联通手机信令大数据的处理分析与可视化
发布日期:2021-06-29 19:49:27
浏览次数:2
分类:技术文章
本文共 4273 字,大约阅读时间需要 14 分钟。
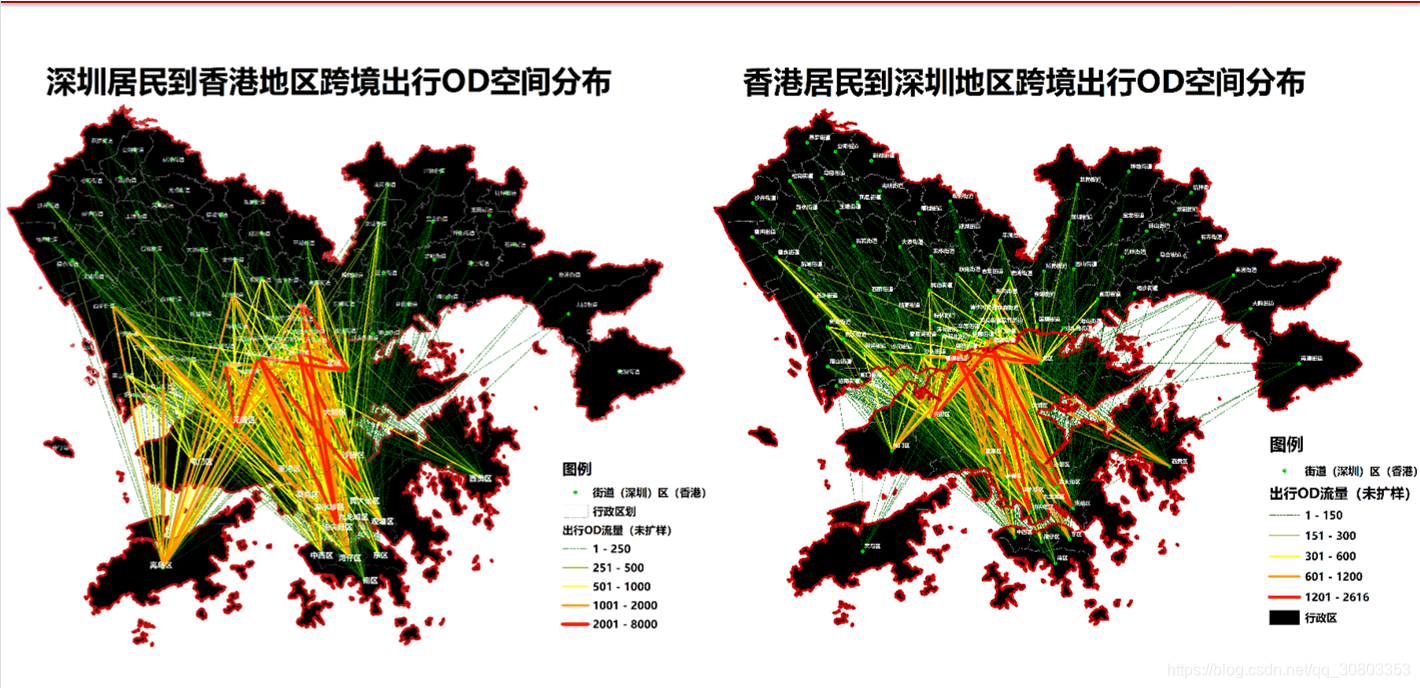
我有联通的2020年扩样后的具体迁徙人数数据,包括所有城市
如果需要的话请到我其他文章找到我的qq 数据处理代码:
import pandas as pdimport osfrom utils.read_write import eachFile, pdReadCsv'''每个社区到达商圈的平均人口数, #3代表节假日#2代表周末 #1代表工作日 * START_GRID_ID 起始网格编号 string * START_CITY 起始城市 string * END_GRID_ID 到达网格编号 string * END_CITY 到达城市 string * date 日期 string * START_TYPE 起始人口类型 string 01-到访 02-居住 03-工作 05职住重合 * END_TYPE 到达人口类型 string 01-到访 02-居住 03-工作 * POP 人数 int * times 次数'''# def test():# filepath = os.path.join(root+'000054_0_weekend.txt')# data = pd.read_csv(filepath, sep='|', usecols=[0, 2, 4, 7], error_bad_lines=False, engine='python')# column = ['START_GRID_ID', 'END_GRID_ID', 'date', 'pop']# data.columns = column# # data = data[data['date'].isin([20191013])]# workFromCom = pd.merge(data, community, left_on='START_GRID_ID', right_on='YGA_Grid_1', how='right')# workFromComToMall = pd.merge(workFromCom, mall, left_on='END_GRID_ID', right_on='YGA_Grid_1', how='right')# workGroup = workFromComToMall.groupby(['SQCODE', 'mall_name']).agg({'pop': sum})# csv = workGroup['pop'].apply(lambda x: int(x / 5))# csv.to_csv(filepath + 'holidayFromCommunityToMall.csv', mode='a')def read_file(dirpath): filepath = os.path.join(dirpath) print(dirpath) data = pd.read_csv(filepath, sep='|', usecols=[0, 2, 4, 7], error_bad_lines=False, engine='python') column = ['START_GRID_ID', 'END_GRID_ID', 'date', 'pop'] data.columns = column weekend = data[data['date'] == 20191013] workFromCom = pd.merge(weekend, community, left_on='START_GRID_ID', right_on='YGA_Grid_1', how='right') workFromComToMall = pd.merge(workFromCom, mall, left_on='END_GRID_ID', right_on='YGA_Grid_1', how='right') workGroup = workFromComToMall.groupby([ 'SQCODE', 'mall_name']).agg({ 'pop': sum}) csv = workGroup['pop'].apply(lambda x: int(x / 5)) csv.to_csv(save + 'weekendFromCommunityToMall.csv', mode='a',header=False,index=True) holiday = data[data['date'] < 20191008] workFromCom = pd.merge(holiday, community, left_on='START_GRID_ID', right_on='YGA_Grid_1', how='right') workFromComToMall = pd.merge(workFromCom, mall, left_on='END_GRID_ID', right_on='YGA_Grid_1', how='right') workGroup = workFromComToMall.groupby([ 'SQCODE', 'mall_name']).agg({ 'pop': sum}) csv = workGroup['pop'].apply(lambda x: int(x / 5)) csv.to_csv(save + 'holidayFromCommunityToMall.csv', mode='a',header=False,index=True) work = data[(data['date'] > 20191007) & (data['date'] != 20191013)] workFromCom = pd.merge(work, community, left_on='START_GRID_ID', right_on='YGA_Grid_1', how='right') workFromComToMall = pd.merge(workFromCom, mall, left_on='END_GRID_ID', right_on='YGA_Grid_1', how='right') workGroup = workFromComToMall.groupby([ 'SQCODE', 'mall_name']).agg({ 'pop': sum}) csv = workGroup['pop'].apply(lambda x: int(x / 5)) csv.to_csv(save + 'workFromCommunityToMall.csv', mode='a',header=False,index=True)def groupby(): src = 'D:\学习文件\项目文件\规土委\data\od\save\save\\' data = pd.read_csv(src+'workFromCommunityToMall.csv',sep=',',names=['SQCODE','mall_name','pop']) group = data.groupby(['SQCODE','mall_name']).agg({ 'pop':sum}) csv = group['pop'].apply(lambda x: int(x / 6)) csv.to_csv(src+'workCommunityToMall'+'.csv',header=True) data = pd.read_csv(src+'holidayFromCommunityToMall.csv',sep=',',names=['SQCODE','mall_name','pop']) group = data.groupby(['SQCODE','mall_name']).agg({ 'pop':sum}) csv = group['pop'].apply(lambda x: int(x / 7)) csv.to_csv(src+'holidayCommunityToMall'+'.csv',header=True) data = pd.read_csv(src+'weekendFromCommunityToMall.csv',sep=',',names=['SQCODE','mall_name','pop']) group = data.groupby(['SQCODE','mall_name']).agg({ 'pop':sum}) group.to_csv(src+'weekendCommunityToMall'+'.csv',header=True)if __name__ == '__main__': groupby() root = 'D:\学习文件\项目文件\规土委\data\od\other\\' save = 'D:\学习文件\项目文件\规土委\data\od\comTomall\\' grid = 'D:\学习文件\项目文件\规土委\data\od\YGA\\' community_file = 'com_grid.txt' community = pdReadCsv(grid + community_file, sep=',') mall = pd.read_csv(grid + 'mall_grid.txt', sep=',', dtype=str) # test() for dir in eachFile(root): # read_file(root + '000054_0_unholiday') read_file(root + dir) 转载地址:https://data-mining.blog.csdn.net/article/details/111612516 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
不错!
[***.144.177.141]2024年04月13日 15时46分17秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
查询linux系统中空闲内存/内存使用状态查看/剩余内存查看
2019-04-30
Linux下屏保设置
2019-04-30
使用开源软件OpenIPMI来监控服务器温度
2019-04-30
使用IPMI管理Linux服务器
2019-04-30
使用ipmi进行服务器管理
2019-04-30
基于Linux的嵌入式系统全程喂狗策略
2019-04-30
linux嵌入式系统开发之看门狗----应用篇。
2019-04-30
看门狗用户空间程序(可用来检测服务器死机)
2019-04-30
scp 使用方法
2019-04-30
Linux man命令的使用方法
2019-04-30
shell高效获取分割字符串的方法?
2019-04-30
Linux Shell编程变量赋值和引用
2019-04-30
计算机专业推荐书籍
2019-04-30
程序员的成长之路
2019-04-30
linux下CPU温度监测
2019-04-30
java数组查找元素索引,无需排序
2019-04-30
QT 多线程程序设计
2019-04-30
Qt 4.8.4 & Qt Creator 2.6.1 安装和配置(Windows)
2019-04-30
Qt使用自定义类型信号槽注册问题
2019-04-30
Android获取拓展外置SD卡(可插拔)路径及读写外置SD卡的方法
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310411665 位访客
访问时间: 2024-05-03 20:19:53
访问IP: 18.220.16.184
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版