本文共 3170 字,大约阅读时间需要 10 分钟。
文章目录
预测用户是否为QQ超级会员
根据前面的内容人人都可以做深度学习应用:入门篇(上)人人都可以做深度学习应用:入门篇(中),我们对上述基于softmax只是三层(输入、处理、输出)的神经网络模型已经比较熟悉,那么,这个模型是否可以应用到我们具体的业务场景中,其中的难度大吗?为了验证这一点,我拿了一些现网的数据来做了这个试验。
1. 数据准备

用于训练的样本数据格式如下:

第一列是QQ号码,只做认知标识的,第二列表示是否超级会员身份,作为训练的标签值,后面的就是IP地址,平台标志位以及参与活动的参与记录(0是未成功参与,1表示成功参与)。则获得一个拥有11个特征的数组(经过一些转化和映射,将特别大的数变小):
[0.9166666666666666, 0.4392156862745098, 0.984313725490196, 0.7411764705882353,
0.2196078431372549, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0]
对应的是否是超级数据格式如下,作为监督学习的标签:超级会员:[0, 1],非超级会员:[1, 0]
这里需要专门解释下,在实际应用中需要做数据转换的原因。一方面,将这些数据做一个映射转化,有助于简化数据模型。另一方面,是为了规避NaN的问题,当数值过大,在一些数学指数和除法的浮点数运算中,有可能得到一个无穷大的数值,或者其他溢出的情形,在Python里会变为NaN类型,这个类型会破坏掉后续全部计算结果,导致计算异常。
例如下图,就是特征数值过大,在训练过程中,导致中间某些参数累计越来越大,最终导致产生NaN值,后续的计算结果全部被破坏掉:
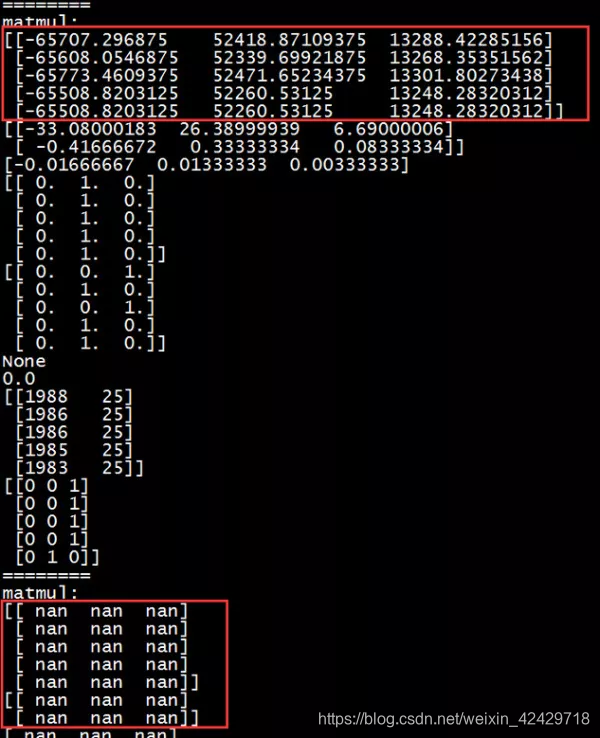
而导致NaN的原因在复杂的数学计算里,会产生无穷大或者无穷小。例如,在我们的这个demo中,产生NaN的原因,主要是因为softmax的计算导致。
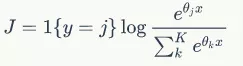

刚开始做实际的业务应用,就发现经常跑出极奇怪异的结果(遇到NaN问题,我发现程序也能继续走下去),几经排查才发现是NAN值问题,是非常令人沮丧的。当然,经过仔细分析问题,发现也并非没有排查的方式。因为,NaN值是个奇特的类型,可以采用下述编码方式NaN != NaN来检测自己的训练过程中,是否出现的NaN。
关键程序代码如下:
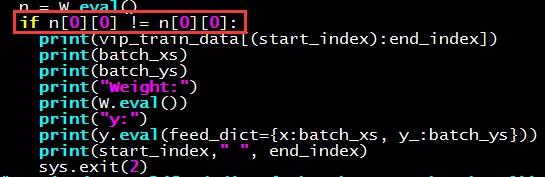
我采用上述方法,非常顺利地找到自己的深度学习程序,在学习到哪一批数据时产生的NaN。因此,很多原始数据我们都会做一个除以某个值,让数值变小的操作。例如官方的MNIST也是这样做的,将256的像素颜色的数值统一除以255,让它们都变成一个小于1的浮点数。
MNIST在处理原始图片像素特征数据时,也对特征数据进行了变小处理:
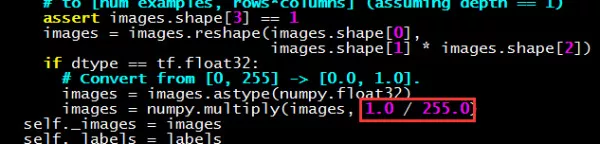
处理NaN问题更专业的方法,就是对输入数据进行归一化处理(min-max标准化或Z-score标准化方法),将值控制在一个可控的范围内。NaN值问题曾一度深深地困扰着我,特别放到这里,避免入门的同学踩坑。
2. 执行结果
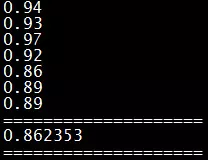
我准备的训练集(6700)和测试集(1000)数据并不多,不过,超级会员身份的预测准确率最终可以达到87%。虽然,预测准确率是不高,这个可能和我的训练集数据比较少有关系,不过,整个模型也没有花费多少时间,从整理数据、编码、训练到最终跑出结果,只用了2个晚上的时间。
下图是两个实际的测试例子,例如,该模型预测第一个QQ用户有82%的概率是非超级会员用户,17.9%的概率为超级会员用户(该预测是准确的)。
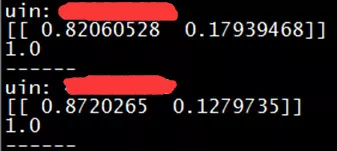
通过上面的这个例子,我们会发觉其实对于某些比较简单的场景下应用,我们是可以比较容易就实现的。
其它模型
1. CIFAR-10识别图片分类的demo(官方)
CIFAR-10数据集的分类是机器学习中一个公开的基准测试问题,它任务是对一组32x32RGB的图像进行分类,这些图像涵盖了10个类别:飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船和卡车。
这也是官方的重要demo之一。

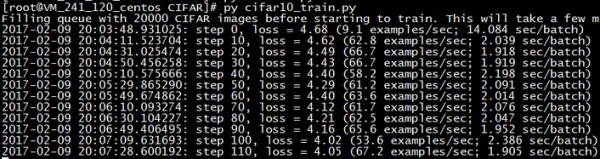
该例子执行的过程比较长,需要耐心等待,x下面是我在机器上的执行过程和结果:
cifar10_train.py用于训练:
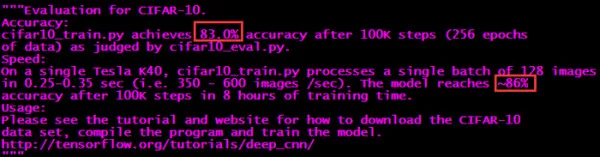
cifar10_eval.py用于检验结果:

识别率不高是因为该官方模型的识别率本来就不高:
2. 是否大于5岁的测试demo
为了检验softma回归模型是否能够学习到一些我自己设定好的规则,我做了一个小demo来测试。我通过随机数生成的方式构造了一系列的数据,让前面的softmax回归模型去学习,最终看看模型能否通过训练集的学习,最终100%预测这个样本数据是否大于5岁。
模型和数据本身都比较简单,构造数据的方式:我随机构造一个只有2个特征纬度的样本数据,[year, 1],其中year随机取值0-10,数字1是放进去作为干扰:如果year大于5岁,则标签设置为:[0, 0, 1];否则,标签设置为:[0, 1, 0]。
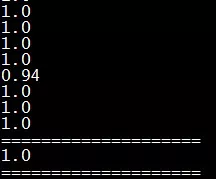
生成了6000条假训练集去训练该模型,最终它能做到100%成功预测准确:
3. 基于RNN的古诗学习
最开头的AI写古诗,非常令人感到惊艳,那个demo是美国的一个研究者做出来的,能够根据主题生成不能的古诗,而且古诗的质量还比较高。于是,我也尝试在自己的机器上也跑一个能够写古诗的模型,后来我找到的是一个基于RNN的模型。RNN循环神经网络(Recurrent Neural Networks),是非常常用的深度学习模型之一。我基于一个外部的demo,进行一些调整后跑起一个能够学习古诗和写古诗的比较简单的程序。
我的程序默认配置是读取三万首诗(做了一些过滤,将格式有误的或者非五言、七言的过滤掉),执行写诗(让它写了十首):

另外,我抽取其中一些个人认为写得比较好的诗句(以前跑出来的,不在上图中)

该模型比较简单,写诗的水平不如最前面我介绍的美国研究者demo,但是,所采用的基本方法应该是类似的,只是他做的更为复杂。
另外,这是一个通用模型,可以学习不同的内容(古诗、现代诗、宋词或者英文诗等),就可以生成对应的结果。
深度学习的入门学习体会
-
人工智能和深度学习技术并不神秘,更像是一个新型的工具,通过喂数据给它,然后,它能发现这些数据背后的规律,并为我们所用。
-
数学基础比较重要,这样有助于理解模型背后的数学原理,不过,从纯应用角度来说,并不一定需要完全掌握数学,也可以提前开始做一些尝试和学习。
-
我深深地感到计算资源非常缺乏,每次调整程序的参数或训练数据后,跑完一次训练集经常要很多个小时,部分场景不跑多一些训练集数据,看不出差别,例如写诗的案例。个人感觉,这个是制约AI发展的重要问题,它直接让程序的“调试”效率非常低下。
-
中文文档比较少,英文文档也不多,开源社区一直在快速更新,文档的内容过时也比较快。因此,入门学习时遇到的问题会比较多,并且缺乏成型的文档。
小结
我们不知道人工智能的时代是否真的会来临,也不知道它将要走向何方,但是,毫无疑问,它是一种全新的技术思维模式。更好的探索和学习这种新技术,然后在业务应用场景寻求结合点,最终达到帮助我们的业务获得更好的成果,一直以来,就是我们工程师的不懈追求。另一方面,对发展有重大推动作用的新技术,通常会快速的发展并且走向普及,就如同我们的编程一样,因此,人人都可以做深度学习应用,并非只是一句噱头。
转载地址:https://chocolate.blog.csdn.net/article/details/104165566 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
