MySQL索引优化总结以及索引失效常见问题
发布日期:2021-06-29 21:37:50
浏览次数:4
分类:技术文章
本文共 5785 字,大约阅读时间需要 19 分钟。
| 文章内容来自于: |
文章目录
1、 前言
索引的建立是为了让我们更加高效快速的查询出结果,但是,要想充分利用起索引,我们首先要解决的最大问题就是要避免索引失效,下面我们来一起通过实例来探讨造成索引失效的情况,并通过优化SQL查询语句来避免索引失效。
➤ 准备工作:- 创建数据表SQL
CREATE TABLE `staffs` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄', `pos` varchar(20) NOT NULL COMMENT '职位', `add_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 插入基础数据
INSERT INTO `test`.`staffs` (`id`, `name`, `age`, `pos`, `add_time`) VALUES ('1', '王洪玉', '25', '总经理', '2018-05-22 09:45:44');INSERT INTO `test`.`staffs` (`id`, `name`, `age`, `pos`, `add_time`) VALUES ('2', 'July', '25', '实习生', '2018-05-22 09:45:58');INSERT INTO `test`.`staffs` (`id`, `name`, `age`, `pos`, `add_time`) VALUES ('3', '李四', '20', '实习生', '2018-05-22 09:46:04');INSERT INTO `test`.`staffs` (`id`, `name`, `age`, `pos`, `add_time`) VALUES ('4', '王玉', '21', '老板娘', '2018-05-22 09:46:17');INSERT INTO `test`.`staffs` (`id`, `name`, `age`, `pos`, `add_time`) VALUES ('5', '王五', '22', '服务员', '2018-05-22 09:46:26');INSERT INTO `test`.`staffs` (`id`, `name`, `age`, `pos`, `add_time`) VALUES ('6', '赵六', '80', '传菜生', '2018-05-22 09:46:45'); - 创建索引
ALTER TABLE staffs ADD INDEX idx_staffs_nameAgePos (NAME, age, pos);或者按照下列规则建立create [UNIQUE/fulltext全文索引] index idx_staffs_nameAgePos on staffs(NAME(length),age(length),pos(length))组合索引(存在磁盘上) ,[UNIQUE] 表示唯一索引,不允许该列重复
上面在staffs表上创建了复合索引idx_staffs_nameAgePos ,顺序为name-age-pos。
- 查询索引
SHOW INDEX FROM staffs

USING INDEX,USING WHERE,USING INDEX CONDITION。 using index 和using where只要使用了索引我们基本都能经常看到,而using index condition则是在mysql5.6后新加的新特性,详细了解Explain参数见文末,当然想要详细了解的可参见 using index:使用覆盖索引的时候就会出现using where:在查找使用索引的情况下,需要回表去查询所需的数据using index condition:查找使用了索引,但是需要回表查询数据using index & using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据 Explain分析中重要的几个字段为,type、possible_keys(理论上要用到的索引)、key(实际上用到的索引)、key_len(使用到的索引长度)、ref、Extra,其余几个字段见文末。
2. 索引失效优化案例
2.1 全值匹配我最爱
全值匹配指的是我要查询的语句的字段和顺序恰好和建立的索引的字段和顺序一致,否则索引失效。
☀ 正确的使用方式
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July';

EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25;

EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25 AND pos = '实习生';

EXPLAIN SELECT * FROM staffs WHERE age = 25 AND pos = '实习生';

EXPLAIN SELECT * FROM staffs WHERE pos = '实习生';

2.2 最佳左前缀法则
如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始并且不跳过索引中的列。
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND pos = '实习生';

✈ 总结:由上面的结果我们可以看出,当索引是按照name,age,pos顺序建立的时候,如果查询条件是以name开头,但是没有按顺序,就会导致后面的索引失效。总结一句话就是:中间兄弟不能断!
2.3 不在索引列上做任何操作
这里的任何操作包括计算、函数、(自动or手动)类型转换,会导致索引失效而转向全表扫描
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July';

EXPLAIN SELECT * FROM staffs WHERE left(NAME,4) = 'July';

2.4 存储引擎不能使用索引中的范围条件右边的列
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25 AND pos = '实习生';

EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age > 25 AND pos = '实习生';

2.5 尽量使用覆盖索引
尽量使用索引的查询即索引列和查询列一致,减少select *
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25 AND pos = '实习生';

EXPLAIN SELECT name,age,pos FROM staffs WHERE NAME = 'July' AND age = 25 AND pos = '实习生';

EXPLAIN SELECT name,age,pos FROM staffs WHERE NAME = 'July' AND age > 25 AND pos = '实习生';

2.6 mysql在使用不等于(!=或者<>)的时候无法使用索引导致全表扫描
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July';

EXPLAIN SELECT * FROM staffs WHERE name != 'July';

EXPLAIN SELECT * FROM staffs WHERE name <> 'July';

2.7 is null可以触发索引,is not null无法触发索引
EXPLAIN SELECT * FROM staffs WHERE name is null;

EXPLAIN SELECT * FROM staffs WHERE name is not null;

2.8 like以通配符开头(’%abc…’)索引失效会变成全表扫描
EXPLAIN SELECT * FROM staffs WHERE name like '%July%'

EXPLAIN SELECT * FROM staffs WHERE name like '%July'

EXPLAIN SELECT * FROM staffs WHERE name like 'July%'

EXPLAIN SELECT id,name,age FROM staffs WHERE name like '%July%'

EXPLAIN SELECT id,name,age,add_time FROM staffs WHERE name like '%July%'

2.9 字符串不加单引号索引失效
我们在数据库中添加一条数据,SQL如下:
INSERT INTO `test`.`staffs` (`id`, `name`, `age`, `pos`, `add_time`) VALUES ('7', '200', '0', '假人', '2018-05-22 15:02:55'); 需要注意的是,我们的name字段类型为varchar类型,我们插入了一个名字为“200”的假人。
我们通过下面两个SQL进行查询,都能够得到正确的数据,这是因为mysql自动给200做了类型转换。SELECT * FROM staffs WHERE name = '200';SELECT * FROM staffs WHERE name = 200;

EXPLAIN SELECT * FROM staffs WHERE name = '200';

EXPLAIN SELECT * FROM staffs WHERE name = 200;

2.10 少用or,用它来连接时会索引失效
EXPLAIN SELECT * FROM staffs WHERE name = 'July' or age = 25

3. 总结
3.1 小练
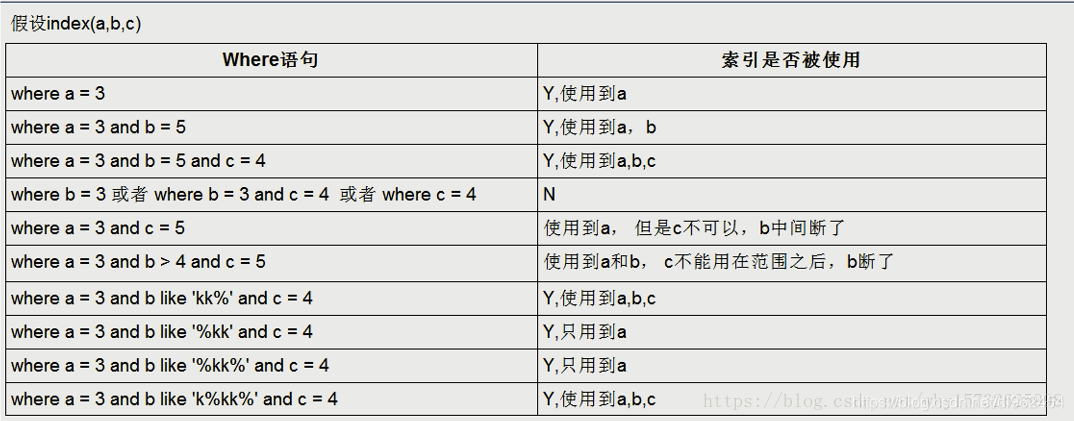
3.2 大练
创建表并创建索引
CREATE TABLE `test03` ( `id` int(11) NOT NULL, `c1` varchar(255) DEFAULT NULL, `c2` varchar(255) DEFAULT NULL, `c3` varchar(255) DEFAULT NULL, `c4` varchar(255) DEFAULT NULL, `c5` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;create index idx_test03_c1234 on test03(c1,c2,c3,c4);
【问题】我们创建了复合索引idx_test03_c1234,根据以下SQL分析索引的使用情况
- mysql查询优化器自动优化

- 范围查找

- order by

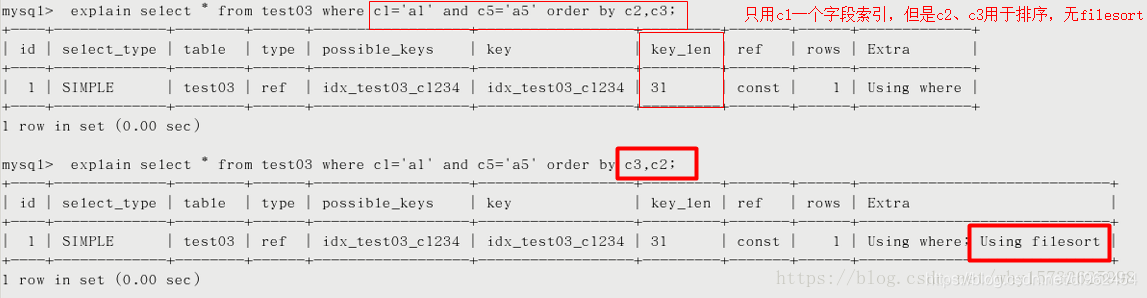

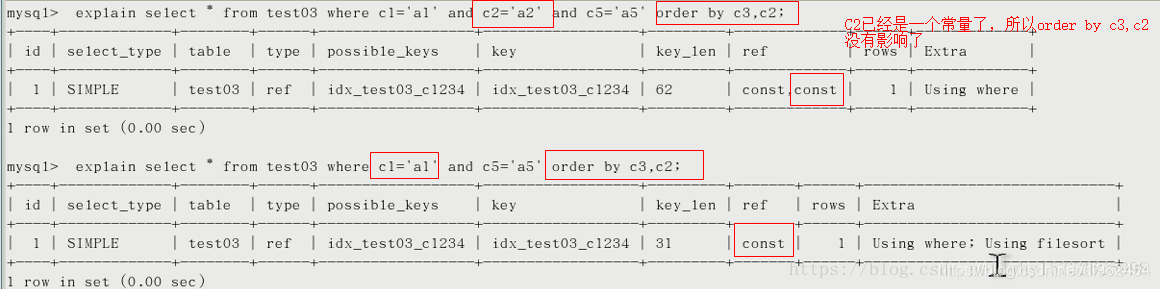
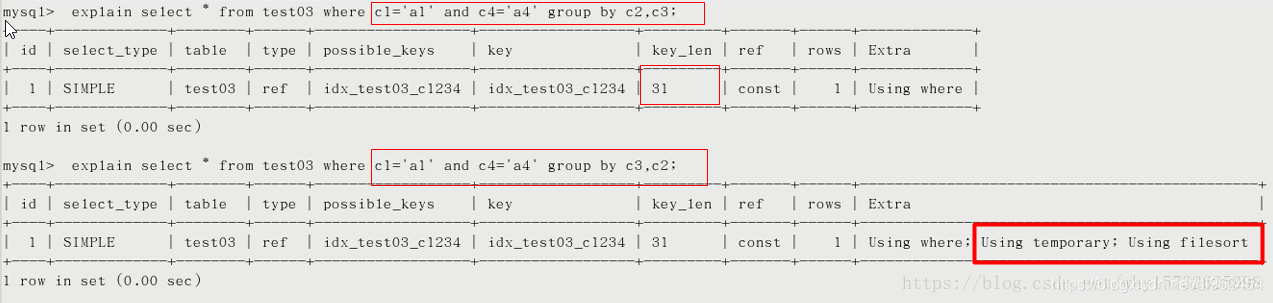
- group by
3.3 一般性建议
- 对于单键索引,尽量选择针对当前query过滤性更好的索引
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好
- 在选择组合索引的时候,尽量选择可以能够包含当前query中的where子句中更多字段的索引
- 尽可能通过分析统计信息和调整query的写法来达到选择合适索引的目的
3.4 优化总结口诀
全值匹配我最爱,最左前缀要遵守; 带头大哥不能死,中间兄弟不能断; 索引列上少计算,范围之后全失效; LIKE百分写最右,覆盖索引不写星; 不能空值还有OR,索引失效要少用; VAR引号不可丢,SQL高级也不难;
文章总结来自:
Explain图解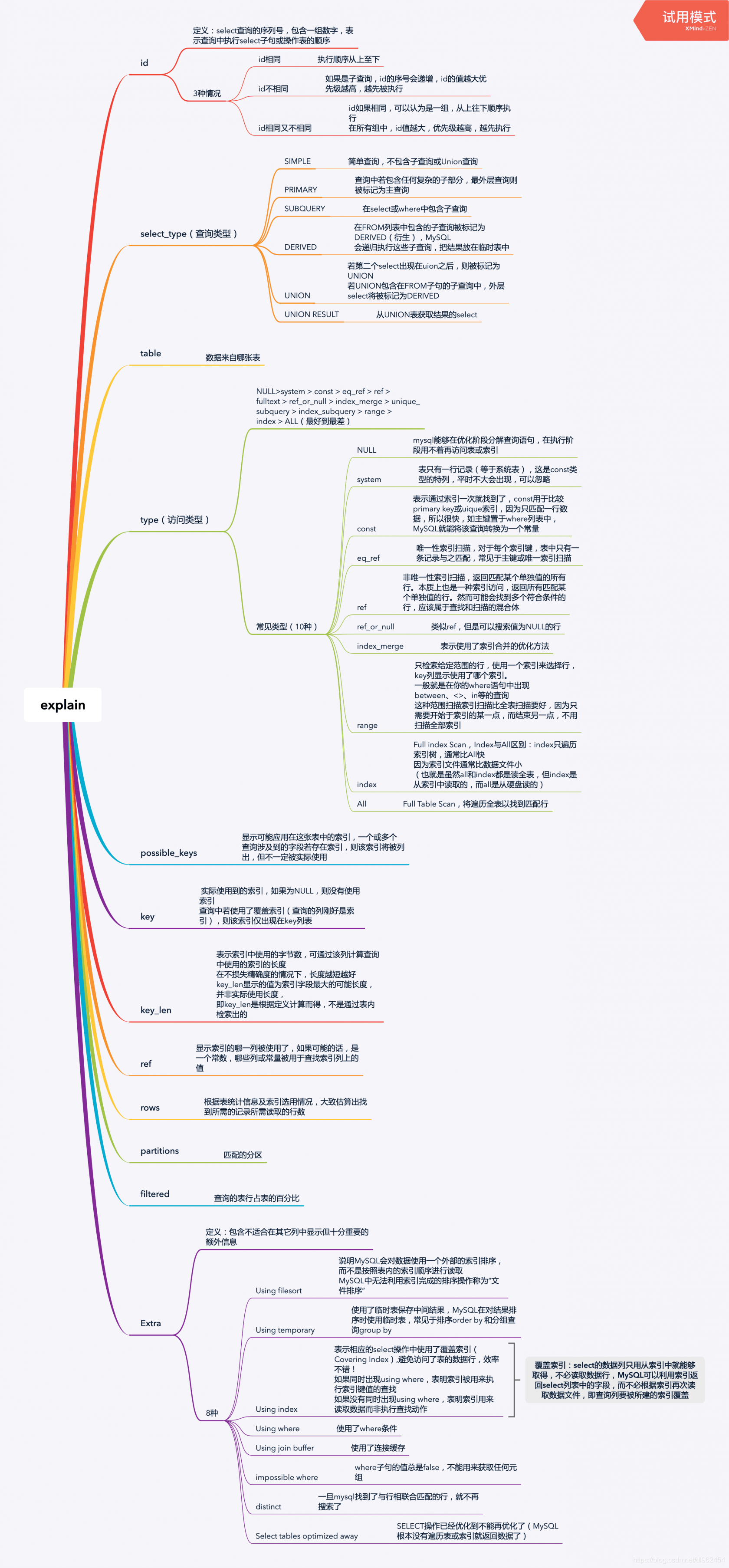
转载地址:https://dh-butterfly.blog.csdn.net/article/details/110938859 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月10日 07时46分26秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
弘辽科技:拼多多店铺星级多久更新一次?如何提升?
2019-04-30
弘辽科技:拼多多店铺星级有用吗?什么是星级?
2019-04-30
弘辽科技:拼多多客单价怎么算?如何提高?
2019-04-30
弘辽科技:拼多多商品详情图怎么做?有什么开店技巧?
2019-04-30
弘辽科技:618收官战报:直播电商强势入场,国潮成消费新趋势
2019-04-30
弘辽科技:宝妈适合做什么?适合宝妈的25个副业
2019-04-30
弘辽科技:老店新开没有自然流量怎么办?
2019-04-30
弘辽科技:拼多多小额收款多久到账?有些什么限制呢?
2019-04-30
弘辽科技:上班同时还能开什么店?上班做副业项目
2019-04-30
弘辽科技:徒有贵族身份,却连一分钱都没有。
2019-04-30
弘辽科技:零食市场内卷化 洽洽的功守道
2019-04-30
弘辽科技:什么行业适合夫妻店?适合夫妻开的店
2019-04-30
弘辽科技:淘宝保险保证金怎么开通?它和消保保证金有什么区别?
2019-04-30
弘辽科技:淘宝开店后怎么经营?步骤有哪些?
2019-04-30
弘辽科技:淘宝开店会有人主动联系吗?怎么才会有人买?
2019-04-30
从零开始搭建免费小程序商城
2019-04-30
如何快速创建个人网站
2019-04-30
立即拥有自己的商城APP,这个功能简直了
2019-04-30
黑科技!无需代码快速搭建网站的平台来了
2019-04-30
如何利用小程序降低获客成本
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310343019 位访客
访问时间: 2024-05-03 14:29:38
访问IP: 3.139.62.103
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版