数据可视化与文本分类_CodingPark编程公园



发布日期:2021-06-29 15:47:08
浏览次数:3
分类:技术文章
本文共 16211 字,大约阅读时间需要 54 分钟。
文章流程
- 预备知识
- 数据可视化
- 语料获取
- 数据预处理
- 探索数据分布
- 词统计图像可视化与词云图
- 文本分类
- 文本向量化 - bag+tfidf
- 分类模型
预备知识
read_csv 与 to_csv 方法参数详解
read_csv方法定义:
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False, as_recarray=None, compact_ints=None, use_unsigned=None, low_memory=True, buffer_lines=None, memory_map=False, float_precision=None
to_csv方法定义:
DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"', line_terminator='\n', chunksize=None, tupleize_cols=None, date_format=None, doublequote=True, escapechar=None, decimal='.')
python类型转换

python 去除字符串两端的引号

python中单引号(’)、双引号(")、三单引号(’’’)及三双引号(""")的比较
单引号(’)与双引号(")的用法比较 :
1). 二者通常用于单行字符串的表示,也可通过使用\n换行后表示多行字符串 2). 使用单引号(’)表示的字符串中可以直接使用双引号而不必进行转义( \ ’ 或 \ " ),使用双引号表示的字符串同理。单引号、双引号)与(三单引号、三双引号)的用法比较 :
1). (单引号、双引号)表示多行时需要添加换行符\n。 2). (三单引号、三双引号)表示多行时无需使用任何多余字符 3). (三单引号、三双引号)中可直接使用(单引号、双引号)而无需使用反斜杠 \ 进行转义NumPy Ndarray 对象
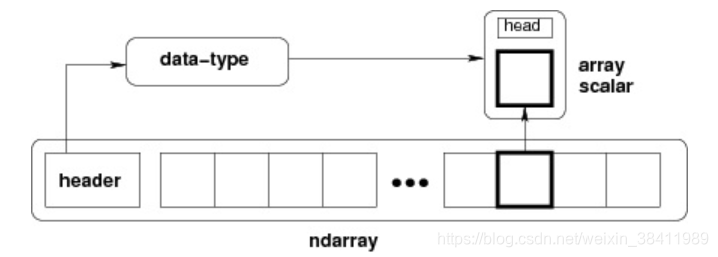
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。 ndarray 中的每个元素在内存中都有相同存储大小的区域。 ndarray 内部由以下内容组成:- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
ndarray 的内部结构:
matplotlib中文乱码
- 下载中文字体(黑体),解压之后在系统当中安装好。
https://www.fontpalace.com/font-details/SimHei/

- 找到matplotlib字体文件夹,例如:/Users/atom-g/opt/anaconda3/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf,将SimHei.ttf拷贝到ttf文件夹下面
- 修改配置文件matplotlibrc 同样在matplotlib/mpl-data/fonts目录下面,修改下面三项配置 font.family : sans-serif font.sans-serif : SimHei, Bitstream Vera Sans, Lucida Grande, Verdana, Geneva, Lucid, Arial, Helvetica, Avant Garde, sans-serif axes.unicode_minus: False,#作用就是解决负号’-'显示为方块的问题
- 重新加载字体,在Python中运行如下代码即可: from matplotlib.font_manager import _rebuild _rebuild() # reload一下 (第一次运行可能还是不行,没关系第二次就会成功的)
如果还不行,建议加入以下语句进行尝试
每次编写代码时进行参数设置
#coding:utf-8 import matplotlib.pyplot as plt plt.rcParams[‘font.sans-serif’]=[‘SimHei’] #用来正常显示中文标签 plt.rcParams[‘axes.unicode_minus’]=False #用来正常显示负号零碎知识
r’’’…’’'是原字符串,\反斜线不会特殊对待
str() 函数将对象转化为适于人阅读的形式。
数据可视化

https://matplotlib.org/index.html
语料获取
chinese_news.csv
https://www.kaggle.com
数据预处理
# -*- encoding: utf-8 -*-"""@File : pretreatment.py @Contact : ag@team-ag.club@License : (C)Copyright 2019-2020, CodingPark@Modify Time @Author @Version @Desciption------------ ------- -------- -----------2020-07-21 16:18 AG 1.0 数据预处理 流程1"""'''基础设施 及 数据导入'''import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport reimport jiebafrom itertools import chainfrom collections import Counternews = pd.read_csv("chinese_news.csv")plt.rcParams["font.family"] = "SimHei"plt.rcParams["axes.unicode_minus"] = False# pandas的dataFrame输出不换行pd.set_option('display.max_rows', 500) # 设置最大可见100行pd.set_option('display.max_columns', 500)pd.set_option('display.width', 5000)# print(news.shape) # okk# print(news.head(10)) # okk'''缺失值处理'''# 方法1 简单快捷 【推荐】# print(news.isnull().sum())# # 方法2 展示详细信息# print(news.info())index = news[news["content"].isnull()].indexnews["content"][index] = news["headline"][index]# print('\n处理后 ->')# print(news.isnull().sum())# print(news.loc[index].sample(5))'''重复值处理'''# print('重复值数量 ->', news.duplicated().sum())# print('重复值内容 ->')# print(news[news.duplicated()])news.drop_duplicates(inplace=True)# print('处理后重复值数量 ->', news.duplicated().sum())'''文本内容清理'''pattern = r"[`~!@#$^&*()=|{}':;',.<>/?~!@#¥……&*()——|{}【】‘;::”“'。,、?%+_\n]"re_obj = re.compile(pattern)def clear(text): return re_obj.sub("", text)news["content"] = news["content"].apply(clear)# print(news.sample(5))'''分词'''def cut_word(text): return jieba.cut(text)news["content"] = news["content"].apply(cut_word)# print(news.sample(5))'''去除停用词'''def get_stopword(): s = set() with open("chineseStopWords.txt", encoding="gbk") as f: for line in f: s.add(line.strip()) return sdef remove_stopword(words): return [word for word in words if word not in stopword]stopword = get_stopword()news["content"] = news["content"].apply(remove_stopword)# print(news.sample(5))news.to_csv('ripe_chinese_news.csv', index=None, encoding='utf-8-sig') # csv保存# 补充'''@ => wordcount.py[begin]'''li_2d = news['content'].tolist() # 蹿到一起 [[],[],[],[]]# print(li_2d)li_1d = list(chain.from_iterable(li_2d)) # 扁平化为1d : [[3,4],[7,8]] => [3,4,7,8]print(f'总词汇量:{len(li_1d)}')Dic = Counter(li_1d) # 可以理解成去重 但其实是字典化。 (新华字典)的感觉print(f'不重复的词汇数量{len(Dic)}')top15 = Dic.most_common(15)print('重复率最高的Top15', top15)'''@ => wordcount.py[end]''' 探索数据分布
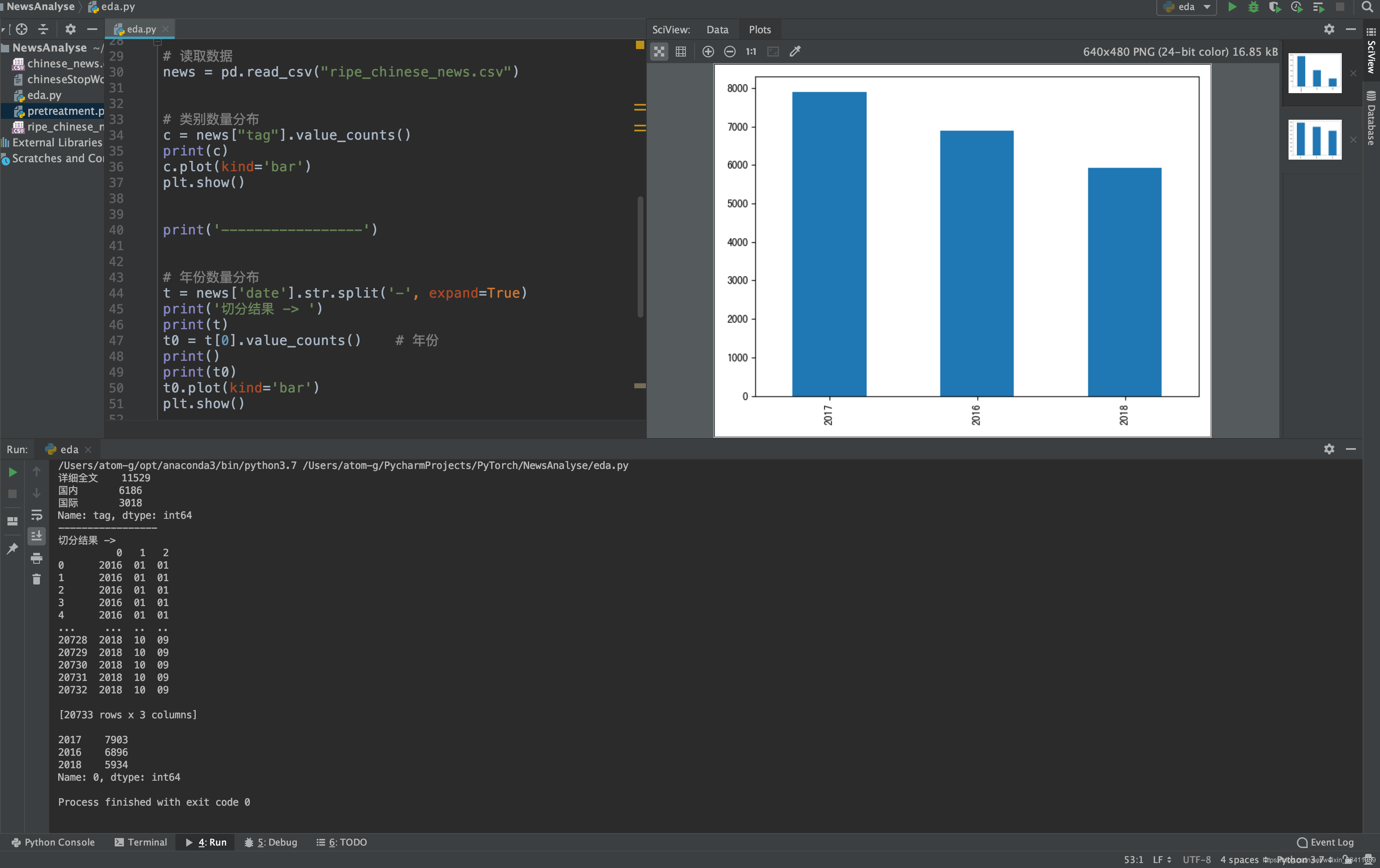
# -*- encoding: utf-8 -*-"""@File : eda.py@Contact : ag@team-ag.club@License : (C)Copyright 2019-2020, CodingPark@Modify Time @Author @Version @Desciption------------ ------- -------- -----------2020-07-21 17:57 AG 1.0 探索数据分布 流程2"""from matplotlib.font_manager import _rebuildimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport reimport jieba# _rebuild() # reload一下 重新加载字体# plt.rcParams["font.family"] = "SimHei"# plt.rcParams["axes.unicode_minus"] = False'''探索数据分布'''# 读取数据news = pd.read_csv("ripe_chinese_news.csv")# 类别数量分布c = news["tag"].value_counts()print(c)c.plot(kind='bar')plt.show()print('-----------------')# 年份数量分布t = news['date'].str.split('-', expand=True)print('切分结果 -> ')print(t)t0 = t[0].value_counts() # 年份print()print(t0)t0.plot(kind='bar')plt.show() 结果展示
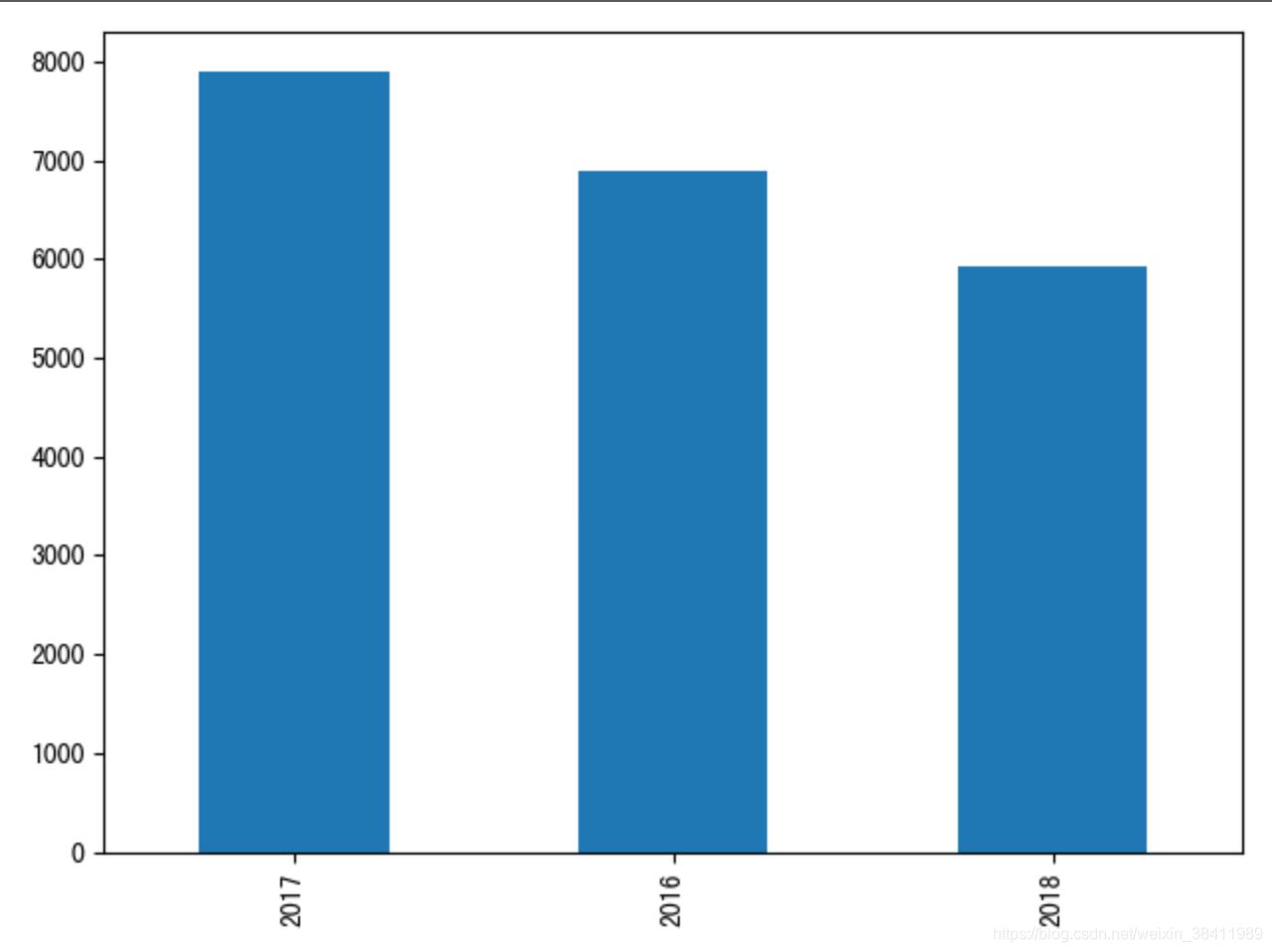

词统计可视化与词云图
# -*- encoding: utf-8 -*-"""@File : wordcount.py @Contact : ag@team-ag.club@License : (C)Copyright 2019-2020, CodingPark@Modify Time @Author @Version @Desciption------------ ------- -------- -----------2020-07-21 21:00 AG 1.0 词统计与词云图 流程3@Desciption =>这个就很有意思了 我下面的代码是一种实现办法 ,可以实现:总词汇量:2223350不重复的词汇数量94747重复率最高的Top15 [('发展', 20414),....然而我在 pretreatment中也续了点有关实现这个功能的代码💡需要思考的是: 出现pretreatment.py 可直接实现 而 wordcount.py不行的原因 =》原因是news = pd.read_csv("ripe_chinese_news.csv")里面的news['content'].values是用双引号包裹的。双引号包裹的例如["['你好', '没错']", "['的确', '没有']"]tolist()后会切分成 一个一个 完全单独的个体"""'''词汇量统计'''from matplotlib.font_manager import _rebuildimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport reimport jiebafrom itertools import chainfrom collections import Counterfrom PIL import Imagenews = pd.read_csv("ripe_chinese_news.csv")listcc = []for i in news['content'].values: cc = eval(i) listcc.append(cc)li_1d = list(chain.from_iterable(listcc))print(f'总词汇量:{len(li_1d)}')Dic = Counter(li_1d) # 可以理解成去重 但其实是字典化。 (新华字典)的感觉print(f'不重复的词汇数量{len(Dic)}')top15 = Dic.most_common(15)print('重复率最高的Top15', top15)'''词频统计'''voc, fre = [], []for v, f in top15: voc.append(v) fre.append(f)# 图绘制plt.figure(figsize=(12, 5))plt.bar(voc, fre)plt.title("词频统计")plt.show()'''百分比统计'''total = len(li_1d)precentage = [f * 100 / total for f in fre]print('\n词频占种词汇量的比例 ⬇ ')print([f'{i:.2f}%'for i in precentage])# 图绘制plt.figure(figsize=(12, 5))colors = ['#CD5C5C', '#800080', '#7B68EE', '#191970', '#B0C4DE', '#87CEFA', '#D4F2E7', '#48D1CC', '#3CB371', '#006400', '#DAA520', '#FFEFD5', '#FF4500', '#FA8072', '#808080'] # 自定义颜色列表plt.pie(precentage, labels=voc, colors=colors)plt.title("词频百分比展示")plt.show()'''新闻词汇长度统计'''num = [len(li) for li in listcc]length = 15plt.bar(range(length), sorted(num, reverse=True)[:length], color='c')plt.title("新闻词汇长度统计")plt.show()plt.hist(num) # 分布直方图plt.title("新闻词汇长度分布直方图")plt.show()'''生成词云图'''# 仅仅是好玩,因为它不准确from wordcloud import WordCloudmask = np.array(Image.open('china.jpg')) # 推荐白色背景色图片wc = WordCloud(font_path='SimHei.ttf', background_color='#8B0000', width=800, height=600, mask=mask, collocations=False)join_words = ' '.join(li_1d)img = wc.generate(join_words)# 图绘制plt.figure(figsize=(15, 10))plt.imshow(img)plt.axis('off')plt.title("词云图")plt.show()# wc.to_file('wordcloud.png') # 本地生成 特别注意
文本分类
文本向量化 - bag+tfidf
文档转词袋
三步走
- 词袋词向量 (CountVectorizer)
- 词袋➕tfidf词向量 (CountVectorizer + TfidfTransformer)
- Tf-Idf词向量 (tf-idfVectorrizer)
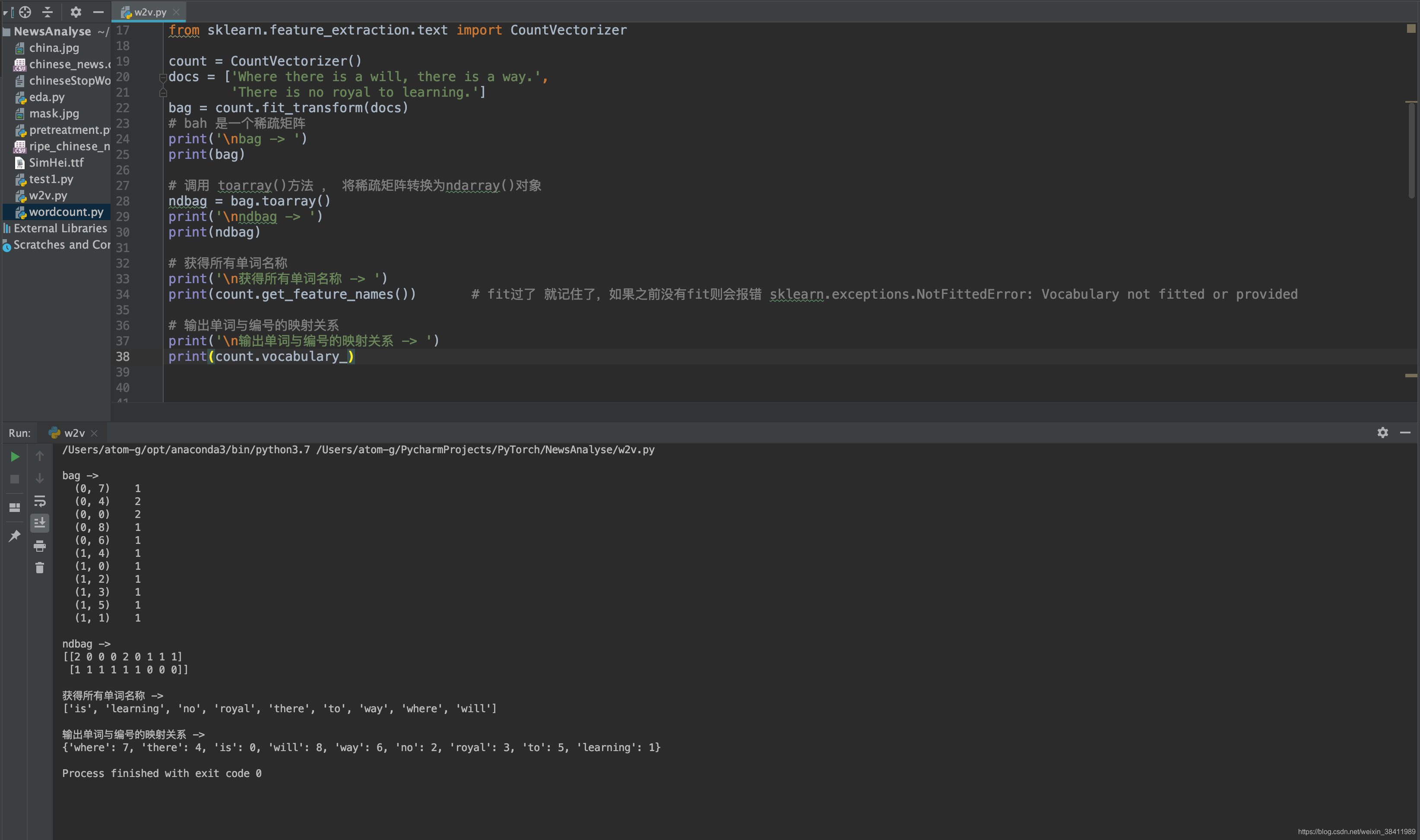
# -*- encoding: utf-8 -*-"""@File : w2v.py @Contact : ag@team-ag.club@License : (C)Copyright 2019-2020, CodingPark@Modify Time @Author @Version @Desciption------------ ------- -------- -----------2020-07-22 11:05 AG 1.0 文本向量化 引例 流程4"""'''词袋'''print('\n\n------- CountVectorizer -------\n\n')from sklearn.feature_extraction.text import CountVectorizercount = CountVectorizer()docs = ['Where there is a will, there is a way.', 'There is no royal to learning.']bag = count.fit_transform(docs)# bah 是一个稀疏矩阵print('\nbag -> ')print(bag)# 调用 toarray()方法 , 将稀疏矩阵转换为ndarray()对象ndbag = bag.toarray()print('\nndbag -> ')print(ndbag)# 获得所有单词名称print('\n获得所有单词名称 -> ')print(count.get_feature_names()) # fit过了 就记住了,如果之前没有fit则会报错 sklearn.exceptions.NotFittedError: Vocabulary not fitted or provided# 输出单词与编号的映射关系print('\n输出单词与编号的映射关系 -> ')print(count.vocabulary_)test_docs = ['While there is life there is hope.', 'No pain, no gain.']t = count.transform(test_docs)print('\nndtest_docs -> ')print(t.toarray())'''tf-idf'''print('\n\n------- TfidfTransformer -------\n\n')from sklearn.feature_extraction.text import TfidfTransformercount = CountVectorizer()docs = ['Where there is a will, there is a way.', 'There is no royal to learning.']bag = count.fit_transform(docs)tfidf = TfidfTransformer()tbag = tfidf.fit_transform(bag)# TfidfTransformer 运算结果也是=>稀疏矩阵# 调用 toarray()方法 , 将稀疏矩阵转换为ndarray()对象print('\ntbag -> ')print(tbag.toarray())'''tf-idfVectorrizer = CountVectorizer + TfidfTransformer'''print('\n\n-------tf-idfVectorrizer = CountVectorizer + TfidfTransformer-------\n\n')from sklearn.feature_extraction.text import TfidfVectorizerdocs = ['Where there is a will, there is a way.', 'There is no royal to learning.']tfidfVec = TfidfVectorizer()tfVecbag = tfidfVec.fit_transform(docs)print('\ntfVecbag -> ')print(tfVecbag.toarray()) 结果展示
分类模型
五步走
- 数据预处理
- 切分训练集&测试集
- 文本向量化(内容向量化 + 标签数字化)
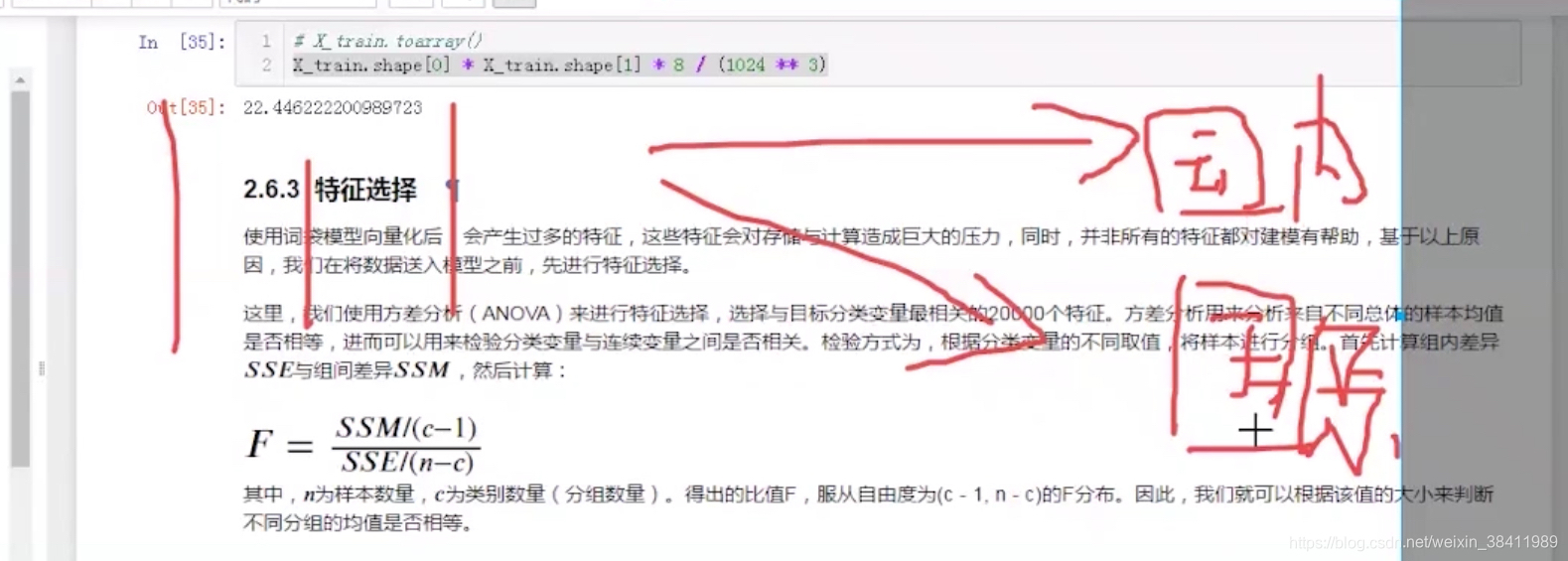
- 特征选择方差分析 F检验 (把影响力小的词处理掉)
- 训练与评估 (朴素贝叶斯)
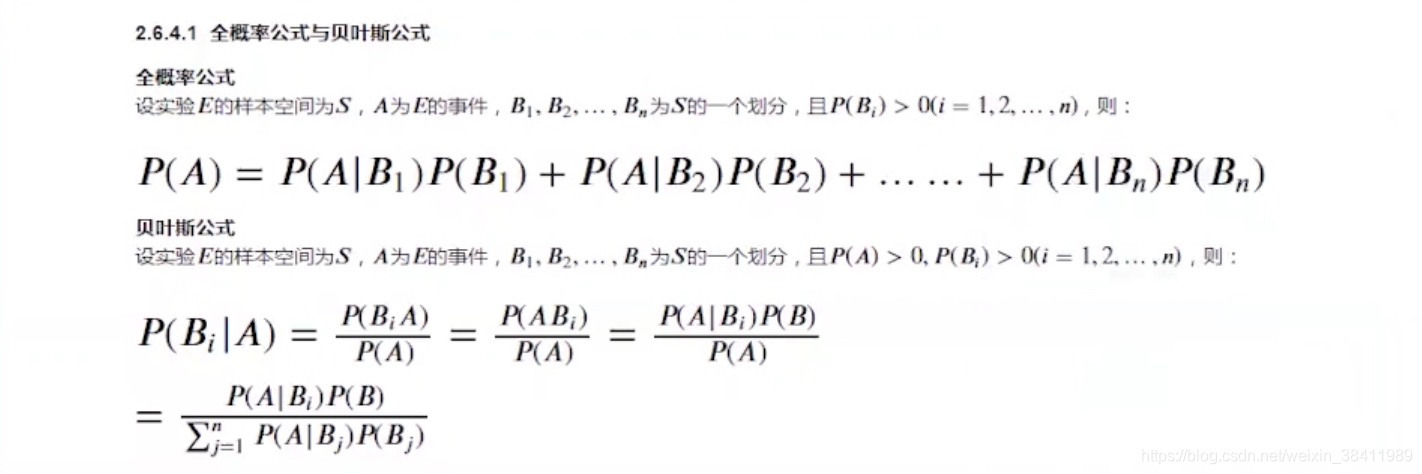
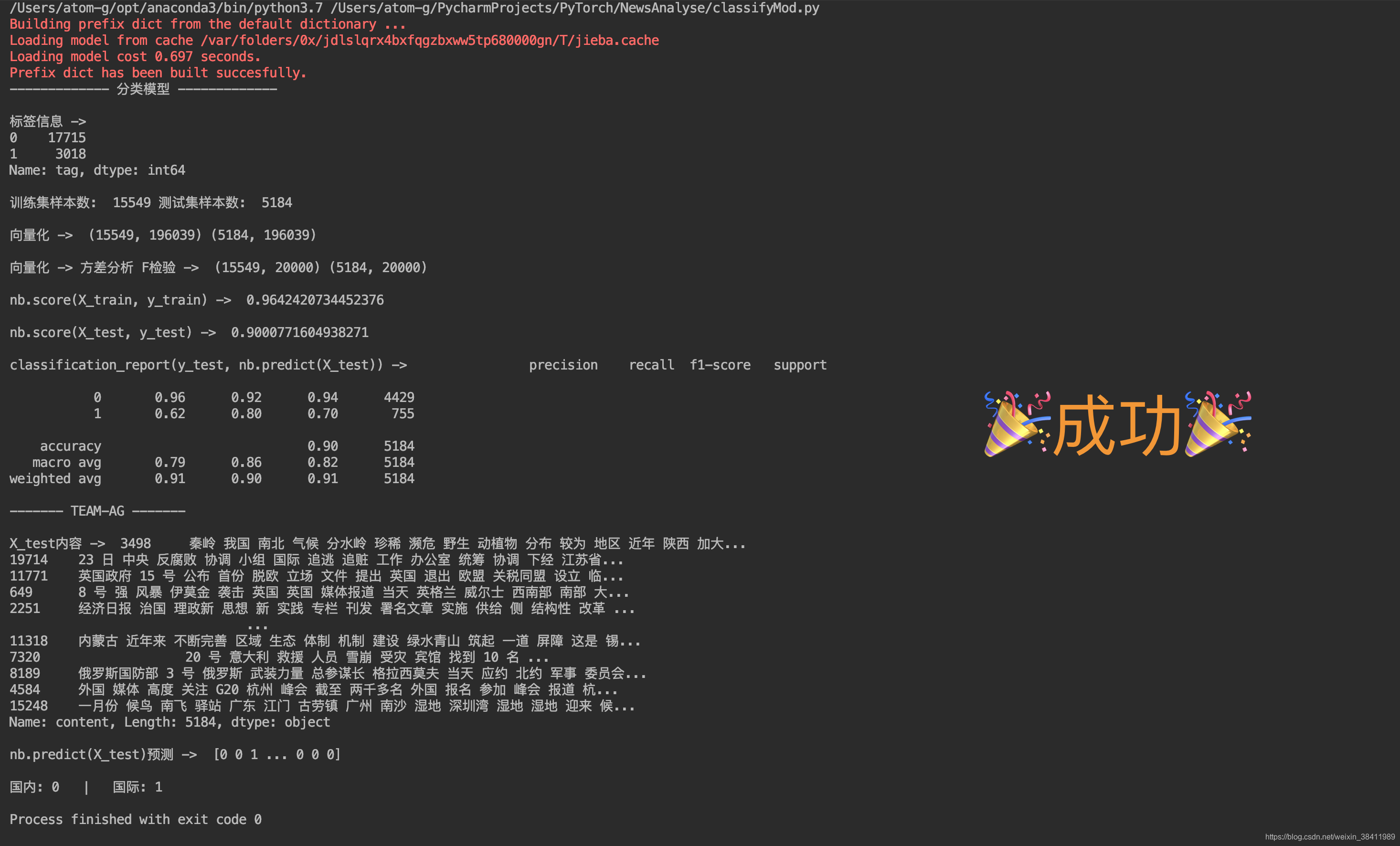
# -*- encoding: utf-8 -*-"""@File : classifyMod.py @Contact : ag@team-ag.club@License : (C)Copyright 2019-2020, CodingPark@Modify Time @Author @Version @Desciption------------ ------- -------- -----------2020-07-22 15:02 AG 1.0 分类模型 流程5"""'''基础设施 及 数据导入'''import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport reimport jiebafrom itertools import chainfrom collections import Counternews = pd.read_csv("chinese_news.csv")plt.rcParams["font.family"] = "SimHei"plt.rcParams["axes.unicode_minus"] = False# pandas的dataFrame输出不换行pd.set_option('display.max_rows', 500) # 设置最大可见100行pd.set_option('display.max_columns', 500)pd.set_option('display.width', 5000)# print(news.shape) # okk# print(news.head(10)) # okk'''缺失值处理'''# 方法1 简单快捷 【推荐】# print(news.isnull().sum())# # 方法2 展示详细信息# print(news.info())index = news[news["content"].isnull()].indexnews["content"][index] = news["headline"][index]# print('\n处理后 ->')# print(news.isnull().sum())# print(news.loc[index].sample(5))'''重复值处理'''# print('重复值数量 ->', news.duplicated().sum())# print('重复值内容 ->')# print(news[news.duplicated()])news.drop_duplicates(inplace=True)# print('处理后重复值数量 ->', news.duplicated().sum())'''文本内容清理'''pattern = r"[`~!@#$^&*()=|{}':;',.<>/?~!@#¥……&*()——|{}【】‘;::”“'。,、?%+_\n]"re_obj = re.compile(pattern)def clear(text): return re_obj.sub("", text)news["content"] = news["content"].apply(clear)# print(news.sample(5))'''分词'''def cut_word(text): return jieba.cut(text)news["content"] = news["content"].apply(cut_word)# print(news.sample(5))'''去除停用词'''def get_stopword(): s = set() with open("chineseStopWords.txt", encoding="gbk") as f: for line in f: s.add(line.strip()) return sdef remove_stopword(words): return [word for word in words if word not in stopword]stopword = get_stopword()news["content"] = news["content"].apply(remove_stopword)# print(news.sample(5))'''构建 训练集&测试集'''print('------------- 分类模型 -------------')def join(text_list): return ' '.join(text_list)news['content'] = news['content'].apply(join)# print(news.sample(5)) # 成功news['tag'] = news['tag'].map({ '详细全文': 0, '国内': 0, '国际': 1})print('\n标签信息 -> ')print(news['tag'].value_counts())from sklearn.model_selection import train_test_splitX = news['content']y = news['tag']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)contentX_test = X_testprint('\n训练集样本数: ', y_train.shape[0], '测试集样本数: ', y_test.shape[0])'''文本向量化'''from sklearn.feature_extraction.text import TfidfVectorizervec = TfidfVectorizer(min_df=2, ngram_range=(1, 2))X_train = vec.fit_transform(X_train)X_test = vec.transform(X_test)print('\n向量化 -> ', X_train.shape, X_test.shape)# 68bit => 8字节# 1024 ** 3 => G为单位# X_train.shape[0] * X_train.shape[1] * 8 / (1024 ** 3)'''特征选择=>方差分析 F检验=> 把没用的处理掉'''from sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import f_classifselect = SelectKBest(f_classif, k=min(20000, X_train.shape[1]))select.fit(X_train, y_train)X_train = select.transform(X_train).astype(np.float)X_test = select.transform(X_test).astype(np.float)print('\n向量化 -> 方差分析 F检验 -> ', X_train.shape, X_test.shape)'''训练与评估=>朴素贝叶斯'''from sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import classification_reportX_train = X_train.toarray()X_test = X_test.toarray()nb = GaussianNB()nb.fit(X_train, y_train)print('\nnb.score(X_train, y_train) -> ', nb.score(X_train, y_train))print('\nnb.score(X_test, y_test) -> ', nb.score(X_test, y_test))print('\nclassification_report(y_test, nb.predict(X_test)) -> ', classification_report(y_test, nb.predict(X_test)))print('------- TEAM-AG -------')print('\nX_test内容 -> ', contentX_test)print('\nnb.predict(X_test)预测 -> ', nb.predict(X_test))print('\n国内: 0 | 国际: 1') 结果展示
更多信息
📍pandas系列 read_csv 与 to_csv 方法各参数详解(全,中文版)
https://blog.csdn.net/u010801439/article/details/80033341?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159540402419726869001259%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159540402419726869001259&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v3~pc_rank_v2-2-80033341.first_rank_ecpm_v3_pc_rank_v2&utm_term=read_csv内容含有双引号&spm=1018.2118.3001.4187 📍python中单引号(’)、双引号(")、三单引号(’’’)及三双引号(""")的比较 https://blog.csdn.net/JohnyHe/article/details/83461266?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase 📍NumPy Ndarray 对象 https://www.runoob.com/numpy/numpy-ndarray-object.html 📍matplotlib图例中文乱码 https://www.zhihu.com/question/25404709 📍matplotlib 知识点11:绘制饼图(pie 函数精讲) https://www.cnblogs.com/biyoulin/p/9565350.html 📍Matplotlib系列(四)–plt.bar与plt.barh条形图 https://www.cnblogs.com/shine-rainbow/p/10742952.html 📍matplotlib.pyplot.xlim()、ylim()、axis()结构及用法||参数详解 https://blog.csdn.net/The_Time_Runner/article/details/89928057 📍Python生成一篇文章的词云图 https://www.cnblogs.com/yunxiaofei/p/11111643.html 📍wordcloud:自定义背景图片,生成词云 https://blog.csdn.net/fly910905/article/details/77763086?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase

转载地址:https://codingpark.blog.csdn.net/article/details/107522783 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月22日 14时06分01秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
自我学习39:接口自动化测试用例&功能测试用例区别
2019-04-29
mirror去兔子补丁下载 附安装教程
2019-04-29
mirror去兔子补丁 v3.0附安装教程
2019-04-29
mirror去兔子补丁为什么还有兔子_mirror去兔子补丁使用教程
2019-04-29
3dmax2012安装教程
2019-04-29
OC渲染器(Octane Render)整合版安装包 附安装教程
2019-04-29
操作系统期末大题复习
2019-04-29
hive:分区表,hbase外表
2019-04-29
想要成为运维,想要成为后期的架构师?这些知识是必备的!
2019-04-29
linux 是如何 快速一键安装禅道的呐?
2019-04-29
运维面试基础试题(四)
2019-04-29
一键安装Openstack单节点 必能成功
2019-04-29
面试紧张怎么办
2019-04-29
关系型数据库 ,nosql数据库简介
2019-04-29
Centos 7搭建NTP时间同步服务器
2019-04-29
centos7 基于rsync+inotify 实现定时备份
2019-04-29
指定IP进行 文件的分发
2019-04-29
基于http搭建本地yum仓库
2019-04-29
常规邮件基础
2019-04-29
邮件基础之 -- SMTP协议
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310061499 位访客
访问时间: 2024-05-02 16:01:13
访问IP: 13.58.137.218
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版