爬虫:Python爬虫学习笔记之网页解析基础——爬取360导航栏目
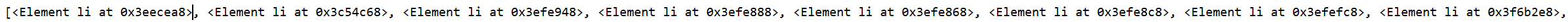 定位第一个li
定位第一个li  取出第一个文本
取出第一个文本 

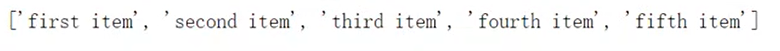
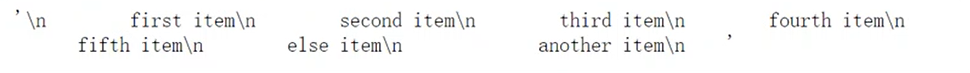 可以对其进行后续操作:
可以对其进行后续操作: 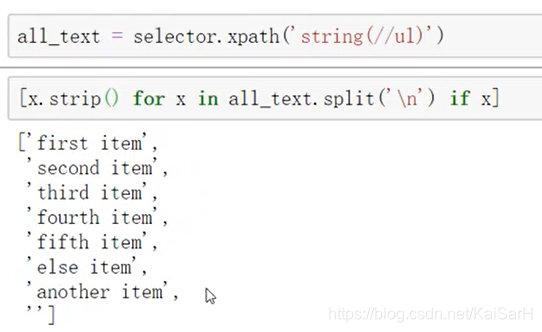
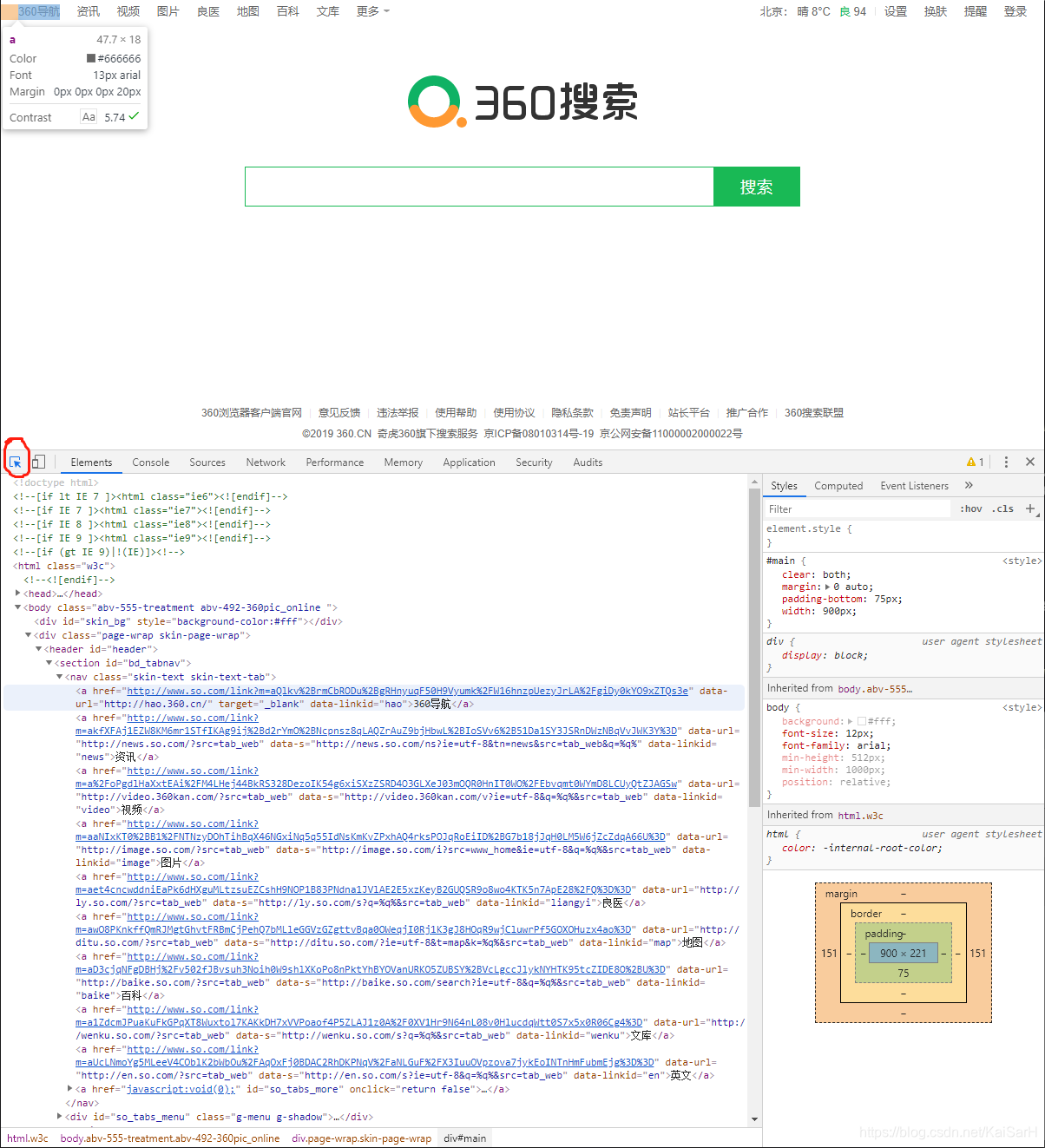
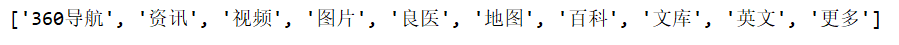 爬出所有导航栏及其对应网址
爬出所有导航栏及其对应网址 
发布日期:2021-06-30 15:42:07
浏览次数:2
分类:技术文章
本文共 4719 字,大约阅读时间需要 15 分钟。
本文是我在使用网易云课堂学习日月光华老师讲的“Python爬虫零基础入门到进阶实战”课程所做的笔记,如果大家觉得不错,可以去看一下老师的视频课,讲的还是很棒的。
认识HTML源码
HTML是一种超文本标记语言,简单理解就是为某些字句加上标志的语言,从而实现预期的特定效果。
HTL的语法格式分为嵌套与非嵌套两类,嵌套格式为<标记>…</标记>,非嵌套仅有<标记>。此外,根据标记的不同,有的标记附带有属性参数,则表示为<标记 属性=“参数值”>。常见网页解析工具
- LXML
- Beautfulsoup
- 正则表达式
Xpath语法与lxml库的用法
lxml是一个网页解析库。XPath是一门在XML文档中查找信息的语言。XPath可用来在XML文档中对元素和属性进行遍历。
安装:pip install lxml XPath查找的方法:一层一层按标签查找元素。使用路径查找元素
有用的路径表达式:
| 路径 | 含义 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从根节点开始匹配,而不考虑它们的位置,如果某些元素唯一,可以利用其唯一性忽略 |
| /text() | 选取文本 |
| @ | 选取属性 |
import requests# 在解析源码的时候主要使用etreefrom lxml import etree# 获取网页源代码response = requests.get('https://www.douban.com')# 构造选择器selector = etree.HTML(response.text)# 查找某一元素 查找所有的liall_li = selector.xpath('//div/ul/li')print(all_li) 执行结果:
定位第一个li li1 = selector.xpath('//div/ul/li[1]') 取出第一个li下的a中的文本
li1_text= selector.xpath('//div/ul/li[1]/a/text()') 执行结果:
取出第一个文本 li1_text= selector.xpath('//div/ul/li[1]/a/text()')[0] 执行结果
使用属性查找元素
从根目录开始查找,class属性值为class_id的li
li_3 = selector.xpath('//li[@class="class_name"]') 通过属性获取文本
li_3 = selector.xpath('//li[@class="class_name"]/a/text()') 从根节点开始查找,查找任何节点,只要class=class_id
li_3 = selector.xpath('//*[@class="class_name"]') 提取属性值
写法:@属性名
获取第二个li中a的属性href的值selector.xpath('//li[2]/a/@href') 取出某种标签所有的li属性class的值
selector.xpath('//li/@class') xpath的嵌套使用
如果第一次xpath查询出来的是一个代码段,可以在第一次查询结果的基础上,继续使用xpath。再次使用时候,要使用相对路径。
li_4 = selector.xpath('//li[4]')[0]# 路径为相对路径li_4.xpath('a/text()') 
pxath高级用法
如何找出有某一个属性的的共同元素
例如:百度搜索首页导航栏中,"更多"是由JavaScript动态生成的。如何将"更多"排除在爬取结果之外?
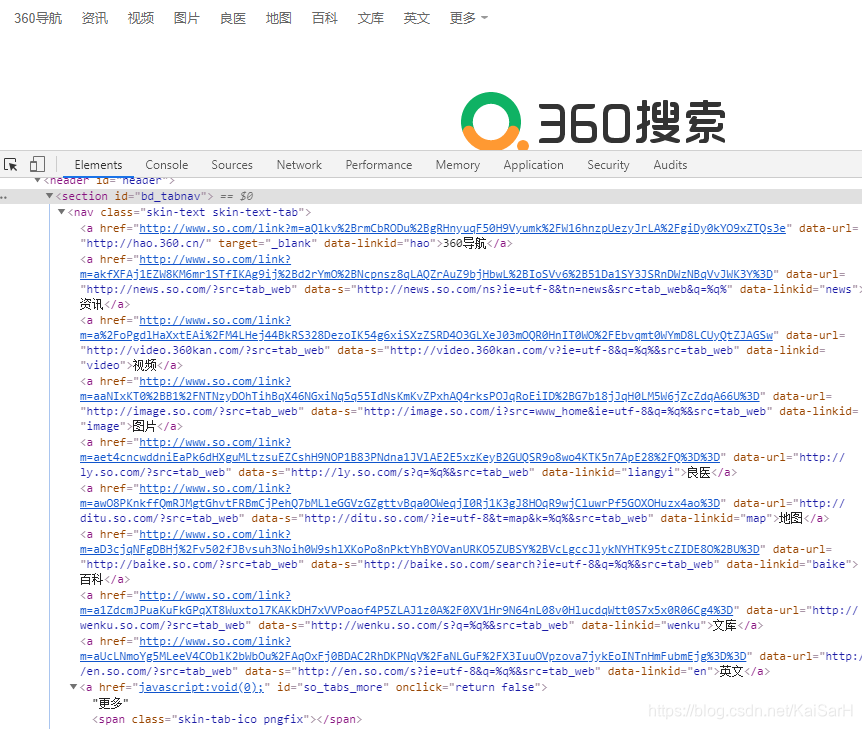
import requestsfrom lxml import etreeurl = 'https://www.so.com'headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}response = requests.get(url, headers=headers)selector = etree.HTML(response.text)title_list = selector.xpath('//*[@id="bd_tabnav"]/nav/a[@data-linkid]/text()')print(title_list) 执行结果图:
找出某个属性名有共同部分的元素
例如,在下图中,构造的htm中,前五个li元素的class属性中都有item-,而第六个li元素没有。如何取出前五个?

import requestsfrom lxml import etreeselector = etree.HTML(htm)selector.xpath('//li[start-with(@class,"item-")]/a/text()') 执行效果图:
找出某个元素所有文本
在下图中,构造的htm中,如何爬取所有文本?

import requestsfrom lxml import etreeselector = etree.HTML(htm)#selector.xpath('string(//div)')selector.xpath('string(//ul)') 执行结果图:
可以对其进行后续操作: 案例:爬取360导航栏目
使用谷歌浏览器Chrome帮助爬取。定位元素。
为了应对反爬虫,要在url中加入headers。 在chrome浏览器中,按F12可以查看界面代码。 使用红色标志部分可以查看对应元素HTML源码。定位元素所在位置。 自己写xpath
善用属性唯一性可以大大简化xpath的长度。
import requests# 在解析源码的时候主要使用etreefrom lxml import etreeurl = 'https://www.so.com'# headers 以字典的形式提交给url 用于应对反爬虫headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}response = requests.get(url, headers=headers)# 可以使用response.status_code# 或者response.status_code == requests.codes.ok# 判断请求是否成功# print(response.status_code == requests.codes.ok)# 建立选择器selector = etree.HTML(response.text)# 从根目录开始查找 较为复杂# 取出360导航名称# a_1 = selector.xpath('//body/div[2]/header/section/nav/a[1]/text()')[0]# 取出360导航的href即url跳转网址 使用属性区分平行元素# a_1_url = selector.xpath('//body/div[@class="page-wrap skin-page-wrap"]/header/section/nav/a[1]/@href')[0]# 根据属性唯一性查找a_1_url = selector.xpath('//*[@class="skin-text skin-text-tab"]/a[1]/text()'[0]print(a_1_url) 使用chrome浏览器
F12进入Elements,选择要查找的元素对应的源代码,右键,Copy,Copy XPath.
取出全部标签或url
不指定a的下标
import requests# 在解析源码的时候主要使用etreefrom lxml import etreeurl = 'https://www.so.com'# headers 以字典的形式提交给url 用于应对反爬虫headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}response = requests.get(url, headers=headers)# 可以使用response.status_code# 或者response.status_code == requests.codes.ok# 判断请求是否成功# print(response.status_code == requests.codes.ok)# 建立选择器selector = etree.HTML(response.text)a_1_url = selector.xpath('//*[@id="bd_tabnav"]/nav/a/text()')print(a_1_url) 执行效果:
爬出所有导航栏及其对应网址 import requests# 在解析源码的时候主要使用etreefrom lxml import etreeurl = 'https://www.so.com'# headers 以字典的形式提交给url 用于应对反爬虫headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'}response = requests.get(url, headers=headers)# 可以使用response.status_code# 或者response.status_code == requests.codes.ok# 判断请求是否成功# print(response.status_code == requests.codes.ok)# 建立选择器selector = etree.HTML(response.text)title_list = selector.xpath('//*[@id="bd_tabnav"]/nav/a/text()')href_list = selector.xpath('//*[@id="bd_tabnav"]/nav/a/@href')print(title_list)for title, url in zip(title_list, href_list): print(title, url) 执行效果图:
转载地址:https://kaisarh.blog.csdn.net/article/details/102925955 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年04月14日 02时46分19秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
机器学习-评价分类、回归算法模型指标
2021-07-04
Azkaban体系结构
2021-07-04
Azkaban2.5环境搭建及测试
2021-07-04
Synchronized与ReentrantLock区别
2021-07-04
机器学习之重头戏-特征预处理
2021-07-04
synchronized底层实现及锁的升级、降级
2021-07-04
Java线程生命周期之旅
2021-07-04
机器学习-简单逻辑回归实现
2021-07-04
如何快速定位JVM相关GC问题
2021-07-04
java线程相关概念之解析
2021-07-04
Python清洗常用工具
2021-07-04
java内存模型及线程案例分析
2021-07-04
小议创建线程的若干方式
2021-07-04
ThreadLocal应用场景分析
2021-07-04
线程池原理及应用之个人心得
2021-07-04
线程池excute方法执行底层过程
2021-07-04
线程池同步异步调用callable和Future
2021-07-04
梯度算法之初见
2021-07-04
解决python安装库较慢的方式
2021-07-04
Maven安装问题总结
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311334612 位访客
访问时间: 2024-05-06 09:43:55
访问IP: 18.221.13.173
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版