本文共 4503 字,大约阅读时间需要 15 分钟。
目录
正则表达式
排列
排列组合是组合学最基本的概念。所谓排列,就是指从给定个数的元素中取出指定个数的元素进行排序。组合则是指从给定个数的元素中仅仅取出指定个数的元素,不考虑排序。排列组合的中心问题是研究给定要求的排列和组合可能出现的情况总数。 排列组合与古典关系密切。
排列,一般地,从n个不同元素中取出m(m≤n)个元素,按照一定的顺序排成一列,叫做从n个元素中取出m个元素的一个排列(permutation)。特别地,当m=n时,这个排列被称作全排列(all permutation)。
用代码生成排列
例子:在[1,2,3,4]中挑出3个数组成一个序列的可能性permutations
4 - 3 :24
4 - 2 :12
4 - 1 :4
排列的可能性次数:n! / (n - m)!
#itertools:将可迭代对象生成迭代器import itertoolslist1 = list(itertools.permutations([1,2,3,4],3))print(list1)print(len(list1))
运行结果:

例子:不重复的组合combinations
4 - 4 :1
4 - 3 :4
4 - 2 :6
4 - 1 :4
排列的可能性次数:n! / m!*(n-m)!
#itertools:将可迭代对象生成迭代器import itertoolslist1 = list(itertools.combinations([1,2,3,4],3))print(list1)print(len(list1))
运行结果:

例子:生成密码可能性
import itertoolslist1 = list(itertools.product([1,2,3,4],repeat=3))print(list1)print(len(list1))
运行结果:

例子:疯狂破解密码
import itertoolsimport time#生成迭代器passwdpasswd = (''.join(x) for x in itertools.product('0123456789',repeat=3))while True: try: time.sleep(0.5) str = next(passwd) print(str) except StopIteration as e: break 运行结果:

正则概述
python自1.5之后增加了re模块,提供了正则表达式模式
re模块使python语音拥有了全部的正则表达式功能
re.match函数原型:match(pattern,string,flags=0)参数:patter--匹配的正则表达式 string--要匹配的字符串 flags--标志位,用于控制正则表达式的匹配方式flags:re.I 忽略大小写 re.L 做本地用户识别 re.M 多行匹配,影响^和$ re.S 是.匹配包括换行符在内的所有字符 re.U 根据Unicode字符集解析字符,影响\w \W \b \B re.X 使我们以更灵活的格式理解正则表达式 功能:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,返回None
print(re.match('www','www.baidu,com'))print(re.match('www','wWW.baidu.',flags=re.I)) 运行结果:

re.search原型:search(pattern,string,flags=0)参数:patter--匹配的正则表达式 string--要匹配的字符串 flags--标志位,用于控制正则表达式的匹配方式功能:扫描整个字符串,并返回第一个匹配成功的
print(re.search('www','baidu.www.com.www')) 运行结果:

re.findall函数原型:findall(pattern,string,flags=0)参数:patter--匹配的正则表达式 string--要匹配的字符串 flags--标志位,用于控制正则表达式的匹配方式功能:扫描整个字符串,返回结果列表
print(re.findall('www','baidu.www.com.www')) 运行结果:

正则表达式的元字符
匹配单个字符与数字
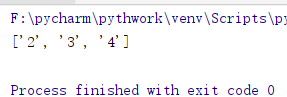
[0123456789] []是字符集合,表示匹配方括号中所包含的任意一个字符 [a-z] 匹配任意小写字母 [A-Z] 匹配任意大写字母 [0-9] 匹配任意数字 [0-9a-z-A-Z] 匹配任意的数字和字母 [0-9a-z-A-Z_] 匹配任意的数字和字母和下划线 [^goodman] 匹配除了goodman这几个字母以外的所有字符,^被称为脱字符,表示不匹配集合中的字符 . 匹配除换行符以外的任意字符 \d 匹配所有数字,效果同[0-9] \D 匹配非数字字符,效果等同于[^0-9] \w 匹配任意的数字和字母和下划线,效果等同于[0-9a-z-A-Z_] \W 匹配任意的非数字和字母和下划线,效果等同于[^0-9a-z-A-Z_] \s 匹配任意的空白符(空格,换行,换页,回车,制表)print(re.findall('[0-9]','a2hij3agi af4ja')) 运行结果:
^ 行首匹配,和在[]里的^不是一个意思$ 行尾匹配
print(re.search('man$','zhe ge ren is man a good man')) 运行结果:

匹配多个字符
(xyz)
说明:x,y,z均为假设的普通字符,不是正则表达式的元字符(xyz) 匹配小括号内的xyz是作为一个整体去匹配 x? 匹配0个或者1个x x* 匹配0个或者任意多个x x+ 匹配至少一个a x{n} 匹配确定的n个x(n是一个非负整数) x{n,} 匹配至少n个x x{n,m} 匹配至少n个最多m个x,注意:n <= m x|y |表示或,匹配的是x或y (?:x) 类似xyz,但不表示一个组
print(re.search('(good)','zhe ge ren is man a goodman'))print(re.findall(r'a?',' aa a')) #非贪婪匹配print(re.findall(r'a*',' aabbab')) #贪婪匹配(尽可能多的匹配)print(re.findall(r'a+','aabaaaaa')) #贪婪匹配(尽可能多的匹配)print(re.findall(r'a{3}','aabaaaaa'))print(re.findall(r'a{3,}','aabaaaaa'))#提取,ok......verystr = 'this is ok good man ,but he is very eee'print(re.findall(r'ok.*very',str))print(re.findall(r'//*.*?/*/',r'/* part1 */ /* part2 */')) 运行结果:

re模块深入
字符串切割
str1 = 'zk is a boy and ...'print(str1.split(' '))print(re.split(r' +',str1)) 运行结果:

re.finditer函数
原型:match(pattern,string,flags=0)
参数:patter--匹配的正则表达式 string--要匹配的字符串 flags--标志位,用于控制正则表达式的匹配方式 功能:与findall类似,扫描整个字符串,返回的是一个迭代器例子:
str1 = 'wo is a good man,wo is a good man,wo is a good man,wo is a good man,'d = re.finditer(r'(wo)',str1)while True: try: print(next(d)) except StopIteration as e: break
运行结果:

字符串的替换和修改
sub(pattern,repl,string,count=0)
subn(pattern,repl,string,count=0) pattern:正则表达式(规则) repl:指定的用来替换的字符串 string:目标字符串 count:最多替换次数 功能:在目标字符串中以正则表达式的规则匹配字符串,再把他们替换成指定的字符串。可以指定替换的次数,如果不指定,替换所有的匹配字符串 区别:sub返回一个被替换的字符串,subn返回一个元组,第一个元素被替换的字符串,第二个元素表示被替换的次数例子:
str1 = 'good good good'print(re.sub(r'good','nice',str1,count=2))print(re.subn(r'good','nice',str1,count=2))
运行结果:

分组
概念:除了简单的判断是否匹配之外,正则表达式还有提取字串的功能。用()表示的就是提取分组
例子:
str1 = '010-535678995'l = re.match(r'(\d{3})-(\d{9})',str1)#使用序号获取对应组的信息print(l.group(0))print(l.group(1))print(l.group(2))#查看匹配的各组的情况print(l.groups()) 运行结果:

例子:
str1 = '010-535678995'l = re.match(r'(?P\d{3})-(?P \d{9})',str1)#使用序号获取对应组的信息print(l.group(0))print(l.group('first'))print(l.group('last'))
运行结果:

编译
编译:当我们使用正则表达式时,re模块会干两件事
1、编译正则表达式,如果正则表达式本身不合法,会报错 2、用编译后的正则表达式去匹配对象 compile(pattern,flags=0) pattern:要编译的正则表达式例子:
pat = r'^1(([3578]\d)|(47))\d{8}$'print(re.match(pat,'13645000000'))#编译成正则对象re_telephone = re.compile(pat)print(re_telephone.match('13645000000')) 运行结果:

一起学习,一起进步 -.- ,如有错误,可以发评论
转载地址:https://kongchengji.blog.csdn.net/article/details/95322724 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
