本文共 3890 字,大约阅读时间需要 12 分钟。
目录
感谢NVIDIA,感谢GPUS!!!
参赛队名:学深会
描述一下数据集收集和标注情况:
数据收集方法的优缺点分析
L同学
主要数据获取方法为:网络爬取。主要通过Google搜索引擎,书写网页爬取程序,从而获得交通路面的相关照片,然后下载到本地。该方法的优点为:1.速度快,短时间内可以获取大量数据,节约团队消耗人力物力实地考察,上街拍摄;2.照片对于分析对象的拍摄角度很全面,各个角度的照片都有,可以较好地训练模型。该方法的缺点是:1.网络上的照片质量参差不齐,偶尔有不是目标的照片也被爬取出来了,需要后期人工挑选出来。2.Google上的照片以国外的路面状况为主,训练时对于交通路标的识别存在影响。
T同学
基本上有以下的方法
- Kaggle上找数据集
- 清华,国内外大神的数据集
- 官方给的数据集(最好的方法)
- 问队友..
- 问官方..
- Google自己爬,自己标(最不好的方法)
- 自己拍照片,没试过
- 其他:淘宝上标框,1个框3分到6分,目前淘宝上没有找到直接买数据集的商家
其他需要注意的事项
- 数据集可能很大,需要准备大的移动硬盘,我16G的U盘硬是不能把12G的数据集放进去
- 百度网盘还是比较香的,有Linux的版本,要好好用哈
- 国外数据集往往在Amazon上面,就是翻墙有时候也打不开是最无语的
数据标注的方法的优缺点分析:
L同学
团队采用目标检测的方法,使用在(离)线的VGG工具标准数据集。该方法的优点为:1.节约数据标准的时间,同时也能较好地完成识别目标对象的工作;2.数据标注的工具同时支持在线和离线,且十分轻便,在无网络的情况下也能开展数据标注工作。该数据标注方法的缺点为:1.获取区域目标比较费时;2.往往需要重复计算区域的特征值,数据不共享,存在大量冗余计算。
T同学
- 在实际数据标注的过程中,我们尝试了各种数据标注平台,最终决定用VGG图像注释 器进行了在线标注。
- 数据标注的最大问题就是文件项目的导入导出问题,因为数据量过大,无法一次性标注所有数据,但是每次标注完成导出的json文件都是包括了所有的图片,无论有没有标注,为后期的训练模型带来了隐患。
- 认识到问题之后,我们学会了手动拼接 有效的json文件,在最终与有经验的学长交流之后,我们学会了标注项目的管理,避免下次标数据时再低效率手动拼接json文件。
Json文件转换kitti文件的方法和踩坑实录
对于json文件转换kitti文件,需要注意的是做好json文件的格式规范,如果每一个json文件都有不同的数据结构,那么使用脚本进行转换就有很大的困难。在转换中,需要用到三个元素,第一是label,也就是ROI里的东西是什么;而后面两个是具体的坐标。
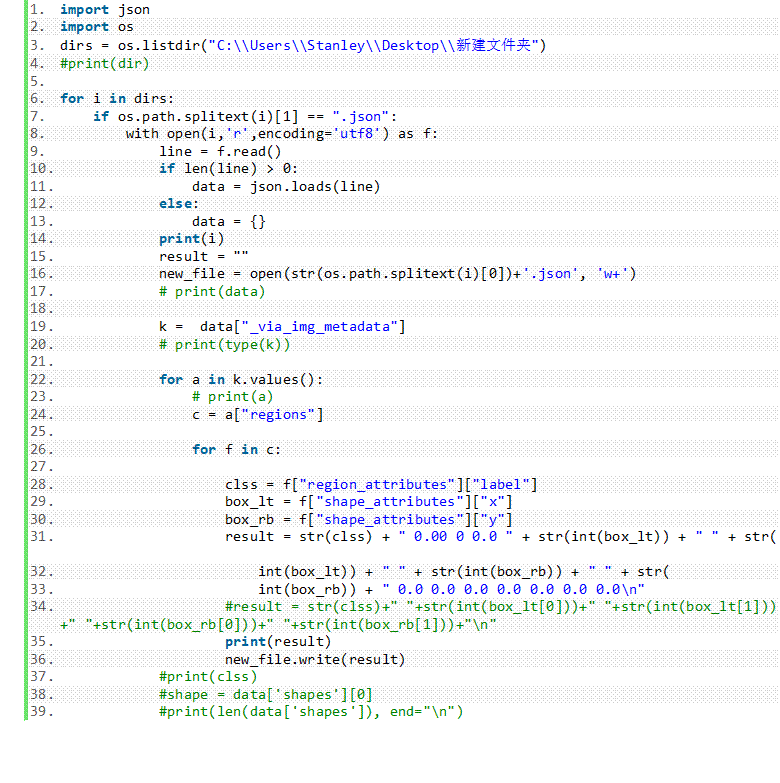
img
描述一下您们是如何进行模型训练(比如训练的时间,训练的结果,利用NVIDIA Transfer Learning Toolkit对模型进行剪枝等优化过程等)
部署网络踩坑总结
,T同学和Y同学
把基本网络搭建好了,请参考官方TLT 文档
https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/
T同学
官方教程踩坑实录
下载数据
image-20201217173627850
Linux百度网盘下载还是挺快的
准备数据
image-20201217173658745
解压官方数据集,ipython notebook设计真人性化
下载预训练模型
image-20201217173921101
导入模型配置文件
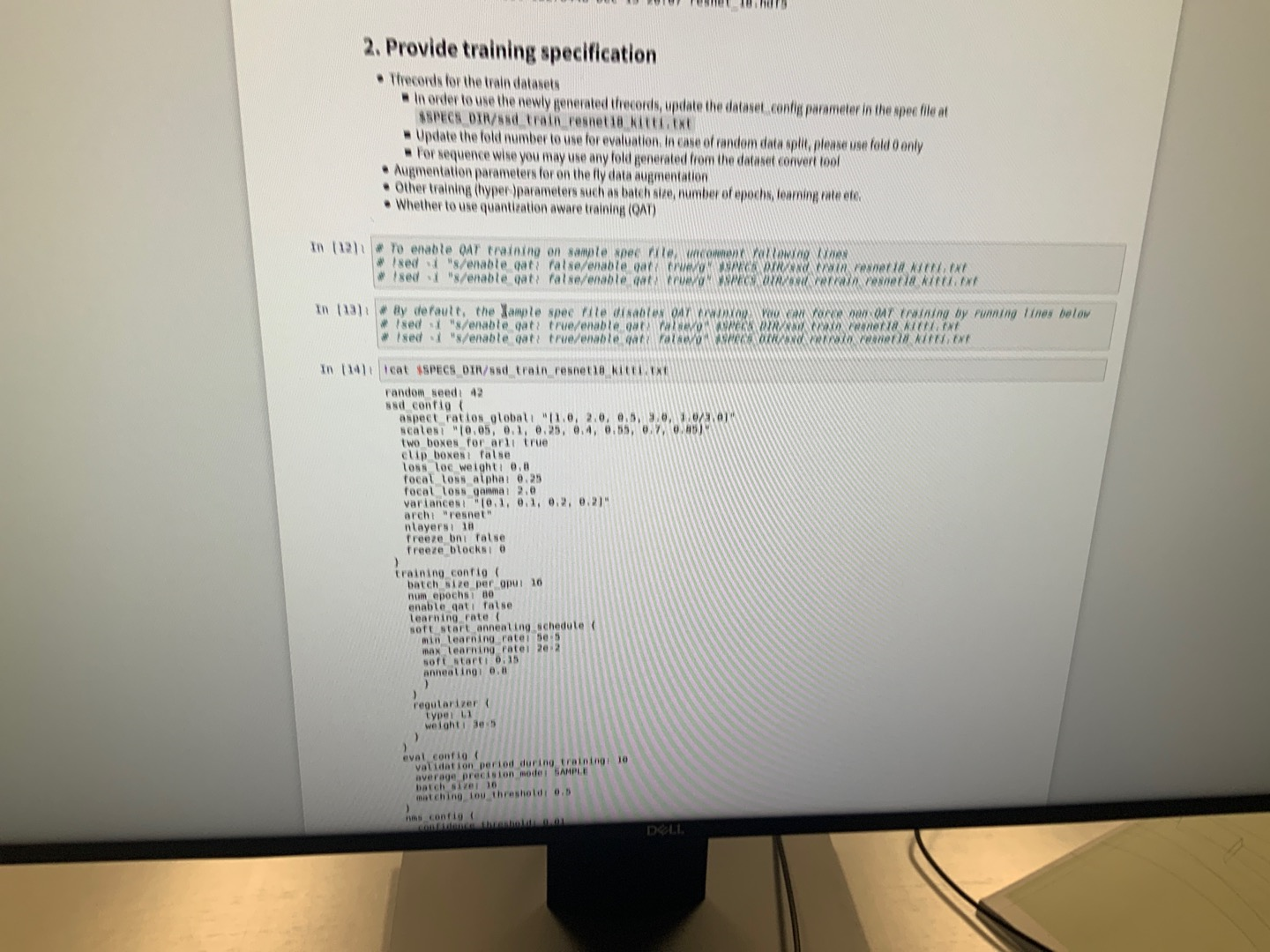
image-20201217174057218
运行TLT文件
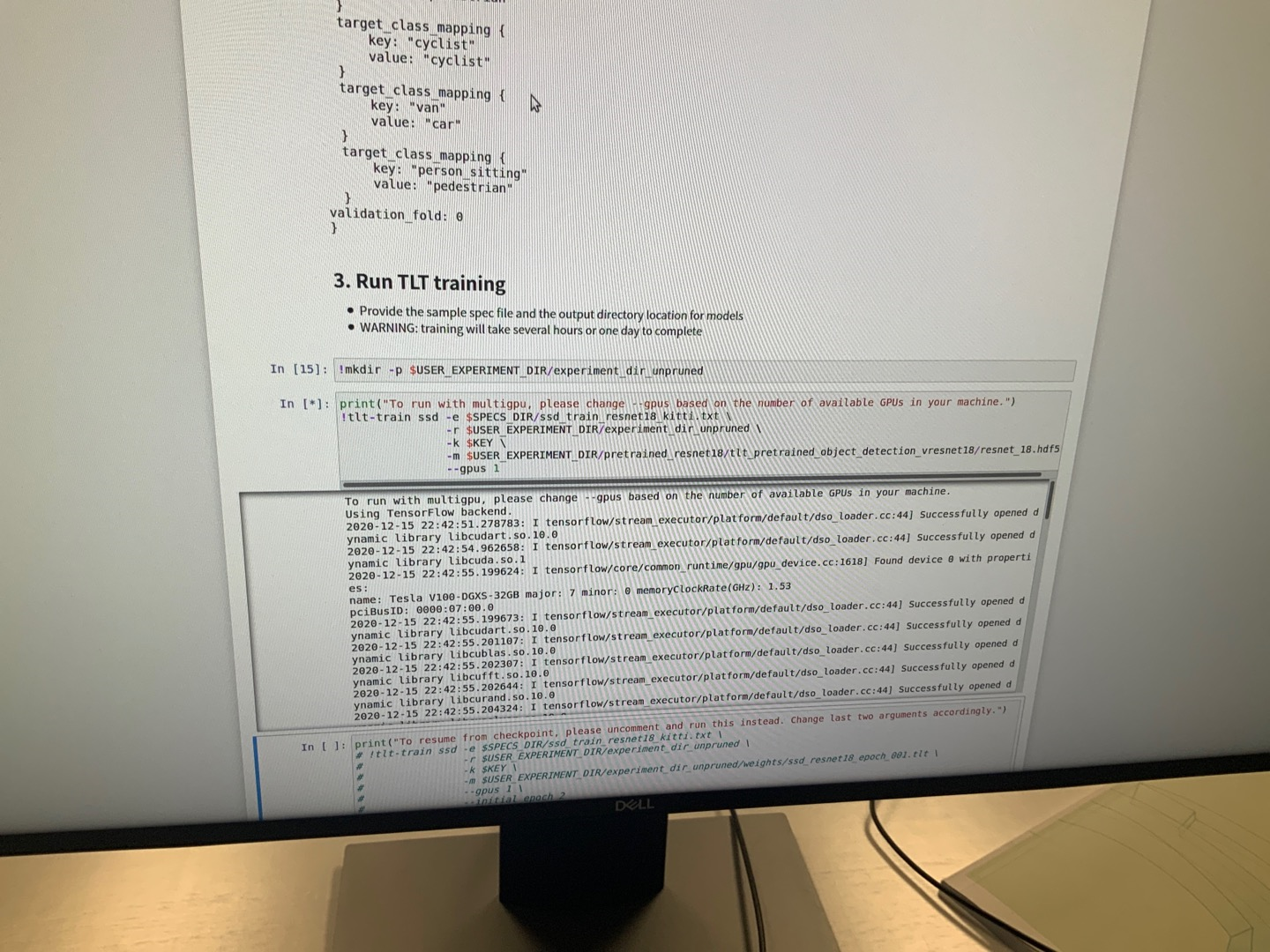
image-20201217174008396
训练模型,这个过程需要至少需要一个小时,如果训练80个epoch的话
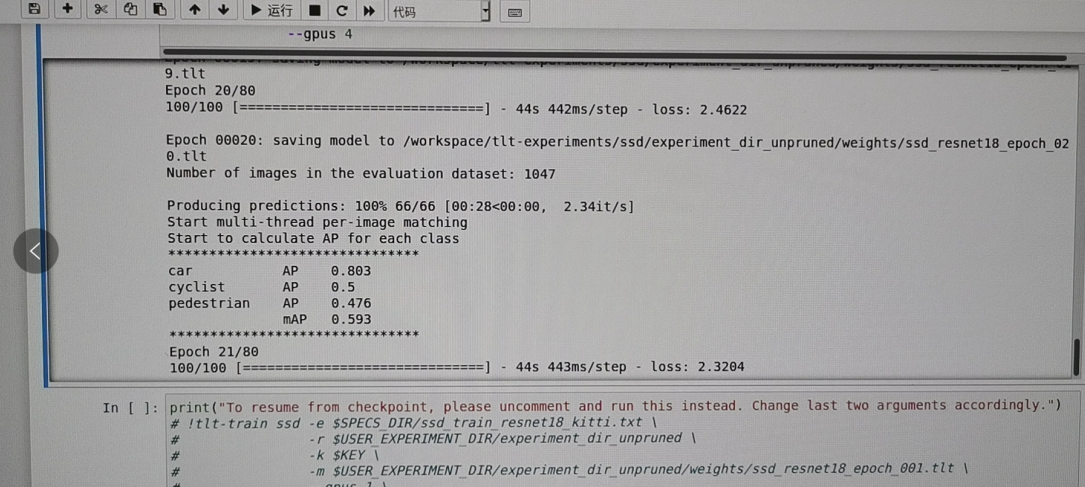
image-20201217174124293
反正最后最重要的是这个mAP,我也不太清楚这个具体的意思,反正这个数字越靠近1越好,反正看着跑的感觉还是挺爽的。
模型重训练
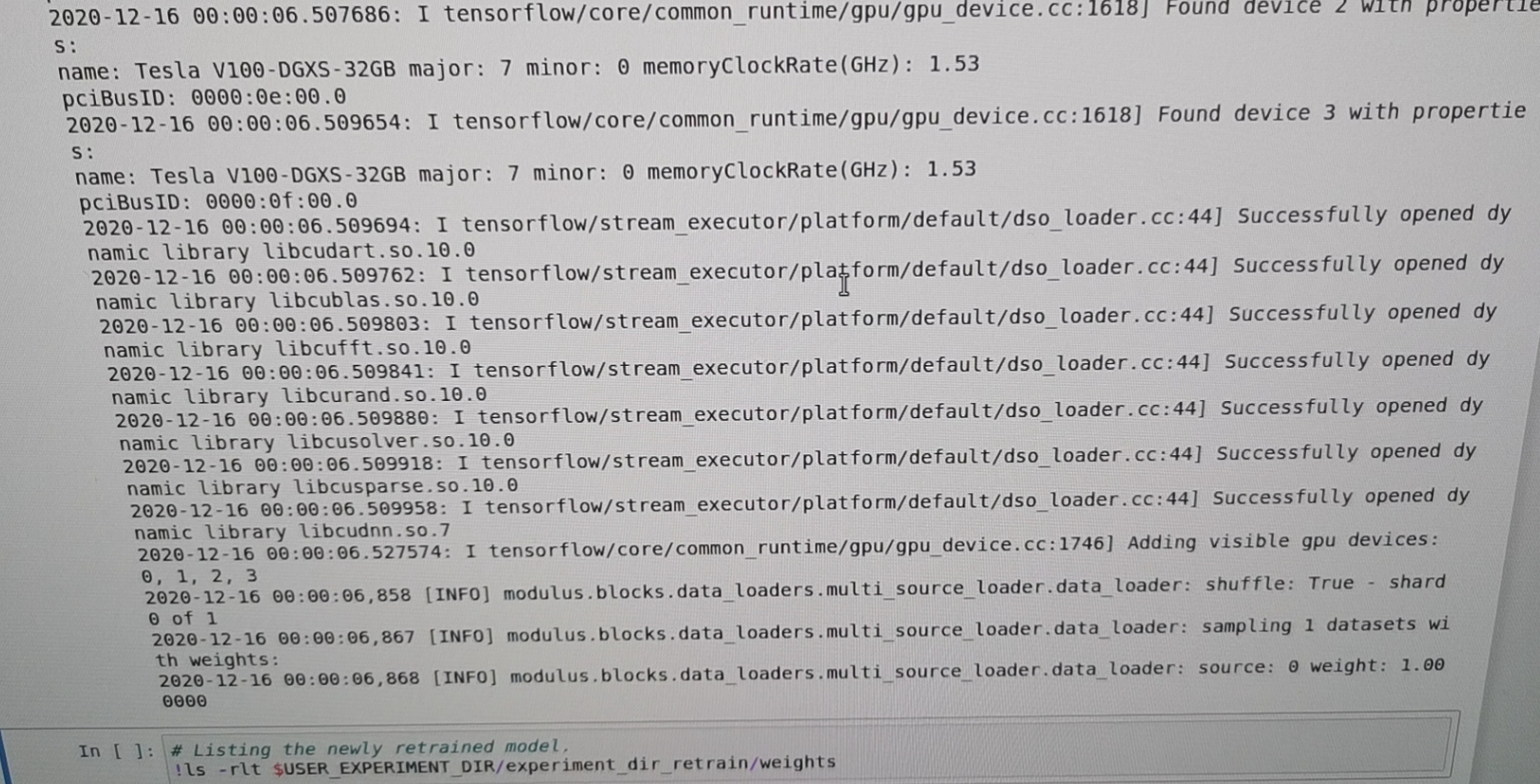
image-20201217174405212
我的理解是NVIDIA有一个工具,在TLT里面,他自动给你加了一些“盐”一样的东西,让你的网络generalization的程度更好,比如说prune或者drop out.(在这里就是仅仅做了剪枝)
剪枝结束的时候的样子是这样的
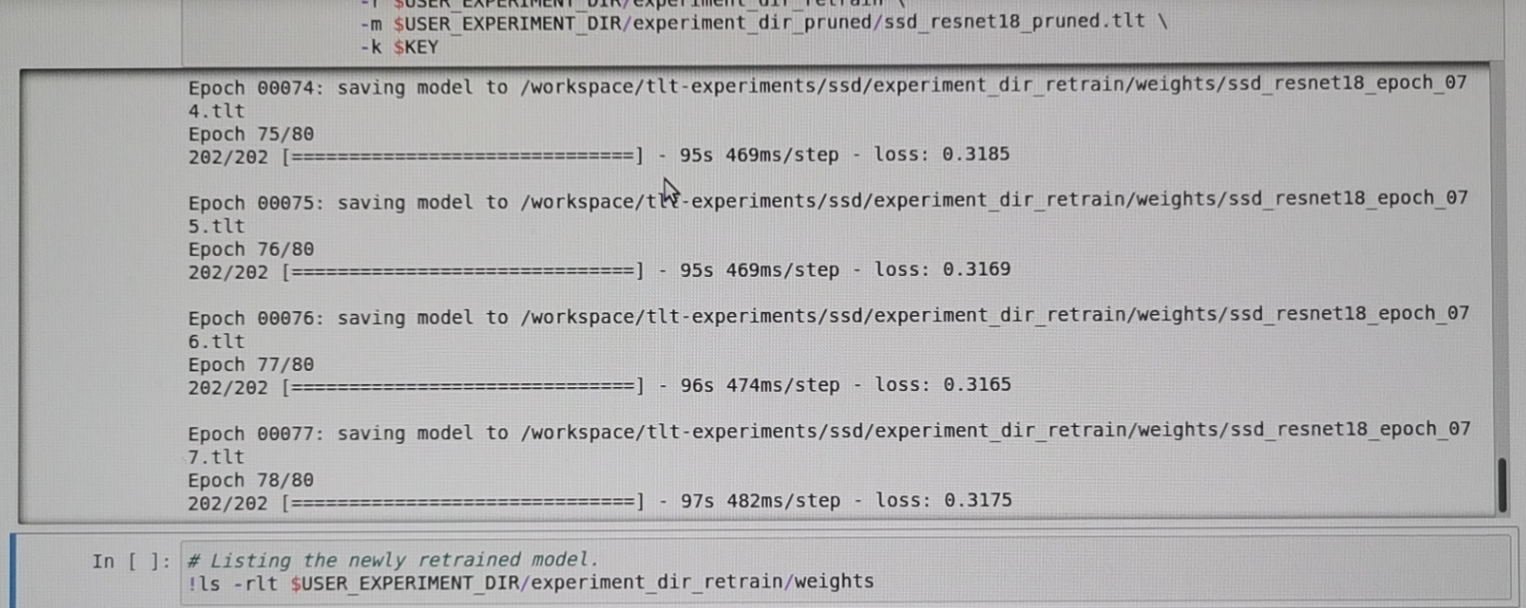
image-20201217174554266
推理的图片
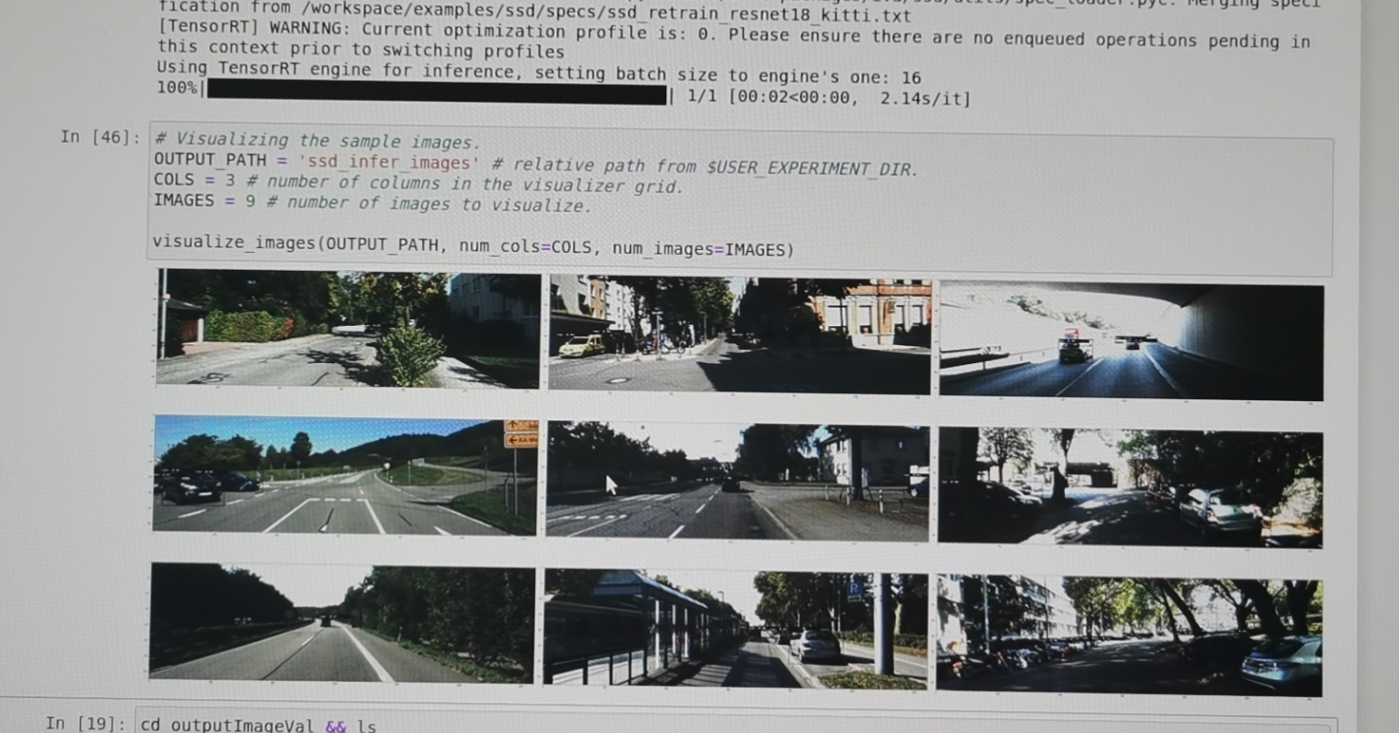
image-20201217174627046
部署到nano上面
先说一下步骤
- 把本机的模型导出来,.etlt文件(PS, .tlt文件是权重向量,每一个epoch都会有一个的,.etlt文件的e应该是engine的意思,是模型文件)
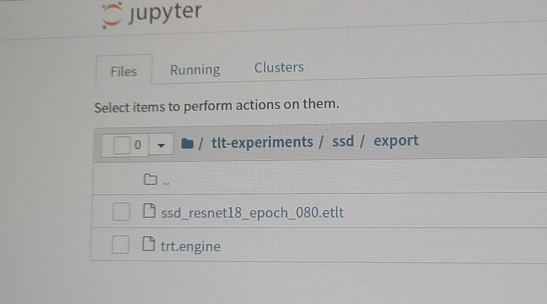
image-20201217174855775
- 之后把.etlt文件的路径和你的NGC账号放到nano部署的Jupiter notebook上面
image-20201217174910822
- nano加载的状态,看下面有busy
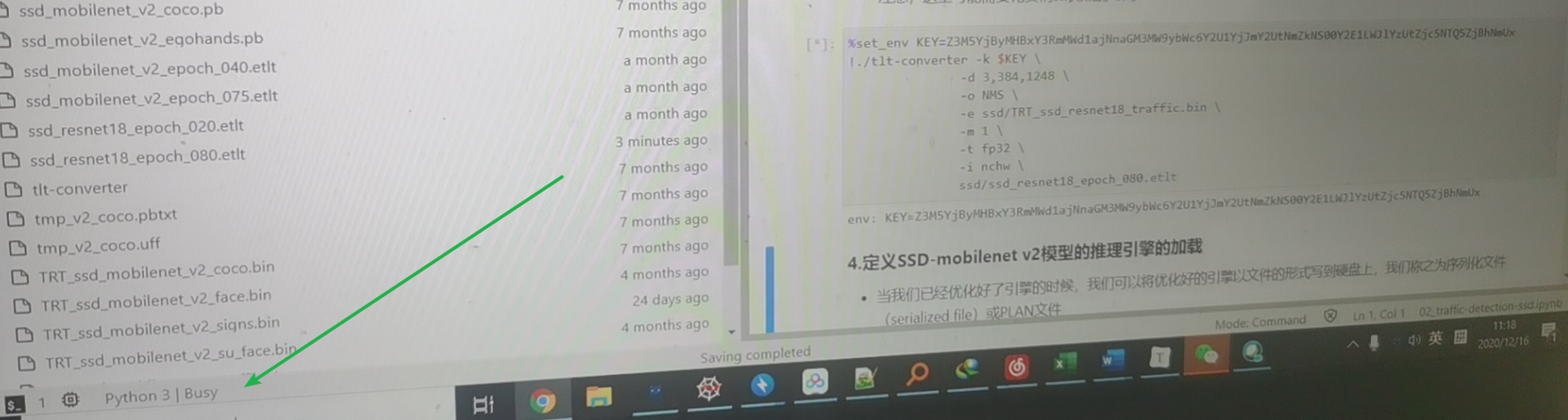
image-20201217175013752
- 注意标签对应,这是future work了
- 这里的键值对应该是和标注的一样,但是改完了有报错,我也不明白了
image-20201217175142587
描述一下您们是如何在Jetson NANO进行部署和推理
硬件平台概况

image-20201206212154429
micro USB直连

image-20201206212139178
-
有了这个USB线,以后就可以直接通过我电脑的网卡来桥接使得jetson上网,通过jupter notebook,此外,直接通过我的电脑控制nano,非常的方便,再也不需要通过外接键盘,鼠标,显示器,网卡,ifconfig读取ip地址,之后通过谷歌浏览器输入ip地址的端口:8888进去jupter notebook来实现了呢
-
我们现在直接连接山,注意这个USB线需要有数据传输的功能,不能是普通的充电线,这样我们就能直接通过在我的电脑上输入http://192.168.55.1:8888 来控制我的nano了,真的很神奇,虽然我也不知道背后的原理,但是,通过浏览器控制本机实际的硬件,这样的体验还是很棒的!
-
by the way, 那个如果这个小绿灯没有亮,先检查电源哈,这是nano电源检测灯

image-20201206212123835
软件平台(供参考)
- NVIDIA Jetpack 4.4
- Ubuntu 18.04 L4T
- Python 3.6.9
- TensorRT 7.1
- CUDA 10.2
- Tensorflow 1.15
- NVIDIA Transfer Learning Toolkit 2.0
- Numpy 1.16.1
- Opencv 4.1.1
总结(团队收获)
收获
S同学
- 经历了这次nvidia的比赛,对神经网络和nvidia的平台有了更深的了解
T同学
- 知道怎么标数据和标数据的项目管理事项
- 知道如何进行环境的配置
- 学习了一些Linux命令的使用方式
- 体会到了深度学习网络的实现流程
Y同学
-
知道常用的CNN模型以及它们的区别
-
了解模型的构建流程
-
了解模型的一些优化方法
-
熟悉了常用的数据增强技巧
-
学会了在jetson nano上部署模型、检测模型识别效果
L同学
- 了解了深度学习的整个流程
- 关于数据集的使用和标注
- 关于配置环境是怎么一回事
T同学
-
知道怎么标注数据
-
自动化标注不靠谱
-
-
认识到了四种计算机视觉问题
-
图像分类
-
目标检测
-
语义分割
-
实例分割
-
-
知道怎么链接notebook
-
知道怎么调整模型的一些参数
-
知道了先跑docker,再再docker里面跑程序的逻辑
-
知道大概模型走多少个epoch能够有足够好的精度
-
知道了jupter notebook 和 jupter lab的区别是啥
-
知道了label要在一开始的时候要很强的同一在一起(强共识,一开始一定要和组里面强共识)
-
Linux怎么看系统配置
-
100张V100训练80epoch,7000张,resnet18大概需要1小时
-
Prune 之后Retrain需要的时间更多步骤200步
-
上了好多NVIDIA的课程,学会了jupiter notebook和lab怎么用,这为我以后在kaggle上跑很多模型,训练集提供了可能
-
知道了怎么用teamviewer来控制计算机
-
知道了怎么用teamviewer传文件
-
练习了linux终端的命令
-
cd
-
cat
-
mkdir
-
ls
-
-
知道了linux终端操作的意义的价值,因为当你的训练集里面有10000个文件,甚至只是10000个txt文件的时候,你要是通过图形界面打开,你的file应用程序就会崩
-
备了以后在nano上面搭建AIOT的能力
-
知道NVIDIA DIGITS本质上就是把输入放到了那个配置文件的格式里面
遗憾
S同学
- 遗憾的是这次比赛选在了学期的最后一周,太多的事情导致没法用太多时间和精力来参加比赛
T同学
- 未能参与nano部署部分
Y同学
- 缺少对模型底层的认识,需要详细学习
L同学
- 未能学习框架的具体细节实现
T同学
- 对于如何定制化模型缺乏认识
希望
S同学
- 以后能更多的使用nvidia的平台,来进行自己的研究
T同学
- 能自己完整的复现项目的整个流程
Y同学
- 官方推出训练以及nano上部署分类、识别、分割、跟踪的案例教程
L同学
- 在后期学习,更全面地了解各种模型框架,灵活运用
T同学
- 能知道怎么写model config文件
转载地址:https://dequn.blog.csdn.net/article/details/111322515 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
