本文共 2229 字,大约阅读时间需要 7 分钟。
目录
一、从网络上下载或者自己找到的图片中裁剪挑选出合适的图片。
图片的大小和格式都要相同,准备好两个文件夹,分别命名为posdata(正样本)和negdata(负样本),所有样本的尺寸必须一致,如果不一致的或者尺寸较大的,可以先将所有样本统一缩放到100*40。posdata中的图片为车辆样本。给分类器展示的是正确的样本。

negdata中的图片为一些背景样本,里面不包含车辆,是用来告诉分类器哪些是错误的样本。虽然负样本就是样本中不存在正样本的内容,但最好是根据不同的项目选择不同的负样本,比如一个项目是做机场的人脸检测,那么就最好从现场拍摄一些图片数据回来,从中采集负样本。

二、在negdata和posdata文件夹准备好之后,使用命令提示符(win + r),输入cmd,把位置切换到posdata文件夹的位置。

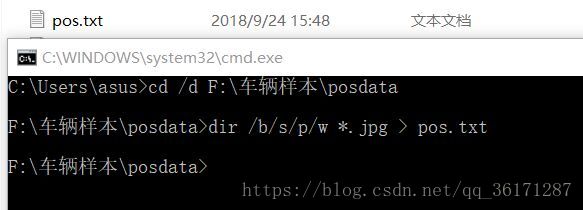
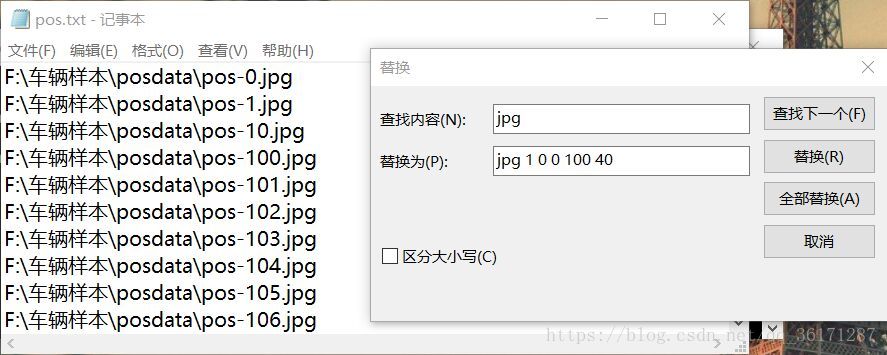
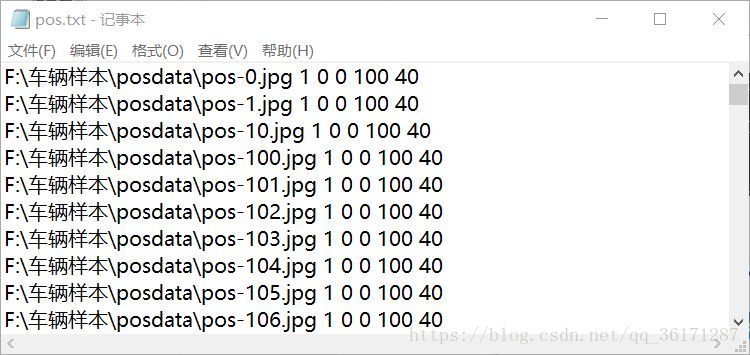
然后在里面输入“ dir /b/s/p/w *.jpg > pos.txt ”,将会在posdata文件夹中产生一个pos.txt的文档。打开pos.txt,选择编辑-替换,在查找中搜索jpg,替换为jpg 1 0 0 100 40,之后保存,将pos.txt复制到上一级目录中。
之后对negdata文件夹进行相同的操作,在cmd中输入的语句为“ dir /b/s/p/w *.jpg > neg.txt ”。
三、找到自己下载的OpenCV文件夹,打开opencv,打开build,打开x64,打开vc14,打开bin文件夹。

选择opencv_createsamples.exe和opencv_traincascade.exe两项,将其复制到需要的文件夹中,与negdata、posdata并列。
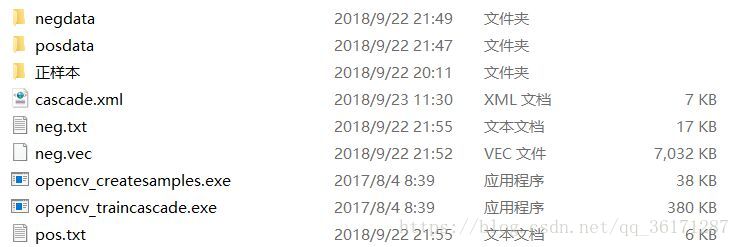
四、打开cmd,在该文件目录下输入“ opencv_createsamples.exe -vec pos.vec -info pos.txt -num 32 -w 100 -h 40 ” 。
pos.txt 表明这是正样本;
num 32 代表正样本照片数量;
w 100 h40表示图片分辨率(宽和高)
之后在该文件夹中会出现pos.vec

之后重复该步骤,cmd输入的语句换为“ opencv_createsamples.exe -vec neg.vec -info neg.txt -num 100 -w 100 -h 40 ”,产生neg.vec。
五、在主文件夹下创建一个txt文档,命名为“traincascade”。
在该txt中输入“
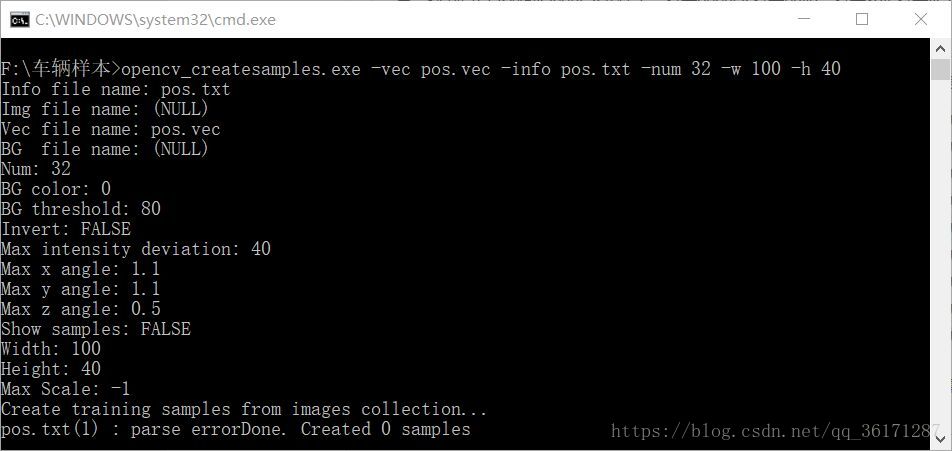
opencv_traincascade.exe -data xml -vec pos.vec -bg neg.txt -numPos 32 -numNeg 100 -numStages 20 -w 100 -h 40 -mode ALL
pause”
numPos 32 代表正样本照片数量 numNeg100 表示负样本照片数量 numStage 20表示检测次数 pause为暂停
对“traincascade.txt”进行重命名,将后缀名改为bat。

之后双击“traincascade.bat”。会产生如下效果
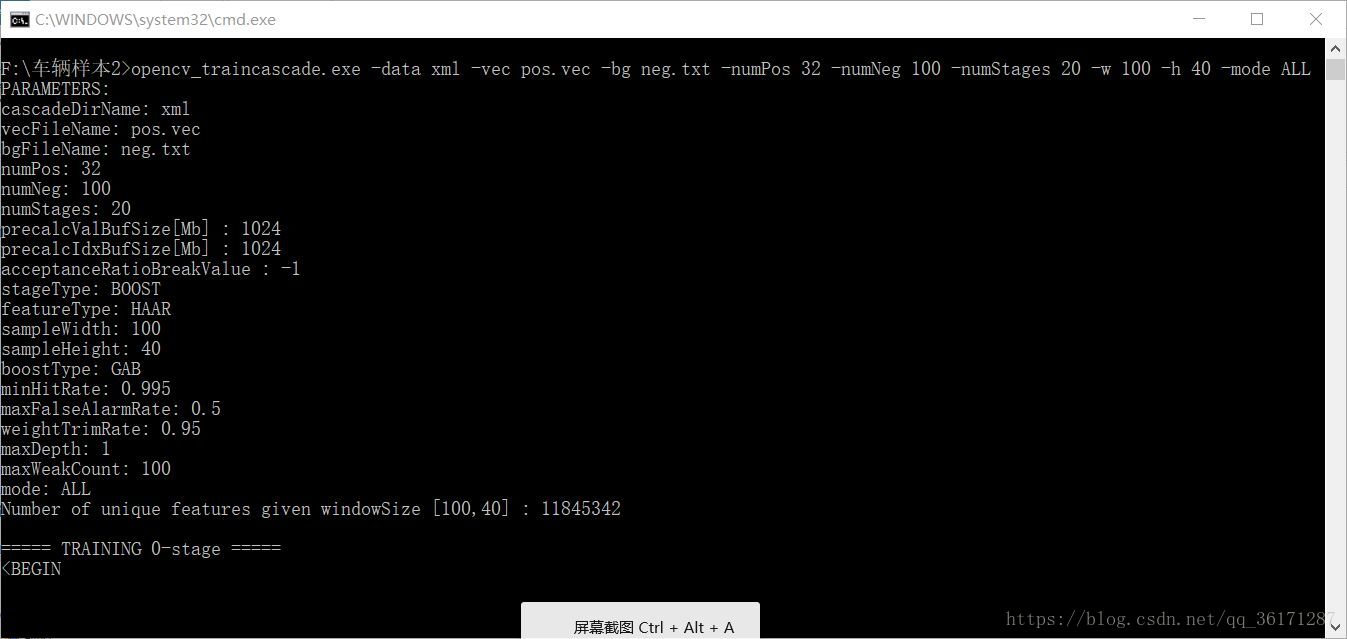
训练分类器时占用CPU空间多,电脑运行将会变卡,处理时间较长。处理完成之后将会在文件夹下生成一个cascade.xml。

六、 之后可以运行VS,新建一个VC++项目。输入一下代码之后进行测试。
代码为:
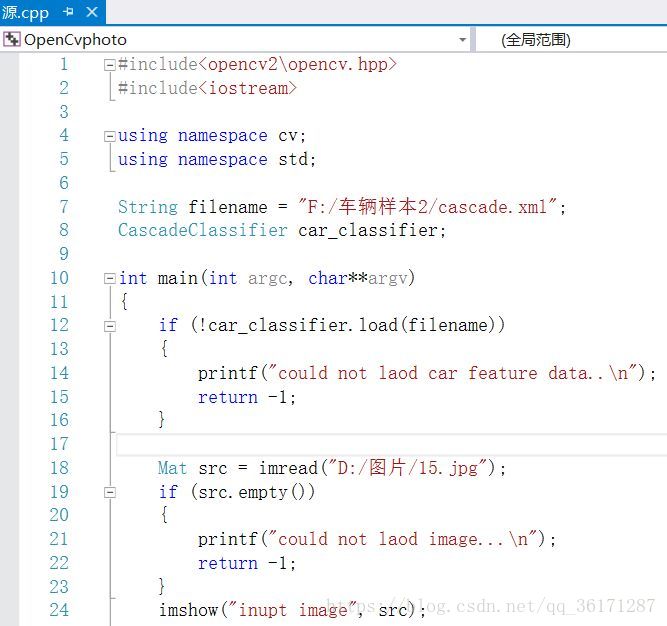
#include<opencv2\opencv.hpp>
#include<iostream>using namespace cv;
using namespace std;String filename = "F:/车辆样本2/cascade.xml"; //之前cascade.xml放置的位置
CascadeClassifier car_classifier;int main(int argc, char**argv)
{ if (!car_classifier.load(filename)) { printf("could not laod car feature data..\n"); return -1; }Mat src = imread("D:/图片/15.jpg"); //需要检测的图片
if (src.empty()) { printf("could not laod image...\n"); return -1; } imshow("inupt image", src); Mat gray; cvtColor(src, gray, COLOR_BGR2GRAY); equalizeHist(gray, gray);vector<Rect>cars;
car_classifier.detectMultiScale(gray, cars, 1.1, 3, 0, Size(50, 50)); for (size_t t = 0; t < cars.size(); t++) { rectangle(src, cars[static_cast<int>(t)], Scalar(0, 0, 255), 2, 8, 0); }imshow("detect cars", src);
waitKey(0); return 0;}
之后点击运行,因为设置的正负样本过少的原因,效果不是很明显。出现效果如下:

转载地址:https://kongchengji.blog.csdn.net/article/details/82828961 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
