2模型评估
发布日期:2021-06-29 18:40:57
浏览次数:2
分类:技术文章
本文共 4416 字,大约阅读时间需要 14 分钟。
文章目录
- 机器学习中,对模型的评估同样至关重要。
- 模型评估分离线评估和在线评估两个阶段。
- 针对分类、排序、回归、序列预测等不同类型,评估指标的选择也有所不同。
- 每种评估指标的精确定义、
- 有针对性地选择合适的评估指标、
- 根据评估指标的反馈进行模型调整,
- 这些都是机器学习在模型评估阶段的关键问题
1 评估指标的局限性
场景描述
- 诸多的评估指标中,大部分指标只能片面地反映模型的一部分性能。如果不能合理地运用评估指标,不仅不能发现模型本身的河题,而且会得出错误的结论。
1 准确率的局限性
- 奢侈品广告主们希望把广告定向投放给奢侈品用户。
- Hulu拿到了部分奢侈品用户的数据,并以此为训练集和测试集,
- 训练和测试奢侈品用户的分类模型
- 模型准确率超95%,但实际广告投放中,
- 该模型还是把大部分广告投给非奢侈品用户,什么原因
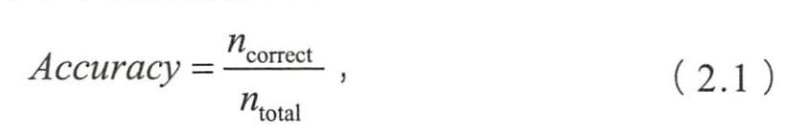
- 正确分类的样本个数
- 总样本的个数。
- 当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。
- 当不同类别的样本比例不均衡时
- 占比大的类别往往成为影响准确率的最主要因素。
- 奢侈品用户只占Hulu全体用户的小部分,虽然模型的整体分类准确率高,但不代表对奢侈品用户的分类准确率也高
- 线上投放过程中,只对模型判定的“奢侈品用户”投放,因此,对“奢侈品用户”判定的准确率不够高的问题就被放大。
- 用更为有效的平均准确率(每个类别下的样本准确率的算术平均)作为模型评估的指标。
- 即使评估指标选对了,仍会存在模型过拟合或欠拟合、
- 测试集和训练集划分不合理、
- 线下评估与线上测试的样本分布存在差异,
- 但评估指标的选择是最容易被发现,
- 也最可能影响评估结果
2 精确率与召回率
- 提供视频的模糊搜索功能,搜索排序模型返回的Top5的精确率非常高,
- 实际中,用户还是经常找不到想要的视频
- 特别是冷门的剧集,哪环节出问题?
- 分类正确的正样本个数占分类器判定为正样本的样本
- 分类正确的正样本个数占真正的正样本
- 排序问题中用TopN返回结果的Precision和Recall来衡量排序模型
- 模型返回的TopN就是模型判定的正样本
- 然后计算
- 前N个位置上的Precision(@N
- 前N个位置上的Recall@N
- 为提Precision,分类器需尽量在“更有把握”时才把样本预测为正,但会因为过于保守而漏掉很多“没有把握”的正样本,导致Recall降低
- 模型返回的Precision5的结果非常好,也就是说排序模型Top5的返回值的质量很高。
- 实际中,为了找冷门视频,往往会找排在靠后位置的结果
- 甚至翻页去查找目标视频
- 用户经常找不到想要的视频,这说明模型没把相关的视频都找出来给用户
- 显然,问题出在召回率
- 如果相关结果有100个,即使Precision5达到100%, Recall5也仅5%。
- 模型评估时,应同时关注 Precision和 Recall?
- 是否应该选取不同的TopN的结果观察?
- 是否应选取更高阶的评估指标来更全面地反映模型在Precision值和 Recall值两方面的表现?
- 为了综合评估一个排序模型好坏,不仅要看模型在不同TopN下的 Precision(@N和 Recall@N,
- 最好绘制出模型的P-R曲线。
- 对排序模型来说,P-R曲线上的一个点代表,
- 在某一阈值下,模型将大于该阈值的结果判定为正样本,
- 小于该國值的结果判定为负样本,
- 此时返回结果对应的召回率和精确率
- P-R曲线是通过将阈值从高到低移动而生成的
- 原点附近代表当阈值最大时模型的精确率和召回率。
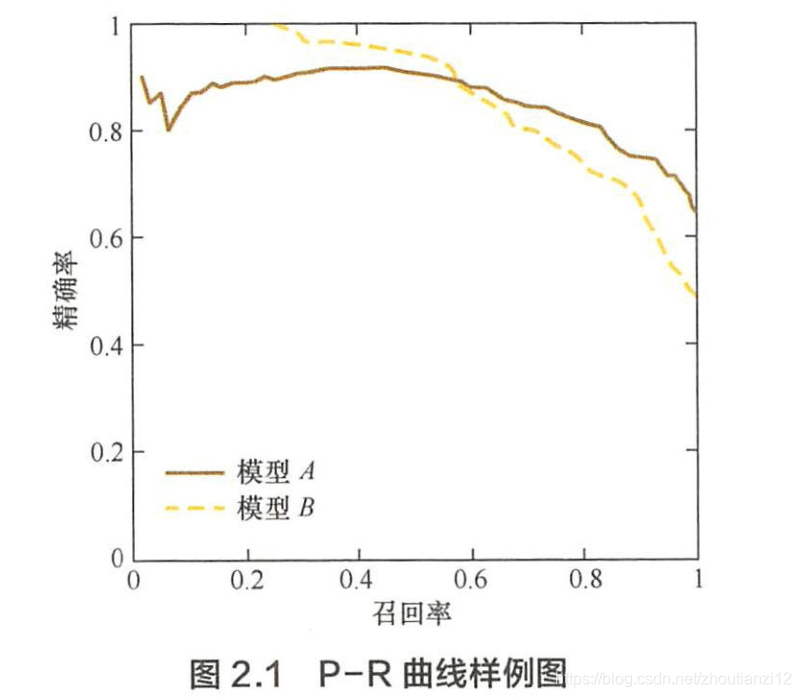
- 召回率接近0时,A精确率0.9,B精确率1,
- 说明B得分前几位的样本全部是真正的正样本
- 而A得分最高的几个样本也存在预测错误
- 随着召回率増加,精确率整体下降
- 当召回率为1时,模型A的精确率反而超过了B。
- 说明,只用某个点对应的精确率和召回率是不能全面地衡量模型的性能,只有通过P-R曲线的整体表现,才能够对模型进行全面的评估。
- F1 score和ROC曲线也能综合地反映一个排序模型的性能。
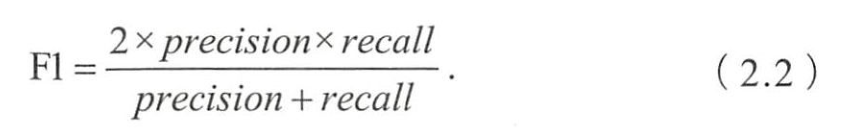
3 平方根误差的“意外”。
- 预测每部美剧的流量趋勢对于广告投放、用户增长都重要。
- 我们希望构建一个回归模型来预测某部美剧的流量趋势,但无论采用哪种回归模型,得到的RMSE指标都非常高。
- 事实是,模型在95%的时间区间内的预测误差都小于1%,
- 取得了相当不错的预测结果。
- RMSE居高不下的最可能原因?
- RMSE衡量回归模型好坏,但按题目叙述,RMSE这个指标失效。
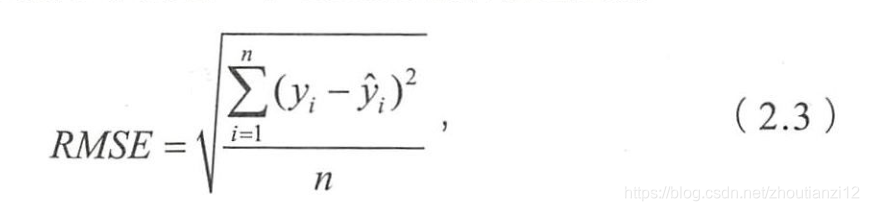
- RMSE能很好反映回归模型预测值与真实值的 偏离程度。但在实际问题中,如果存在个别偏离程度非常大的离群点 ( Outlier)时,即使离群点数量非常少,也会让RMSE指标变得很差。
- 模型在95%的时间区间内的预测误差都小于1%
- 大部分时间区间内,模型的预测效果都优秀。
- 然而,RMSE却一直很差,这很可能是由于在其他的5%时间区间内 存在非常严重的离群点。
- 事实上,在流量预估这个问题中,噪声点确实是很容易产生的,比如流量特别小的美剧、刚上映的美剧或者刚获奖的美剧,甚至一些相关社交媒体突发事件带来的流量,都可能会造 成离群点。
- 如果认定这些离群点是“噪声”的话,就需在数据预处理的阶段把这些噪声过滤
- 如果不认为这些离群点是“噪声点”的话,就需进一步提高模型的预测能力,将离群点产生的机制建模进去
- 找一个更合适的指标来评估该模型
- 存在比RMSE的鲁棒性更好的指标,平均绝对百分比误差( Mean Absolute Percent Error,MAPE),

- 相比RMSE,MAPE相当把每个点的误差归ー化,降低了个别离群点带来的绝对误差的影响
2 ROC曲线
场景描述
- 二值分类器的指标很多,
- precision、 recall、 F1 score、P-R曲线
- 只能反映模型在某一方面性能
- ROC则很多优点,常作为评估二值分类器最重要的指标
1 什么是ROC曲线?
- Receiver Operating Characteristic Curve
- “受试者工作特征曲线”。
- 假阳性率( False Positive Rate,FPR)
- 纵坐标真阳性率( True Positive Rate,TPR)

- P是真实正样本
- N是真实负样本
- TP是P个正样本中被分类器预测为正样本的个数
- FP是N个负样本中被分类器预测为正样本的个数
- 10位疑似
- 3位确实(P=3),
- 7位不是(N=7)。
- 诊断出3位,2位确实是(P=2)
- 那么真阳性率2/3
- 对7位非癌症来说,一位被误诊
- 那么假阳性率1/7
- 对分类器来说
- 就对应ROC曲线上的一个点(1/7,2/3)
如何绘制ROC曲线?
- ROC不断移动分类器的“截断点”来生成曲线上的一组关键点
- 二值分类输出一般都是预测样本为正的概率
- 阈值为0.9,那只有第一个样本会被预测为正例,其他全部都负
- “截断点”就是区分正负预测结果的阈值
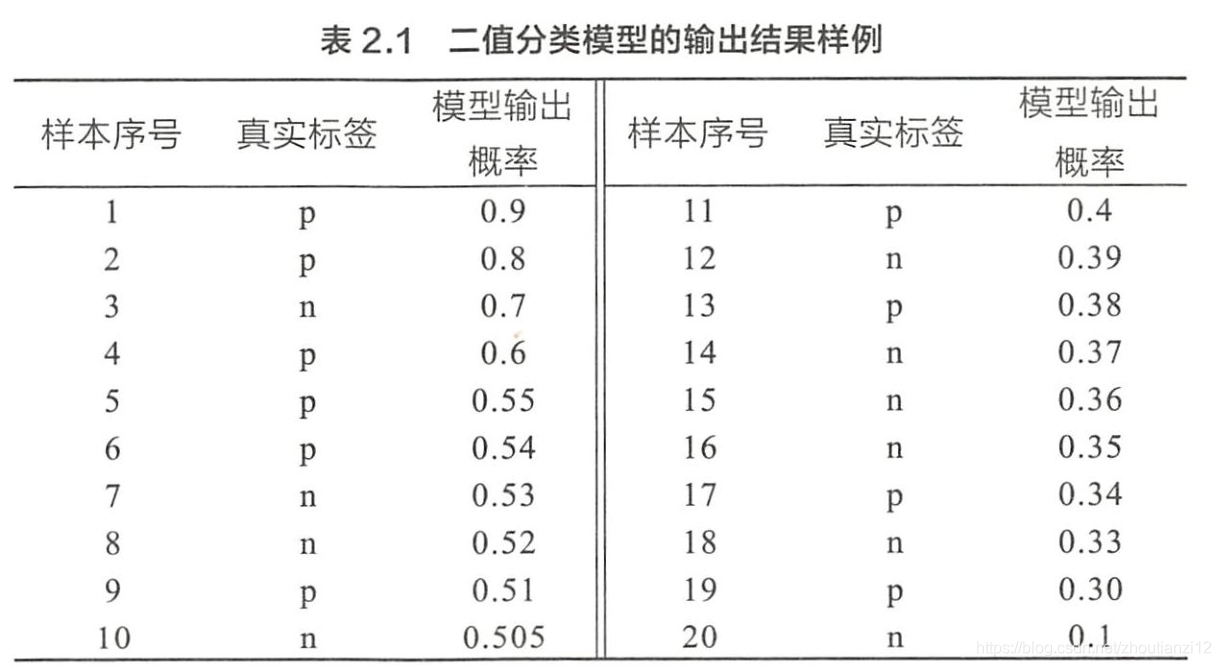
- 通过动态调整截断点,从最高得分开始(正无穷开始,对应零点),逐渐调整到最低得分
- 每一个截断点都对应一个FPR和TPR,在ROC上绘制出每个截断点对应的位置再连接所有点就得到ROC
- 为正无穷,全部样本预测为负,
- 第一个坐标(0,0)
- 截断点0.9时
- TP=1
- 所有正例数量为P=10,故TPR=1/10
- FPR=0,对应(0,0.1)
- 依次调整截断点,直到画出全部关键点,
- 再连接关键点即得到最终的ROC
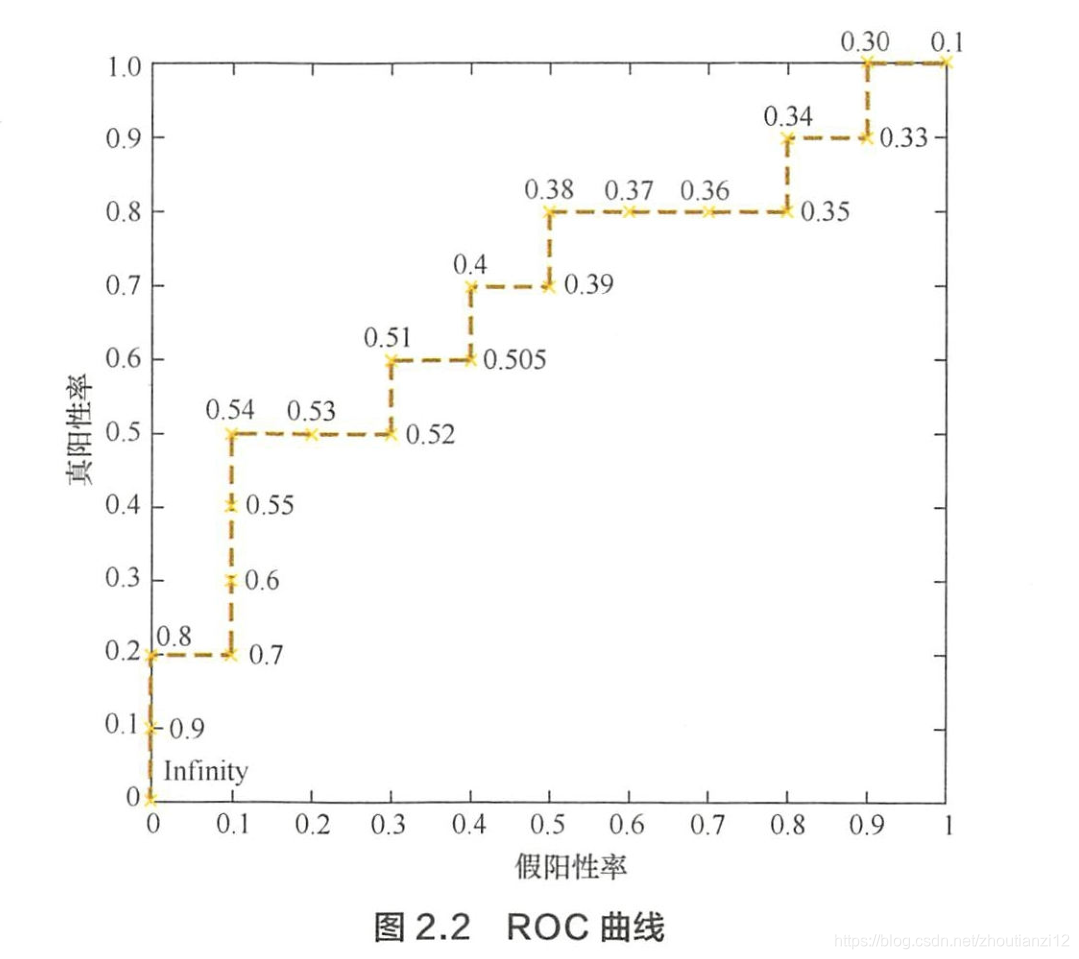
- 正样本为P,负样本为N
- 横轴刻度间隔设为1/N,纵轴刻度间隔设1/P
- 再根据模型输出的预测概率对样本排序(从高到低)
- 依次遍历样本,同时从零点绘制ROC,
- 每遇一个正样本就沿纵轴方向绘制一个刻度间隔的曲线,
- 每遇到一个负样本就沿横轴方向绘制一个刻度间隔的曲线,
- 直到遍历完所有样本
- 曲线最终停在(1,1)
3 如何计算AUC?
- 量化反映基于ROC曲线衡量出的模型性能
- 只需要沿着ROC横轴做积分就可
- ROC一般都处y=x上方(如果不,只要把模型预测的概率反转成1-P就可以得到一个更好的分类器),所以AUC一般在0.5~1之间。
- 越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
4 ROC相比P-R有什么特点?
- 同样被经常用来评估分类和排序模型的P-R曲线。
- 相比P-R,ROC有一特点
- 当正负样本的分布变化时
- ROC形状基本不变
- 而P-R一般剧烈变化
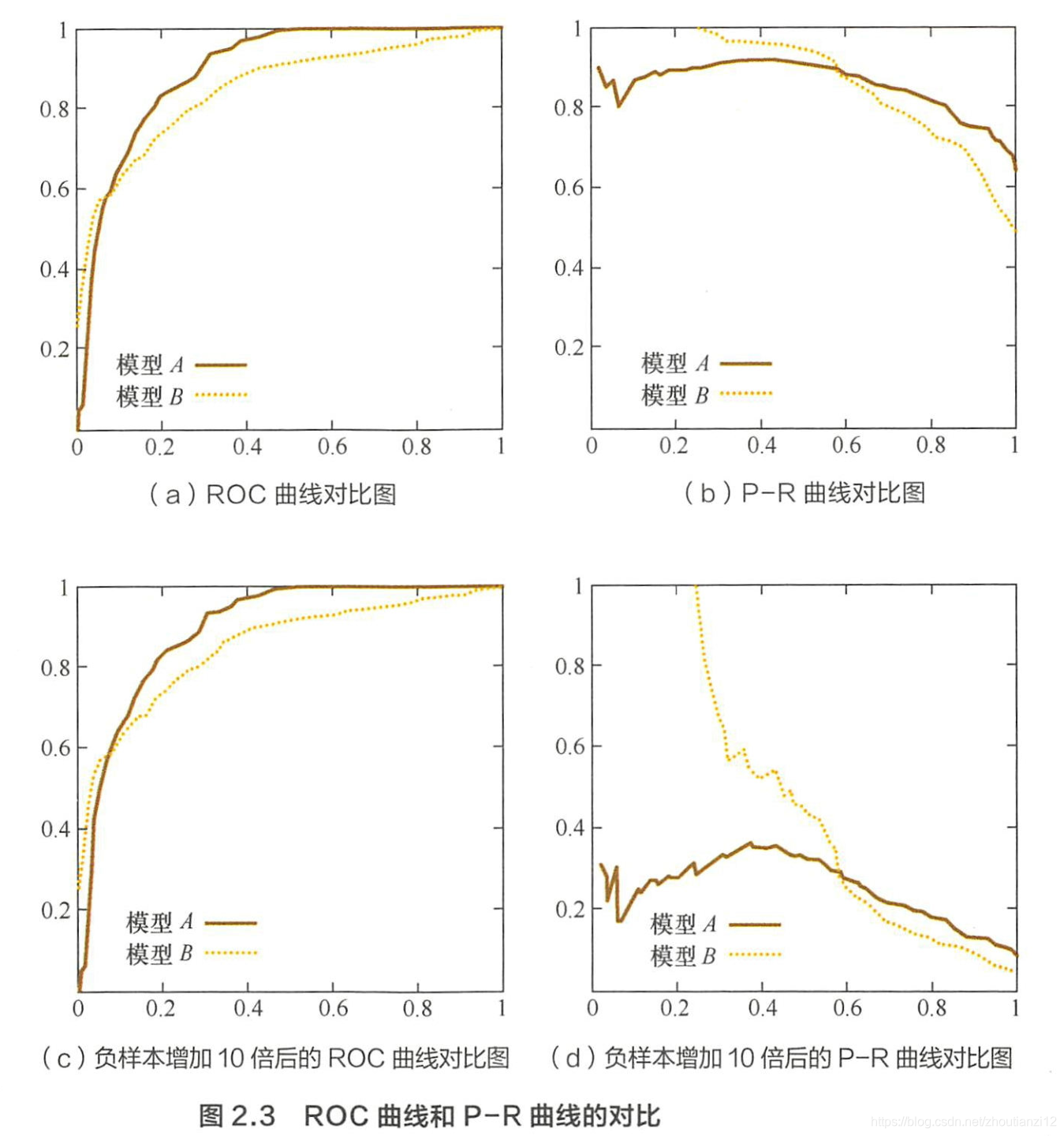
- 这让ROC能尽量降低不同测试集带来的干扰,更客观衡量模型本身性能
- 计算广告常涉及转化率模型,正样本是负样本的1/1000甚至1/10000。
- 若选不同测试集,P-R变化非常大,而ROC能更稳定反映模型本身好坏
- 所以,ROC的适用场景更多,被广泛用于排序、推荐、广告
- 如果希望更多地看到模型在特定数据集上的表现,P-R则能够更直观地反映其性能。
7 过拟合与欠拟合
1 过拟合和欠拟合具体是指什?
- 过拟合指模型对于训练数据拟合过当,
- 模型在训练集上的表现很好,
- 但在测试集和新数据上的表现差
- 模型在训练集上的表现很好,
- 欠拟合: 模型在训练和预测时表现都不好
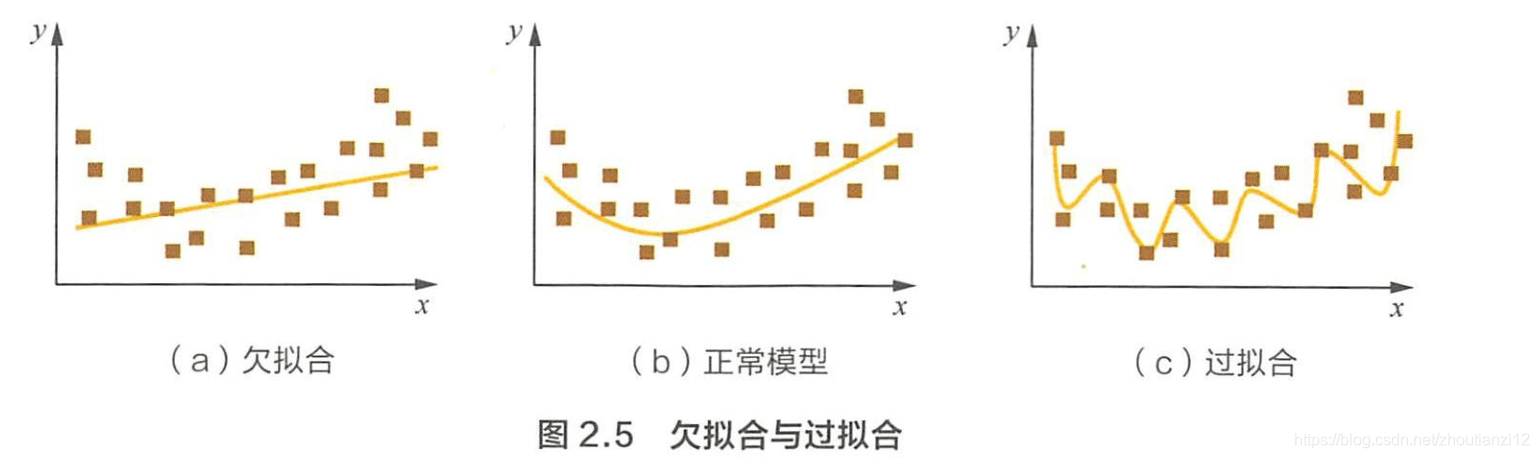
- 模型过于复杂,把噪声数据的特征也学习到模型中,导致泛化能力下降,在后期应用过程中很容易输出错误的预测
2 几种降低过拟合和欠拟合?
降低“过拟合”风险的方法
- (1)获更多训练数据
- 用更多训练数据是解决过拟合最有效手段
- 因为更多的样本能让模型学习到更多更有效的特征,減小噪声影响
- 直接增加实验数据困难,可通过一定规则扩充训练数据
- 图像分类,可通过图像平移、旋转、缩放扩充数据
- 使用生成式对抗网络来合成大量的新训练数据
- (2)降低模型复杂度。
- 数据较少时,模型过于复杂是产生过拟合主要因素
- 适当降低模型复杂度可避免模型拟合过多采样噪声
- 神经网络中減少网络层数、神经元个数
- 决策树模型中降低树深度、剪枝
- (3)正则化方法。
- 给模型的参数加上一定的正则约束
- 如将权值大小加入到损失函数
- L2正则化
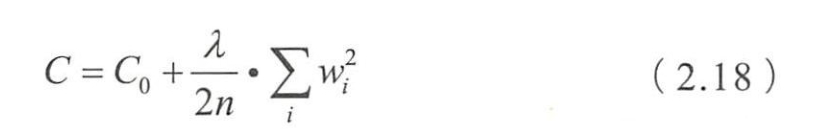
- 优化原来的目标函数 C 0 C_0 C0的同时,也能避免权值过大带来的过拟合
- (4)集成学习方法。
- 集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,如 Bagging
降低“欠拟合”风险的方法
- (1)添加新特征
- 当特征不足或现有特征与样本标签的相关性不强时,易欠拟合
- 挖掘“上下文特征”“ID类特征”“组合特征”等新特征,往往能取得更好效果
- 深度学习中有很多模型可帮助完成特征工程
- 如因子分解机、梯度提升決策树
- Deep-crossing都可成为丰富特征的方法
- (2)增加模型复杂度
- 简单模型学习能力较差,通过增加模型复杂度可使模型有更强拟合能力
- 线性模型中添加高次项
- 在神经网络模型中増加网络层数或神经元个数
- (3)减小正则化系数。
- 正则化是来防止过拟合的,出现欠拟合时,则要针对性减小正则化系数
转载地址:https://cyj666.blog.csdn.net/article/details/104963658 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月20日 19时35分21秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
计算机网络(一)—— 概述(5):计算机网络的性能指标
2019-04-30
计算机网络(一)—— 概述(6):计算机网络体系结构
2019-04-30
计算机网络(一)—— 概述(7):总结
2019-04-30
计算机网络(三)—— 数据链路层(1):数据链路层概述
2019-04-30
计算机网络(三)—— 数据链路层(5):点对点协议PPP
2019-04-30
MySQL(一)-约束
2019-04-30
Mysql(三)-视图
2019-04-30
SpringBoot(一)-入门介绍
2019-04-30
SpringBoot(二)-配置文件与自动配置
2019-04-30
Linux上安装Docker并使用(含错误解决)
2019-04-30
SpringBoot-整合Dubbo+Zookeeper
2019-04-30
利用HTML,CSS,JS实现登录页面的制作
2019-04-30
利用HTML,CSS,JS进行注册页面的制作
2019-04-30
前端学习详细知识点讲解-HTML(第一天)
2019-04-30
前端学习详细知识点讲解-HTML(第二天)
2019-04-30
前端学习详细知识点讲解-CSS(第一天)
2019-04-30
前端学习详细知识点讲解-CSS(第二天)
2019-04-30
前端学习详细知识点讲解-CSS(第三天)
2019-04-30
前端学习详细知识点讲解-CSS(第四天)
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310433085 位访客
访问时间: 2024-05-03 22:13:45
访问IP: 18.191.13.255
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版