本文共 3288 字,大约阅读时间需要 10 分钟。
TCP
TCP缓冲区与滑动窗口
-
每个TCP连接都会在内核中建立对应TCP内存缓冲区。
-
进程可以从TCP缓冲区中read/write数据,也可以将TCP缓冲区的数据send到网络传输设备上去。
-
高并发下TCP连接增多,传输数据很多,就会导致buff/cache这个系统内存变得很大。一个TCP连接占用内存4k+,几十万连接就多增加GB级别系统内存消耗。
-
TCP连接的接收方根据自己的TCP缓冲区,计算可接收报文字节大小,即接收窗口。
-
每当TCP连接接收方收到报文后,将报文存放到TCP接收缓冲区,剩余接收缓冲区变小,所以接收窗口也变小。
-
当进程调用read函数从TCP连接的TCP接收缓冲区读取数据后,数据就从内核空间读取到了进程的用户空间,接收缓冲区变大,接收窗口也变大。
-
TCP连接的发送方收到接收方ack响应报文头中的window字段即接收窗口大小后,就会调整自己的发送窗口大小与其保持一致。
-
理论上的最佳效果是TCP发送缓冲区等于带宽时延积。这样发送缓冲区的数据可以按照发送窗口的大小去发送数据包到网络设备上。这样刚好满足网络带宽和时延限制下的最大处理能力。但实际中通常使用缓冲区动态调节功能。不至于让缓冲区一直保持很大,浪费内存。所以不要在socket 网络编程时,通过设置 socket 的 SO_SNDBUF 属性去设定缓冲区的大小。
-
带宽时延积的衡量方式:对网络时延多次取样计算平均值,再乘以带宽。
缓冲区动态调节功能
发送缓冲区自动调整(自动开启):
net.ipv4.tcp_wmem = 4096(动态范围下限) 16384(初始默认值) 4194304(动态范围上限)
一旦发送出的数据被确认,而且没有新的数据要发送,就可以把发送缓冲区的内存释放掉
接收缓冲区自动调整
通过设置net.ipv4.tcp_moderate_rcvbuf = 1开启.
net.ipv4.tcp_rmem = 4096(动态范围下限) 87380(初始默认值) 6291456(动态范围上限)
可以依据空闲系统内存的数量来调节接收窗口。如果系统的空闲内存很多,就可以把缓冲区增大一些,这样传给对方的接收窗口也会变大,因而对方的发送速度就会通过增加飞行报文来提升。反之,内存紧张时就会缩小缓冲区,这虽然会减慢速度,但可以保证更多的并发连接正常工作。
接收缓冲区判断内存空闲的方式:
net.ipv4.tcp_mem = 88560 118080 177120
- 当 TCP 内存小于第 1 个值时,不需要进行自动调节;
- 在第 1 和第 2 个值之间时,内核开始调节接收缓冲区的大小;
- 大于第 3 个值时,内核不再为 TCP 分配新内存,此时新连接是无法建立的。
拥塞控制与慢启动
- 接收主机的处理能力不足时,是通过滑动窗口来减缓对方的发送速度。
- 接收主机的处理能力很强时,也无法通过增加发送方的发送窗口来提升发送速度,因为网络的传输速度是有限的,它会直接丢弃超过其处理能力的报文。 发送方只有在重传RTO时间超时后才会发现报文被丢弃然后重传报文。 解决这个问题办法是拥塞控制。
- TCP慢启动 TCP连接传输中会穿越多层网络并不清楚网络传输能力,所以一开始TCP会调低发送窗口大小,避免发送超过网络传输负载大小的报文。这样以来TCP发送报文速度就会变慢,这就是慢启动。 TCP调低发送窗口(swnd)的大小是通过”拥塞窗口“—congestion window(cwnd)实现的。
- 如果不考虑网络拥塞,发送窗口就等于对方的接收窗口,而考虑了网络拥塞后,发送窗口则应当是拥塞窗口(cwnd)与对方接收窗口(rwnd)的最小值.
swnd = min(cwnd, rwnd)
,即发送速度就综合考虑了接收方和网络的处理能力。
- 通常用 MSS 作为描述窗口大小的单位,其中 MSS 是 TCP 报文的最大长度。虽然窗口的计量单位是字节。
- 拥塞窗口增长原理 假如:初始拥塞窗口只有 1 个 MSS,MSS为1KB,RTT时延为100ms。发送速度=1KB/100ms=10KB/s
– 当没有发生拥塞时,拥塞窗口必须快速扩大,才能提高互联网的传输速度.
– 启动阶段会以指数级扩大拥塞窗口,发送方每收到一个 ACK 确认报文,拥塞窗口就增加 1 倍 MSS,比如最初的初始拥塞窗口(也称为 initcwnd)是 1 个 MSS,经过 4 个 RTT 就会变成 16 个 MSS。
– 互联网中的很多资源体积并不大, 2010 年 Google 对 Web 对象大小的 CDF 累积分布统计,大多数对象在 10KB 左右。
==》当 MSS 是 1KB 时,则多数 HTTP 请求至少包含 10 个报文才能下载完一个文件。以指数级增加拥塞窗口,经过4个RTT之后,才能收到大于10个MSS。– 2013 年 TCP 的初始拥塞窗口调整到了 10 个 MSS,这样下载一个10KB的文件,只需要一个RTT就可以传输10KB的请求。
如果你需要传输的对象体积更大,BDP 带宽时延积很大时,完全可以继续提高初始拥塞窗口的大小– 根据网络状况和传输对象的大小,调整初始拥塞窗口的大小
①ss 命令查看当前拥塞窗口:ss -nli|fgrep cwnd
②ip route change 命令修改初始拥塞窗口
# ip route | while read r; do ip route change $r initcwnd 10; done
慢启动结束的三个场景
慢启动阶段结束场景一(通过定时器明确探测到了丢包)
发送数据后发送方在timeout时间内没有收到ack报文,说明报文丢失,网络拥塞。降低发送速度,即调小拥塞窗口大小,cubic可以将拥塞窗口降低为原先的0.8倍。同时记得设置慢启动阈值为发生网络拥塞之前的拥塞窗口的大小。
慢启动阶段结束场景二(拥塞窗口的增长到达了慢启动阈值 ssthresh):
慢启动阶段,拥塞窗口大小达到了慢启动阈值,很可能出现网络拥塞,为了避免拥塞,拥塞窗口增长速度应当更加保守的使用线性增长,而不是开始的指数增长。线性增长方式时每个RTT增加一个MSS,指数增长方式时每个ACK增加一倍MSS。
慢启动阶段结束场景三(接收到重复的 ACK 报文,可能存在丢包):
如果发送方连续发送多个报文,在慢启动阶段第6个报文丢失。那么接收方就会接下来直接收到发送的第七个报文。接收方收到失序的第7个报文会触发快速重传算法,立刻返回ACK6。以后收到的第8个、第9个报文都会返回ACK6,接收方直接反复的传递ACK6,这样发送方就能明白,报文6丢了,他可以提前重发报文6. 这叫做快速重传!
而不是等待发送方在RTO时间内没收到报文6的ACK响应才重传,那样就太慢了! 在触发快速重传之后,发送方会把慢启动阈值和拥塞窗口都降到之前的一半,进入”快速恢复阶段“。 此时发送方的拥塞窗口会由于接收到重复的ACK6,而增加相应个数的MSS。 发送方明白了报文6丢失之后,立即发送报文6给接收方,接收方这次收到了并给出了正常的响应。 后续不会再重复ACK6的响应了。然后才进入”拥塞避免阶段“(也就是从指数变线程增长)。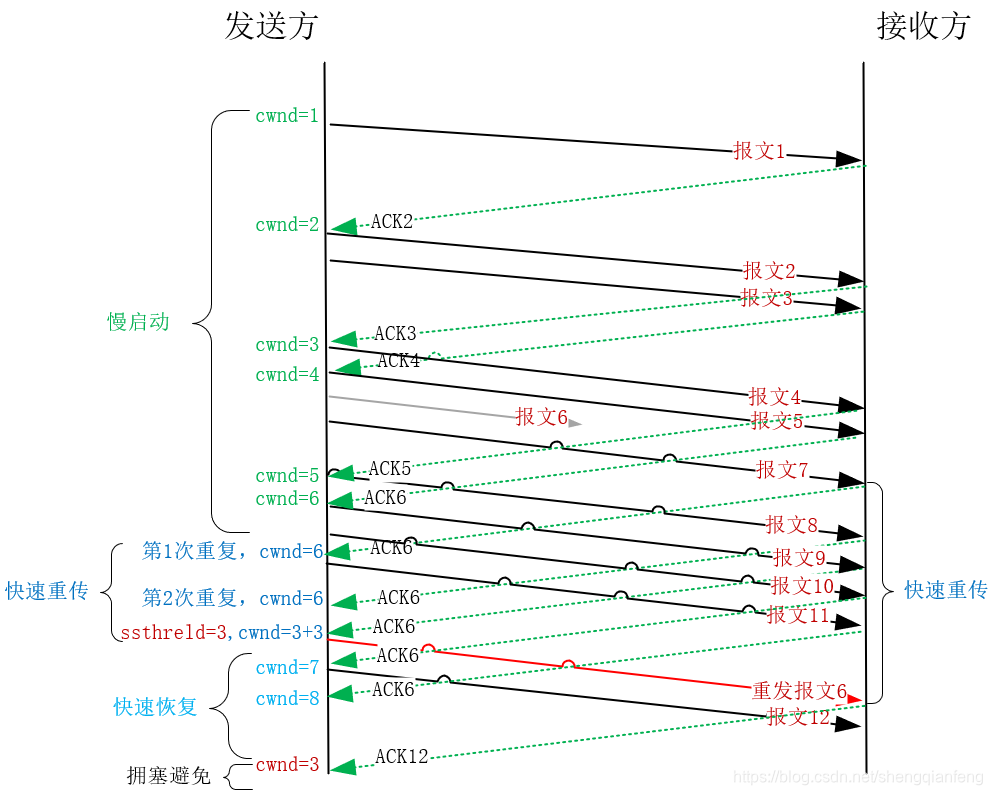
拥塞控制算法
慢启动、拥塞避免、快速重传、快速恢复,共同构成了拥塞控制算法
内核支持的拥塞控制算法列表:net.ipv4.tcp_available_congestion_control = cubic reno
内核选择的拥塞控制算法:
net.ipv4.tcp_congestion_control = cubic
Linux 4.9 版本之后都支持 BBR 算法,是基于测量的拥塞控制算法,开启 BBR 算法仍然使用 tcp_congestion_control 配置:
net.ipv4.tcp_congestion_control=bbr
转载地址:https://jeffsheng.blog.csdn.net/article/details/107379400 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
