本文共 9482 字,大约阅读时间需要 31 分钟。
- 扫描器设计与编程实现(扫描器的设计与实现)
NFA确定化算法设计与编程实现(NFA确定化(选做))- 递归下降分析器设计与实现
(预测分析方法设计与实现)- 算符优先分析法设计与实现(算符优先分析程序设计实现)
目录
一、实验目的
通过设计、编制并调试一个具体的词法分析程序,加深对词法分析原理的理解。掌握在对程序设计语言源程序进行扫描过程中,将其分解为各类单词的词法分析方法。
理解词法分析在编译程序中的作用;加深对有穷自动机模型的理解;掌握词法分析程序的实现方法和技术。
二、实验内容
自定义一种程序设计语言,或者选择已有的一种高级语言,编制它的词法分析程序。词法分析程序的实现可以采用任何一种编程语言和编程工具。
设计词法分析程序,从输入的源程序中,识别出各个具有独立意义的单词,即关键字、标识符、常数、运算符、界符,并依次输出各个单词的内部编码及单词符号自身值(遇到错误时可显示“Error”,然后跳过错误部分继续显示)。
(软件、硬件)环境:
软件环境:Visual Studio Code、CodeBlocks 17.12 编写、调试并执行实验代码
硬件环境:“Windows 10教育版”计算机
三、实验过程与结果
修改课本P212表C.1,将其扩充为C语言的保留字表,如下所示:
char *rwtab[] = {"int", "long", "short", "float", "double", "char", "unsigned", "signed", "const", "void", "volatile", "enum", "struct", "union","if", "else", "goto", "switch", "case", "do", "while", "for", "continue", "break", "return", "default", "typedef","auto", "register", "extern", "static", "sizeof", "begin", "then", "end", "cout", "main", _KEY_WORD_END};
实验代码
参考P212附录C,编写源程序,实验代码如下所示:
/*需要的库和全局变量、函数及主程序*/#include#include #include #include #define _KEY_WORD_END "waiting for your expanding"using namespace std;typedef struct //词的结构,二元组形式(单词种别,单词自身的值){ int typenum; //单词种别 char *word;} WORD;char input[255];char token[255] = "";int p_input; //指针int p_token;char ch;char *rwtab[] = {"int", "long", "short", "float", "double", "char", "unsigned", "signed", "const", "void", "volatile", "enum", "struct", "union", "if", "else", "goto", "switch", "case", "do", "while", "for", "continue", "break", "return", "default", "typedef", "auto", "register", "extern", "static", "sizeof", "begin", "then", "end", "cout", "main", _KEY_WORD_END};WORD *scanner(); //扫描int main(){ int over = 1; WORD *oneword = new WORD; //实现从文件读取代码段 cout << "read something from data.txt" << endl; FILE *fp; if ((fp = freopen("data.txt", "r", stdin)) == NULL) { printf("Not found file!\n"); return 0; } else { while ((scanf("%[^#]s", &input)) != EOF) { p_input = 0; printf("your words:\n%s\n", input); while (over < 1000 && over != -1) { oneword = scanner(); if (oneword->typenum < 1000) { if (oneword->typenum != 999) cout << "[ " << oneword->typenum << "\t" << oneword->word << " ]" << endl; } over = oneword->typenum; } scanf("%[^#]s", input); } } return 0;}//从输入缓冲区读取一个字符到ch中char m_getch(){ ch = input[p_input]; p_input++; // p_input = p_input + 1; return (ch);}//去掉空白符号void getbc(){ while (ch == ' ' || ch == 10) { ch = input[p_input]; p_input++; // p_input = p_input + 1; }}//拼接单词void concat(){ token[p_token] = ch; p_token++; // p_token = p_token + 1; token[p_token] = '\0';}//判断是否字母int letter(){ if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z') return 1; else return 0;}//判断是否数字int digit(){ if (ch >= '0' && ch <= '9') return 1; else return 0;}//检索关键字表格int reserve(){ int i = 0; while (strcmp(rwtab[i], _KEY_WORD_END)) { if (!strcmp(rwtab[i], token)) return i + 1; i++; } return 10; // 如果不是关键字,则返回种别码10}//回退一个字符void retract(){ p_input--; // p_input = p_input - 1;}//词法扫描程序WORD *scanner(){ WORD *myword = new WORD; myword->typenum = 10; // 初始值 myword->word = ""; p_token = 0; //单词缓冲区指针 m_getch(); getbc(); //去掉空白 if (letter()) //判断读取到的首字母是字母 { //如int while (letter() || digit()) { concat(); //连接 m_getch(); } retract(); //回退一个字符 myword->typenum = reserve(); //判断是否为关键字,返回种别码 myword->word = token; return (myword); } else if (digit()) //判断读取到的单词首字符是数字 { while (digit()) //所有数字连接起来 { concat(); m_getch(); } retract(); //数字单词种别码统一为20,单词自身的值为数字本身 myword->typenum = 20; myword->word = token; return (myword); } else switch (ch) { case '=': m_getch(); //首字符为=,再读取下一个字符判断 if (ch == '=') { myword->typenum = 39; myword->word = "=="; return (myword); } retract(); //读取到的下个字符不是=,则要回退,直接输出= myword->typenum = 21; myword->word = "="; return (myword); break; case '+': myword->typenum = 22; myword->word = "+"; return (myword); break; case '-': myword->typenum = 23; myword->word = "-"; return (myword); break; case '/': //读取到该符号之后,要判断下一个字符是什么符号,判断是否为注释 m_getch(); //首字符为/,再读取下一个字符判断 if (ch == '*') // 说明读取到的是注释 { m_getch(); while (ch != '*') { m_getch(); //注释没结束之前一直读取注释,但不输出 if (ch == '*') { m_getch(); if (ch == '/') //注释结束 { myword->typenum = 999; myword->word = "注释"; return (myword); break; } } } } else { retract(); //读取到的下个字符不是*,即不是注释,则要回退,直接输出/ myword->typenum = 25; myword->word = "/"; return (myword); break; } case '*': myword->typenum = 24; myword->word = "*"; return (myword); break; case '(': myword->typenum = 26; myword->word = "("; return (myword); break; case ')': myword->typenum = 27; myword->word = ")"; return (myword); break; case '[': myword->typenum = 28; myword->word = "["; return (myword); break; case ']': myword->typenum = 29; myword->word = "]"; return (myword); break; case '{': myword->typenum = 30; myword->word = "{"; return (myword); break; case '}': myword->typenum = 31; myword->word = "}"; return (myword); break; case ',': myword->typenum = 32; myword->word = ","; return (myword); break; case ':': m_getch(); if (ch == '=') { myword->typenum = 18; myword->word = ":="; return (myword); break; } else { retract(); myword->typenum = 33; myword->word = ":"; return (myword); break; } case ';': myword->typenum = 34; myword->word = ";"; return (myword); break; case '>': m_getch(); if (ch == '=') { myword->typenum = 37; myword->word = ">="; return (myword); break; } retract(); myword->typenum = 35; myword->word = ">"; return (myword); break; case '<': m_getch(); if (ch == '=') { myword->typenum = 38; myword->word = "<="; return (myword); break; } else if (ch == '<') { myword->typenum = 42; myword->word = "<<"; return (myword); break; } else { retract(); myword->typenum = 36; myword->word = "<"; return (myword); } case '!': m_getch(); if (ch == '=') { myword->typenum = 40; myword->word = "!="; return (myword); break; } retract(); myword->typenum = -1; myword->word = "ERROR"; return (myword); break; case ' " ': myword->typenum = 41; myword->word = " \" "; return (myword); break; case '\0': myword->typenum = 1000; myword->word = "OVER"; return (myword); break; case '#': myword->typenum = 0; myword->word = "#"; return (myword); break; default: myword->typenum = -1; myword->word = "ERROR"; return (myword); break; }}
data.txt文件
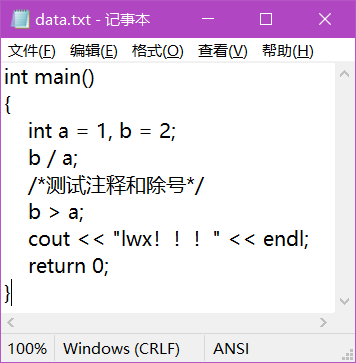
int main(){ int a = 1, b = 2; b / a; /*测试注释和除号*/ b > a; cout << "lwx!!!" << endl; return 0;} data.txt 文件截图:
代码运行截图
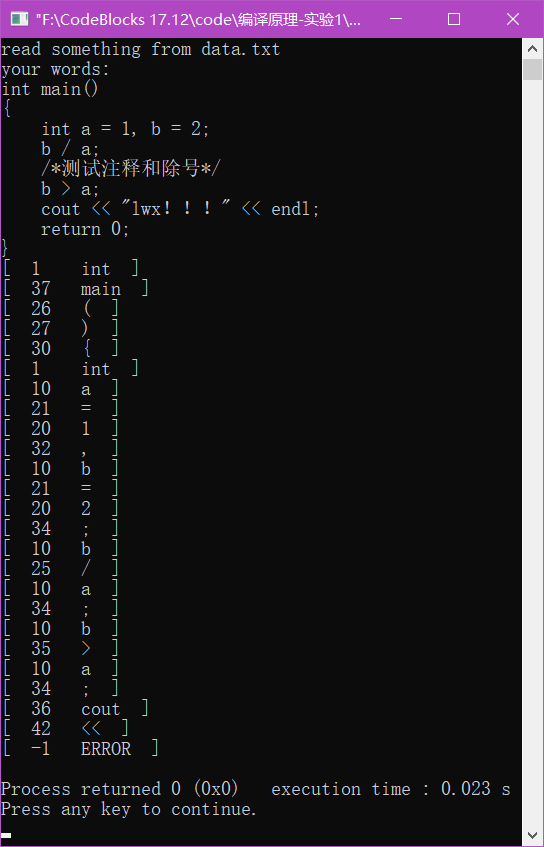
词法分析器,实验运行截图:
四、总结与体会
此次实验,参照课本编写了扫描器的设计,并将其实现。实验过程中,遇到了诸多困难,但都一一解决,加深了我对课本概念的理解,收获甚多。
使用文件操作的方式,从data.txt文件中读入要分析的程序,C语言中的文件操作并不难以实现,使用文件操作可以提升用户的体验感。编程时,将各个基本功能用函数来实现,使得程序的条理性增强了;全局变量的使用也使得数据在函数间的传递更加方便。
本次实验结合书本上的理论知识,我进一步了解词法分析程序构造的一些细节。在实验中,发现了自身的许多不足,课下我会多加努力。
转载地址:https://blog.csdn.net/weixin_44949135/article/details/116103074 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
