TCP/IP卷一:72---TCP超时与重传之(设置重传超时RTO(经典方法、标准方法、Linux采用的方法、RTT估计器行为、RTTM对丢包和失序的鲁棒性))
发布日期:2021-06-29 22:33:25
浏览次数:3
分类:技术文章
本文共 8390 字,大约阅读时间需要 27 分钟。
前言
- TCP超时和重传的基础是怎样根据给定连接的RTT设置RTO
- 一些棘手的问题:
- 若TCP先于RTT开始重传,可能会在网络中引人不必要的重复数据
- 反之,若延迟至远大于RTT的间隔发送重传数据,整体网络利用率(及单个连接吞吐量)会随之下降
- 由于RTT的测量较为复杂,根据路由与网络资源的不同,它会随时间而改变。TCP必须跟踪这些变化并适时做出调整来维持好的性能
RTT样本、设置RTO
- TCP在收到数据后会返回确认信息,因此可在该信息中携带一个字节的数据(采用一个特殊序列号)来测量传输该确认信息所需的时间。每个此类的测量结果称为RTT样本
- TCP首先需要根据一段时间内的样本值建立好的估计值。第二步是怎样基于估计值设置RTO。RTO设置得当是保证TCP性能的关键
- 每个TCP连接的RTT均独立估算,并且重传计时器会对任何占用序列号的在传数据(包括SYN和FIN报文段)计时。如何恰当设置计时器一直以来都是研究的热点问题,近年来也取得了一些成果。本章节将探讨计算RTO计算方法在演进历程中的一些重要里程碑。
一、经典方法
SRTT的估计值
- 最初的TCP规范采用如下公式计算得到平滑的RTT估计值(称为SRTT):
- SRTT是基于现存值和新的样本值RTTs得到更新结果
- 常量α为平滑因子,推荐值为0.8~0.9
- 每当得到新的样本值,SRTT就会做出相应的更新。从α的设定值可以看到,新的估计值有80%~90%来自现存值,10% ~ 20%来自新测量值。这种估算方法称为指数加权移动平均(EWMA)或低通过滤器
- 该方法实现起来较为简单,只要保存SRTT的先前值即可得到新的估计值
RTO的计算
- 考虑到SRTT估计器得到的估计值会随RTT而变化,[RFCO793]推荐根据如下公式设置RTO:
- β为时延离散因子,推荐值为1.3 - 2.0
- ubound为RTO的上边界(可设定建议值,,如1分钟)
- lbound为RTO的下边界(可设定建议值,如1秒)
- 我们称该方法为经典方法,它使得RTO的值设置为1秒,或约两倍的SRTT
- 对于相对稳定的RTT分布来说,这种方法能取得不错的性能。然而,若TCP运行于RTT变化较大的网络中,则无法获得期望的效果
二、标准方法
- 在[J88]中,Jacobson进一步分析了上述经典方法,即按照[RFCO793]设置计时器无法适应RTT的大规模变动(特别是,当实际的RTT远大于估计值时,会导致不必要的重传)。 增大的RTT样本值表明网络已出现过载,此时不必要的重传无疑会进一步加重网络负担
- 为解决上述问题,可对原方法做出改进以适应RTT变动较大的情况。可通过记录RTT测量值的变化情况以及均值来得到较为准确的估计值。基于均值和估计值的变化来设置RTO,将比仅使用均值的常数倍来计算RTO更能适应RTT变化幅度较大的情况
- [J88]中的图5和图6显示了采用[RFCO793]与同时考虑RTT变化值的方法计算RTO的对比情况。如果我们将TCP得到的RTT测量样本值考虑为一个统计过程,那么同时测量均值和方差(或标准差)能更好地估计将来值。对RTT的可能值范围做出好的预测可以帮助TCP设定一个能适应大多数情况的RTO值
标准方法如下:
- 正如Jacobson所述,平均偏差是对标准差的一种好的逼近,但计算起来却更容易、更快捷。计算标准差需要对方差进行平方根运算,对于快速TCP实现来说代价较大。 (但这并非全部原因,可参见[GO4]中所述的有趣的“争论”历史。)因此我们需要结合平均值和平均偏差来进行估算。可对每个RTT测量值M(前面称为RTTs)采用如下算式:
- 这里,srtt值替代了之前的SRTT,且rttvar为平均偏差的EWMA,而非采用先前的β来设置RTO
- 这组等式也可以写成另一种形式,对计算机实现来说操作较为方便:
- 如前所述,srtt为均值的EWMA,rttvar为绝对误差|Err|的EWMA。Err为测量值M与当前RTT估计值srtt之间的偏差。srtt与rttvar均用于计算RTO且随时间变化。增量g为新RTT样本M占srtt估计值的权重,取为1/8。增量h为新平均偏差样本(新样本M与当前平均值srtt之间的绝对误差)占偏差估计值rttvar的权重,取为1/4。当RTT变化时,偏差的增量越大,RTO增长越快。g和h的值取为2的(负的)多少次方,使得整个计算过程较为简单,对计算机来说只要采用定点整型数的移位和加法操作即可,而无须复杂的乘除法运算
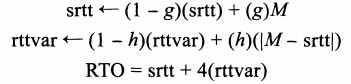


- 比较经典方法与Jacobson的计算方法,平均RTT的计算过程类似(α等于1减增量g),只是采用的增量不同。另外,Jacobson同时基于平滑RTT和平滑偏差计算RTO,而经典方法简单采用平滑RTT的倍数。这是迄今为止许多TCP实现计算RTO的方法,并且由于其作为[RFC6298]的基础,我们称其为标准方法,尽管在[RFC6298]中有一些改进。下面我们就讨论这个问题
①时钟粒度与RTO边界
- 在测量RTT的过程中,TCP时钟始终处于运转状态。对初始序列号来说,实际TCP连接的时钟并非从零开始计时,也没有绝对精确的精度。相反地,TCP时钟通常为某个变量,该变量值随着系统时钟而做出更新,但并非一对一地同步更新。TCP时钟一个“滴答”的时间长度称为粒度。通常,该值相对较大(约500ms),但近期实现的时钟使用更细的粒度(如Linux采用1ms)
- 粒度会影响RTT的测量以及RTO的设置。在[RFC6298]中,粒度用于优化RTO的更新情况,并给RTO设置了一个下界。计算公式如下:
- 这里的G为计时器粒度,1000ms为整个RTO的下界值([RFC6298]的规则(2.4)建议值)。 因此,RTO至少为1s,同时提供了可选上界值,假设为60s
②RTO初始值
- 我们已经看到估计器怎样随时间进行更新,但同时也需要了解怎样设置初始值。在首个SYN交换前,TCP无法设置RTO初始值。除非系统提供(有些系统在转发表中缓存了该信息,见后面“目的度量”文章),否则也无法设置估计器的初始值
- 根据[RFC6298],RTO的初始值为1s,而初始SYN报文段采用的超时间隔为3s。当接收到首个RTT测量结果″,估计器按如下方法进行初始化:
- 我们已经了解了估计器的初始化和运行过程。RTO的设置看似取决于得到的RTT采样值,下面我们将看到一些例外情况

③重传二义性与Karn算法
- 在测量RTT样本的过程中若出现重传,就可能导致某些问题。假设一个包的传输出现超时,该数据包会被重传,接着收到一个确认信息。那么该信息是对第一次还是第二次传输的确认就存在二义性。这就是重传二义性的一个例子
- [KP87]指出,当出现超时重传时,接收到重传数据的确认信息时不能更新RTT估计值。这是Karn算法的“第一部分” 。它通过排除二义性数据来解决RTT估算中出现的二义性问题。 [RFC6298]做出了相关要求。
- 假如我们在设置RTO过程中简单地将重传问题完全忽略,就可能将网络提供的一些有用信息也同时忽略(即网络中可能出现某些因素影响传输速度)。这种情况下,在网络不再出现丢包前降低重传率有助于减轻网络负担。这也是下面指数退避行为的理论基础(见前面一篇文章的TCP超时与重传案例)
- TCP在计算RTO过程中采用一个退避系数,每当重传计时器出现超时,退避系数加倍,该过程一直持续至接收到非重传数据。此时,退避系数重新设为1(即二进制指数退避取消),重传计时器返回正常值。对重传过程退避系数加倍,这是Karn算法的 “第二部分”。注意若TCP超时,同时会引发拥塞控制机制,以此改变发送速率(拥塞控制将在后面文章介绍)。
- 因此,Karn算法实际上由两部分组成,如[KP89]所述:
- Karn算法一直作为TCP实现中的必要方法(自[RFC1122]起),然而也有例外情况。在使用TCP时间戳选项(见前面TCP选项文章)的情况下,可以避免二义性问题,因此Kam算法的第一 部分不适用

④带有时间戳选项的RTT测量
- TCP时间戳选项(TSOPT)作为PAWS算法的基础(在前面TCP选项文章已经介绍过),还可用作RTT测量(RTTM)。TSOPT的基本格式在前面TCP选项文章已经介绍过。它允许发送者在返回的对应确认信息中携带一个32比特的数
- 时间戳值(TSV)携带于初始SYN的TSOPT中,并在SYN+ACK的TSOPT的TSER部分返回,以此设定srtt、 rttvar与RTO的初始值。由于初始SYN可看作数据(即同样采取丢失重传策略且占用一个序列号),应测量其RTT值。其他报文段中也包含TSOPT,因此可结合其他样本值估算该连接的RTT
- 该过程看似简单但实际存在很多不确定因素,因为TCP并非对其接收到的每个报文段都返回ACK:
- 例如,当传输大批量数据时,TCP通常采取每两个报文段返回一个ACK的方法(见后面“TCP数据流与窗口管理”)
- 另外,当数据出现丢失、失序或重传成功时,TCP的累积确认机制袁明报文段与其ACK之间并非严格的一一对应关系。
- 为解决上面这些问题,使用时间戳选项的TCP(大部分的Linux和Windows版本都包含)采用如下算法来测量RTT样本值:
- 1.TCP发送端在其发送的每个报文段的TSOPT的TSV部分携带一个32比特的时间戳值。该值包含数据发送时刻的TCP时钟值
- 2.接收端记录接收到的TSV值(名为TsRecent的变量)并在对应的ACK中返回,并且记录其上一个发送的ACK号(名为LastACK的变量)。回忆一下,ACK号代表接收端(即ACK的发送方)期望接收的下一个有序序号
- 3.当一个新的报文段到达时,如果其序列号与LastACK的值吻合(即为下一个期望接收的报文段),则将其TSV值存入TsRecent
- 4.接收端发送的任何一个ACK都包含TSOPT,TsRecent变量包含的时间戳值被写人其 TSER部分
- 5.发送端接收到ACK后,将当前TCP时钟减去TSER值,得到的差即为新的RTT样本估计值
- FreeBSD、 Linux以及近期的Windows版本都默认启用时间戳选项。在Linux中,系统配置变量net.ipv4.tcp_timestamps控制是否使用该选项(0代表禁用,1代表使用)。在 Windows中,通过前面提到的注册表区域的Tcp13230pts值来控制其使用。若值为0,时间戳被禁用;若值为2,则启用。该键值没有设默认值(它并非默认存在于注册表中)。但若在连接初始化过程中,TCP通信的另一方使用时间戳,则默认启用
三、Linux采用的方法
- Linux的RTT测量过程与标准方法有所差别。它采用的时钟粒度为1ms,与其他实现方法相比,其粒度更细,TSOPT也是如此
-
Linux测量方法的两个问题:
- ①采用更频繁的RTT测量与更细的时钟粒度,RTT测量也更为精确,但也易于导致rttvar值随时间减为最小[LSOO]。这是由于当累积了大量的平 均偏差样本时,这些样本之间易产生相互抵消的效果。这是其RTO设置区别于标准方法的一个原因
- ②另外,当某个RTT样本显著低于现有的RTT估计值srtt时,标准方法会增大rttvar
- 为更好地理解第二个问题,首先回顾一下RTO通常设置为srtt+4(rttvar)。因此,无论最大RTT样本值是大于还是小于srtt,rttVar的任何大的变动都会导致RTO增大。这与直觉相反一若实际RTT大幅降低,RTO并不会因此增大。Linux通过减小RTT样本值大幅下降对rttvar的影响来解决这一问题
- 下面我们详细讨论Linux设置RTO的方法,该方法可以同时解决上述两个问题
Linux的实现方法
- 与标准方法一样,Linux也记录变量srtt与rttvar值,但同时还记录两个新的变量,即mdev和mdev_max。mdev为采用标准方法的瞬时平均偏差估计值,即前面方法的rttvar。mdev_max则记录在测量RTT样本过程中的最大mdev,其最小值不小于50ms。另外,rttVar 需定期更新以保证其不小于mdev_maX。因此RTO不会小于200ms
- Linux根据mdev_maX的值来更新rttvar。RTO总是等于srtt与4(rttvar)之和,以此确保RTO不超过TCP_RTO_MAX (默认值为120s)。详见[SKO2]。下图详细描述了这一过程,从中也可看到时间戳选项是怎样工作的
- 从上图中可以看到,该TCP连接采用时间戳选项。发送端为Linux2.6系统,接收端为FreeBSD 5.4系统。为简单起见,序列号和时间戳取相对值,且只显示了发送端的时间戳。为使数据简单可读,本图并未严格按照时间尺度。基于本例中得到的初始RTT测量值,Linux采用如下算法进行更新:
- 在初始SYN交换后,发送端对接收端的SYN返回一个ACK,接收端则进行了一次相应的窗口更新。由于这些包都未包含实际数据(SYN或FIN位字段,但都被算作数据),并没有记录对应的时间,且发送端收到窗日更新时也没有进行RTT更新。TCP对不含数据的报文段不提供可靠传输,意味着若出现丢包不会重传,因此无须设定重传计时器
- 当应用首次执行写操作,发送端TCP发送两个报文段,每个报文段包含一个值为127 的TSV.由于两次发送间隔小于1ms(发送端TCP时钟粒度),因此这两个值相等。当发送端以这种方式接连发送多个报文段时,很容易看到时钟没有前进或小幅前进的情况
- 接收端变量LastACK记录其上一个发送ACK的序列号。在本例中,上一个发送的 ACK为连接建立阶段的SYN +ACK包,因此LastACK从1开始。当首个全长(full-size)报文段到达,其序列号与LastACK吻合,则将TSRecent变量更新为新接收分组的TSV,即1270第二个报文段的到达并没有更新TsRecent,因为其序列号字段与LastACK中的值并不匹配。接收端返回对应分组的ACK时,需在其TSER部分包含TsRecent,同时接收端还要更新LastACK变量的ACK号为2801
- 当该ACK到达时,TCP就可以进行第二个RTT样本的测量。首先获得当前TCP时钟值,减去已接收ACK包含的TSER,即样本值阴=223 - 127=960根据该测量值,Linux TCP按如下步骤更新连接变量:




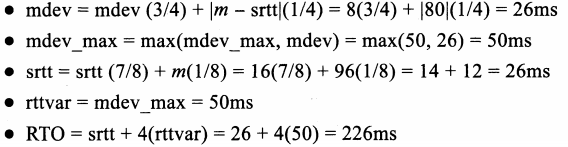
- 如前所述,Linux TCP针对经典RTT估算方法做出了几处改进。在经典算洼提出之时,TCP时钟粒度普遍为500ms,且时间戳选项也没有得到广泛应用。通常,每个窗口只测量一 个RTT样本,并据此进行估计器的更新。在不使用时间戳的情况下,依然采用这种方法
- 若每个窗口只测量一个RTT样本,rttVar相对变动则较小。利用时间戳和对每个包的测量,就可以得到更多的样本值。因为对同一个窗口的数据而言,每个包对应的RTT样本通 常存在一定的差异,短时间内得到的大量样本值(如窗口较大)可能导致平均偏差变小(接 近0,基于大数定律[F68])。为解决上述问题,Linux维护瞬时平均偏差估计值mdev,但设置RTO时则基于rttvar(在一个窗口数据期间记录的最大mdev,且最小值为50ms)。仅当进 人下一个窗口时,rttvar才可能减小
- 标准方法中rttvar所占权重较大(系数为4),因此即使当RTT减小时,也会导致RTO增长。在时钟粒度较粗时(如500ms),这种情况不会有很大影响,因为RTO可用值很少。 然而,若时钟粒度较细,如Linux的1ms,就可能出现问题。针对RTT减小的情况,若新样本值小于RTT估计范围的下界(srtt - mdev),则减小新样本的权重。完整的关系式如下:
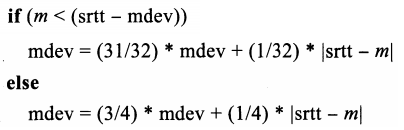
- 该条件语句只在新RTT样本值小于期望的RTT测量范围下界的前提下成立。若该条件成立,则表明该连接的RTT正处于急剧减小的状态。为避免该情况下的mdev增大(以及由 此导致的rttvar和RTO增大),新的平均偏差样本|srtt-m|,将其权重减小为原来的1/8。整体来看,该结果可以避免RTT减小导致的RTO增大间题。对该问题的进一步讨论,请参见 [LSOO]及[SK.02]。在[RKSO7]中,作者在280万个TCP流的多个系统上运行了RTT估算算法,运行结果表明Linux估计器性能最优,这很大程度上是由于其相对快速收敛,但也可能 是减小了RTT变动对RTO的影响。
- 现在回到上图,当接收端生成ACK7001时,我们看到其TSER包含了一个TSV副本,该值并非来自最新到达的报文段,而是最早的一个未经确认的报文段。当该ACk返回至发送端,通过计算得到的RTT样本是基于第一个报文段,而非第二个。这说明了时间戳算洼在延时或不稳定的ACK下的工作情况。若计算最早的包对应的RTT,得到的样本值为发送端期望收到ACK需经过的时间,而非实际网络RTT。这点很重要,因为发送端需根据 其ACK接收率来设置RTO,接收率可能小于包的发送率
四、RTT估计器行为
- 我们已经看到,设置RTO与估算RTT有大量的设计和改进方法
- 下图显示了其中主要的估算方法,即基于标准方法和Linux算法得到的综合数据集。图中[RFC6298]推荐的标准算法最小RTO值1s已被移除。目前的大多数TCP实现方法都不再采用该值[RKSO7]
- 图中显示了两个在高斯概率分布N(200,50)和N(50,,50)上的200个值对应的时间序列图。第一个分布对应前100个点,第二个对应后100个点。负的样本值通过符号变换转化为正值(只针对第二个分布)。每个加号(+)表示一个具体的样本值。很明显可以看到,在第100个样本值之后出现了巨幅下降,另外Linux方法在第100个样本值之后RTO立即减小,而标准方洼则在120个样本值后才开始减小
- 观察Linux的rttvar线,可以看到其基本保持恒定。这是由于mdev_max的最小值为 50ms(因此rttvar也是如此),使得Linux的RTO始终保持在200ms以上,并且避免了所有不必要的重传(尽管可能由于RTO较大,计时器未超时,导致丢包时性能降低)。标准方法在样本78和191可能出现潜在问题,即伪重传的发生。这个问题留到后面再讨论

五、RTTM(RTT测量)对丢包和失序的鲁棒性
- 当没有丢包情况时,不论接收端是否延迟发送ACK,TSOPT可以很好地工作。该算法在以下几种情况下都能正确运行:
- 失序报文段:当接收端收到失序报文段时,通常是由于在此之前出现了丢包,应当立即返回ACK以启动快速重传算法(见后面文章)。该ACK的TSER部分包含的TSV值为接收端收到最近的有序报文段的时刻(即最新的使窗口前进的报文段,通常不会是失序报文段)。这会使得发送端RTT样本增大,由此导致相应的RTO增大。这在 一定程度上是有利的,即当包失序时,发送端有更多的时间去发现是出现了失序而非丢包,由此可避免不必要的重传
- 成功重传:当收到接收端缓存中缺失的报文段时(如成功接收重传报文段),窗口通常会前移。此时对应ACK中的TSV值来自最新到达的报,这是比较有利的。若采用原来报文段中的TSV,可能对应的是前一个RTO,导致发送端RTT估算的偏离
图示
- 下图的例子描述了这些点。假设三个报文段,每个包含1024字节,接收顺序如下:
- 报文段1包含1-1024字节
- 报文段3包含2049-3027字节
- 接着是报文段2包含1025 - 2048字节
- 上图中发回的ACK 1025包含了报文段1的时间戳(正常的数据确认),以及另一个包含报文段1时间戳的ACK 1025(对应于在窗口中但失序的重复ACK),接着是ACK 3037包含了报文段2的时间戳(而非报文段3的时间戳)
- 当分组失序(或丢失)时,RTT会被过高估算。较大的RTT估计值使得RTO也更大,由此发送端也不会急于重传。在失序情况下这是很有利的,因为过分积极的重传可能导致伪重传

- 我们已经看到,时间戳选项使得发送端即使在丢包、延时、失序的情况下也能测量RTT。发送端在测量RTT的过程中,可以在其选项中包含任意值,但其单位必须至少和实际时间成比例,且粒度合理,并与TCP序列号兼容,连接速率可信(详见[RFC1323])。特别是,为了对发送端更有利,对任何可信的RTT,TCP时钟必须至少“滴答”一次。另外,其每次变化不能快于59ns。若小于,在IP层允许单个包存在的最大时间(255s)内,记录TCP时钟的32位的TSV值能够环绕[ID1323b]。满足上述所有条件后,RTO值就可以用来触发重传
转载地址:https://dongshao.blog.csdn.net/article/details/104082993 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月24日 03时33分35秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Oracle 查询数据库有多少张表
2019-04-30
VBA工作表的操作详解
2019-04-30
ORA-01940:无法删除当前已连接的用户
2019-04-30
Oracle exp/imp 导入导出命令
2019-04-30
Orcle DBA学习笔记(角色,对象,权限,用户,索引,视图,同义词,序列)
2019-04-30
Oracle 字符串函数总结
2019-04-30
Oracle 数值函数和日期函数总结
2019-04-30
Oracle 之常用分析函数
2019-04-30
U盘太土没个性?快来定制盘符图像!
2019-04-30
Oracle多库查询方法
2019-04-30
给Eclipse代码编辑区设置背景图片
2019-04-30
Timer定时任务调度Api及优缺点
2019-04-30
Kotlin 奇葩的when语法
2019-04-30
Kotlin使用lambda表达式过滤和映射集合:
2019-04-30
Kotlin 读取文件内容
2019-04-30
Base64工具类
2019-04-30
文件读取工具类
2019-04-30
eWebEditor编辑器的使用
2019-04-30
redis执行了flushdb或者flushall之后的“后悔药”操作
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310479291 位访客
访问时间: 2024-05-04 01:52:47
访问IP: 3.137.183.14
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版