Netty源码面试解析(八) - 解码上
 看一下这个
看一下这个


发布日期:2021-06-30 12:34:17
浏览次数:3
分类:技术文章
本文共 2998 字,大约阅读时间需要 9 分钟。
就像很多标准的架构模式都被各种专用框架所支持一样,常见的数据处理模式往往也是目标实现的很好的候选对象,它可以节省开发人员大量的时间和精力。
当然这也适应于本文的主题:编码和解码,或者数据从一种特定协议的格式到另一种格式的转 换。这些任务将由通常称为编解码器的组件来处理 Netty 提供了多种组件,简化了为了支持广泛 的协议而创建自定义的编解码器的过程 例如,如果你正在构建一个基于 Netty 的邮件服务器,那 么你将会发现 Netty 对于编解码器的支持对于实现 POP3、IMAP 和 SMTP 协议来说是多么的宝贵 0 什么是编解码器
每个网络应用程序都必须定义
- 如何解析在两个节点之间来回传输的原始字节
- 如何将其和目标应用程序的数据格式做相互转换
这种转换逻辑由编解码器处理,编解码器由编码器和解码器组成,它们每种都可以将字节流从一种格式转换为另一种格式
那么它们的区别是什么呢?
如果将消息看作是对于特定的应用程序具有具体含义的结构化的字节序列— 它的数据。那 么编码器是将消息转换为适合于传输的格式(最有可能的就是字节流);而对应的解码器则是将 网络字节流转换回应用程序的消息格式。因此,编码器操作出站数据,而解码器处理入站数据。 记住这些背景信息,接下来让我们研究一下 Netty 所提供的用于实现这两种组件的类。1 Netty解码概述

1.1 本文目标
- 解码器抽象的解码过程
- Netty里面有哪些拆箱即用的解码器
Netty 的解码器类:
- 将字节解码为消息 ByteToMessageDecoder 和 ReplayingDecoder
- 将一种消息类型解码为另一种 MessageToMessageDecoder
解码器负责将入站数据从一种格式转到另一种,所以 Netty 解码器实
ChannelInboundHandler 也很自然。 - 什么时候会用解码器? 每当需为
ChannelPipeline中的下一个ChannelInboundHandler转换入站数据时。
得益于ChannelPipeline 的设计,可以将多个解码器连接在一起,以实现任意复杂的转换逻辑,这也是 Netty 是如何支持代码的模块化以及复用的一个很好的例子。
案例代码



2 抽象解码器 ByteToMessageDecoder
2.1 示例
Netty 提供抽象基类:ByteToMessageDecoder,将字节解码为消息(或另一个字节序列)。
由于你不可能知道远程节点是否会一次性发送一个完整消息,所以该类会缓冲入站数据,直到它准备好处理。 - ByteToMessageDecoderAPI
 假设你接收了一个包含简单 int 的字节流,每个 int 都需要被单独处理 在这种情况下,你需要从入站
假设你接收了一个包含简单 int 的字节流,每个 int 都需要被单独处理 在这种情况下,你需要从入站ByteBuf中读取每个 int,并将它传递给ChannelPipeline中的下一个ChannelInboundHandler为了解码这个字节流,你要扩展ByteToMessageDecoder类(原子类型的 int 在被添加到 List 中时,会被自动装箱为 Integer)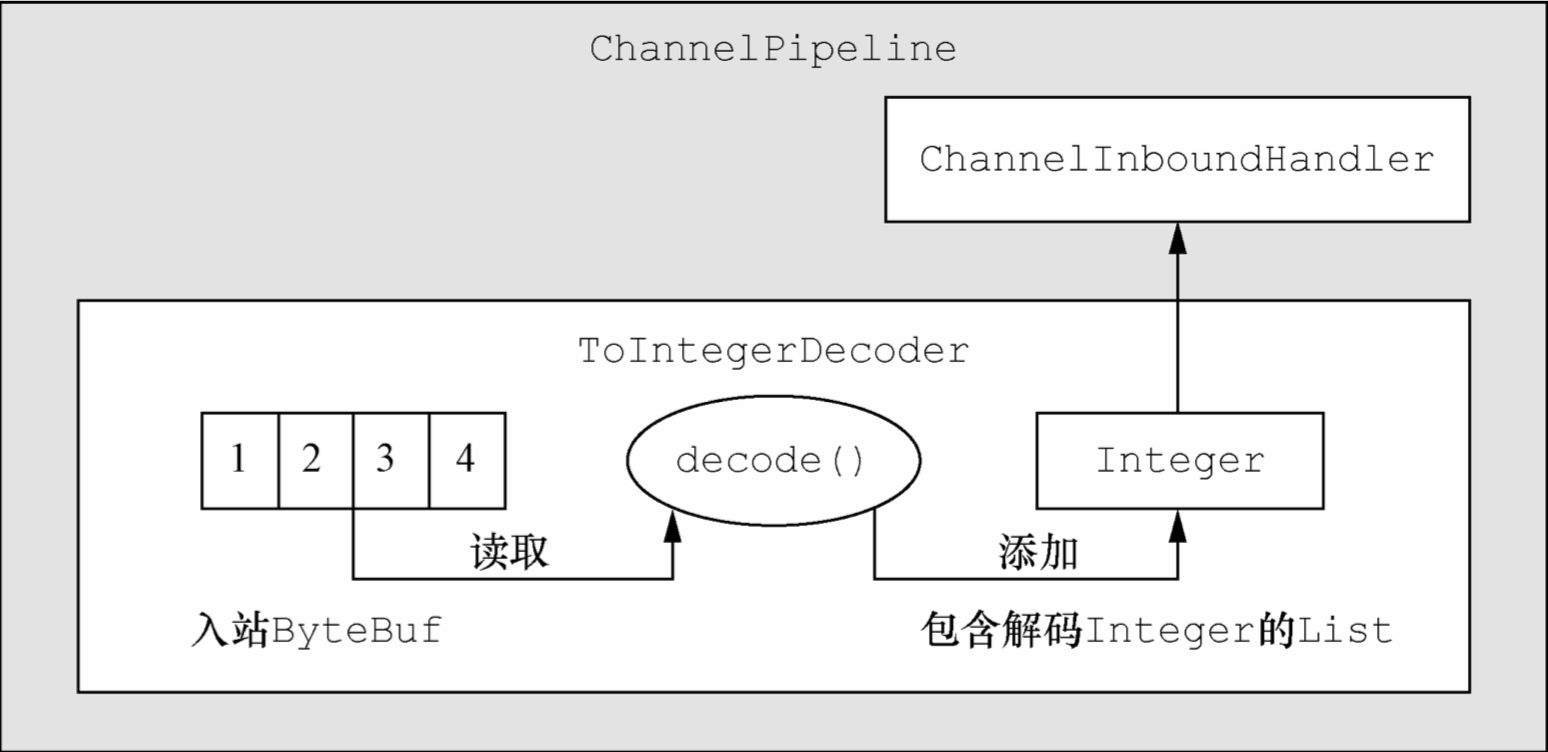 每次从入站 ByteBuf 中读取 4 字节,将其解码为一个 int,然后将它添加到一个 List 中 当没有更多的元素可以被添加到该 List 中时,它的内容将会被发送给下一个 Channel- InboundHandler
每次从入站 ByteBuf 中读取 4 字节,将其解码为一个 int,然后将它添加到一个 List 中 当没有更多的元素可以被添加到该 List 中时,它的内容将会被发送给下一个 Channel- InboundHandler - ToIntegerDecoder类扩展了ByteToMessageDecoder
 虽然
虽然ByteToMessageDecoder可以很简单地实现这种模式,但是你可能会发现,在调用readInt()前不得不验证所输入的 ByteBuf 是否具有足够的数据有点繁琐 在下一节中, 我们将讨论 ReplayingDecoder,它是一个特殊的解码器,以少量的开销消除了这个步骤
2.2 源码解析

下面开始解析解码流程的源码:
2.2.1 累加字节流

其中的cumulator 为
看一下这个MERGE_CUMULATOR public static final Cumulator MERGE_CUMULATOR = new Cumulator() { @Override public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) { ByteBuf buffer; // 当前写指针后移一定字节,若超过最大容量,则扩容 if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes() || cumulation.refCnt() > 1) { // Expand cumulation (by replace it) when either there is not more room in the buffer // or if the refCnt is greater then 1 which may happen when the user use slice().retain() or // duplicate().retain(). // // See: // - https://github.com/netty/netty/issues/2327 // - https://github.com/netty/netty/issues/1764 buffer = expandCumulation(alloc, cumulation, in.readableBytes()); } else { buffer = cumulation; } // 将当前数据写到累加器 buffer.writeBytes(in); // 释放读进的数据对象 in.release(); return buffer; }}; 2.2.2 调用子类 decode 方法进行解析
- 进入该方法查看源码


2.2.2 将解析到的 ByteBuf 向下传播
 注意到上图中的如下代码段:
注意到上图中的如下代码段:

编解码器中的引用计数
对于编码器和解码器,一旦消息被编码或解码,它就会被 ReferenceCountUtil.release(message)调用自动释放。
ReferenceCountUtil.retain(message),这会增加该引用计数,从而防止该消息被释放。 3 固定长度解码器

4 行解码器
4.1 定位行尾

4.2 非丢弃模式

-
找到换行符

-
找不到换行符


4.3 丢弃模式

-
找到换行符

-
找不到换行符

参考
- 《Netty实战》
转载地址:https://javaedge.blog.csdn.net/article/details/84594794 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过,博主的博客真漂亮。。
[***.116.15.85]2024年04月05日 04时50分00秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
android 7.0 apk安装问题
2019-04-30
Android 键值大全(键值定义源码)
2019-04-30
android 7.0 Jack-server 编译问题
2019-04-30
Linux基本使用&安装JDK
2019-04-30
Java基础知识1【安装+配置+初识Java】
2019-04-30
Java基础知识2【变量与数据类型】
2019-04-30
Java基础知识3【选择结构】
2019-04-30
Java基础知识4【循环结构】
2019-04-30
Java基础知识5【数组与Arrays工具类与排序算法】
2019-04-30
新手使用VUE做菜单/组织结构树
2019-04-30
简易的搭建ipv6网络环境iphone
2019-04-30
jquery的jquery.page分页插件使用方法
2019-04-30
pom.xml报unknown error
2019-04-30
记录一个小问题Invalid bound statement (not found)
2019-04-30
spring-admin使用过程中的一个小问题
2019-04-30
个人关于MYSQL的锁、事务、隔离级别的一些理解
2019-04-30
记录下本人对分布式session问题的理解与解决方案
2019-04-30
记录下本人对前后端token处理的理解
2019-04-30
mybatis-plus分页使用
2019-04-30
RedisTemplet和StringRedisTemplet的区别和坑
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310524426 位访客
访问时间: 2024-05-04 05:47:36
访问IP: 3.144.104.29
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版