本文共 4370 字,大约阅读时间需要 14 分钟。
NOTE:ROW/COW 最新更新请跳转
目录
快照与备份的区别
传统地, 人们一直采用数据复制、备份、恢复等技术来保护重要的数据信息, 定期对数据进行备份或复制。由于数据备份过程会影响应用性能, 并且非常耗时, 因此数据备份通常被安排在系统负载较轻时进行(如夜间). 另外, 为了节省存储空间, 通常结合全量和增量备份技术. 显然, 这种数据备份方式存在一个显著的不足, 即备份窗口问题. 在数据备份期间, 企业业务需要暂时停止对外提供服务. 随着企业数据量和数据增长速度的加快, 这个窗口可能会越来越长, 这对于关键性业务系统来说是无法接受的. 诸如银行、电信等机构, 信息系统要求 24*7 不间断运行, 短时的停机或者少量数据的丢失都会导致巨大的损失. 因此, 就需要将数据备份窗口尽可能地缩小, 甚至缩小为零. 数据快照(Snapshot)、持续数据保护(CDP, Continuous Data Protection)等技术,就是为了满足这样的需求而出现的数据保护技术.
需要注意的是: 目前, 随着对信息系统的依赖程度越来越高, 即使不是银行、电信这类传统关键行业, 在政府、教育、企业也越来越多的系统要求更小的备份窗口和更短的停机时间. 降低数据保护的代价, 提高数据保护过程中的应用感知能力,逐步成为客户的首要需求.
快照的优势:
快照可以在数秒钟内建立拷贝, 供备份应用使用. 利用快照技术, 配合普通的备份软件是这样实现的:
- 通过图形的管理界面发出做快照的命令
- 快照功能自动寻找没有数据改变的时刻进行拷贝,几秒钟之后拷贝生成
- 再使用备份软件对该拷贝进行备份
利用快照的镜像可以在数秒钟内把数据恢复到做快照的时间点, 还允许系统管理员选择性地迅速恢复受损或被删文件
数据快照的功能还有很多用处, 比如现在需要一份最新的生产数据来做新系统的测试或者提供决策支持和数据分析所用, 而系统又不能停机, 使用磁带备份恢复 一份数据时间又很长. 这样的情况可以利用数据快照的备份功能在任一时间点建立快照拷贝, 利用拷贝的数据进行测试和分析, 不会影响系统的正常使用
Snapshot 快照技术
SNIA(存储网络行业协会)对快照的定义是:关于指定数据集合的一个完全可用拷贝, 该拷贝包含了相应数据在某个时间点的镜像.
按照 SNIA 的定义, 快照有 全量快照和增量快照 两种类型, 其中又各自使用了不同的快照技术:
- 全量快照:
- 镜像分离 (Split Mirror)
- 增量快照
- 写时拷贝 (Copy-On-Write)
- 写时重定向 (Redirect-On-Write)
其中写时重定向快照方式的灵活性以及使用存储空间的高效性, 加上分布式存储的流行, 使其逐渐成为快照技术的主流.
全量快照
又称全拷贝快照或原样复制, 使用 镜像分离快照技术 在到达预设的快照时间点之前, 首先为源数据卷创建并维护一个完整的镜像卷. 每次写入数据到磁盘时, 都会往源数据卷和镜像卷同时写入, 这样保证了同一份数据的两个副本分别保存在源数据卷和镜像卷上, 并且由两者组成的一个镜像对. 在预设快照时间点到达时, 镜像对的数据写入操作被停止, 镜像卷快速脱离镜像对并转化为快照卷, 这样就获得了一份数据快照. 快照卷在完成数据快照/数据备份等应用后, 将与源数据卷重新进行同步, 成为一盒新的镜像卷.
那么, 对于要同时保留多个连续时间点快照的源数据卷, 就必须预先为其创建多个镜像卷, 当第一个镜像卷被转化为快照卷并作为数据备份后, 预先创建的第二个镜像卷立即与源数据卷同步, 成为新的镜像对.
镜像分离快照的好处在于数据隔离性好, 使离线访问数据成为可能, 并且简化了恢复、复制或存档一块硬盘上的所有数据的过程. 最重要的是操作的时间非常短, 仅仅是断开镜像卷对所需的时间, 通常只有几毫秒, 这样小的备份窗口几乎不会对上层应用造成影响. 不存在快照卷和源数据卷的相互影响, 但这种方式的缺点也十分明显, 缺乏灵活性, 无法在任意时间点为任意的数据卷建立快照. 另外, 它需要一个或者多个与源数据卷容量相同的镜像卷, 占用了大量存储空间, 而且写数据时同时写两份, 对写入性能影响比较大, 在同步镜像时还会降低存储系统的整体性能. 为了解决镜像分离快照技术实现的全量快照方式, 引入了差量快照的实现方式以及 COW/ROW 两种差量快照技术.
增量快照
COW 写时拷贝快照技术

如上图, COW 首先会为每个源数据卷都创建一张数据指针表用于保存源数据卷(Base Volume)所有数据的物理指针, 在创建快照时, 存储系统会拷贝出一份源数据卷指针表的副本, 该副本作为快照卷数据指针表. 而且 COW 只有在创建快照时才会建立快照卷, 该快照卷只占用了相对少量的存储空间, 用于保存快照时间点之后源数据卷中被更新的数据. 具体的步骤如下:
- Step 1: 生成源数据卷数据指针表
- Step 2: 创建快照
- Step 3: 从源数据卷数据指针表拷贝出快照卷数据指针表
- Step 4: 生成快照卷
- Step 5: 源数据卷中的原始数接收到更新操作指令
- Step 6: 将源数据卷中的原始数据拷贝到快照卷中(预留空间), 下次针对这一位置的写操作将不再执行写时拷贝操作
- Step 7: 更新快照卷指针表
- Step 8: 更新源数据卷的原始数据
- Step 9: 不断的重复 Step 5~8, 直到执行下一次快照
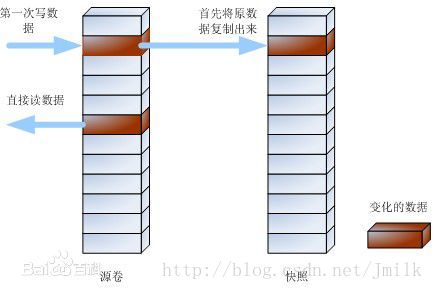
通过上面的步骤可以看出, 写时拷贝的本意是: 更新源数据卷中的原始数据时, 将原始数据 Copy 到快照卷中. 当我们需要恢复快照时, 只需要按照快照指针表逐一进行寻址就能够完成了. 而且 COW 在使用上非常的灵活, 可以随时为任意源数据卷建立快照.
优势: COW 在进行快照操作之前, 不会占用任何的存储资源, 也不会影响系统性能. 创建快照时由于快照卷与源数据卷通过各自的指针表共享同一份物理数据, 而不需要进行全量拷贝所以快照创建速度非常快, 可以瞬间完成. COW 创建快照时产生的备份窗口长度与源数据卷的 Size 成线性比例, 一般为几秒钟, 相比全量快照要长, 但快照卷占用的存储空间却大大减少.
劣势: COW 因为创建快照后会的每次写入操作都需要先将源数据卷中的原始数据拷贝到快照卷中才能开始写入源数据卷, 所以会降低源数据卷的写性能. 而且很显然, 如果对同一源数据卷做了多次快照之后, 写性能将会更加低下. 再一个就是由于快照卷仅仅保存了源数据卷的部分原始数据, 因此无法得到完整的物理副本, 碰到需要完整物理副本的应用就无能为力了, 而且如果拷贝到快照卷中的数据量超过了保留空间, 快照就将失效.
应用场景: COW 快照技术在创建快照后的一次数据更新操作实际上需要一次读操作(读源数据卷的数据)和两次写操作(写源数据卷与写快照卷). 所以, COW 更适合于应用对存储设备读多写少的场景. 除此之外, 如果一个应用容易出现对存储设备的写入热点(只针对某个有限范围内的数据进行写操作), 也是较较理想的选择. 因为其数据更改都局限在一个范围内, 对同一份数据的多次写操作只会出现一次写时复制操作.
ROW 写时重定向快照技术
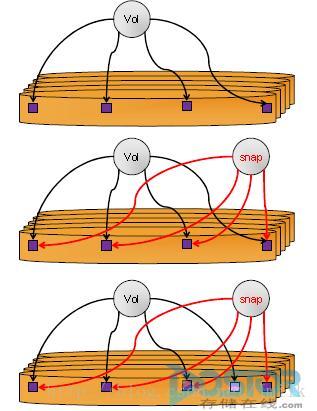
如上图, Vd 表示源数据卷, Snap 表示快照卷, 当源数据卷创建一个快照时, Vd 与 snap 是一致的. 如果在创建快照之后, 对源数据卷的数据进行了更新操作的话, 并不会像 COW 似得直接修改源数据卷原始数据, 而是再开辟一个新的空间用于存放用于更新原始数据的新的数据. 具体步骤如下:
- Step 1: 创建快照
Step 2: 将自上次快照以来所有的重定向写数据所对应在源数据卷中的数据复制出来生成这个时间点的快照, 然后再将这些重定向写数据写回到源数据卷中的相应位置
Step 3: 源数据卷中的原始数据接收到更新操作指令
- Step 4: 开辟一个新的数据存储卷(预留空间)
- Step 5: 将源数据卷数据指针表中被更新原始数据的指针重定向到新开辟的数据存储卷
- Step 6: 写入更新数据到新开辟的存储空间中
- Step 7: 重复 Step 3~6, 直到下一次执行快照
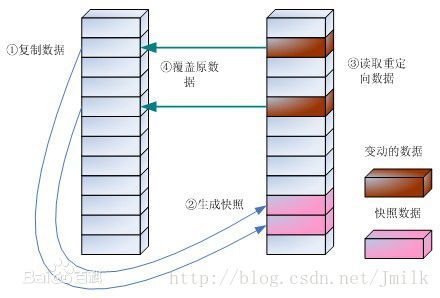
NOTE 1: 而读操作是否需要读重定向, 则根据读取数据的位置是否有过自上次快照以来的写重定向, 必须对有过写重定向的位置进行读重定向, 反之就不需要了.
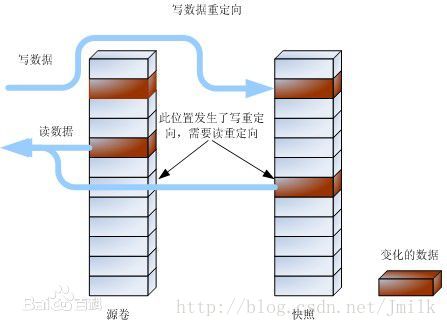
从上述步骤可以看出, 写时重定向的本意是: 更新源数据卷中的原始数据时, 将源数据卷数据指针表中的被更新原始数据指针重定向到新的存储空间. 所以由此至终, 快照卷的数据指针表和其对应的数据是没有被改变过的. 恢复快照的时候, 只需要按照快照卷数据指针表来进行寻址就可以完成恢复了.
优势: 源数据卷创建快照后的写操作会被重定向, 所有的写 IO 都被重定向到新卷中, 而所有快照卷数据(旧数据)均保留在只读的源数据卷中. 这样做的好处是更新源数据卷只需要一次写操作, 解决了 COW 写两次的性能问题. 所以 ROW 最明显的优势就是不会降低源数据卷的写性能.
劣势: ROW 的快照卷数据指针表保存的是源数据卷的原始副本, 而源数据卷数据指针表保存的则是更新后的副本, 这导致在删除快照卷之前需要将快照卷数据指针表指向的数据同步至源数据卷中. 而且当创建了多个快照后, 会产生一个快照链, 使原始数据的访问、快照卷和源数据卷数据的追踪以及快照的删除将变得异常复杂. 例如: 一共执行了 10 次快照, 在快照恢复时, 要恢复到最新的快照点, 则需要合并 10 个快照文件, 最终才能实现恢复. 所以 ROW 的主要缺点是没有一个完整的快照卷, 而是由多个不同时刻的快照卷来组成一个特定的快照时间点. 如果快照层级越多, 进行快照恢复时的系统开销会比较大. 除此之外, 因为源数据卷数据指针指向的数据会很快的被重定向分散, 所以 ROW 另一个主要缺点就是降低了读性能(局部空间原理).
应用场景: 在传统存储设备上, ROW 快照在多次读写后, 源数据卷的数据被分散, 对于连续读写的性能不如COW. 所以 ROW 比较适合 Write-Intensive(写密集) 类型的存储系统. 但是, 在分布式存储设备上, ROW 的连续读写的性能会比 COW 更加好. 一般而言, 读写性能的瓶颈都在磁盘上. 而分布式存储的特性是数据越是分散到不同的存储设备中, 系统性能越高. 所以 ROW 的源数据卷重定向分散性反而带来了好处. 因此, ROW 逐渐成为了业界的主流.
最后
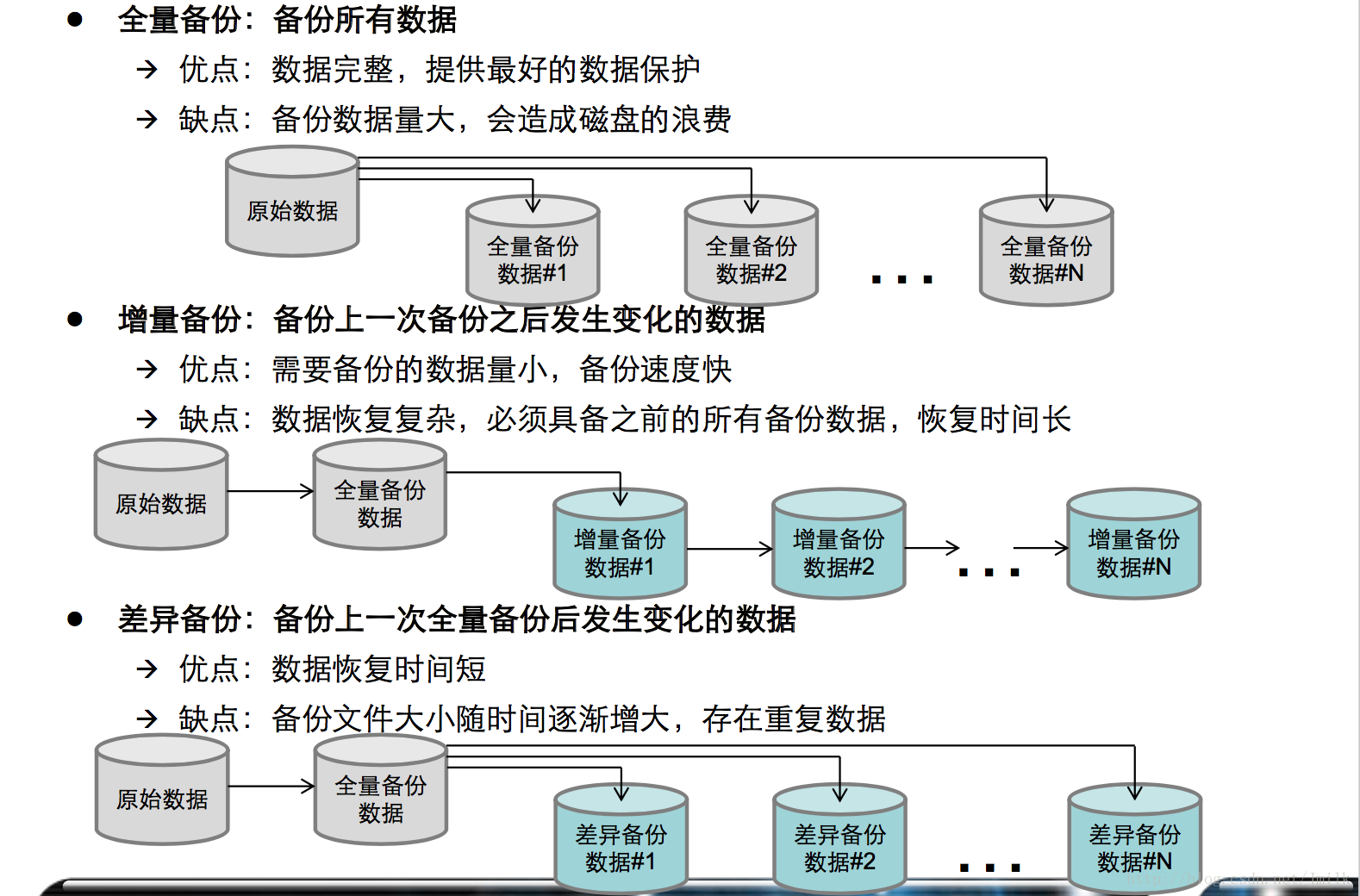
以一张图结尾, 这里的备份大致可以替换为镜像去理解.
转载地址:https://is-cloud.blog.csdn.net/article/details/65629391 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
