卷积神经网络交通标志识别
发布日期:2021-06-29 15:45:34
浏览次数:2
分类:技术文章
本文共 51832 字,大约阅读时间需要 172 分钟。
# 加载数据import pickle# 数据集所在的文件位置training_file = "/content/drive/traffic-signs-data/train.p"validation_file = "/content/drive/traffic-signs-data/valid.p"testing_file = "/content/drive/traffic-signs-data/test.p"# 打开文件with open(training_file,mode="rb") as f: train = pickle.load(f)with open(validation_file,mode="rb") as f: valid = pickle.load(f)with open(testing_file,mode="rb") as f: test = pickle.load(f)# 获取数据集的特征及标签数据X_train,y_train = train["features"],train["labels"]X_valid,y_valid = valid["features"],valid["labels"]X_test,y_test = test["features"],test["labels"]
# 查看数据量print("Number of training examples =",X_train.shape[0])print("Number of validtion examples =",X_valid.shape[0])print("Number of testing examples=",X_test.shape[0])# 查看数据格式print("Image data shape =",X_train.shape[1:]) Number of training examples = 34799Number of validtion examples = 4410Number of testing examples= 12630Image data shape = (32, 32, 3)
# 查看数据的标签的数量import numpy as npsum = np.unique(y_train)print("number of classes =",len(sum)) number of classes = 43
# 查看标签数据import pandas as pdsign_names_file = "/content/drive/traffic-signs-data/signnames.csv"sign_names = pd.read_csv(sign_names_file)print(sign_names)
ClassId SignName0 0 Speed limit (20km/h)1 1 Speed limit (30km/h)2 2 Speed limit (50km/h)3 3 Speed limit (60km/h)4 4 Speed limit (70km/h)5 5 Speed limit (80km/h)6 6 End of speed limit (80km/h)7 7 Speed limit (100km/h)8 8 Speed limit (120km/h)9 9 No passing10 10 No passing for vehicles over 3.5 metric tons11 11 Right-of-way at the next intersection12 12 Priority road13 13 Yield14 14 Stop15 15 No vehicles16 16 Vehicles over 3.5 metric tons prohibited17 17 No entry18 18 General caution19 19 Dangerous curve to the left20 20 Dangerous curve to the right21 21 Double curve22 22 Bumpy road23 23 Slippery road24 24 Road narrows on the right25 25 Road work26 26 Traffic signals27 27 Pedestrians28 28 Children crossing29 29 Bicycles crossing30 30 Beware of ice/snow31 31 Wild animals crossing32 32 End of all speed and passing limits33 33 Turn right ahead34 34 Turn left ahead35 35 Ahead only36 36 Go straight or right37 37 Go straight or left38 38 Keep right39 39 Keep left40 40 Roundabout mandatory41 41 End of no passing42 42 End of no passing by vehicles over 3.5 metric ...
# 定义将标签id转换成name的函数sign_names = np.array(sign_names)def id_to_name(id): return sign_names[id][1]
# 验证是否id_to_name函数id_to_name(0)
'Speed limit (20km/h)'
# 绘制交通标志图import matplotlib.pyplot as plt%matplotlib inlinefig,axes = plt.subplots(2,5,figsize=(18,5))ax_array = axes.ravel()for ax in ax_array: index = np.random.randint(0,len(X_train)) ax.imshow(X_train[index]) ax.axis("off") ax.set_title(id_to_name(y_train[index]))plt.show() 
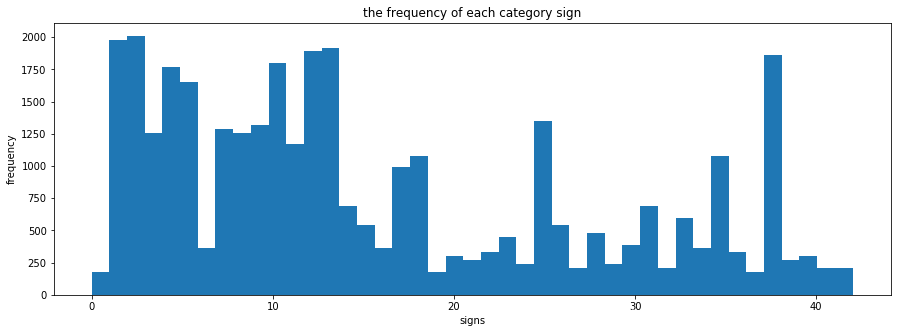
# 直方图来展示图像训练集的各个类别的分布情况n_classes = len(sum)def plot_y_train_hist(): fig = plt.figure(figsize=(15,5)) ax = fig.add_subplot(1,1,1) hist = ax.hist(y_train,bins = n_classes) ax.set_title("the frequency of each category sign") ax.set_xlabel("signs") ax.set_ylabel("frequency") plt.show() return histprint(X_train.shape)print(y_train.shape)hist = plot_y_train_hist() (34799, 32, 32, 3)(34799,)
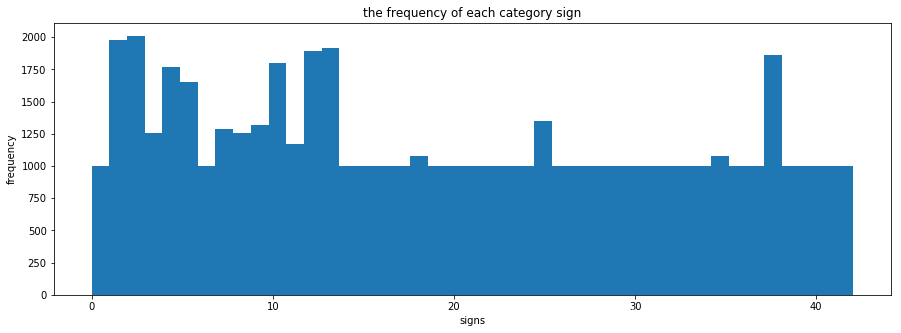
# 数据重采样,使样本个数分配均匀bin_edges = hist[1]bin_centers = (bin_edges[1:] + bin_edges[0:len(bin_edges)-1])/2for i in range(len(bin_centers)): if hist[0][i] < 1000: train_data = [X_train[j] for j in range(len(y_train)) if y_train[j] == i] need_resample_num = int(1000 - hist[0][i]) new_data_x = [np.copy(train_data[np.random.randint(len(train_data))]) for k in range(need_resample_num)] new_data_y = [i for x in range(need_resample_num)] X_train = np.vstack((X_train, np.array(new_data_x))) y_train = np.hstack((y_train, np.array(new_data_y)))print(X_train.shape)print(y_train.shape)plot_y_train_hist()
(51690, 32, 32, 3)(51690,)
(array([1000., 1980., 2010., 1260., 1770., 1650., 1000., 1290., 1260., 1320., 1800., 1170., 1890., 1920., 1000., 1000., 1000., 1000., 1080., 1000., 1000., 1000., 1000., 1000., 1000., 1350., 1000., 1000., 1000., 1000., 1000., 1000., 1000., 1000., 1000., 1080., 1000., 1000., 1860., 1000., 1000., 1000., 1000.]), array([ 0. , 0.97674419, 1.95348837, 2.93023256, 3.90697674, 4.88372093, 5.86046512, 6.8372093 , 7.81395349, 8.79069767, 9.76744186, 10.74418605, 11.72093023, 12.69767442, 13.6744186 , 14.65116279, 15.62790698, 16.60465116, 17.58139535, 18.55813953, 19.53488372, 20.51162791, 21.48837209, 22.46511628, 23.44186047, 24.41860465, 25.39534884, 26.37209302, 27.34883721, 28.3255814 , 29.30232558, 30.27906977, 31.25581395, 32.23255814, 33.20930233, 34.18604651, 35.1627907 , 36.13953488, 37.11627907, 38.09302326, 39.06976744, 40.04651163, 41.02325581, 42. ]), )
二、数据预处理
# 源图像src = X_train[4000]plt.imshow(src)print(src.shape)
(32, 32, 3)

# 转为灰度图像import cv2dst = cv2.cvtColor(src,cv2.COLOR_RGB2GRAY)plt.imshow(dst)print(dst.shape)
(32, 32)
# 灰度图的直方图plt.hist(dst.ravel(),256,[0,256],color="r")plt.show()
# 灰度图的直方图均衡化dst2 = cv2.equalizeHist(dst)plt.hist(dst2.ravel(),256,[0,256],color="r")plt.show()
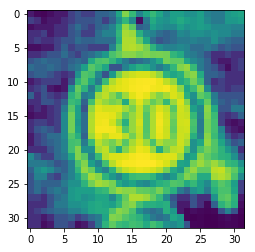
# 查看直方图均衡化的图片plt.imshow(dst2)
# 增加维度print(dst2.shape)dst3 = np.expand_dims(dst2,2)print(dst3.shape)
(32, 32)(32, 32, 1)
# 归一化处理dst4 = np.array(dst3,dtype=np.float32)dst4 = (dst4-128)/128
# 查看一下归一化处理后的图像数据dst4[0]
array([[-0.859375 ], [-0.9609375], [-0.9765625], [-0.9296875], [-0.859375 ], [-0.859375 ], [-0.625 ], [-0.484375 ], [-0.625 ], [-0.625 ], [-0.375 ], [-0.375 ], [-0.2890625], [ 0.171875 ], [ 0.6171875], [ 0.3359375], [-0.1171875], [ 0.171875 ], [ 0.3359375], [ 0.171875 ], [-0.0546875], [ 0.125 ], [ 0.125 ], [ 0.0078125], [ 0.0078125], [ 0.125 ], [-0.1171875], [-0.1875 ], [-0.1875 ], [ 0.0625 ], [ 0.125 ], [ 0.171875 ]], dtype=float32)
# 封装数据预处理的方法import cv2def preprocess_features(X, equalize_hist=True): normalized_X = [] for i in range(len(X)): # Convert from RGB to YUV yuv_img = cv2.cvtColor(X[i], cv2.COLOR_RGB2YUV) yuv_img_v = X[i][:, :, 0] # equalizeHist yuv_img_v = cv2.equalizeHist(yuv_img_v) # expand_dis yuv_img_v = np.expand_dims(yuv_img_v, 2) normalized_X.append(yuv_img_v) # normalize normalized_X = np.array(normalized_X, dtype=np.float32) normalized_X = (normalized_X-128)/128 # normalized_X /= (np.std(normalized_X, axis=0) + np.finfo('float32').eps) return normalized_X # 对数据集整体进行处理X_train_normalized = preprocess_features(X_train)X_valid_normalized = preprocess_features(X_valid)X_test_normalized = preprocess_features(X_test)
# 将数据集打乱from sklearn.utils import shuffleX_train_normalized,y_train = shuffle(X_train_normalized,y_train)
# 数据增强from keras.preprocessing.image import ImageDataGenerator# 图像数据生成器image_datagen = ImageDataGenerator(rotation_range = 10., zoom_range = 0.2, width_shift_range = 0.08, height_shift_range = 0.08 )# 从训练集随意选取一张图片index = np.random.randint(0, len(X_train_normalized))img = X_train_normalized[index]# 展示原始图片plt.figure(figsize=(1, 1))plt.imshow(np.squeeze(img), cmap="gray")plt.title('Example of GRAY image (name = {})'.format(id_to_name(y_train[index])))plt.axis('off')plt.show()# 展示数据增强生成的图片fig, ax_array = plt.subplots(3, 10, figsize=(15, 5))for ax in ax_array.ravel(): images = np.expand_dims(img, 0) # np.expand_dims(img, 0) means add dim augmented_img, _ = image_datagen.flow(np.expand_dims(img, 0), np.expand_dims(y_train[index], 0)).next() #augmented_img=preprocess_features(augmented_img) ax.imshow(augmented_img.squeeze(), cmap="gray") ax.axis('off')plt.suptitle('Random examples of data augment (starting from the previous image)')plt.show() Using TensorFlow backend.

print("Number of training examples =",X_train.shape[0]) Number of training examples = 51690
# 对标签数据进行one-hot编码from keras.utils import np_utilsprint("Shape before one-hot encoding:",y_train.shape)Y_train = np_utils.to_categorical(y_train,n_classes)Y_valid = np_utils.to_categorical(y_valid,n_classes)Y_test = np_utils.to_categorical(y_test,n_classes)print("Shape after one-hot encoding:",Y_train.shape) Shape before one-hot encoding: (51690,)Shape after one-hot encoding: (51690, 43)
print(y_train[0])print(Y_train[0])
24[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
三、交通标志牌的识别模型搭建
1.2层Conv2D+1层MaxPooling2D+1层Drop(0.25)+1层Flatten+1层Dense+1层Dropout层(0.5)+1层Dense
from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Flattenfrom keras.layers import Conv2D, MaxPooling2Dmodel = Sequential()## Feature Extraction# 第1层卷积,32个3x3的卷积核 ,激活函数使用 relumodel.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=X_train_normalized.shape[1:]))# 第2层卷积,64个3x3的卷积核,激活函数使用 relumodel.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))# 最大池化层,池化窗口 2x2model.add(MaxPooling2D(pool_size=(2, 2)))# Dropout 25% 的输入神经元model.add(Dropout(0.25))# 将 Pooled feature map 摊平后输入全连接网络model.add(Flatten())## Classification# 全联接层model.add(Dense(128, activation='relu'))# Dropout 50% 的输入神经元model.add(Dropout(0.5))# 使用 softmax 激活函数做多分类,输出各类别的概率model.add(Dense(n_classes, activation='softmax'))
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.Instructions for updating:Colocations handled automatically by placer.WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.Instructions for updating:Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
# 查看模型的结构model.summary()
_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d_1 (Conv2D) (None, 30, 30, 32) 320 _________________________________________________________________conv2d_2 (Conv2D) (None, 28, 28, 64) 18496 _________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 14, 14, 64) 0 _________________________________________________________________dropout_1 (Dropout) (None, 14, 14, 64) 0 _________________________________________________________________flatten_1 (Flatten) (None, 12544) 0 _________________________________________________________________dense_1 (Dense) (None, 128) 1605760 _________________________________________________________________dropout_2 (Dropout) (None, 128) 0 _________________________________________________________________dense_2 (Dense) (None, 43) 5547 =================================================================Total params: 1,630,123Trainable params: 1,630,123Non-trainable params: 0_________________________________________________________________
# 编译模型model.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer="adam")
# 训练模型history = model.fit(X_train_normalized, Y_train, batch_size=256, epochs=120, verbose=2, validation_data=(X_valid_normalized,Y_valid))
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.Instructions for updating:Use tf.cast instead.Train on 51690 samples, validate on 4410 samplesEpoch 1/120 - 7s - loss: 1.2242 - acc: 0.6591 - val_loss: 0.3351 - val_acc: 0.8957Epoch 2/120 - 4s - loss: 0.2724 - acc: 0.9174 - val_loss: 0.2139 - val_acc: 0.9370Epoch 3/120 - 4s - loss: 0.1670 - acc: 0.9492 - val_loss: 0.1646 - val_acc: 0.9490Epoch 4/120 - 4s - loss: 0.1190 - acc: 0.9622 - val_loss: 0.1639 - val_acc: 0.9467Epoch 5/120 - 4s - loss: 0.0910 - acc: 0.9709 - val_loss: 0.1620 - val_acc: 0.9537Epoch 6/120 - 4s - loss: 0.0770 - acc: 0.9752 - val_loss: 0.1439 - val_acc: 0.9585Epoch 7/120 - 4s - loss: 0.0656 - acc: 0.9795 - val_loss: 0.1304 - val_acc: 0.9587Epoch 8/120 - 4s - loss: 0.0572 - acc: 0.9809 - val_loss: 0.1411 - val_acc: 0.9601Epoch 9/120 - 4s - loss: 0.0514 - acc: 0.9835 - val_loss: 0.1529 - val_acc: 0.9562Epoch 10/120 - 4s - loss: 0.0473 - acc: 0.9847 - val_loss: 0.1166 - val_acc: 0.9642Epoch 11/120 - 4s - loss: 0.0427 - acc: 0.9863 - val_loss: 0.1336 - val_acc: 0.9619Epoch 12/120 - 4s - loss: 0.0371 - acc: 0.9879 - val_loss: 0.1309 - val_acc: 0.9635Epoch 13/120 - 4s - loss: 0.0380 - acc: 0.9874 - val_loss: 0.1194 - val_acc: 0.9685Epoch 14/120 - 4s - loss: 0.0315 - acc: 0.9898 - val_loss: 0.1403 - val_acc: 0.9633Epoch 15/120 - 4s - loss: 0.0328 - acc: 0.9889 - val_loss: 0.1469 - val_acc: 0.9574Epoch 16/120 - 4s - loss: 0.0292 - acc: 0.9903 - val_loss: 0.1241 - val_acc: 0.9689Epoch 17/120 - 4s - loss: 0.0291 - acc: 0.9903 - val_loss: 0.1307 - val_acc: 0.9673Epoch 18/120 - 4s - loss: 0.0265 - acc: 0.9910 - val_loss: 0.1434 - val_acc: 0.9651Epoch 19/120 - 4s - loss: 0.0259 - acc: 0.9914 - val_loss: 0.1291 - val_acc: 0.9680Epoch 20/120 - 4s - loss: 0.0246 - acc: 0.9916 - val_loss: 0.1332 - val_acc: 0.9635Epoch 21/120 - 4s - loss: 0.0231 - acc: 0.9922 - val_loss: 0.1261 - val_acc: 0.9671Epoch 22/120 - 4s - loss: 0.0232 - acc: 0.9923 - val_loss: 0.1301 - val_acc: 0.9680Epoch 23/120 - 4s - loss: 0.0198 - acc: 0.9932 - val_loss: 0.1388 - val_acc: 0.9669Epoch 24/120 - 4s - loss: 0.0226 - acc: 0.9923 - val_loss: 0.1210 - val_acc: 0.9719Epoch 25/120 - 4s - loss: 0.0212 - acc: 0.9930 - val_loss: 0.1297 - val_acc: 0.9683Epoch 26/120 - 4s - loss: 0.0206 - acc: 0.9932 - val_loss: 0.1344 - val_acc: 0.9687Epoch 27/120 - 4s - loss: 0.0203 - acc: 0.9932 - val_loss: 0.1495 - val_acc: 0.9692Epoch 28/120 - 4s - loss: 0.0200 - acc: 0.9935 - val_loss: 0.1305 - val_acc: 0.9696Epoch 29/120 - 4s - loss: 0.0181 - acc: 0.9938 - val_loss: 0.1436 - val_acc: 0.9685Epoch 30/120 - 4s - loss: 0.0167 - acc: 0.9944 - val_loss: 0.1377 - val_acc: 0.9673 - 7s - loss: 0.0072 - acc: 0.9977 - val_loss: 0.1146 - val_acc: 0.9823Epoch 111/120 - 7s - loss: 0.0059 - acc: 0.9981 - val_loss: 0.1531 - val_acc: 0.9741Epoch 112/120 - 7s - loss: 0.0065 - acc: 0.9977 - val_loss: 0.1157 - val_acc: 0.9805Epoch 113/120 - 7s - loss: 0.0061 - acc: 0.9980 - val_loss: 0.1638 - val_acc: 0.9717Epoch 114/120 - 7s - loss: 0.0055 - acc: 0.9983 - val_loss: 0.1301 - val_acc: 0.9794Epoch 115/120 - 7s - loss: 0.0041 - acc: 0.9985 - val_loss: 0.1501 - val_acc: 0.9773Epoch 116/120 - 5s - loss: 0.0066 - acc: 0.9976 - val_loss: 0.1437 - val_acc: 0.9757Epoch 117/120 - 4s - loss: 0.0064 - acc: 0.9979 - val_loss: 0.1508 - val_acc: 0.9780Epoch 118/120 - 4s - loss: 0.0066 - acc: 0.9978 - val_loss: 0.1489 - val_acc: 0.9769Epoch 119/120 - 4s - loss: 0.0065 - acc: 0.9980 - val_loss: 0.1378 - val_acc: 0.9766Epoch 120/120 - 4s - loss: 0.0059 - acc: 0.9982 - val_loss: 0.1255 - val_acc: 0.9789
# 可视化指标fig = plt.figure()plt.subplot(2,1,1)plt.plot(history.history['acc'])plt.plot(history.history['val_acc'])plt.title('Model Accuracy')plt.ylabel('accuracy')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='lower right')plt.subplot(2,1,2)plt.plot(history.history['loss'])plt.plot(history.history['val_loss'])plt.title('Model Loss')plt.ylabel('loss')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='upper right')plt.tight_layout()plt.show() 
# 保存模型import osimport tensorflow.gfile as gfilesave_dir = "/content/drive/model/v1/"if gfile.Exists(save_dir): gfile.DeleteRecursively(save_dir)gfile.MakeDirs(save_dir)model_name = 'keras_traffic_1.h5'model_path = os.path.join(save_dir, model_name)model.save(model_path)print('Saved trained model at %s ' % model_path) Saved trained model at /content/drive/model/v1/keras_traffic_1.h5
# 加载模型from keras.models import load_modeltraffic_model = load_model(model_path)
# 统计模型在测试集上的分类结果loss_and_metrics = traffic_model.evaluate(X_test_normalized, Y_test, verbose=2,batch_size=256) print("Test Loss: {}".format(loss_and_metrics[0]))print("Test Accuracy: {}%".format(loss_and_metrics[1]*100))predicted_classes = traffic_model.predict_classes(X_test_normalized)correct_indices = np.nonzero(predicted_classes == y_test)[0]incorrect_indices = np.nonzero(predicted_classes != y_test)[0]print("Classified correctly count: {}".format(len(correct_indices)))print("Classified incorrectly count: {}".format(len(incorrect_indices))) Test Loss: 0.22923571624080058Test Accuracy: 96.88836103380434%Classified correctly count: 12237Classified incorrectly count: 393
2.3层Con2D MaxPooling2D+1层Flatten层+2层Dense
from keras.models import Sequentialfrom keras.layers import Dense,Dropout,Flattenfrom keras.layers import Conv2D,MaxPooling2Dmodel2 = Sequential()# layers1model2.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=X_train_normalized.shape[1:], activation="relu"))model2.add(MaxPooling2D(pool_size=(2,2)))# layers2model2.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu"))model2.add(MaxPooling2D(pool_size=(2,2)))# layers3model2.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu"))model2.add(MaxPooling2D(pool_size=(2,2)))# flatternmodel2.add(Flatten())# Densemodel2.add(Dense(512,activation="relu"))# Densemodel2.add(Dense(n_classes,activation="softmax"))
# 查看模型的结构model2.summary()
_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d_3 (Conv2D) (None, 30, 30, 32) 320 _________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 15, 15, 32) 0 _________________________________________________________________conv2d_4 (Conv2D) (None, 13, 13, 64) 18496 _________________________________________________________________max_pooling2d_3 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________conv2d_5 (Conv2D) (None, 4, 4, 64) 36928 _________________________________________________________________max_pooling2d_4 (MaxPooling2 (None, 2, 2, 64) 0 _________________________________________________________________flatten_2 (Flatten) (None, 256) 0 _________________________________________________________________dense_3 (Dense) (None, 512) 131584 _________________________________________________________________dense_4 (Dense) (None, 43) 22059 =================================================================Total params: 209,387Trainable params: 209,387Non-trainable params: 0_________________________________________________________________
# 编译模型model2.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer="adam")
# 训练模型history2 = model2.fit(X_train_normalized, Y_train, batch_size=256, epochs=120, verbose=2, validation_data=(X_valid_normalized,Y_valid))
Train on 51690 samples, validate on 4410 samplesEpoch 1/120 - 2s - loss: 1.3340 - acc: 0.6319 - val_loss: 0.6667 - val_acc: 0.8041Epoch 2/120 - 2s - loss: 0.2375 - acc: 0.9308 - val_loss: 0.4388 - val_acc: 0.8762Epoch 3/120 - 2s - loss: 0.1122 - acc: 0.9669 - val_loss: 0.3823 - val_acc: 0.8964Epoch 4/120 - 2s - loss: 0.0769 - acc: 0.9775 - val_loss: 0.3509 - val_acc: 0.9036Epoch 5/120 - 2s - loss: 0.0508 - acc: 0.9857 - val_loss: 0.3434 - val_acc: 0.9088Epoch 6/120 - 2s - loss: 0.0420 - acc: 0.9874 - val_loss: 0.3413 - val_acc: 0.9204Epoch 7/120 - 2s - loss: 0.0297 - acc: 0.9912 - val_loss: 0.3266 - val_acc: 0.9243Epoch 8/120 - 2s - loss: 0.0198 - acc: 0.9943 - val_loss: 0.3150 - val_acc: 0.9256Epoch 9/120 - 2s - loss: 0.0205 - acc: 0.9940 - val_loss: 0.3463 - val_acc: 0.9200Epoch 10/120 - 2s - loss: 0.0174 - acc: 0.9947 - val_loss: 0.3045 - val_acc: 0.9236Epoch 11/120 - 2s - loss: 0.0194 - acc: 0.9943 - val_loss: 0.3561 - val_acc: 0.9184Epoch 12/120 - 2s - loss: 0.0109 - acc: 0.9968 - val_loss: 0.3475 - val_acc: 0.9259Epoch 13/120 - 2s - loss: 0.0116 - acc: 0.9964 - val_loss: 0.3646 - val_acc: 0.9270Epoch 14/120 - 2s - loss: 0.0127 - acc: 0.9958 - val_loss: 0.3486 - val_acc: 0.9295Epoch 15/120 - 2s - loss: 0.0090 - acc: 0.9975 - val_loss: 0.3234 - val_acc: 0.9297Epoch 16/120 - 2s - loss: 0.0118 - acc: 0.9962 - val_loss: 0.4056 - val_acc: 0.9236Epoch 17/120 - 2s - loss: 0.0082 - acc: 0.9976 - val_loss: 0.3282 - val_acc: 0.9345Epoch 18/120 - 2s - loss: 0.0066 - acc: 0.9982 - val_loss: 0.3327 - val_acc: 0.9381Epoch 19/120 - 2s - loss: 0.0089 - acc: 0.9971 - val_loss: 0.3708 - val_acc: 0.9338Epoch 20/120 - 2s - loss: 0.0109 - acc: 0.9967 - val_loss: 0.3011 - val_acc: 0.9397Epoch 21/120 - 2s - loss: 0.0030 - acc: 0.9993 - val_loss: 0.3431 - val_acc: 0.9406Epoch 22/120 - 2s - loss: 0.0121 - acc: 0.9965 - val_loss: 0.3113 - val_acc: 0.9413Epoch 23/120 - 2s - loss: 0.0068 - acc: 0.9981 - val_loss: 0.3195 - val_acc: 0.9431Epoch 24/120 - 2s - loss: 0.0021 - acc: 0.9995 - val_loss: 0.3079 - val_acc: 0.9447Epoch 25/120 - 2s - loss: 0.0080 - acc: 0.9973 - val_loss: 0.2953 - val_acc: 0.9408Epoch 26/120 - 2s - loss: 0.0086 - acc: 0.9971 - val_loss: 0.3595 - val_acc: 0.9315Epoch 27/120 - 2s - loss: 0.0105 - acc: 0.9967 - val_loss: 0.3286 - val_acc: 0.9342Epoch 28/120 - 2s - loss: 0.0039 - acc: 0.9990 - val_loss: 0.3357 - val_acc: 0.9363Epoch 29/120 - 2s - loss: 0.0038 - acc: 0.9992 - val_loss: 0.2930 - val_acc: 0.9440Epoch 30/120 - 2s - loss: 0.0053 - acc: 0.9985 - val_loss: 0.2465 - val_acc: 0.9537Epoch 110/120 - 2s - loss: 6.2377e-04 - acc: 1.0000 - val_loss: 0.4051 - val_acc: 0.9519Epoch 111/120 - 2s - loss: 6.2377e-04 - acc: 1.0000 - val_loss: 0.4071 - val_acc: 0.9524Epoch 112/120 - 2s - loss: 6.2377e-04 - acc: 1.0000 - val_loss: 0.4111 - val_acc: 0.9524Epoch 113/120 - 2s - loss: 6.2377e-04 - acc: 1.0000 - val_loss: 0.4106 - val_acc: 0.9524Epoch 114/120 - 2s - loss: 6.2377e-04 - acc: 1.0000 - val_loss: 0.4115 - val_acc: 0.9522Epoch 115/120 - 2s - loss: 6.2377e-04 - acc: 1.0000 - val_loss: 0.4134 - val_acc: 0.9519Epoch 116/120 - 2s - loss: 6.2377e-04 - acc: 1.0000 - val_loss: 0.4157 - val_acc: 0.9510Epoch 117/120 - 2s - loss: 6.2377e-04 - acc: 1.0000 - val_loss: 0.4181 - val_acc: 0.9515Epoch 118/120 - 2s - loss: 6.2376e-04 - acc: 1.0000 - val_loss: 0.4188 - val_acc: 0.9517Epoch 119/120 - 2s - loss: 6.2376e-04 - acc: 1.0000 - val_loss: 0.4199 - val_acc: 0.9517Epoch 120/120 - 2s - loss: 6.2376e-04 - acc: 1.0000 - val_loss: 0.4196 - val_acc: 0.9510
# 可视化指标fig = plt.figure()plt.subplot(2,1,1)plt.plot(history2.history['acc'])plt.plot(history2.history['val_acc'])plt.title('Model Accuracy')plt.ylabel('accuracy')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='lower right')plt.subplot(2,1,2)plt.plot(history2.history['loss'])plt.plot(history2.history['val_loss'])plt.title('Model Loss')plt.ylabel('loss')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='upper right')plt.tight_layout()plt.show() 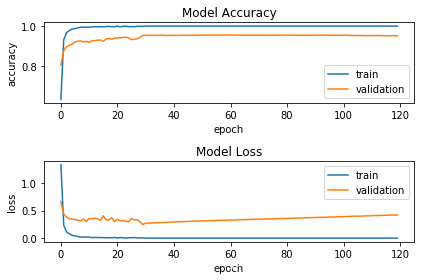
# 保存模型import osimport tensorflow.gfile as gfilesave_dir = "/content/drive/model/v2/"if gfile.Exists(save_dir): gfile.DeleteRecursively(save_dir)gfile.MakeDirs(save_dir)model_name = 'keras_traffic_2.h5'model_path = os.path.join(save_dir, model_name)model2.save(model_path)print('Saved trained model at %s ' % model_path) Saved trained model at /content/drive/model/v2/keras_traffic_2.h5
# 加载模型from keras.models import load_modeltraffic_model = load_model(model_path)
# 统计模型在测试集上的分类结果loss_and_metrics = traffic_model.evaluate(X_test_normalized, Y_test, verbose=2,batch_size=256) print("Test Loss: {}".format(loss_and_metrics[0]))print("Test Accuracy: {}%".format(loss_and_metrics[1]*100))predicted_classes = traffic_model.predict_classes(X_test_normalized)correct_indices = np.nonzero(predicted_classes == y_test)[0]incorrect_indices = np.nonzero(predicted_classes != y_test)[0]print("Classified correctly count: {}".format(len(correct_indices)))print("Classified incorrectly count: {}".format(len(incorrect_indices))) Test Loss: 0.6938359957692742Test Accuracy: 93.08788600368152%Classified correctly count: 11757Classified incorrectly count: 873
3.对上述模型进行改进 增加2层Dropout层
from keras.models import Sequentialfrom keras.layers import Dense,Dropout,Flattenfrom keras.layers import Conv2D,MaxPooling2Dmodel3 = Sequential()# layers1model3.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=X_train_normalized.shape[1:], activation="relu"))model3.add(MaxPooling2D(pool_size=(2,2)))# layers2model3.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu"))model3.add(MaxPooling2D(pool_size=(2,2)))# Dropoutmodel3.add(Dropout(0.25))# layers3model3.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu"))model3.add(MaxPooling2D(pool_size=(2,2)))# flatternmodel3.add(Flatten())# Densemodel3.add(Dense(512,activation="relu"))# Dropoutmodel3.add(Dropout(0.5))# Densemodel3.add(Dense(n_classes,activation="softmax"))
model3.summary()
_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d_6 (Conv2D) (None, 30, 30, 32) 320 _________________________________________________________________max_pooling2d_5 (MaxPooling2 (None, 15, 15, 32) 0 _________________________________________________________________conv2d_7 (Conv2D) (None, 13, 13, 64) 18496 _________________________________________________________________max_pooling2d_6 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________dropout_3 (Dropout) (None, 6, 6, 64) 0 _________________________________________________________________conv2d_8 (Conv2D) (None, 4, 4, 64) 36928 _________________________________________________________________max_pooling2d_7 (MaxPooling2 (None, 2, 2, 64) 0 _________________________________________________________________flatten_3 (Flatten) (None, 256) 0 _________________________________________________________________dense_5 (Dense) (None, 512) 131584 _________________________________________________________________dropout_4 (Dropout) (None, 512) 0 _________________________________________________________________dense_6 (Dense) (None, 43) 22059 =================================================================Total params: 209,387Trainable params: 209,387Non-trainable params: 0_________________________________________________________________
# 编译模型model3.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer="adam")
# 训练模型history3 = model3.fit(X_train_normalized, Y_train, batch_size=256, epochs=120, verbose=2, validation_data=(X_valid_normalized,Y_valid))
Train on 51690 samples, validate on 4410 samplesEpoch 1/120 - 2s - loss: 1.8536 - acc: 0.4729 - val_loss: 0.6255 - val_acc: 0.8197Epoch 2/120 - 2s - loss: 0.4513 - acc: 0.8609 - val_loss: 0.3030 - val_acc: 0.9082Epoch 3/120 - 2s - loss: 0.2391 - acc: 0.9261 - val_loss: 0.2413 - val_acc: 0.9272Epoch 4/120 - 2s - loss: 0.1676 - acc: 0.9480 - val_loss: 0.2010 - val_acc: 0.9401Epoch 5/120 - 2s - loss: 0.1248 - acc: 0.9610 - val_loss: 0.1635 - val_acc: 0.9519Epoch 6/120 - 2s - loss: 0.1006 - acc: 0.9692 - val_loss: 0.1346 - val_acc: 0.9619Epoch 7/120 - 2s - loss: 0.0848 - acc: 0.9736 - val_loss: 0.1464 - val_acc: 0.9553Epoch 8/120 - 2s - loss: 0.0731 - acc: 0.9765 - val_loss: 0.1513 - val_acc: 0.9526Epoch 9/120 - 2s - loss: 0.0664 - acc: 0.9785 - val_loss: 0.1365 - val_acc: 0.9580Epoch 10/120 - 2s - loss: 0.0590 - acc: 0.9810 - val_loss: 0.1404 - val_acc: 0.9553Epoch 11/120 - 2s - loss: 0.0493 - acc: 0.9838 - val_loss: 0.1258 - val_acc: 0.9646Epoch 12/120 - 2s - loss: 0.0446 - acc: 0.9859 - val_loss: 0.1265 - val_acc: 0.9642Epoch 13/120 - 2s - loss: 0.0389 - acc: 0.9874 - val_loss: 0.1258 - val_acc: 0.9678Epoch 14/120 - 2s - loss: 0.0385 - acc: 0.9872 - val_loss: 0.1220 - val_acc: 0.9669Epoch 15/120 - 2s - loss: 0.0348 - acc: 0.9889 - val_loss: 0.1200 - val_acc: 0.9662Epoch 16/120 - 2s - loss: 0.0354 - acc: 0.9883 - val_loss: 0.0980 - val_acc: 0.9728Epoch 17/120 - 2s - loss: 0.0316 - acc: 0.9897 - val_loss: 0.1222 - val_acc: 0.9680Epoch 18/120 - 2s - loss: 0.0280 - acc: 0.9909 - val_loss: 0.1069 - val_acc: 0.9703Epoch 19/120 - 2s - loss: 0.0285 - acc: 0.9911 - val_loss: 0.1080 - val_acc: 0.9703Epoch 20/120 - 2s - loss: 0.0240 - acc: 0.9915 - val_loss: 0.1049 - val_acc: 0.9714Epoch 21/120 - 2s - loss: 0.0248 - acc: 0.9921 - val_loss: 0.1137 - val_acc: 0.9703Epoch 22/120 - 2s - loss: 0.0248 - acc: 0.9922 - val_loss: 0.0974 - val_acc: 0.9728Epoch 23/120 - 2s - loss: 0.0213 - acc: 0.9930 - val_loss: 0.1277 - val_acc: 0.9633Epoch 24/120 - 2s - loss: 0.0232 - acc: 0.9924 - val_loss: 0.0980 - val_acc: 0.9751Epoch 25/120 - 2s - loss: 0.0208 - acc: 0.9932 - val_loss: 0.1124 - val_acc: 0.9739Epoch 26/120 - 2s - loss: 0.0183 - acc: 0.9939 - val_loss: 0.1076 - val_acc: 0.9726Epoch 27/120 - 2s - loss: 0.0205 - acc: 0.9928 - val_loss: 0.0998 - val_acc: 0.9735Epoch 28/120 - 2s - loss: 0.0167 - acc: 0.9944 - val_loss: 0.1231 - val_acc: 0.9701Epoch 29/120 - 2s - loss: 0.0188 - acc: 0.9940 - val_loss: 0.1025 - val_acc: 0.9737Epoch 30/120 - 2s - loss: 0.0164 - acc: 0.9947 - val_loss: 0.1189 - val_acc: 0.9701Epoch 110/120 - 2s - loss: 0.0069 - acc: 0.9980 - val_loss: 0.0982 - val_acc: 0.9805Epoch 111/120 - 2s - loss: 0.0086 - acc: 0.9976 - val_loss: 0.0940 - val_acc: 0.9816Epoch 112/120 - 2s - loss: 0.0057 - acc: 0.9982 - val_loss: 0.0958 - val_acc: 0.9807Epoch 113/120 - 2s - loss: 0.0066 - acc: 0.9981 - val_loss: 0.1343 - val_acc: 0.9780Epoch 114/120 - 2s - loss: 0.0059 - acc: 0.9982 - val_loss: 0.1218 - val_acc: 0.9796Epoch 115/120 - 2s - loss: 0.0074 - acc: 0.9979 - val_loss: 0.1266 - val_acc: 0.9771Epoch 116/120 - 2s - loss: 0.0063 - acc: 0.9981 - val_loss: 0.1001 - val_acc: 0.9819Epoch 117/120 - 2s - loss: 0.0063 - acc: 0.9980 - val_loss: 0.0945 - val_acc: 0.9819Epoch 118/120 - 2s - loss: 0.0082 - acc: 0.9976 - val_loss: 0.1334 - val_acc: 0.9751Epoch 119/120 - 2s - loss: 0.0073 - acc: 0.9976 - val_loss: 0.1341 - val_acc: 0.9735Epoch 120/120 - 2s - loss: 0.0072 - acc: 0.9977 - val_loss: 0.1004 - val_acc: 0.9794
# 可视化指标fig = plt.figure()plt.subplot(2,1,1)plt.plot(history3.history['acc'])plt.plot(history3.history['val_acc'])plt.title('Model Accuracy')plt.ylabel('accuracy')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='lower right')plt.subplot(2,1,2)plt.plot(history3.history['loss'])plt.plot(history3.history['val_loss'])plt.title('Model Loss')plt.ylabel('loss')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='upper right')plt.tight_layout()plt.show() 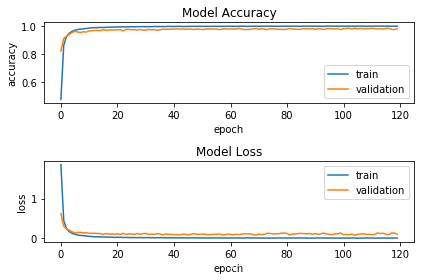
# 保存模型import osimport tensorflow.gfile as gfilesave_dir = "/content/drive/model/v3/"if gfile.Exists(save_dir): gfile.DeleteRecursively(save_dir)gfile.MakeDirs(save_dir)model_name = 'keras_traffic_3.h5'model_path = os.path.join(save_dir, model_name)model3.save(model_path)print('Saved trained model at %s ' % model_path) Saved trained model at /content/drive/model/v3/keras_traffic_3.h5
# 加载模型from keras.models import load_modeltraffic_model = load_model(model_path)
# 统计模型在测试集上的分类结果loss_and_metrics = traffic_model.evaluate(X_test_normalized, Y_test, verbose=2,batch_size=256) print("Test Loss: {}".format(loss_and_metrics[0]))print("Test Accuracy: {}%".format(loss_and_metrics[1]*100))predicted_classes = traffic_model.predict_classes(X_test_normalized)correct_indices = np.nonzero(predicted_classes == y_test)[0]incorrect_indices = np.nonzero(predicted_classes != y_test)[0]print("Classified correctly count: {}".format(len(correct_indices)))print("Classified incorrectly count: {}".format(len(incorrect_indices))) Test Loss: 0.2989197100426409Test Accuracy: 95.88281867056732%Classified correctly count: 12110Classified incorrectly count: 520
4.2层卷积池化层+1层展开层+3层全连接层
from keras.models import Sequentialfrom keras.layers import Dense,Dropout,Flattenfrom keras.layers import Conv2D,MaxPooling2Dmodel4 = Sequential()# layers1model4.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=X_train_normalized.shape[1:], activation="relu"))model4.add(MaxPooling2D(pool_size=(2,2)))# layers2model4.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu"))model4.add(MaxPooling2D(pool_size=(2,2)))# flatternmodel4.add(Flatten())# Densemodel4.add(Dense(512,activation="relu"))# Densemodel4.add(Dense(100,activation="relu"))# Densemodel4.add(Dense(n_classes,activation="softmax"))
# 查看模型的结构model4.summary()
_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d_9 (Conv2D) (None, 30, 30, 32) 320 _________________________________________________________________max_pooling2d_8 (MaxPooling2 (None, 15, 15, 32) 0 _________________________________________________________________conv2d_10 (Conv2D) (None, 13, 13, 64) 18496 _________________________________________________________________max_pooling2d_9 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________flatten_4 (Flatten) (None, 2304) 0 _________________________________________________________________dense_7 (Dense) (None, 512) 1180160 _________________________________________________________________dense_8 (Dense) (None, 100) 51300 _________________________________________________________________dense_9 (Dense) (None, 43) 4343 =================================================================Total params: 1,254,619Trainable params: 1,254,619Non-trainable params: 0_________________________________________________________________
# 编译模型model4.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer="adam")
# 训练模型history4 = model4.fit(X_train_normalized, Y_train, batch_size=256, epochs=120, verbose=2, validation_data=(X_valid_normalized,Y_valid))
Train on 51690 samples, validate on 4410 samplesEpoch 1/120 - 3s - loss: 0.9466 - acc: 0.7433 - val_loss: 0.4214 - val_acc: 0.8746Epoch 2/120 - 2s - loss: 0.1339 - acc: 0.9632 - val_loss: 0.3042 - val_acc: 0.9152Epoch 3/120 - 2s - loss: 0.0681 - acc: 0.9809 - val_loss: 0.2988 - val_acc: 0.9170Epoch 4/120 - 2s - loss: 0.0414 - acc: 0.9885 - val_loss: 0.3027 - val_acc: 0.9125Epoch 5/120 - 2s - loss: 0.0244 - acc: 0.9934 - val_loss: 0.2754 - val_acc: 0.9308Epoch 6/120 - 2s - loss: 0.0198 - acc: 0.9944 - val_loss: 0.2664 - val_acc: 0.9299Epoch 7/120 - 2s - loss: 0.0139 - acc: 0.9963 - val_loss: 0.3340 - val_acc: 0.9197Epoch 8/120 - 2s - loss: 0.0150 - acc: 0.9958 - val_loss: 0.2918 - val_acc: 0.9336Epoch 9/120 - 2s - loss: 0.0166 - acc: 0.9948 - val_loss: 0.2496 - val_acc: 0.9399Epoch 10/120 - 2s - loss: 0.0070 - acc: 0.9979 - val_loss: 0.2661 - val_acc: 0.9365Epoch 11/120 - 2s - loss: 0.0060 - acc: 0.9984 - val_loss: 0.3019 - val_acc: 0.9290Epoch 12/120 - 2s - loss: 0.0063 - acc: 0.9984 - val_loss: 0.2890 - val_acc: 0.9347Epoch 13/120 - 2s - loss: 0.0076 - acc: 0.9979 - val_loss: 0.2583 - val_acc: 0.9363Epoch 14/120 - 2s - loss: 0.0124 - acc: 0.9962 - val_loss: 0.3169 - val_acc: 0.9240Epoch 15/120 - 2s - loss: 0.0097 - acc: 0.9970 - val_loss: 0.2796 - val_acc: 0.9429Epoch 16/120 - 2s - loss: 0.0088 - acc: 0.9975 - val_loss: 0.3084 - val_acc: 0.9320Epoch 17/120 - 2s - loss: 0.0093 - acc: 0.9972 - val_loss: 0.3469 - val_acc: 0.9281Epoch 18/120 - 2s - loss: 0.0029 - acc: 0.9991 - val_loss: 0.2834 - val_acc: 0.9388Epoch 19/120 - 2s - loss: 9.1336e-04 - acc: 0.9998 - val_loss: 0.2210 - val_acc: 0.9535Epoch 20/120 - 2s - loss: 3.3410e-04 - acc: 0.9999 - val_loss: 0.2416 - val_acc: 0.9546Epoch 21/120 - 2s - loss: 4.8947e-05 - acc: 1.0000 - val_loss: 0.2395 - val_acc: 0.9556Epoch 22/120 - 2s - loss: 2.7690e-05 - acc: 1.0000 - val_loss: 0.2449 - val_acc: 0.9556Epoch 23/120 - 2s - loss: 2.0403e-05 - acc: 1.0000 - val_loss: 0.2481 - val_acc: 0.9556Epoch 24/120 - 2s - loss: 1.6893e-05 - acc: 1.0000 - val_loss: 0.2507 - val_acc: 0.9553Epoch 25/120 - 2s - loss: 1.4042e-05 - acc: 1.0000 - val_loss: 0.2534 - val_acc: 0.9553Epoch 26/120 - 2s - loss: 1.2080e-05 - acc: 1.0000 - val_loss: 0.2556 - val_acc: 0.9556Epoch 27/120 - 2s - loss: 1.0456e-05 - acc: 1.0000 - val_loss: 0.2577 - val_acc: 0.9551Epoch 28/120 - 2s - loss: 9.1271e-06 - acc: 1.0000 - val_loss: 0.2589 - val_acc: 0.9560Epoch 29/120 - 2s - loss: 8.0037e-06 - acc: 1.0000 - val_loss: 0.2610 - val_acc: 0.9549Epoch 30/120 - 2s - loss: 7.1773e-06 - acc: 1.0000 - val_loss: 0.2630 - val_acc: 0.9560Epoch 110/120 - 2s - loss: 1.2023e-07 - acc: 1.0000 - val_loss: 0.3727 - val_acc: 0.9533Epoch 111/120 - 2s - loss: 1.2010e-07 - acc: 1.0000 - val_loss: 0.3727 - val_acc: 0.9537Epoch 112/120 - 2s - loss: 1.1994e-07 - acc: 1.0000 - val_loss: 0.3716 - val_acc: 0.9535Epoch 113/120 - 2s - loss: 1.1984e-07 - acc: 1.0000 - val_loss: 0.3747 - val_acc: 0.9535Epoch 114/120 - 2s - loss: 1.1972e-07 - acc: 1.0000 - val_loss: 0.3758 - val_acc: 0.9535Epoch 115/120 - 2s - loss: 1.1968e-07 - acc: 1.0000 - val_loss: 0.3763 - val_acc: 0.9533Epoch 116/120 - 2s - loss: 1.1957e-07 - acc: 1.0000 - val_loss: 0.3789 - val_acc: 0.9528Epoch 117/120 - 2s - loss: 1.1953e-07 - acc: 1.0000 - val_loss: 0.3783 - val_acc: 0.9531Epoch 118/120 - 2s - loss: 1.1947e-07 - acc: 1.0000 - val_loss: 0.3796 - val_acc: 0.9528Epoch 119/120 - 2s - loss: 1.1943e-07 - acc: 1.0000 - val_loss: 0.3805 - val_acc: 0.9535Epoch 120/120 - 2s - loss: 1.1942e-07 - acc: 1.0000 - val_loss: 0.3811 - val_acc: 0.9533
# 可视化指标fig = plt.figure()plt.subplot(2,1,1)plt.plot(history4.history['acc'])plt.plot(history4.history['val_acc'])plt.title('Model Accuracy')plt.ylabel('accuracy')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='lower right')plt.subplot(2,1,2)plt.plot(history4.history['loss'])plt.plot(history4.history['val_loss'])plt.title('Model Loss')plt.ylabel('loss')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='upper right')plt.tight_layout()plt.show() 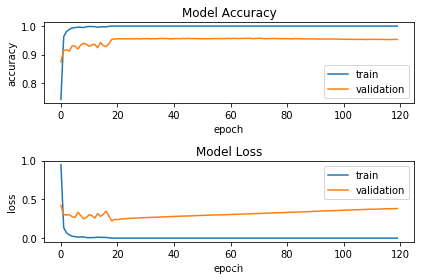
# 保存模型import osimport tensorflow.gfile as gfilesave_dir = "/content/drive/model/v4/"if gfile.Exists(save_dir): gfile.DeleteRecursively(save_dir)gfile.MakeDirs(save_dir)model_name = 'keras_traffic_4.h5'model_path = os.path.join(save_dir, model_name)model4.save(model_path)print('Saved trained model at %s ' % model_path) Saved trained model at /content/drive/model/v4/keras_traffic_4.h5
# 加载模型from keras.models import load_modeltraffic_model = load_model(model_path)
# 统计模型在测试集上的分类结果loss_and_metrics = traffic_model.evaluate(X_test_normalized, Y_test, verbose=2,batch_size=256) print("Test Loss: {}".format(loss_and_metrics[0]))print("Test Accuracy: {}%".format(loss_and_metrics[1]*100))predicted_classes = traffic_model.predict_classes(X_test_normalized)correct_indices = np.nonzero(predicted_classes == y_test)[0]incorrect_indices = np.nonzero(predicted_classes != y_test)[0]print("Classified correctly count: {}".format(len(correct_indices)))print("Classified incorrectly count: {}".format(len(incorrect_indices))) Test Loss: 0.61759698928016Test Accuracy: 93.18289788016608%Classified correctly count: 11769Classified incorrectly count: 861
5.对上述模型进行改进增加3层Dropout层
# 改进模型from keras.models import Sequentialfrom keras.layers import Dense,Dropout,Flattenfrom keras.layers import Conv2D,MaxPooling2Dmodel5 = Sequential()# layers1model5.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=X_train_normalized.shape[1:], activation="relu"))model5.add(MaxPooling2D(pool_size=(2,2)))# layers2model5.add(Conv2D(filters=64, kernel_size=(3,3), activation="relu"))model5.add(MaxPooling2D(pool_size=(2,2)))# Dropoutmodel5.add(Dropout(0.5))# flatternmodel5.add(Flatten())# Densemodel5.add(Dense(512,activation="relu"))# Dropoutmodel5.add(Dropout(0.5))# Densemodel5.add(Dense(100,activation="relu"))# Dropoutmodel5.add(Dropout(0.5))# Densemodel5.add(Dense(n_classes,activation="softmax"))
model5.summary()
_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d_11 (Conv2D) (None, 30, 30, 32) 320 _________________________________________________________________max_pooling2d_10 (MaxPooling (None, 15, 15, 32) 0 _________________________________________________________________conv2d_12 (Conv2D) (None, 13, 13, 64) 18496 _________________________________________________________________max_pooling2d_11 (MaxPooling (None, 6, 6, 64) 0 _________________________________________________________________dropout_5 (Dropout) (None, 6, 6, 64) 0 _________________________________________________________________flatten_5 (Flatten) (None, 2304) 0 _________________________________________________________________dense_10 (Dense) (None, 512) 1180160 _________________________________________________________________dropout_6 (Dropout) (None, 512) 0 _________________________________________________________________dense_11 (Dense) (None, 100) 51300 _________________________________________________________________dropout_7 (Dropout) (None, 100) 0 _________________________________________________________________dense_12 (Dense) (None, 43) 4343 =================================================================Total params: 1,254,619Trainable params: 1,254,619Non-trainable params: 0_________________________________________________________________
# 编译模型model5.compile(loss="categorical_crossentropy", metrics=["accuracy"], optimizer="adam")
# 训练模型history5 = model5.fit(X_train_normalized, Y_train, batch_size=256, epochs=120, verbose=2, validation_data=(X_valid_normalized,Y_valid))
Train on 51690 samples, validate on 4410 samplesEpoch 1/120 - 3s - loss: 2.0740 - acc: 0.4183 - val_loss: 0.5267 - val_acc: 0.8590Epoch 2/120 - 2s - loss: 0.5917 - acc: 0.8149 - val_loss: 0.2372 - val_acc: 0.9395Epoch 3/120 - 2s - loss: 0.3512 - acc: 0.8919 - val_loss: 0.1723 - val_acc: 0.9508Epoch 4/120 - 2s - loss: 0.2560 - acc: 0.9214 - val_loss: 0.1449 - val_acc: 0.9583Epoch 5/120 - 2s - loss: 0.2048 - acc: 0.9382 - val_loss: 0.1341 - val_acc: 0.9590Epoch 6/120 - 2s - loss: 0.1682 - acc: 0.9497 - val_loss: 0.1183 - val_acc: 0.9655Epoch 7/120 - 2s - loss: 0.1406 - acc: 0.9573 - val_loss: 0.1070 - val_acc: 0.9698Epoch 8/120 - 2s - loss: 0.1288 - acc: 0.9604 - val_loss: 0.1037 - val_acc: 0.9667Epoch 9/120 - 2s - loss: 0.1175 - acc: 0.9641 - val_loss: 0.1056 - val_acc: 0.9685Epoch 10/120 - 2s - loss: 0.1016 - acc: 0.9690 - val_loss: 0.0935 - val_acc: 0.9696Epoch 11/120 - 2s - loss: 0.0940 - acc: 0.9709 - val_loss: 0.0856 - val_acc: 0.9741Epoch 12/120 - 2s - loss: 0.0896 - acc: 0.9729 - val_loss: 0.0901 - val_acc: 0.9741Epoch 13/120 - 2s - loss: 0.0857 - acc: 0.9744 - val_loss: 0.0879 - val_acc: 0.9719Epoch 14/120 - 2s - loss: 0.0803 - acc: 0.9757 - val_loss: 0.0894 - val_acc: 0.9723Epoch 15/120 - 2s - loss: 0.0740 - acc: 0.9782 - val_loss: 0.1040 - val_acc: 0.9705Epoch 16/120 - 2s - loss: 0.0708 - acc: 0.9796 - val_loss: 0.1073 - val_acc: 0.9683Epoch 17/120 - 2s - loss: 0.0652 - acc: 0.9800 - val_loss: 0.0791 - val_acc: 0.9753Epoch 18/120 - 2s - loss: 0.0660 - acc: 0.9801 - val_loss: 0.0794 - val_acc: 0.9751Epoch 19/120 - 2s - loss: 0.0571 - acc: 0.9828 - val_loss: 0.0925 - val_acc: 0.9705Epoch 20/120 - 2s - loss: 0.0573 - acc: 0.9828 - val_loss: 0.0692 - val_acc: 0.9791Epoch 21/120 - 2s - loss: 0.0532 - acc: 0.9834 - val_loss: 0.0726 - val_acc: 0.9785Epoch 22/120 - 2s - loss: 0.0548 - acc: 0.9837 - val_loss: 0.0824 - val_acc: 0.9741Epoch 23/120 - 2s - loss: 0.0529 - acc: 0.9841 - val_loss: 0.0747 - val_acc: 0.9789Epoch 24/120 - 2s - loss: 0.0544 - acc: 0.9839 - val_loss: 0.0710 - val_acc: 0.9776Epoch 25/120 - 2s - loss: 0.0470 - acc: 0.9859 - val_loss: 0.0687 - val_acc: 0.9789Epoch 26/120 - 2s - loss: 0.0459 - acc: 0.9860 - val_loss: 0.0710 - val_acc: 0.9769Epoch 27/120 - 2s - loss: 0.0482 - acc: 0.9859 - val_loss: 0.0718 - val_acc: 0.9764Epoch 28/120 - 2s - loss: 0.0456 - acc: 0.9862 - val_loss: 0.0744 - val_acc: 0.9812Epoch 29/120 - 2s - loss: 0.0469 - acc: 0.9861 - val_loss: 0.0883 - val_acc: 0.9762Epoch 30/120 - 2s - loss: 0.0445 - acc: 0.9863 - val_loss: 0.0757 - val_acc: 0.9757Epoch 110/120 - 2s - loss: 0.0217 - acc: 0.9941 - val_loss: 0.0600 - val_acc: 0.9832Epoch 111/120 - 2s - loss: 0.0243 - acc: 0.9936 - val_loss: 0.0716 - val_acc: 0.9800Epoch 112/120 - 2s - loss: 0.0204 - acc: 0.9941 - val_loss: 0.0740 - val_acc: 0.9794Epoch 113/120 - 2s - loss: 0.0178 - acc: 0.9948 - val_loss: 0.0669 - val_acc: 0.9828Epoch 114/120 - 2s - loss: 0.0184 - acc: 0.9949 - val_loss: 0.0569 - val_acc: 0.9850Epoch 115/120 - 2s - loss: 0.0224 - acc: 0.9943 - val_loss: 0.0703 - val_acc: 0.9791Epoch 116/120 - 2s - loss: 0.0203 - acc: 0.9944 - val_loss: 0.0762 - val_acc: 0.9789Epoch 117/120 - 2s - loss: 0.0182 - acc: 0.9945 - val_loss: 0.0705 - val_acc: 0.9798Epoch 118/120 - 2s - loss: 0.0204 - acc: 0.9944 - val_loss: 0.0603 - val_acc: 0.9819Epoch 119/120 - 2s - loss: 0.0188 - acc: 0.9950 - val_loss: 0.0544 - val_acc: 0.9848Epoch 120/120 - 2s - loss: 0.0198 - acc: 0.9947 - val_loss: 0.0593 - val_acc: 0.9857
# 可视化指标fig = plt.figure()plt.subplot(2,1,1)plt.plot(history5.history['acc'])plt.plot(history5.history['val_acc'])plt.title('Model Accuracy')plt.ylabel('accuracy')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='lower right')plt.subplot(2,1,2)plt.plot(history5.history['loss'])plt.plot(history5.history['val_loss'])plt.title('Model Loss')plt.ylabel('loss')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='upper right')plt.tight_layout()plt.show() 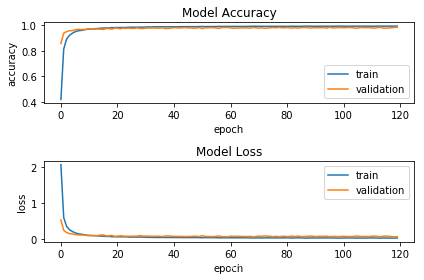
# 保存模型import osimport tensorflow.gfile as gfilesave_dir = "/content/drive/model/v5/"if gfile.Exists(save_dir): gfile.DeleteRecursively(save_dir)gfile.MakeDirs(save_dir)model_name = 'keras_traffic_5.h5'model_path = os.path.join(save_dir, model_name)model5.save(model_path)print('Saved trained model at %s ' % model_path) Saved trained model at /content/drive/model/v5/keras_traffic_5.h5
# 加载模型from keras.models import load_modeltraffic_model = load_model(model_path)
# 统计模型在测试集上的分类结果loss_and_metrics = traffic_model.evaluate(X_test_normalized, Y_test, verbose=2,batch_size=256) print("Test Loss: {}".format(loss_and_metrics[0]))print("Test Accuracy: {}%".format(loss_and_metrics[1]*100))predicted_classes = traffic_model.predict_classes(X_test_normalized)correct_indices = np.nonzero(predicted_classes == y_test)[0]incorrect_indices = np.nonzero(predicted_classes != y_test)[0]print("Classified correctly count: {}".format(len(correct_indices)))print("Classified incorrectly count: {}".format(len(incorrect_indices))) Test Loss: 0.15594110083032578Test Accuracy: 96.76167853182493%Classified correctly count: 12221Classified incorrectly count: 409
补充单张图片预测
# 加载模型from keras.models import load_modeltraffic_model = load_model(model_path)
# 加载预测图片import osimport cv2import matplotlib.image as mpimgimport matplotlib.pyplot as pltimport numpy as npimage_path = "/content/drive/image/"filenames = os.listdir(image_path)X_predict = []for filename in filenames: if filename.endswith(".jpg"): img = cv2.imread(image_path+filename) img = cv2.resize(img,(32,32),cv2.INTER_LINEAR) X_predict.append(img) plt.imshow(img) # 封装数据预处理的方法import cv2def preprocess_features(X, equalize_hist=True): normalized_X = [] for i in range(len(X)): # Convert from RGB to YUV yuv_img = cv2.cvtColor(X[i], cv2.COLOR_RGB2YUV) yuv_img_v = X[i][:, :, 0] # equalizeHist yuv_img_v = cv2.equalizeHist(yuv_img_v) # expand_dis yuv_img_v = np.expand_dims(yuv_img_v, 2) normalized_X.append(yuv_img_v) # normalize normalized_X = np.array(normalized_X, dtype=np.float32) normalized_X = (normalized_X-128)/128 # normalized_X /= (np.std(normalized_X, axis=0) + np.finfo('float32').eps) return normalized_X # 对数据进行处理X_predict_normalized = preprocess_features(X_predict)
# 数据维度及数据类型print(X_predict_normalized.shape,type(X_predict_normalized))
# 模型预测y_predict = traffic_model.predict_classes(X_predict_normalized)print(id_to_name(y_predict[0]))
转载地址:https://codingchaozhang.blog.csdn.net/article/details/93194997 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月21日 09时45分35秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
未来战争:装载AI的美国空军侦察机已经试飞……
2019-04-29
屡战屡败:为什么你会觉得学习编程很难?
2019-04-29
“狙击”特斯拉:电动汽车后起之秀的最后一战
2019-04-29
软件测试的未来:2021年需要关注的15大软件测试趋势
2019-04-29
六大基本AI术语:如何做好人工智能咨询服务?
2019-04-29
讲真,如果手机有灵魂,那就是“备忘录”
2019-04-29
端到端加密:WhatsApp不会去读取你的信息,它不需要……
2019-04-29
国会大厦骚乱,与一家极不可靠的面部识别公司……
2019-04-29
解锁宇宙密码:为什么是3、6、9?
2019-04-29
数据可视化中的格式塔心理学
2019-04-29
电动汽车的“专属危险”:网络威胁问题不容小觑
2019-04-29
短暂的告别,马上再回来
2019-04-29
统治50年:为什么SQL在如今仍然很重要?
2019-04-29
测试是一场竞争,而数据每次都会获得胜利
2019-04-29
读心的测谎系统:究竟是骗子还是个天才?
2019-04-29
最大规模技术重建:数据库连接从15000个到100个以下
2019-04-29
复工之后:员工如何改善网络安全?
2019-04-29
70%求职者因此被拒,你还不避开这些“雷区”?!
2019-04-29
办法不在多,有用就行!用Dropout解决过度拟合问题
2019-04-29
色情演员识别?绝对是人脸识别最糟糕的应用……
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310036560 位访客
访问时间: 2024-05-02 14:19:11
访问IP: 3.144.187.103
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版