本文共 12021 字,大约阅读时间需要 40 分钟。
从朴素贝叶斯到N-gram语言模型
文章介绍
在本文中你将会学到朴素贝叶斯是什么、朴素贝叶斯有什么应用、实际工程上的小技巧等
N-grame是什么、它比朴素贝叶斯好在哪里等目录
- 朴素贝叶斯
- N-gram语言模型
- 两个实例代码
朴素贝叶斯

引言
贝叶斯公式 + 条件独立假设 = 朴素贝叶斯
贝叶斯方法是一个历史悠久,有着坚实的理论基础的方法,同时处理很多问题时直接而又高效,很多高级自然语言处理模型也可以从它演化而来。因此,学习贝叶斯方法,是研究自然语言处理问题的一个非常好的切入口。联合概率公式
由 联合概率公式 可推导出 贝叶斯公式
贝叶斯公式
其中 P(Y)叫做先验概率, P(Y|X) 叫做后验概率, P(Y,X)叫做联合概率。
在机器学习的视角下,我们把 X 理解成“具有某特征”
把 Y理解成“类别标签”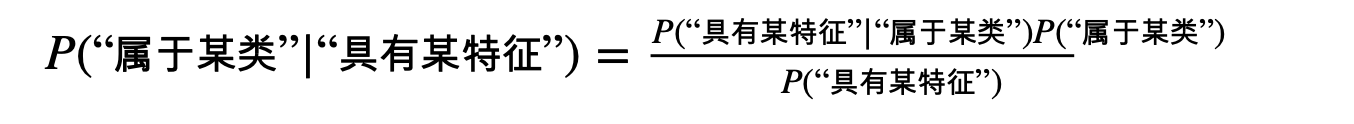 解释上述公式: P(“属于某类”|“具有某特征”)=在已知某样本“具有某特征”的条件下,该样本“属于某类”的概率。所以叫做后验概率。 P(“具有某特征”|“属于某类”)=在已知某样本“属于某类”的条件下,该样本“具有某特征”的概率(可求)。 P(“属于某类”)=(在未知某样本具有该“具有某特征”的条件下,)该样本“属于某类”的概率。所以叫做先验概率(可求)。 P(“具有某特征”)=(在未知某样本“属于某类”的条件下,)该样本“具有某特征”的概率(可求)。
解释上述公式: P(“属于某类”|“具有某特征”)=在已知某样本“具有某特征”的条件下,该样本“属于某类”的概率。所以叫做后验概率。 P(“具有某特征”|“属于某类”)=在已知某样本“属于某类”的条件下,该样本“具有某特征”的概率(可求)。 P(“属于某类”)=(在未知某样本具有该“具有某特征”的条件下,)该样本“属于某类”的概率。所以叫做先验概率(可求)。 P(“具有某特征”)=(在未知某样本“属于某类”的条件下,)该样本“具有某特征”的概率(可求)。 而我们二分类问题的最终目的就是要判断 P(“属于某类”|“具有某特征”)是否大于1/2就够了。贝叶斯方法把计算“具有某特征的条件下属于某类”的概率转换成需要计算“属于某类的条件下具有某特征”的概率,而后者获取方法就简单多了,我们只需要找到一些包含已知特征标签的样本,即可进行训练。而样本的类别标签都是明确的,所以贝叶斯方法在机器学习里属于有监督学习方法。
分词
一个很悲哀但是很现实的结论:训练集是有限的,而句子的可能性则是无限的。所以覆盖所有句子可能性的训练集是不存在的。
解决方法:句子的可能性无限,但是词语就那么些!分词也就是把一整句话拆分成更细粒度的词语来进行表示 因此贝叶斯公式就变成了:
因此贝叶斯公式就变成了: 但是我们可以从公式中发现,这也没法进行计算呀?
但是我们可以从公式中发现,这也没法进行计算呀? 条件独立假设
上面等式👉右边,概率 P((“我”,“司”,“可”,“办理”,“正规发票”,“保真”,“增值税”,“发票”,“点数”,“优惠”)|“垃圾邮件”)依旧不够好求,我们引进一个很朴素的近似。为了让公式显得更加紧凑,我们令字母S表示“垃圾邮件”,令字母H表示“正常邮件”。近似公式如下:
 这就是条件独立假设!因为条件独立所以可以各个概率相乘 又因为等式👉右边 分母相同,于是我们就只需要比较以下两个式子的大小:
这就是条件独立假设!因为条件独立所以可以各个概率相乘 又因为等式👉右边 分母相同,于是我们就只需要比较以下两个式子的大小:  等式👉右边式子中的每一项都特别好求!只需要分别统计各类邮件中该关键词出现的概率就可以了!比如:
等式👉右边式子中的每一项都特别好求!只需要分别统计各类邮件中该关键词出现的概率就可以了!比如:
朴素贝叶斯(Naive Bayes),“Naive”在何处?
答:朴素贝叶斯失去了词语之间的顺序信息因此这种情况也称作词袋子模型(bag of words)
 词袋子模型与人们的日常经验完全不同。比如,在条件独立假设的情况下 武松打死了老虎 与 老虎打死了武松被它认作一个意思了。恩,朴素贝叶斯就是这么单纯和直接,对比于其他分类器,好像是显得有那么点萌蠢。
词袋子模型与人们的日常经验完全不同。比如,在条件独立假设的情况下 武松打死了老虎 与 老虎打死了武松被它认作一个意思了。恩,朴素贝叶斯就是这么单纯和直接,对比于其他分类器,好像是显得有那么点萌蠢。 处理重复词语的三种方式
我们之前的垃圾邮件向量(“我”,“司”,“可”,“办理”,“正规发票”,“保真”,“增值税”,“发票”,“点数”,“优惠”),其中每个词都不重复。而这在现实中其实很少见。因为如果文本长度增加,或者分词方法改变,必然会有许多词重复出现,因此需要对这种情况进行进一步探讨。比如以下这段邮件:
“代开发票。增值税发票,正规发票。” 分词后为向量: (“代开”,“发票”,“增值税”,“发票”,“正规”,“发票”) 其中“发票”重复了三次。多项式模型:

重复词汇-统计多次
如果我们考虑重复词语的情况,也就是说,重复的词语我们视为其出现多次,直接按条件独立假设的方式推导,则有 P((“代开”,“发票”,“增值税”,“发票”,“正规”,“发票”)|S) =P(“代开””|S)P(“发票”|S)P(“增值税”|S)P(“发票”|S)P(“正规”|S)P(“发票”|S) =P(“代开””|S)P3(“发票”|S)P(“增值税”|S)P(“正规”|S) 注意这一项: P3(“发票”|S) 在统计计算P(“发票”|S)时,每个被统计的垃圾邮件样本中重复的词语也 统计多次。
你看这个多次出现的结果,出现在概率的指数/次方上,因此这样的模型叫作多项式模型。
伯努利模型:
重复词汇-统计一次
另一种更加简化的方法是将重复的词语都视为其只出现1次, P((“代开”,“发票”,“增值税”,“发票”,“正规”,“发票”)|S) =P(“发票”|S)P(“代开””|S)P(“增值税”|S)P(“正规”|S)统计计算 P(“词语”|S)
时也是如此。
这样的模型叫作伯努利模型(又称为二项独立模型)。这种方式更加简化与方便。当然它丢失了词频的信息,因此效果可能会差一些。
混合模型:
第三种方式是在计算句子概率时,不考虑重复词语出现的次数,但是在统计计算词语的概率P(“词语”|S)时,却考虑重复词语的出现次数,这样的模型可以叫作混合模型。
去除停用词与选择关键词
“停用词”和“关键词”一般都可以提前靠人工经验指定。不同的“停用词”和“关键词”训练出来的分类器的效果也会有些差异。
平滑技术
例如:P(“正规发票”|S)=0…问题严重了,整个概率都变成0了!
 平滑技术是因为数据集太小而产生的现实需求。如果数据集足够大,平滑技术对结果的影响将会变小。
平滑技术是因为数据集太小而产生的现实需求。如果数据集足够大,平滑技术对结果的影响将会变小。 朴素贝叶斯的局限性
我们知道朴素贝叶斯的局限性来源于其条件独立假设,它将文本看成是词袋子模型,不考虑词语之间的顺序信息,就会把“武松打死了老虎”与“老虎打死了武松”认作是一个意思。那么有没有一种方法提高其对词语顺序的识别能力呢?有,就是这里要提到的N-gram语言模型。
N-gram语言模型
从假设性独立到联合概率链规则
照抄我们垃圾邮件识别中的条件独立假设,长这个样子: 为了简化起见,我们以字母 xi表示每一个词语,并且先不考虑条件“S”。于是上式就变成了下面的独立性公式。
为了简化起见,我们以字母 xi表示每一个词语,并且先不考虑条件“S”。于是上式就变成了下面的独立性公式。 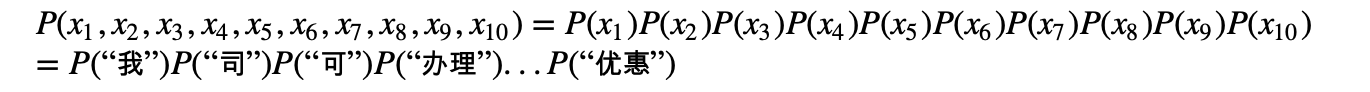 上面的公式要求满足独立性假设,如果去掉独立性假设,我们应该有下面这个恒等式,即联合概率链规则(chain rule) :
上面的公式要求满足独立性假设,如果去掉独立性假设,我们应该有下面这个恒等式,即联合概率链规则(chain rule) : 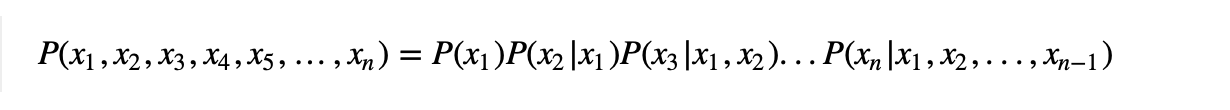 从联合概率链规则到n-gram语言模型
从联合概率链规则到n-gram语言模型 上面的联合概率链规则公式考虑到词和词之间的依赖关系,但是比较复杂,在实际生活中几乎没办法使用,于是我们就想了很多办法去近似这个公式,比如我们要讲到的语言模型n-gram就是它的一个简化。

两个实例代码
一个手动实现 bayes_NewsClassification新闻分类的例子 (python3.7)
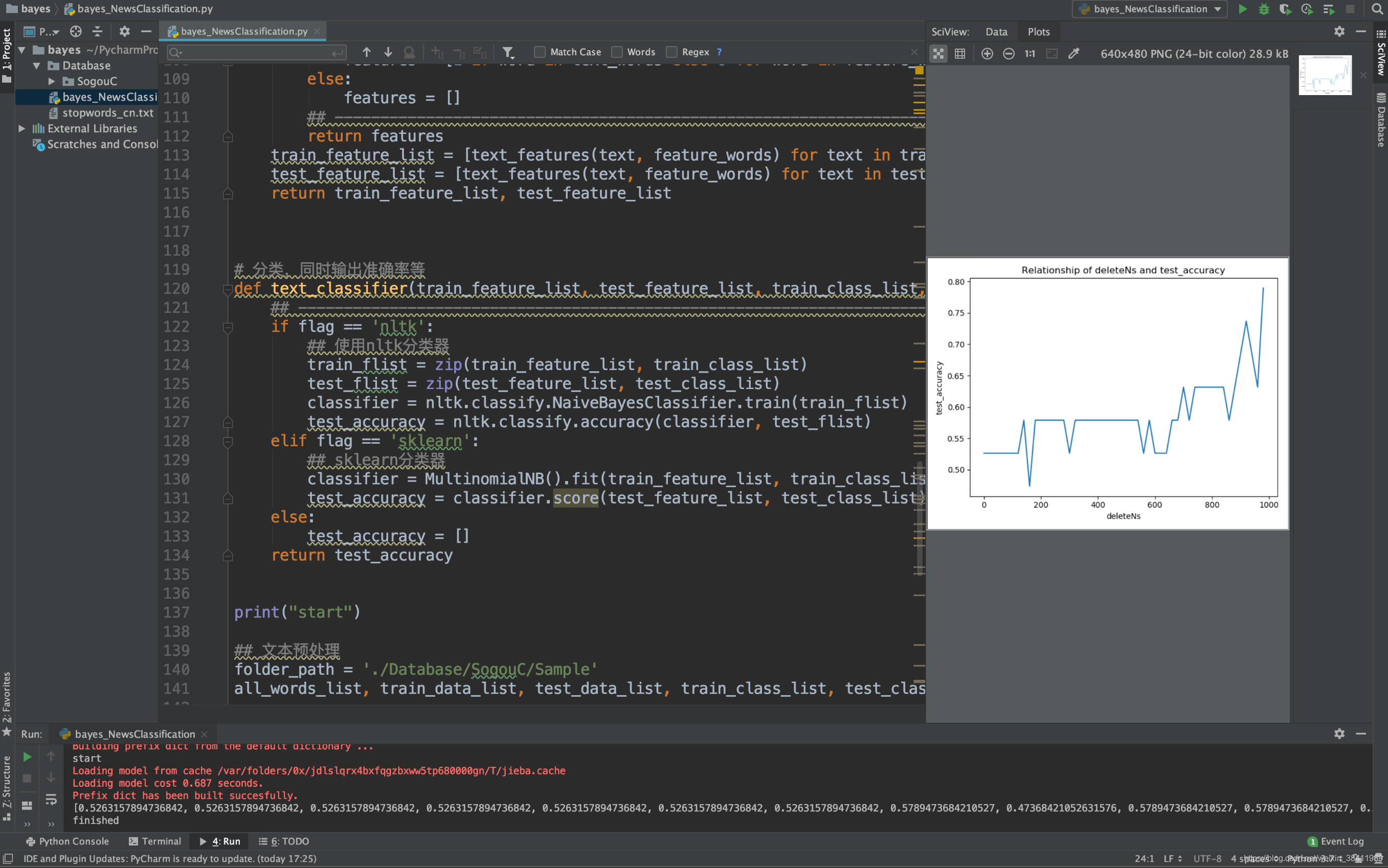
#coding: utf-8import osimport timeimport randomimport jieba #处理中文#import nltk #处理英文import nltkimport sklearnfrom sklearn.naive_bayes import MultinomialNBimport numpy as npimport pylab as plimport matplotlib.pyplot as plt'''预处理'''# stopword词统计def make_word_set(words_file): words_set = set() with open(words_file, 'r') as fp: for line in fp.readlines(): word = line.strip().encode("utf-8").decode("utf-8") if len(word)>0 and word not in words_set: # stoplist words_set.add(word) return words_set# 文本处理,也就是样本生成过程def text_processing(folder_path, test_size=0.2): folder_list = os.listdir(folder_path) data_list = [] class_list = [] # 遍历文件夹 for folder in folder_list: new_folder_path = os.path.join(folder_path, folder) files = os.listdir(new_folder_path) # 读取文件 j = 1 for file in files: if j > 100: # 怕内存爆掉,只取100个样本文件,你可以注释掉取完 break with open(os.path.join(new_folder_path, file), 'r') as fp: raw = fp.read() ## 是的,随处可见的jieba中文分词 jieba.enable_parallel(4) # 开启并行分词模式,参数为并行进程数,不支持windows word_cut = jieba.cut(raw, cut_all=False) # 精确模式,返回的结构是一个可迭代的genertor word_list = list(word_cut) # genertor转化为list,每个词unicode格式 jieba.disable_parallel() # 关闭并行分词模式 data_list.append(word_list) # 训练集list class_list.append(folder.encode('utf-8').decode('utf-8')) # 类别 j += 1 ## 粗暴地划分训练集和测试集 data_class_list = list(zip(data_list, class_list)) random.shuffle(data_class_list) index = int(len(data_class_list) * test_size) + 1 train_list = data_class_list[index:] test_list = data_class_list[:index] train_data_list, train_class_list = list(zip(*train_list)) test_data_list, test_class_list = list(zip(*test_list)) # print("test_data_list -> ",test_data_list) # print("test_class_list -> ",test_class_list) # 其实可以用sklearn自带的部分做 # train_data_list, test_data_list, train_class_list, test_class_list = sklearn.cross_validation.train_test_split(data_list, class_list, test_size=test_size) # 统计词频放入all_words_dict all_words_dict = { } for word_list in train_data_list: for word in word_list: if word in all_words_dict: all_words_dict[word] += 1 else: all_words_dict[word] = 1 # key函数利用词频进行降序排序 all_words_tuple_list = sorted(all_words_dict.items(), key=lambda f: f[1], reverse=True) # 内建函数sorted参数需为list all_words_list = list(zip(*all_words_tuple_list))[0] return all_words_list, train_data_list, test_data_list, train_class_list, test_class_listdef words_dict(all_words_list, deleteN, stopwords_set=set()): # 选取特征词 feature_words = [] n = 1 for t in range(deleteN, len(all_words_list), 1): if n > 1000: # feature_words的维度1000 break if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len( all_words_list[t]) < 5: feature_words.append(all_words_list[t]) n += 1 return feature_words# 文本特征def text_features(train_data_list, test_data_list, feature_words, flag): def text_features(text, feature_words): text_words = set(text) # ----------------------------------------------------------------------------------- if flag == 'nltk': ## nltk特征 dict features = { word:1 if word in text_words else 0 for word in feature_words} elif flag == 'sklearn': ## sklearn特征 list features = [1 if word in text_words else 0 for word in feature_words] else: features = [] # ----------------------------------------------------------------------------------- return features train_feature_list = [text_features(text, feature_words) for text in train_data_list] # print("train_feature_list -> ",train_feature_list) test_feature_list = [text_features(text, feature_words) for text in test_data_list] return train_feature_list, test_feature_list# 分类,同时输出准确率等def text_classifier(train_feature_list, test_feature_list, train_class_list, test_class_list, flag): ## ----------------------------------------------------------------------------------- if flag == 'nltk': ## 使用nltk分类器 train_flist = zip(train_feature_list, train_class_list) test_flist = zip(test_feature_list, test_class_list) classifier = nltk.classify.NaiveBayesClassifier.train(train_flist) test_accuracy = nltk.classify.accuracy(classifier, test_flist) elif flag == 'sklearn': ## sklearn分类器 classifier = MultinomialNB().fit(train_feature_list, train_class_list) test_accuracy = classifier.score(test_feature_list, test_class_list) else: test_accuracy = [] return test_accuracyprint("start")## 文本预处理folder_path = './Database/SogouC/Sample'all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = text_processing(folder_path, test_size=0.2)# 生成stopwords_setstopwords_file = './stopwords_cn.txt'stopwords_set = make_word_set(stopwords_file)## 文本特征提取和分类# flag = 'nltk'flag = 'sklearn'deleteNs = range(0, 1000, 20)test_accuracy_list = []for deleteN in deleteNs: # feature_words = words_dict(all_words_list, deleteN) feature_words = words_dict(all_words_list, deleteN, stopwords_set) train_feature_list, test_feature_list = text_features(train_data_list, test_data_list, feature_words, flag) test_accuracy = text_classifier(train_feature_list, test_feature_list, train_class_list, test_class_list, flag) test_accuracy_list.append(test_accuracy)print(test_accuracy_list)# 结果评价#plt.figure()plt.plot(deleteNs, test_accuracy_list)plt.title('Relationship of deleteNs and test_accuracy')plt.xlabel('deleteNs')plt.ylabel('test_accuracy')plt.show()#plt.savefig('result.png')print("finished") 结果展示:
LanguageDetect (python3.7)
import refrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import MultinomialNBclass LanguageDetector(): def __init__(self, classifier=MultinomialNB()): # 模型 self.classifier = classifier # 特征抽取 self.vectorizer = CountVectorizer(ngram_range=(1,2), max_features=1000, preprocessor=self._remove_noise) def _remove_noise(self, document): noise_pattern = re.compile("|".join(["http\S+", "\@\w+", "\#\w+"])) clean_text = re.sub(noise_pattern, "", document) return clean_text def features(self, X): # 特征 return self.vectorizer.transform(X) def fit(self, X, y): # 拟合(学习) self.vectorizer.fit(X) self.classifier.fit(self.features(X), y) def predict(self, x): return self.classifier.predict(self.features([x])) def score(self, X, y): return self.classifier.score(self.features(X), y)in_f = open('data.csv') # 读入lines = in_f.readlines()in_f.close() # 读入完成dataset = [(line.strip()[:-3], line.strip()[-2:]) for line in lines] # 拥有了 数据集print("dataset[0] -> ",dataset[0]) # dataset[0] -> ('1 december wereld aids dag voorlichting in zuidafrika over bieten taboes en optimisme', 'nl')x, y = zip(*dataset) # 解压print("x -> ", x)print("y -> ", y)x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1) # 划分 训练集与 测试集language_detector = LanguageDetector()language_detector.fit(x_train, y_train)print(language_detector.predict('What language are you speaking now?'))print(language_detector.score(x_train, y_train)) # 皮一下很开心 在训练集上跑一下print(language_detector.score(x_test, y_test)) 结果展示:
dataset[0] -> (‘1 december wereld aids dag voorlichting in zuidafrika over bieten taboes en optimisme’, ‘nl’) x -> (‘1 december wereld aids dag voorlichting in zuidafrika over bieten taboes en optimisme’, '1 millón de afectados ante las inundaciones en sri… y -> (‘nl’, ‘es’, ‘es’, ‘it’, ‘de’, ‘nl’, ‘en’, ‘fr’, ‘de’, ‘en’, ‘en’, ‘fr’, ‘nl’, ‘fr’, ‘fr’, ‘de’, ‘fr’, ‘fr’, ‘nl’, ‘nl’… [‘en’] 0.9797028974849242 0.9770621967357741编写代码中遇到的 问题 及 解决方法
#出现“cannot identify image file ‘/Users//.DS_Store’”问题的解决办法
采用的做法是,cd 到这个文件夹,然后给出这样一条指令:
sudo find ./ -name “.DS_Store” -depth -exec rm {} ;
#TypeError: object of type ‘zip’ has no len()、‘zip’ object is not subscriptable
Try using list(zip(…) where you have zip(…) – python3.0
#‘dict’ object has no attribute ‘has_key’ 解决办法
修改代码
if dict.has_key(key1): 改为 if key1 in adict:
#TypeError: ‘zip’ object is not subscriptable
原代码:
for dog,cat in zip(dp.dogs,dp.cats)[:1000]: 解决方法:使用list包装zip对象 for dog,cat in list(zip(dp.dogs,dp.cats))[:1000]:
#文件操作中open()与with open() as… 间的差异
首先,在执行”fp = open(“./aa.txt”, “w+”)”这行语句时,系统需要为这个文件操作腾出一个空地(运行内存),一直供这个文件操作使用,直至执行”fp.close()”语句时,相应的内存空间才会被释放。
with…as…是根据代码块(隶属)关系进行工作的,当程序执行在代码块内时,文件会一直保持打开状态,一旦当程序离开这个代码块(即不隶属这个区间)时,程序就会自动的关闭这个文件.
#python中zip()与zip(*)的用法解析
zip在英文中有拉链的意思,我们由此可以形象的理解它的作用:将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
a = [1,2,3] b = [4,5,6] c = [4,5,6,7,8] zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] zip(*zipped) # 与 zip 相反,可理解为解压,为zip的逆过程,可用于矩阵的转置 [(1, 2, 3), (4, 5, 6)]

转载地址:https://codingpark.blog.csdn.net/article/details/105611848 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
