使用spyder编写爬虫_CodingPark编程公园

 这样我们就确定可以爬取了
这样我们就确定可以爬取了 

发布日期:2021-06-29 15:46:22
浏览次数:2
分类:技术文章
本文共 4818 字,大约阅读时间需要 16 分钟。
文章介绍
本文主要讲述了利用Anaconda spyder进行爬虫编写
使用spyder编写爬虫

准备工作
这次我们使用 heartbeat -> cid
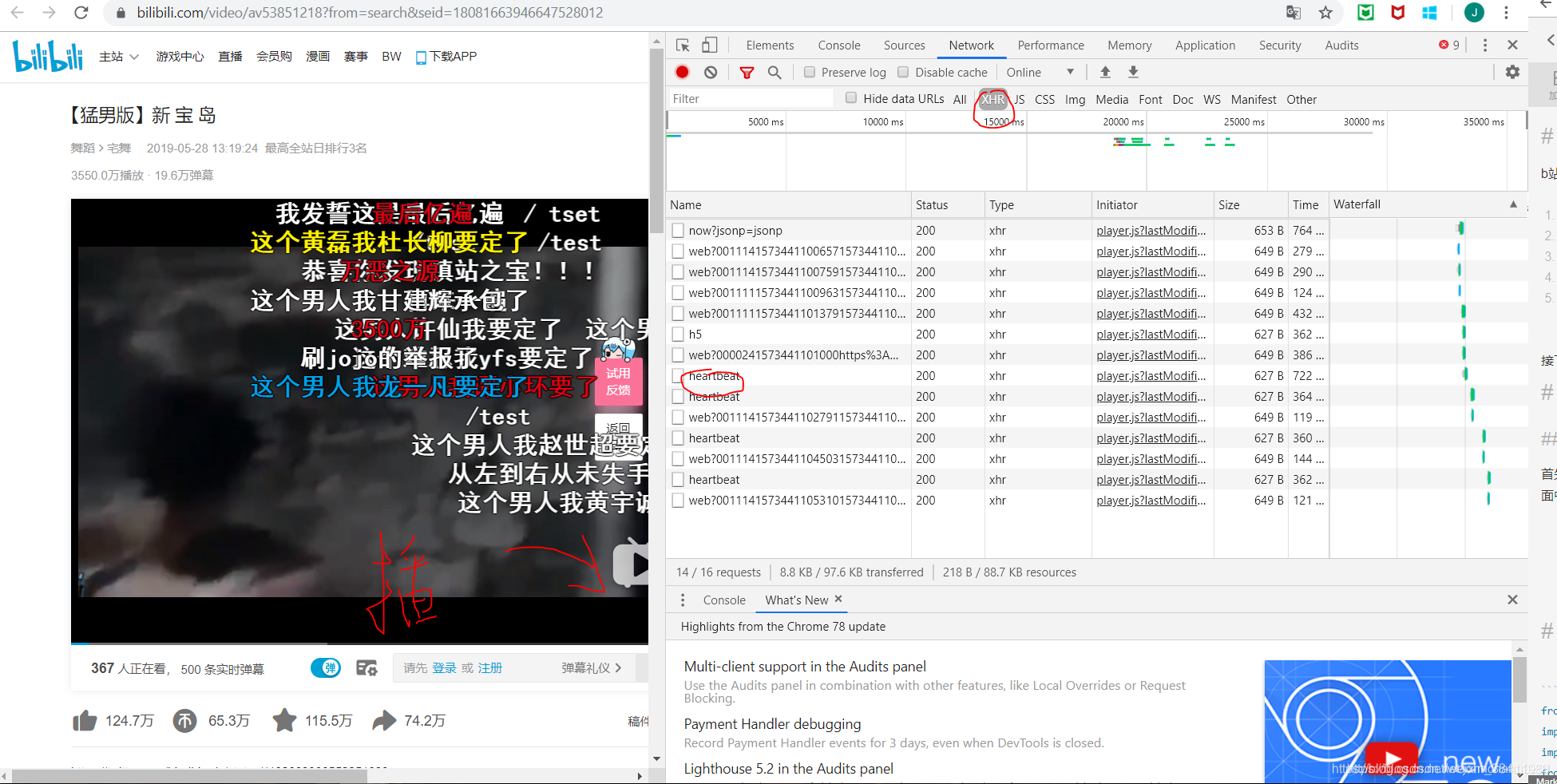
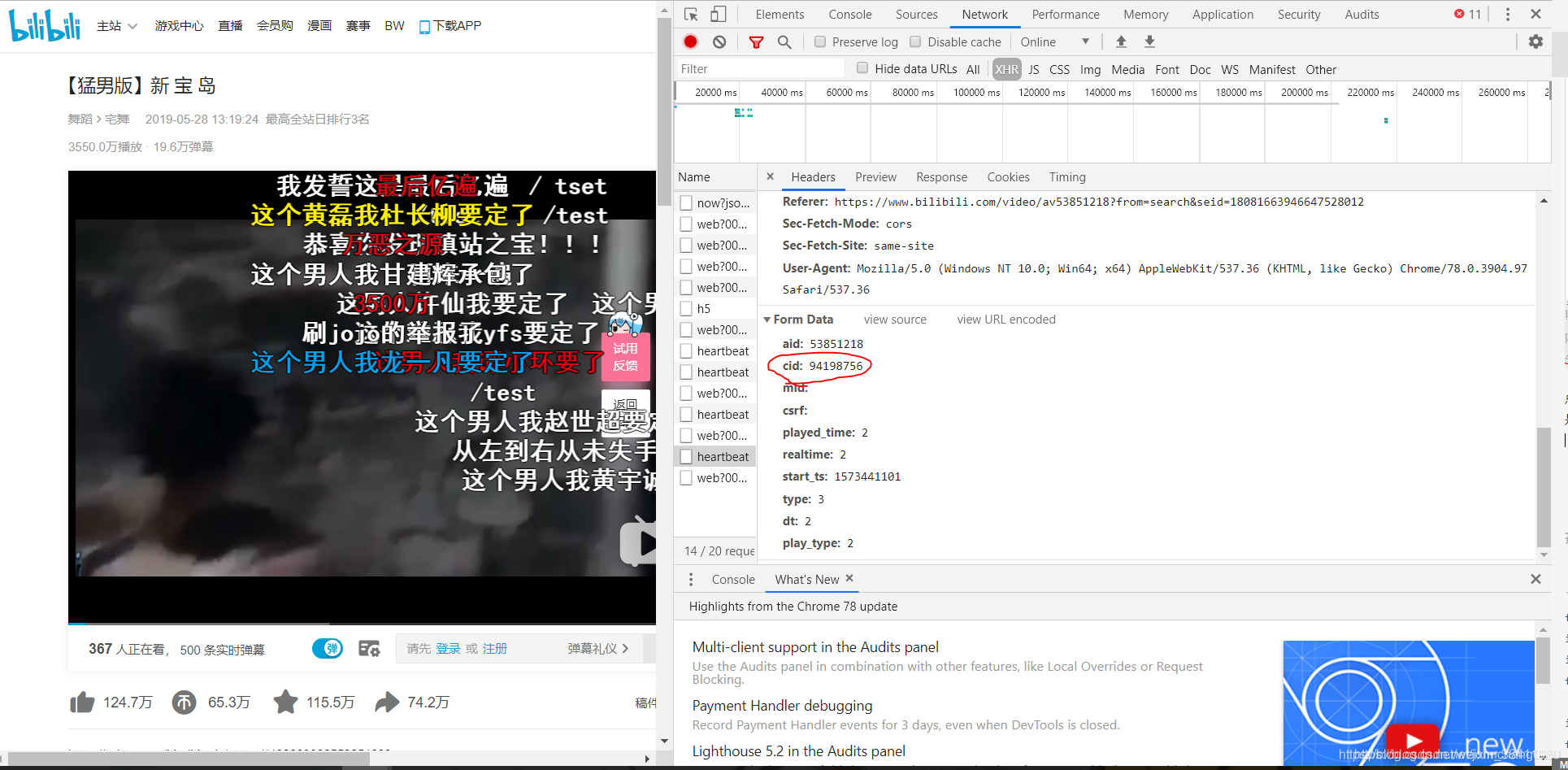
我们拿到cid之后就可以去检查一下是否可以获取弹幕了。获取的固定xml格式是:
https://comment.bilibili.com/视频的cid.xml
例如在这里我们的页面就是:
'https://comment.bilibili.com/94198756.xml'
我们把这个链接用网页的方式打开,就能看到如下内容:
这样我们就确定可以爬取了 需要注意的坑
1
每行脚本按 command + 回车 —> 执行 ⚠️每行都需执行一次 2
可以不写print语句 而选取所要print的部分进行 ** command + 回车 —> 执行** 输出 3
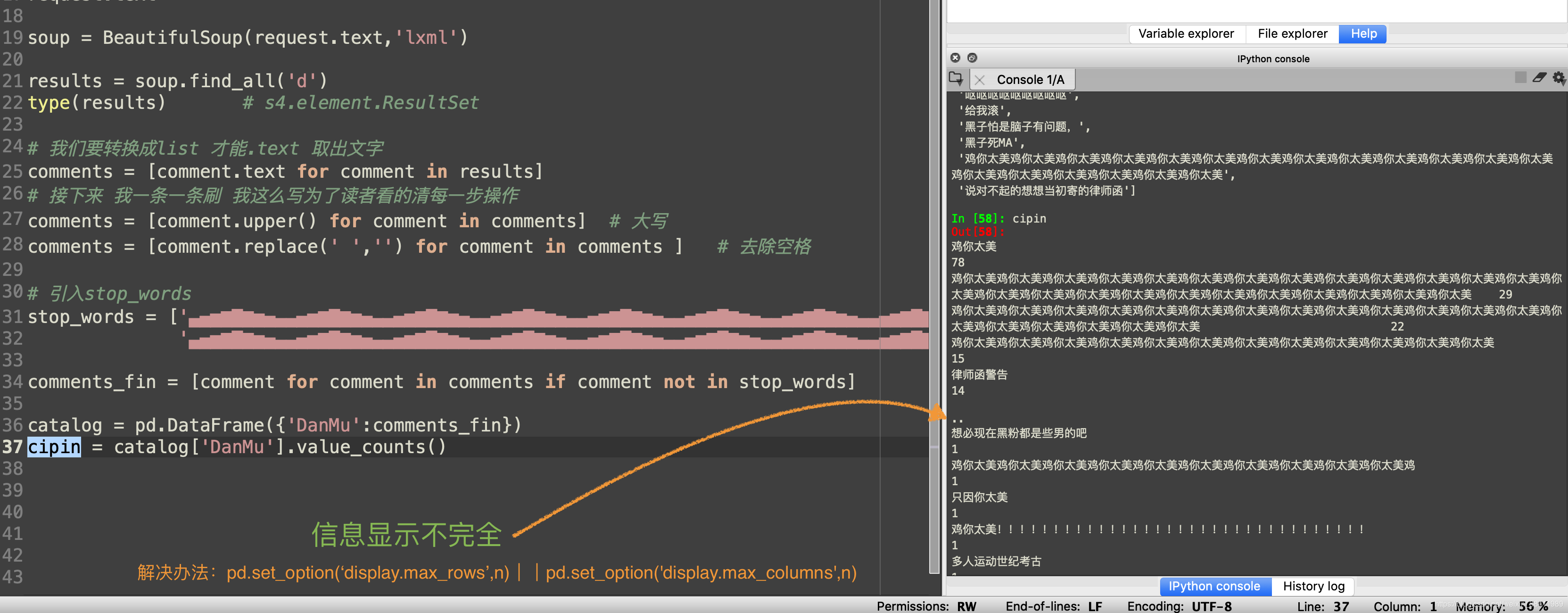
终端输出信息不完全 pd.set_option(‘display.max_rows’,n)将看不到的行显示完整
import numpy as npimport pandas as pdpd.set_option('display.max_columns',10)pd.set_option('display.max_rows',100) #设置最大可见100行df=pd.DataFrame(np.random.rand(100,10))df.head(100) pd.set_option(‘display.max_columns’,n)将看不到的列显示完整
import numpy as npimport pandas as pdpd.set_option('display.max_columns',10) #给最大列设置为10列df=pd.DataFrame(np.random.rand(2,10))df.head() 完整代码(基础功能)
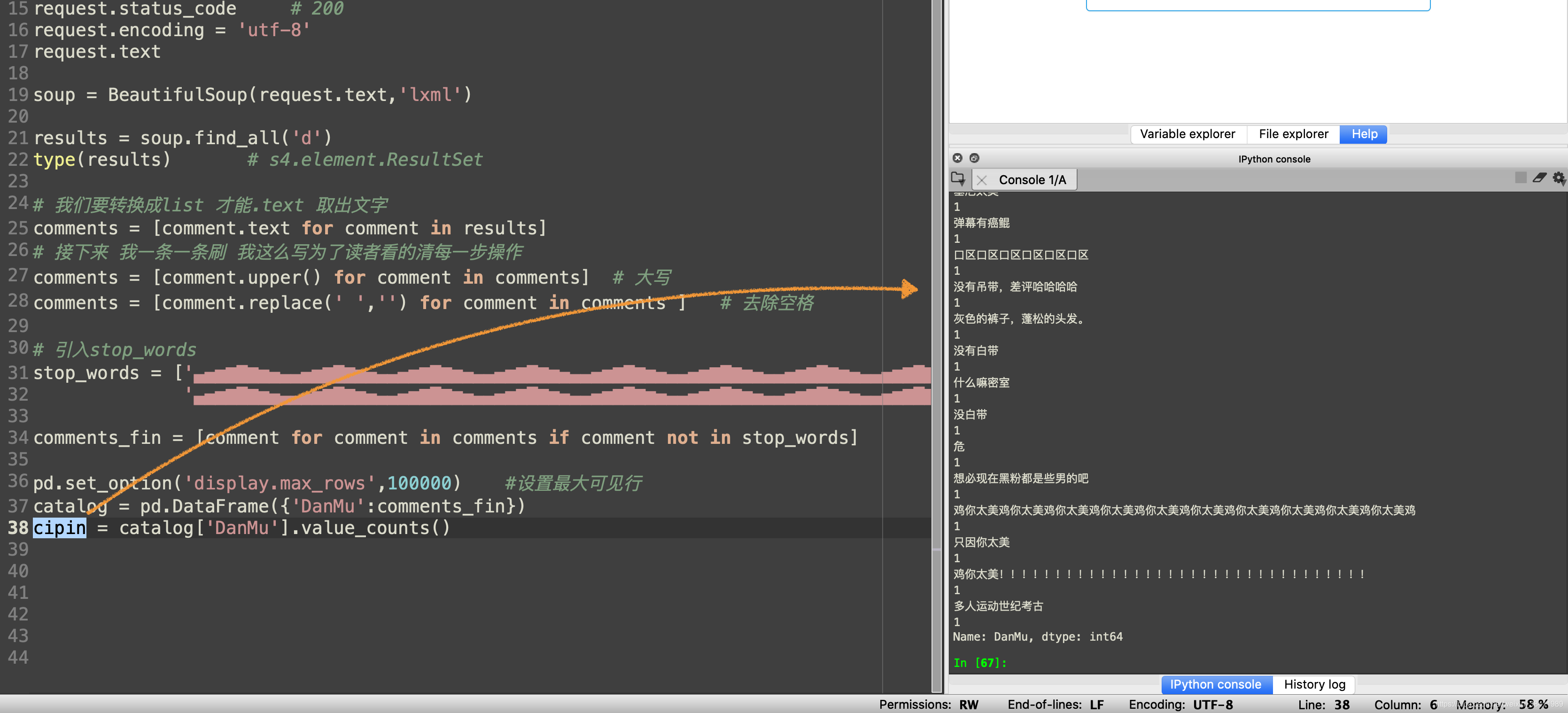
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""Created on Sat May 9 17:34:24 2020@author: atom-g"""import requests from bs4 import BeautifulSoupimport pandas as pd # 数据处理(美化)url = 'https://comment.bilibili.com/83089367.xml'request = requests.get(url)request.status_code # 200request.encoding = 'utf-8'request.textsoup = BeautifulSoup(request.text,'lxml')results = soup.find_all('d')type(results) # s4.element.ResultSet# 我们要转换成list 才能.text 取出文字comments = [comment.text for comment in results]# 接下来 我一条一条刷 我这么写为了读者看的清每一步操作comments = [comment.upper() for comment in comments] # 大写comments = [comment.replace(' ','') for comment in comments ] # 去除空格# 引入stop_wordsstop_words = ['▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅', '▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄']comments_fin = [comment for comment in comments if comment not in stop_words]pd.set_option('display.max_rows',100000) #设置最大可见行catalog = pd.DataFrame({ 'DanMu':comments_fin})cipin = catalog['DanMu'].value_counts() 输出信息
完整代码(Plus)
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""Created on Sat May 9 17:34:24 2020@author: atom-g"""import requests from bs4 import BeautifulSoupimport pandas as pd # 数据处理(美化)import numpy as npurl = 'https://comment.bilibili.com/83089367.xml'request = requests.get(url)request.status_code # 200request.encoding = 'unicode'request.textsoup = BeautifulSoup(request.text,'lxml')results = soup.find_all('d')type(results) # s4.element.ResultSet# 我们要转换成list 才能.text 取出文字comments = [comment.text for comment in results]# 接下来 我一条一条刷 我这么写为了读者看的清每一步操作comments = [comment.upper() for comment in comments] # 大写comments = [comment.replace(' ','') for comment in comments ] # 去除空格# 引入stop_wordsstop_words = ['▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅', '▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▄▄▅▆▇█▇▆▅▄▄▅▆▇█▇▆▅▄▄', ',','!',']','。']comments_fin = [comment for comment in comments if comment not in stop_words]pd.set_option('display.max_rows',100000) # 设置最大可见100行catalog = pd.DataFrame({ 'DanMu':comments_fin})cipin = catalog['DanMu'].value_counts()import jiebaDanMustr = ''.join(i for i in comments_fin if i not in stop_words) # 拼成串words = list(jieba.cut(DanMustr))words_fin_DanMustr = [word for word in words if word not in stop_words] # 这里我学到了stop_word需完全对应才可words_fin_DanMustr_str = ','.join(words_fin_DanMustr)# py 生成本地txtfile_handle=open('/Users/atom-g/spyder/Cai.txt',mode='w')file_handle.write(words_fin_DanMustr_str)file_handle.close()words_fin = [i for i in words if len(i)>1]# np.set_printoptions(threshold=1e6) #利用np全部输出# cc = np.array(words_fin)# cc.tofile('/Users/atom-g/spyder/Cai.txt') # txt至本地import wordcloud # 生成词云wc = wordcloud.WordCloud(height = 1000, width = 1000, font_path = 'simsun.ttc')wc.generate(' '.join(words_fin))from matplotlib import pyplot as pltplt.imshow(wc)wc.to_file('/Users/atom-g/spyder/Cai.png') # 图片至本地 输出信息
✏️Python-list转字符串
命令:''.join(list)其中,引号中是字符之间的分割符,如“,”,“;”,“\t”等等如:list = [1, 2, 3, 4, 5]''.join(list) 结果即为:12345','.join(list) 结果即为:1,2,3,4,5
✏️Python-字符串转list
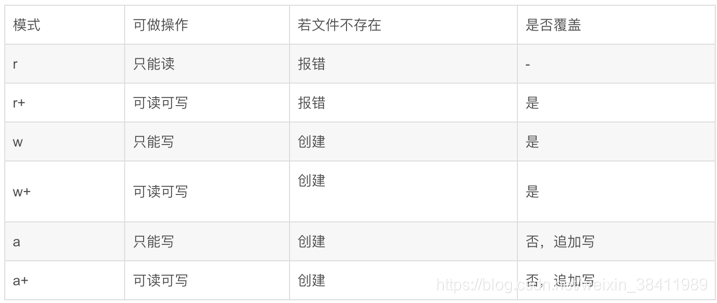
print list('12345')输出: ['1', '2', '3', '4', '5']print list(map(int, '12345'))输出: [1, 2, 3, 4, 5]str2 = "123 sjhid dhi" list2 = str2.split() #or list2 = str2.split(" ") print list2 ['123', 'sjhid', 'dhi']str3 = "www.google.com" list3 = str3.split(".") print list3 ['www', 'google', 'com'] ✏️Python-生成本地txt模式
特别鸣谢
📍Python spyder显示不全df列和行
https://blog.csdn.net/Arwen_H/article/details/83510364?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase 📍python(如何将数据写入本地txt文本文件) https://blog.csdn.net/huo_1214/article/details/79153847 📍Python list 和 str 互转 https://blog.csdn.net/qq_35531549/article/details/88209377

转载地址:https://codingpark.blog.csdn.net/article/details/106025837 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
初次前来,多多关照!
[***.217.46.12]2024年04月20日 04时49分30秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
欢迎使用CSDN-markdown编辑器
2019-04-29
a标签中href调用js的几种方法
2019-04-29
jstl标签详解
2019-04-29
Eclipse中使用SVN的使用
2019-04-29
JSON.parse和eval的区别
2019-04-29
JQuery中$.ajax()方法参数详解
2019-04-29
正则表达式的数字实例
2019-04-29
OGNL表达式struts2标签“%,#,$”的区别
2019-04-29
struts2中<s:if>标签的使用
2019-04-29
js 刷新页面window.location.reload();
2019-04-29
【转】EasyUI 验证
2019-04-29
java开发时内存溢出问题
2019-04-29
【easyui】combobox 关于省市联动
2019-04-29
设置csdn皮肤方法,更改自己喜欢的老版皮肤
2019-04-29
Eclipse中无法查看JDK源码,解决方法
2019-04-29
Git操作常用口令
2019-04-29
IDEA去除掉虚线,波浪线,和下划线实线的方法
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309941292 位访客
访问时间: 2024-05-02 07:42:18
访问IP: 18.188.218.184
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版