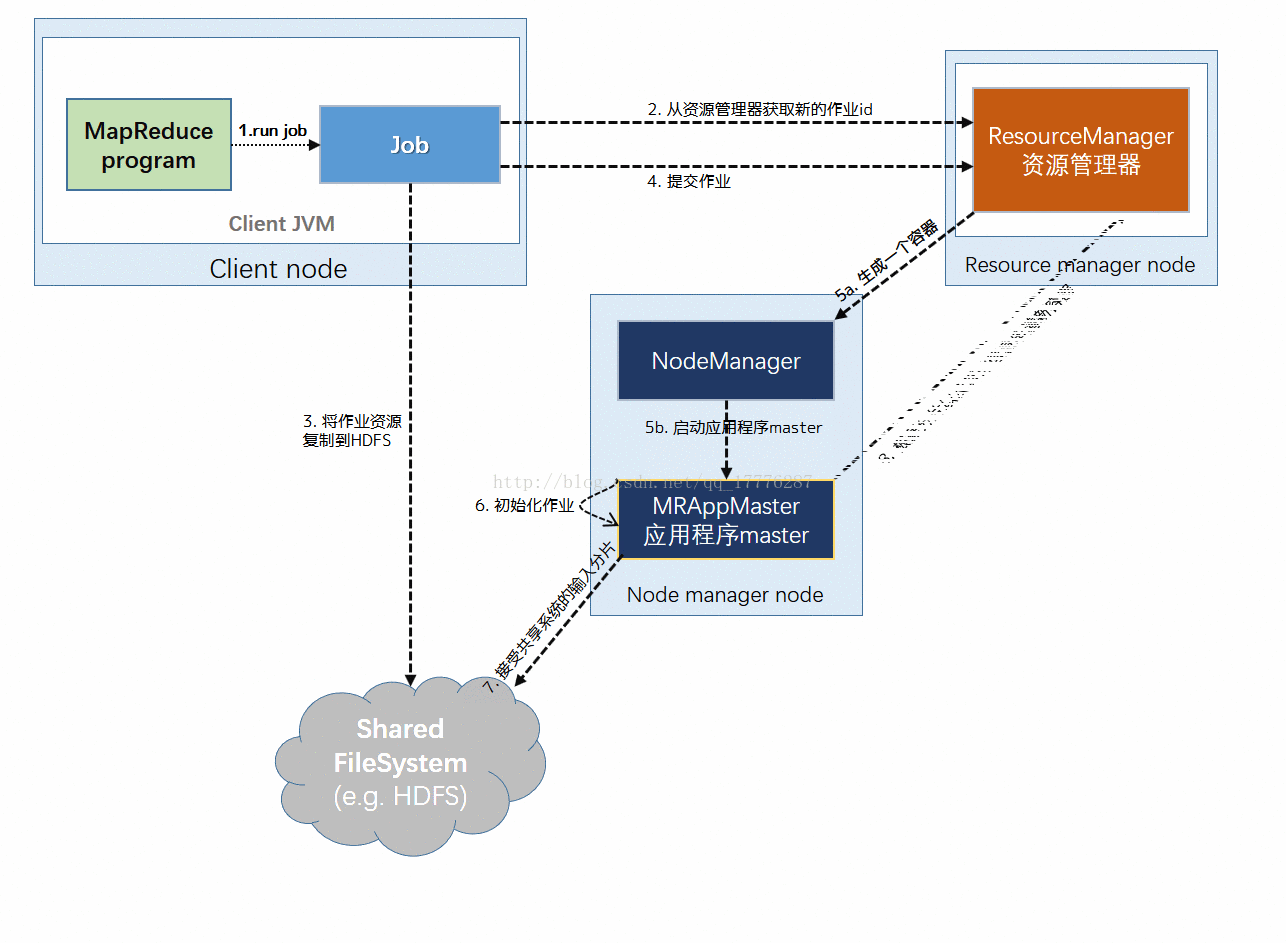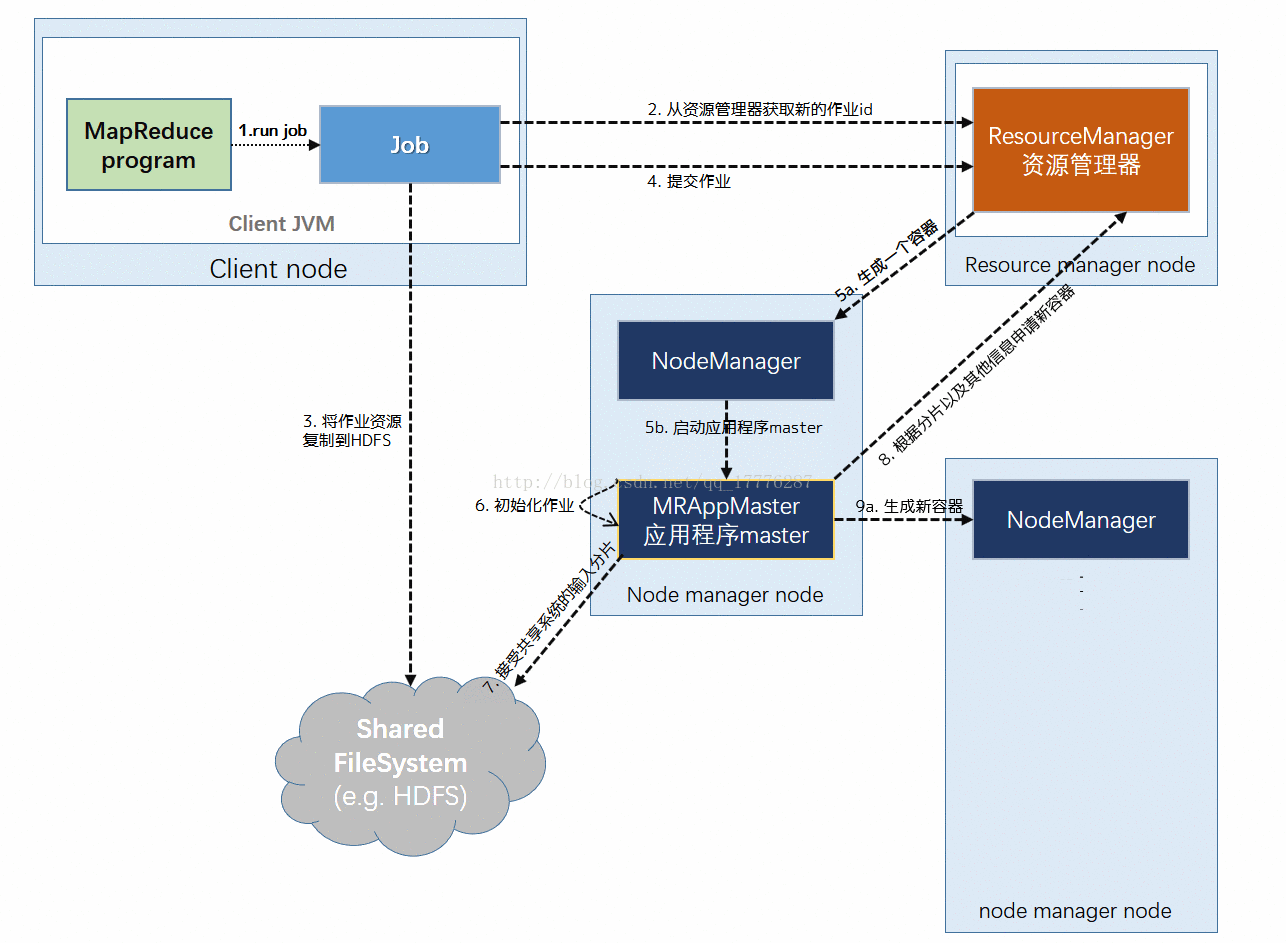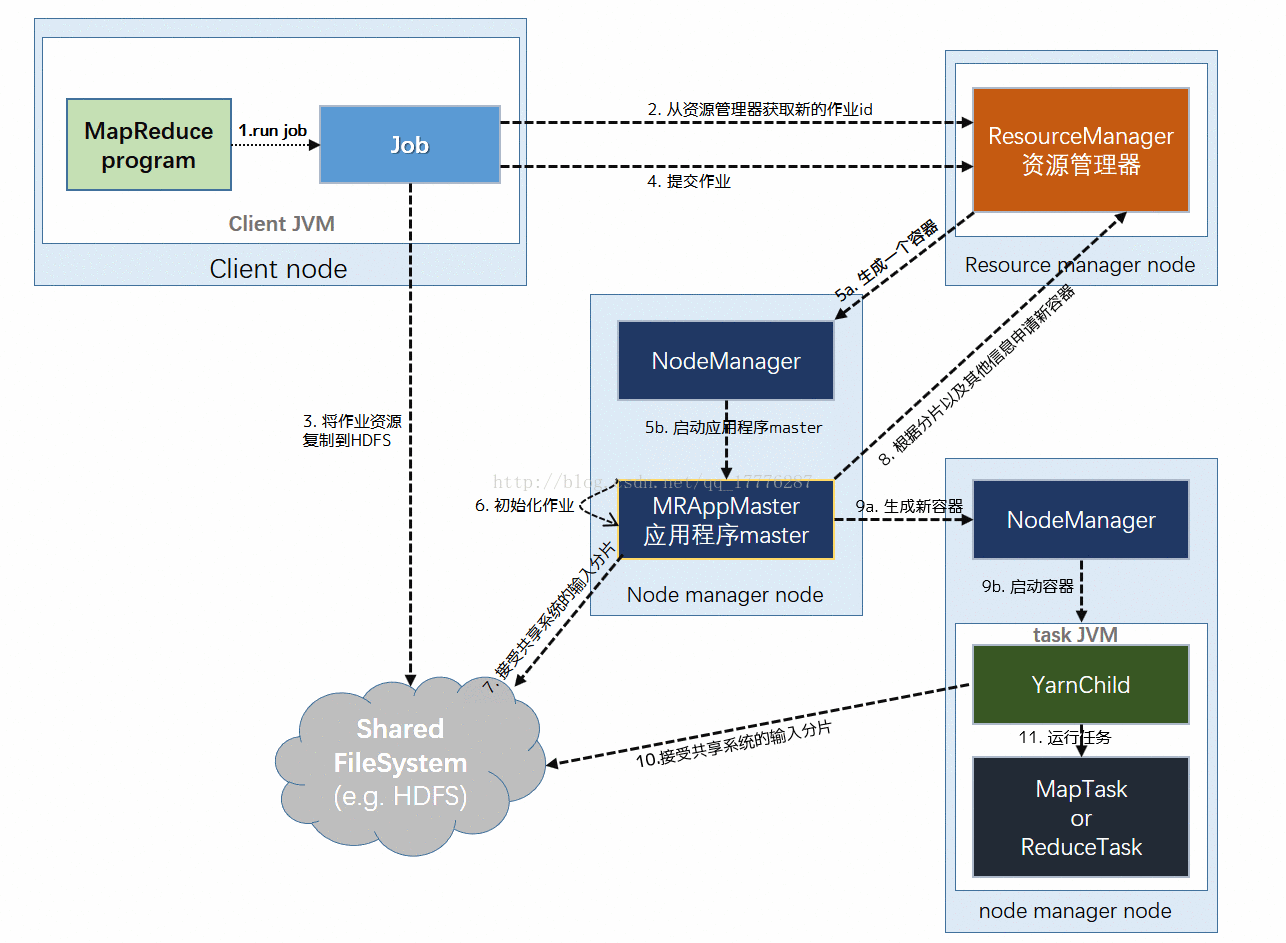
(3)任务分配
- ApplicationMaster 为该作业中的所有 map 任务和 reduce 任务向 RM 请求 Container (步骤8);【随着心跳信息的请求包括每个map任务的数据本地化信息,特别是输入分片所在的主机和相应机架信息。理想情况下,它将任务分配到数据本地化的节点,但如果不可能这么做,就会相对于本地化的分配优先使用机架本地化的分配】
请求也为任务指定了内存需求。在默认情况下, map任务和reduce任务都分配到 1024MB 的内存,但这可以通过 mapreduce.map.memory.mb 和 mapreduce.reduce.memory.mb来设置。
(4)任务执行
- 一旦 RM 的 scheduler 为任务分配了 Container, ApplicationMaster就通过与 NM通信来启动 Container (步骤9a & 9b);
- 该任务由主类为 YardChild 的Java应用程序执行。在它运行任务之前,首先将任务需要的资源本地化(包括作业的配置、JAR文件和所有来自分布式缓存的文件)(步骤10);
- 最后,运行 map 任务或 reduce 任务(步骤11)。
(5)进度和状态的更新
- 在YARN下运行,任务每 3s通过 umbilical 接口向 ApplicationMaster 汇报进度和状态(包括计数器),作为作业的汇聚试图(aggregate view)。
(6)作业完成
- 除了向 ApplicationMaster 查询进度外,Client 每 5s还通过调用 Job 的 waitForCompletion() 来检查作业是否完成【查询的间隔可以通过 mapreduce.client.completion.pollinterval 属性进行设置】。
- 作业完成后, ApplicationMaster 和任务容器清理其工作状态, OutputCommitter 的作业清理方法会被调用。作业历史服务器保存作业的信息供用户需要时查询。

转载地址:https://buildupchao.blog.csdn.net/article/details/78176515 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
