朴素贝叶斯算法---机器学习算法之三
发布日期:2022-01-31 02:37:26
浏览次数:31
分类:技术文章
本文共 5527 字,大约阅读时间需要 18 分钟。
最近刚刚开始利用空余时间学习一下机器学习领域的10大经典算法,作为知识的储备,算是给自己的学习作一个备份。
何为朴素贝叶斯分类算法
朴素贝叶斯分类算法,基于概率论实现分类,它不给出确切的分类,而是给出所属的类别的估计概率。朴素贝叶斯的理论基础是条件概率和贝叶斯准则条件概率
条件概率公式如下:这里,事件b表示条件。公式的含义可以理解为在事件b发生的前提下,事件a发生的概率 = 事件a、b同时发生的概率 *事件b发生的概率。 如果事件a有多个属性,公式的形式如下:
需要注意的是上述公式成立的一个条件是
相互独立
贝叶斯定理
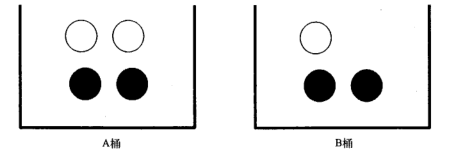
举一个具体的例子,假如现在有一个装了7个球的桶,其中3个是白色的,4个是黑色的,那么随机取出一个球,球是白色的概率为3/7,为黑色的概率是4/7。如果这7个球放在A、B两个桶中,如下图所示:
按照上面的条件概率公式可以知道,p(白/B)=p(白,B)P(B) = (1/7 )/ (3/7) = 1/3。 解释一下p(白/B)和p(白,B)的区别:p(白/B)表示在B桶中抽到一个白球(所以B是限定条件),p(白,B)表示抽到一个白球且这个白球位于B桶中(白球和B桶同时发生)。通常p(白/B)称之为先验概率 那么问题来了,如果知道了p(白/B),如何求P(B/白)的概率,也就是已知抽到一个白球,那么它来自B桶的概率是多少。 这个问题可以利用贝叶斯公式来求解:对于上面这个具体的例子可以有: 抽到白球的概率p(白)=p(白/A)p(A)+p(白/B)p(B) = (2/4)(4/7) + (1/3) (3/7) = 3/7 也就是白球发生的概率是3/7 p(白/B)p(B) = 1/7 p(B/白) = (1/7) / (3/7) = 1/3
为什么是朴素贝叶斯
这里面有个假设——各个属性间互相独立决策标准
如果p(1/x,y) > p(2/x,y), 那么属于类别1 如果p(2/x,y) > p(1/x,y), 那么属于类别2缺陷
因为没有这里假设各个属性相互独立,但是在某些情况下,属性B出现的概率依赖于其他属性,这时候分类的准确度会有偏差,解决办法在后面的博文中会介绍实现代码
使用python语言实现,这里有一个小技巧,对于连乘的数学表达式,采用取对数的方式,变成加法,作用是防止出现某一项为0导致整个表达式为0的情况
@python# -*- coding:utf-8 -*-__author__ = 'Administrator'from numpy import *def loadDataSet(): postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid'] ] classVec = [0, 1, 0, 1, 0, 1] # 1表示出现侮辱性文字,0表示没有出现侮辱性文字 return postingList, classVecdef createVocabList(dataSet): vocabSet = set([]) for document in dataSet: vocabSet = vocabSet | set(document) return list(vocabSet)def setOfWords2Vec(vocabList, inputSet): returnVec = [0] * len(vocabList) # python 中,列表乘以一个常数n,表示列表中所有元素作为整体重复n次 for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my vocablist!" % word) return returnVecdef bagOfWords2Vec(vocabList, inputSet): returnVec = [0] * len(vocabList) # python 中,列表乘以一个常数n,表示列表中所有元素作为整体重复n次 for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] += 1 else: print("the word: %s is not in my vocablist!" % word) return returnVecdef trainNB0(trainMatrix, trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory) / float(numTrainDocs) # p0Num = zeros(numWords) # p1Num = zeros(numWords) p0Num = ones(numWords) p1Num = ones(numWords) p0Denom = 2.0 p1Denom = 2.0 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) # 该类中包含的所有词汇的总数 else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) # 该类中包含的所有词汇的总数 p1Vec = log(p1Num / p1Denom) p0Vec = log(p0Num / p0Denom) return p0Vec, p1Vec, pAbusivedef classifyNB(vec2Classify, p0vec, p1vec, pClass1): p1 = sum(vec2Classify * p1vec) + log(pClass1) p0 = sum(vec2Classify * p0vec) + log(1-pClass1) if p1 > p0: return 1 else: return 0def testingNb(): listOPosts, listClasses = loadDataSet() myVocabList = createVocabList(listOPosts) trainMat = [] for postinDoc in listOPosts: trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) p0v, p1v, pAb = trainNB0(array(trainMat), array(listClasses)) testEntry = ['love', 'my', 'dalmation'] thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) print testEntry, "classified as: ", classifyNB(thisDoc, p0v, p1v, pAb) testEntry = ['stupid', 'garbage'] thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) print testEntry, "classified as: ", classifyNB(thisDoc, p0v, p1v, pAb)def textParse(bigString): import re listOfTockens = re.split(r'\W*', bigString) return [tok.lower() for tok in listOfTockens if len(tok) > 2]def spamTest(): docList = [] classList = [] fullText = [] for i in range(1, 26): wordList = textParse(open('email/spam/%d.txt' % i).read()) docList.append(wordList) # wordlist整体作为一个元素加入到doclist fullText.extend(wordList) # wordList的元素依次加入到doclist classList.append(1) wordList = textParse(open('email/ham/%d.txt' % i).read()) docList.append(wordList) # wordlist整体作为一个元素加入到doclist fullText.extend(wordList) # wordList的元素依次加入到doclist classList.append(0) vocabList = createVocabList(docList) trainingSet = range(50) testSet = [] for i in range(10): randIndex = int(random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) del(trainingSet[randIndex]) trainMat = [] trainClass = [] for docIndex in trainingSet: trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) trainClass.append(classList[docIndex]) p0v, p1v, pSpam = trainNB0(array(trainMat), array(classList)) errorCount = 0 for docIndex in testSet: wordVector = setOfWords2Vec(vocabList, docList[docIndex]) if classifyNB(array(wordVector), p0v, p1v, pSpam) != classList[docIndex]: errorCount += 1 print('error doc = ', docList[docIndex]) # print('the error rate is:', float(errorCount / len(testSet))) print('the error rate is:', float(errorCount) / len(testSet)) 这里写代码片
转载地址:https://blog.csdn.net/LJH0600301217/article/details/47664017 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
初次前来,多多关照!
[***.217.46.12]2024年04月25日 05时36分07秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
FTP文件管理项目(本地云)项目日报(一)
2019-04-27
FTP文件管理项目(本地云)项目日报(二)
2019-04-27
FTP文件管理项目(本地云)项目日报(三)
2019-04-27
FTP文件管理项目(本地云)项目日报(四)
2019-04-27
【C++】勉强能看的线程池详解
2019-04-27
FTP文件管理项目(本地云)项目日报(七)
2019-04-27
FTP文件管理项目(本地云)项目日报(八)
2019-04-27
【Linux】血泪教训 -- 动态链接库配置方法
2019-04-27
FTP文件管理项目(本地云)项目日报(九)
2019-04-27
以练代学设计模式 -- FTP文件管理项目
2019-04-27
FTP文件管理项目(本地云)项目日报(十)
2019-04-27
学以致用设计模式 之 “组合模式”
2019-04-27
我用过的设计模式(7)--享元模式
2019-04-27
MySQL数据库从入门到实战应用(学习笔记一)
2019-04-27
MySQL数据库从入门到实战应用(学习笔记二)
2019-04-27
种树:二叉树、二叉搜索树、AVL树、红黑树、哈夫曼树、B树、树与森林
2019-04-27
【C++】攻克哈希表(unordered_map)
2019-04-27
转:【答学员问】- 该如何根据岗位学习相关技能
2019-04-27
转:【答学员问】有什么经验教训,是你在面试很多次之后才知道的?
2019-04-27
消息队列:解耦、异步、削峰,现有MQ对比以及新手入门该如何选择MQ?
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308109372 位访客
访问时间: 2024-04-26 19:02:31
访问IP: 18.218.70.93
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版