分布式事务系列--分布式跨库查询解决方案 mysql federated引擎的使用
配置文件添加:
这里需要注意,数据库引擎的选择,要明确指定引擎
2.远程表的数据库据密码,不能含有@字符,因为在创建映射表时,
发布日期:2021-06-30 11:08:04
浏览次数:2
分类:技术文章
本文共 3267 字,大约阅读时间需要 10 分钟。
背景
在服务高度拆分,数据库不断细化切分的情况下,我们经常有连接多台数据库查询的需求,如果不断的把数据库连接的逻辑添加在代码中,那么这种耦合会越来越严重,这会给程序的拓展和维护带来很大的麻烦。
mysql的federated引擎,可以在本地创建远程数据库的映射表,创建完后,拓扑如下:
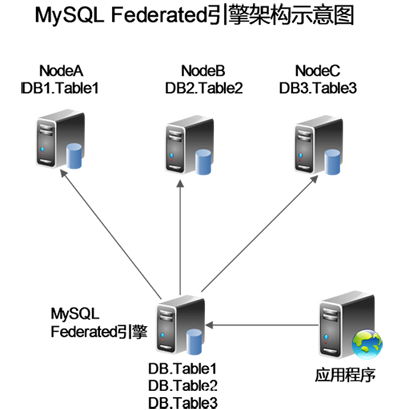
如此,我们可以在本地构建多个远程数据库库的统一入口,这样可以极大的简化在分布式环境中,跨服务器数据库的交互查询问题。
1.开启引擎
查询数据库是否支持
SHOW ENGINES;
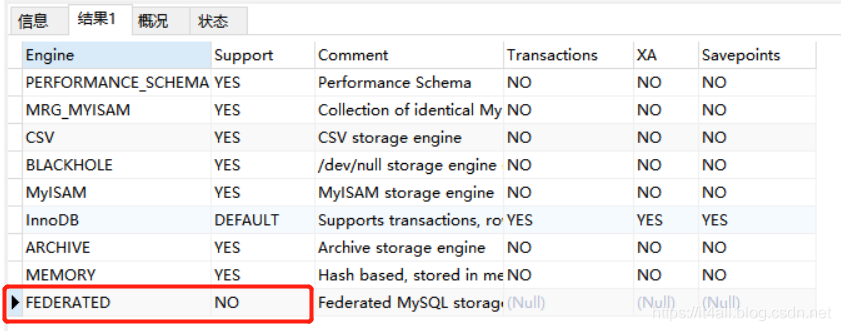
有,说明支持,但是没有开启,开启一下:
配置文件添加:federated,如下:
[mysqld]federated## Remove leading # and set to the amount of RAM for the most important data# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.# innodb_buffer_pool_size = 128M## Remove leading # to turn on a very important data integrity option: logging# changes to the binary log between backups.# log_bin## Remove leading # to set options mainly useful for reporting servers.# The server defaults are faster for transactions and fast SELECTs.# Adjust sizes as needed, experiment to find the optimal values.# join_buffer_size = 128M# sort_buffer_size = 2M# read_rnd_buffer_size = 2Mdatadir=/var/lib/mysqlsocket=/var/lib/mysql/mysql.sock# Disabling symbolic-links is recommended to prevent assorted security riskssymbolic-links=0log-error=/var/log/mysqld.logpid-file=/var/run/mysqld/mysqld.pidsql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
然后重启mysql,再次查询,发现已经开启:
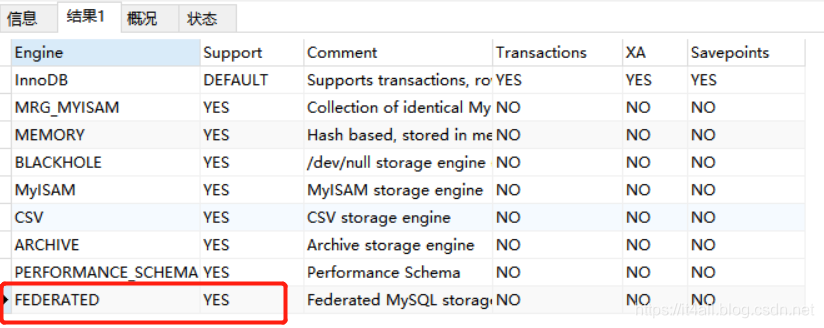
2.场景
数据库1:阿里云 java4all,表product_stock;
数据库2:华为云 wangtest1,表user;
user表中有一个product_stock_id。
需求:需要跨库查询。
3.创建数据库表映射
在华为云的wangtest1数据库中,创建一个阿里云的java4all库的product_stock表的映射表。
CREATE TABLE `product_stock` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `stock` int(11) DEFAULT NULL COMMENT '库存', PRIMARY KEY (`id`)) ENGINE=FEDERATED DEFAULT CHARSET=utf8 COMMENT='库存表,来自阿里云映射'CONNECTION='mysql://username:password@ip:port/java4all/product_stock';
这里需要注意,数据库引擎的选择,要明确指定引擎ENGINE=FEDERATED,
创建完后,会发现,在wangtest1库中,也有了product_stock表:
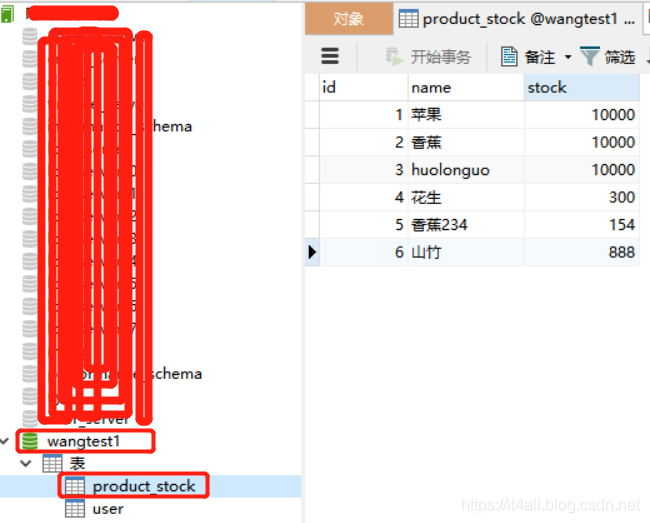
此时,其实在华为云的wangtest1库中,就有了阿里云的java4all库中的product_stock这张表的映射了。我们可以看到,这张表外观看起来和正常的表是一样的,但是其实华为云这边这是存储了表结构,数据还是从阿里云拉取的。
我们尝试在阿里云修改数据,在华为云这边刷新,也会看到变化。反之也是可以的。在使用层面看来,这个product_stock和本地原本就创建了的效果是一样的,各种查询都是支持的,但是不建议给映射表写的权限。
查询测试:
SELECT * from user a ,product_stock ps WHERE a.product_stock_id = ps.idand ps.`name` LIKE CONCAT('%','香','%')and a.user_type = 1; 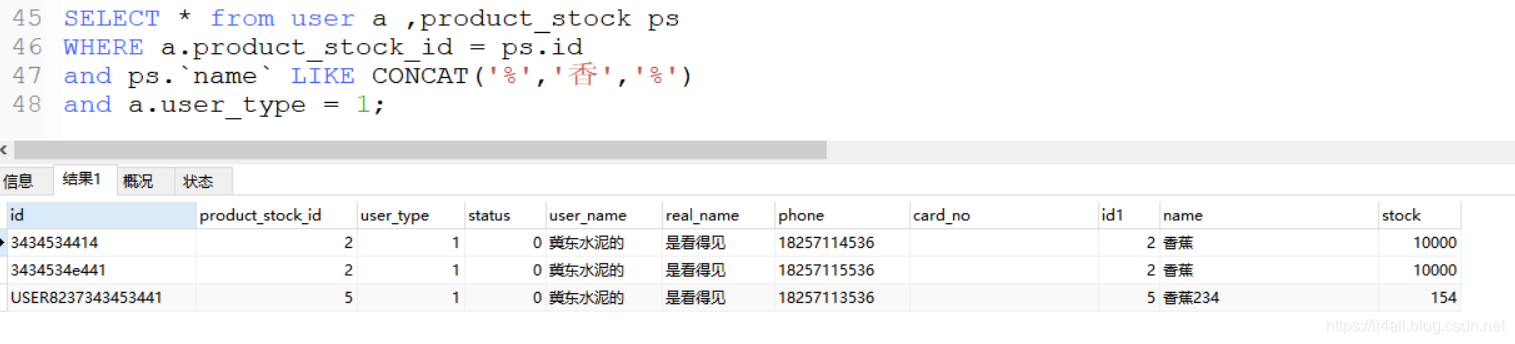
4.注意事项
1.映射表的字段,要少于等于原表(远程表)字段。
2.远程表的数据库据密码,不能含有@字符,因为在创建映射表时,CONNECTION='mysql://root:1xxx@1xx.xx.xx.xx:3306/java4all/product_stock',这里用户名密码,和数据库地址之间的分隔符是@,如果你的密码含有@,会导致解析出错。
3.修改本地表结构,是不允许的,因为你这个表是映射远程表的,远程表没改,你改了,可能会映射不上一些字段。如果远程表修改了,这个表需要重新映射。所有,理论上,为了防止不必要的麻烦,本地的映射表禁止任何结构性修改,如果远程表结构修改了,本地的删掉重新映射即可。
4.删除本地映射表,对远程表无负作用。
5.本地数据库服务必须支持federated引擎,远程服务器可以不支持。
6.数据库版本需要在5.0以上。
7.federated引擎是基于表级别的,无法实现基于库级别的整体映射。
8.如果远程表添加了索引,及时同步更新到本地映射表中。
9.limit是个比较慢的操作,引擎会将所有满足条件的数据读取到本地,再limit处理。
10.显然,看起来,你可能会觉得,那我把各个相关微服务的表全部映射过来,那连分布式事务的问题都一并解决了,因为本地看起来就拥有所有的表,那分布式事务的各种解决方案都不需要存在了。这里,由于没有这么大规模生产压测过,不好定论,不好反驳。但是既然微服务拆分了,解耦了应用,那库显然也是解耦的,mysql只是提供了这种功能,让你在某些特殊需求场景下,来连接和简化多数据源数据的交互问题。而不是让你里用这个,将原本做好了解耦和合理拆分的东西,再重新糅合一团。
11.Pay attention to the border!
5.关于连接的问题
1.本地虚拟表与远程实体表之间是 TCP 长连接,并且是多个客户端利用的。所以不用担心因频繁建立连接带来的网络开销。
2.本虚拟表表与远程实体表之间的网络连接断开后,当对虚拟表发起查询时,它会尝试重新连接远程实体表,所以我们不用担心网络连接断开造成的永久中断问题。
3.如果长时间未对本地虚拟表作任何操作,虚拟表与实体表之间的连接将在远程主机的 wait_timeout 秒后自动断开,当对虚拟表发起查询时,连接又会重新建立。
6.性能
由于少见有大厂专门对此进行过性能测试,网上资料也比较少,目前未见到什么明显的性能短板,但没有大规模生产使用,应该还是有短板的(待我去官网翻译一波文档)。打算踩坑的可以一起组团踩坑。直接上生产的,注意风险把控。
起码是个跨服务查询,数据量大的时候,网络和传输应该是个起码的瓶颈。
转载地址:https://it4all.blog.csdn.net/article/details/88684475 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
不错!
[***.144.177.141]2024年04月27日 01时42分40秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
uni-app 环境搭建
2019-04-30
uni-app 浏览器测试
2019-04-30
dom - 12 种 node 类型
2019-04-30
css sprite是什么、有什么优缺点
2019-04-30
清除浮动的⼏种⽅式
2019-04-30
CSS在性能优化方面的实践
2019-04-30
CSS3动画(简单动画的实现,如旋转等)
2019-04-30
base64的原理及优缺点
2019-04-30
几种常见的CSS布局
2019-04-30
stylus/sass/less区别
2019-04-30
postcss的作用
2019-04-30
如何美化CheckBox
2019-04-30
伪类和伪元素的区别
2019-04-30
自适应布局
2019-04-30
什么是外边距重叠?重叠的结果是什么?
2019-04-30
rgba()和opacity的透明效果有什么不同?
2019-04-30
css中可以让文字在垂直和水平方向上重叠的两个属性是什么
2019-04-30
如何垂直居中一个浮动元素?
2019-04-30
px和em的区别
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310459656 位访客
访问时间: 2024-05-04 00:01:52
访问IP: 3.21.231.245
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版