本文共 5493 字,大约阅读时间需要 18 分钟。
长文预警: 共22727字
注意:文末附有所有源码的地址
建议:收藏后找合适时间阅读。

| 六、实战手写数字识别 |
之前的五篇博客讲述的内容应该覆盖了如何编写神经网络的大部分内容,在经过之前的一系列努力之后,终于可以开始实战了。试试写出来的神经网络怎么样吧。
| 数据准备 |
MNIST数据集
有人说MNIST手写数字识别是机器学习领域的Hello World,所以我这一次也是从手写字体识别开始。我是从Kaggle找的手写数字识别的数据集。数据已经被保存为csv格式,相对比较方便读取。
数据集包含了数字0-9是个数字的灰度图。但是这个灰度图是展开过的。展开之前都是28x28的图像,展开后成为1x784的一行。csv文件中,每一行有785个元素,第一个元素是数字标签,后面的784个元素分别排列着展开后的184个像素。看起来像下面这样:
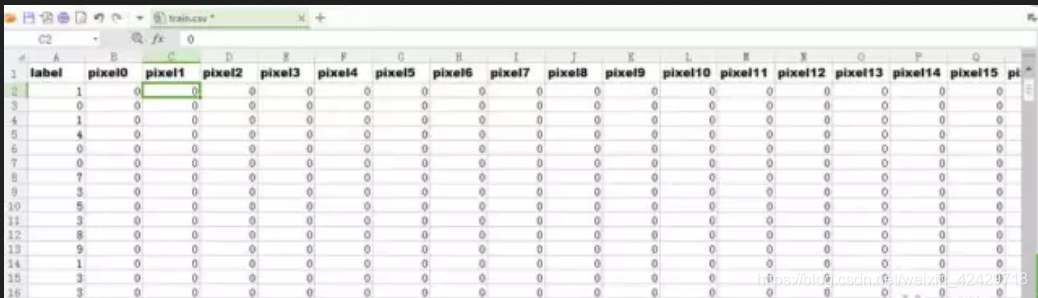

csv文件中包含42000个样本,这么多样本,对于我七年前买的4000元级别的破笔记本来说,单单是读取一次都得半天,更不要提拿这么多样本去迭代训练了,简直是噩梦(兼论一个苦逼的学生几年能挣到换电脑的钱!)。所以我只是提取了前1000个样本,然后把归一化后的样本和标签都保存到一个xml文件中。在前面的一篇博客中已经提到了输入输出的组织形式,偷懒直接复制了。
既然说到了输出的组织方式,那就顺便也提一句输入的组织方式。生成神经网络的时候,每一层都是用一个单列矩阵来表示的。显然第一层输入层就是一个单列矩阵。所以在对数据进行预处理的过程中,我就是把输入样本和标签一列一列地排列起来,作为矩阵存储。标签矩阵的第一列即是第一列样本的标签。以此类推。
把输出层设置为一个单列十行的矩阵,标签是几就把第几行的元素设置为1,其余都设为0。由于编程中一般都是从0开始作为第一位的,所以位置与0-9的数字正好一一对应。我们到时候只需要找到输出最大值所在的位置,也就知道了输出是几。”
这里只是重复一下,这一部分的代码在csv2xml.cpp中:
#include#include using namespace std;using namespace cv;//int csv2xml()int main(){ CvMLData mlData; mlData.read_csv("train.csv");//读取csv文件 Mat data = cv::Mat(mlData.get_values(), true); cout << "Data have been read successfully!" << endl; //Mat double_data; //data.convertTo(double_data, CV_64F); Mat input_ = data(Rect(1, 1, 784, data.rows - 1)).t(); Mat label_ = data(Rect(0, 1, 1, data.rows - 1)); Mat target_(10, input_.cols, CV_32F, Scalar::all(0.)); Mat digit(28, 28, CV_32FC1); Mat col_0 = input_.col(3); float label0 = label_.at (3, 0); cout << label0; for (int i = 0; i < 28; i++) { for (int j = 0; j < 28; j++) { digit.at (i, j) = col_0.at (i * 28 + j); } } for (int i = 0; i < label_.rows; ++i) { float label_num = label_.at (i, 0); //target_.at (label_num, i) = 1.; target_.at (label_num, i) = label_num; } Mat input_normalized(input_.size(), input_.type()); for (int i = 0; i < input_.rows; ++i) { for (int j = 0; j < input_.cols; ++j) { //if (input_.at (i, j) >= 1.) //{ input_normalized.at (i, j) = input_.at (i, j) / 255.; //} } } string filename = "input_label_0-9.xml"; FileStorage fs(filename, FileStorage::WRITE); fs << "input" << input_normalized; fs << "target" << target_; // Write cv::Mat fs.release(); Mat input_1000 = input_normalized(Rect(0, 0, 10000, input_normalized.rows)); Mat target_1000 = target_(Rect(0, 0, 10000, target_.rows)); string filename2 = "input_label_0-9_10000.xml"; FileStorage fs2(filename2, FileStorage::WRITE); fs2 << "input" << input_1000; fs2 << "target" << target_1000; // Write cv::Mat fs2.release(); return 0;}
这是我最近用ReLU的时候的代码,标签是几就把第几位设为几,其他为全设为0。最后都是找到最大值的位置即可。
在代码中Mat digit的作用是,检验下转换后的矩阵和标签是否对应正确这里是把col(3),也就是第四个样本从一行重新变成28x28的图像,看上面的第一张图的第一列可以看到,第四个样本的标签是4。那么它转换回来的图像时什么样呢?是下面这样:

然后在使用的时候用前面提到过的get_input_label()获取一定数目的样本和标签。
| 实战数字识别 |
实战
没想到前面数据处理说了那么多。。。。
废话少说,直接说训练的过程:
-
给定每层的神经元数目,初始化神经网络和权值矩阵
-
从inputlabel1000.xml文件中取前800个样本作为训练样本,后200作为测试样本。
-
这是神经网络的一些参数:训练时候的终止条件,学习率,激活函数类型
-
前800样本训练神经网络,直到满足loss小于阈值loss_threshold,停止。
-
后200样本测试神经网络,输出正确率。
-
保存训练得到的模型。
以sigmoid为激活函数的训练代码如下:
#include"../include/Net.h"//using namespace std;using namespace cv;using namespace liu;int main(int argc, char *argv[]){ //Set neuron number of every layer vector layer_neuron_num = { 784,100,10 }; // Initialise Net and weights Net net; net.initNet(layer_neuron_num); net.initWeights(0, 0., 0.01); net.initBias(Scalar(0.5)); //Get test samples and test samples Mat input, label, test_input, test_label; int sample_number = 800; get_input_label("data/input_label_1000.xml", input, label, sample_number); get_input_label("data/input_label_1000.xml", test_input, test_label, 200, 800); //Set loss threshold,learning rate and activation function float loss_threshold = 0.5; net.learning_rate = 0.3; net.output_interval = 2; net.activation_function = "sigmoid"; //Train,and draw the loss curve(cause the last parameter is ture) and test the trained net net.train(input, label, loss_threshold, true); net.test(test_input, test_label); //Save the model net.save("models/model_sigmoid_800_200.xml"); getchar(); return 0;}
对比前面说的六个过程,代码应该是很清晰的了。参数output_interval是间隔几次迭代输出一次,这设置为迭代两次输出一次。
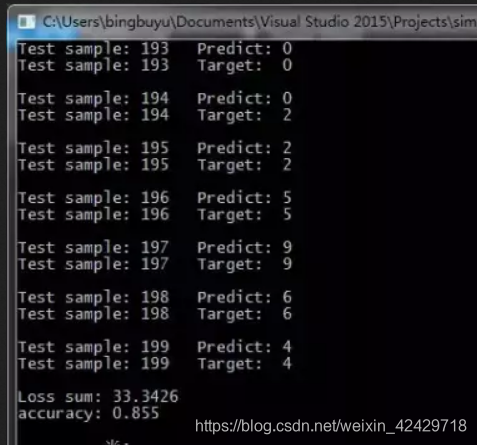
如果按照上面的参数来训练,正确率是0.855:
如果要直接使用训练好的样本,那就更加简单了:
//Get test samples and the label is 0--1 Mat test_input, test_label; int sample_number = 200; int start_position = 800; get_input_label("data/input_label_1000.xml", test_input, test_label, sample_number, start_position); //Load the trained net and test. Net net; net.load("models/model_sigmoid_800_200.xml"); net.test(test_input, test_label); getchar(); return 0; 如果激活函数是tanh函数,由于tanh函数的值域是[-1,1],所以在训练的时候要把标签矩阵稍作改动,需要改动的地方如下:
//Set loss threshold,learning rate and activation function float loss_threshold = 0.2; net.learning_rate = 0.02; net.output_interval = 2; net.activation_function = "tanh"; //convert label from 0---1 to -1---1,cause tanh function range is [-1,1] label = 2 * label - 1; test_label = 2 * test_label - 1;
这里不光改了标签,还有几个参数也是需要改以下的,学习率比sigmoid的时候要小一个量级,效果会比较好。这样训练出来的正确率大概在0.88左右,也是可以接受的。
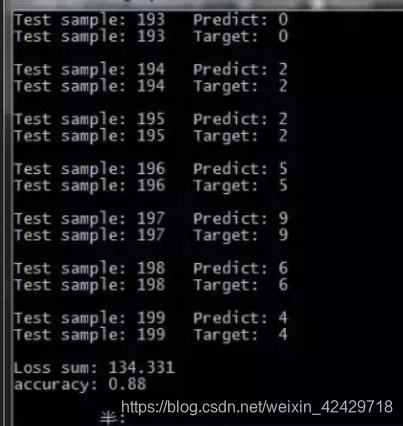
源码链接
所有的代码都已经托管在Github上面,感兴趣的可以去下载查看。源码链接地址为
https://github.com/LiuXiaolong19920720/simple_net
学如逆水行舟,不进则退
转载地址:https://chocolate.blog.csdn.net/article/details/104168112 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
