本文共 14254 字,大约阅读时间需要 47 分钟。
成富是著名的Java专家,在IBM技术网站发表很多Java好文,也有著作。
线程上下文类加载器
线程上下文类加载器(context class loader)是从 JDK 1.2 开始引入的。类 java.lang.Thread中的方法 getContextClassLoader()和 setContextClassLoader(ClassLoader cl)用来获取和设置线程的上下文类加载器。如果没有通过 setContextClassLoader(ClassLoader cl)方法进行设置的话,线程将继承其父线程的上下文类加载器。Java 应用运行的初始线程的上下文类加载器是系统类加载器。在线程中运行的代码可以通过此类加载器来加载类和资源。
前面提到的类加载器的代理模式并不能解决 Java 应用开发中会遇到的类加载器的全部问题。Java 提供了很多服务提供者接口(Service Provider Interface,SPI),允许第三方为这些接口提供实现。常见的 SPI 有 JDBC、JCE、JNDI、JAXP 和 JBI 等。这些 SPI 的接口由 Java 核心库来提供,如 JAXP 的 SPI 接口定义包含在 javax.xml.parsers包中。这些 SPI 的实现代码很可能是作为 Java 应用所依赖的 jar 包被包含进来,可以通过类路径(CLASSPATH)来找到,如实现了 JAXP SPI 的 所包含的 jar 包。SPI 接口中的代码经常需要加载具体的实现类。如 JAXP 中的 javax.xml.parsers.DocumentBuilderFactory类中的 newInstance()方法用来生成一个新的 DocumentBuilderFactory的实例。这里的实例的真正的类是继承自 javax.xml.parsers.DocumentBuilderFactory,由 SPI 的实现所提供的。如在 Apache Xerces 中,实现的类是 org.apache.xerces.jaxp.DocumentBuilderFactoryImpl。而问题在于,SPI 的接口是 Java 核心库的一部分,是由引导类加载器来加载的;SPI 实现的 Java 类一般是由系统类加载器来加载的。引导类加载器是无法找到 SPI 的实现类的,因为它只加载 Java 的核心库。它也不能代理给系统类加载器,因为它是系统类加载器的祖先类加载器。也就是说,类加载器的代理模式无法解决这个问题。
线程上下文类加载器正好解决了这个问题。如果不做任何的设置,Java 应用的线程的上下文类加载器默认就是系统上下文类加载器。在 SPI 接口的代码中使用线程上下文类加载器,就可以成功的加载到 SPI 实现的类。线程上下文类加载器在很多 SPI 的实现中都会用到。
译文:
原文:
Q:我什么时候该用Thread.getContextClassLoader()?
当动态加载一个资源时,至少有三种类加载器可供选择: 系统类加载器(也被称为应用类加载器)(system classloader),当前类加载器(current classloader),和当前线程的上下文类加载器( the current thread context classloader)。上面提到的问题指的是最后一种加载器。
容易排除的一个选择:系统类加载器。这个类加载器处理classpath环境变量所指定的路径下的类和资源,可以通过ClassLoader.getSystemClassLoader()方法以编程式访问。所有的ClassLoader.getSystemXXX()API方法也是通过这个类加载器访问。
当前类加载器加载和定义当前方法所属的那个类。这个类加载器在你使用带单个参数的Class.forName()方法,Class.getResource()方法和相似方法时会在运行时类的链接过程中被隐式调用。
线程上下文类加载器是在J2SE中被引进的。每一个线程分配一个上下文类加载器(除非线程由本地代码创建)。该加载器是通过Thread.setContextClassLoader()方法来设置。如果你在线程构造后不调用这个方法,这个线程将会从它的父线程中继承上下文类加载器。如果你在整个应用中不做任何设置,所有线程将以系统类加载器作为它们自己的上下文加载器。重要的是明白自从Web和J2EE应用服务器为了像JNDI,线程池,组件热部署等特性而采用复杂的类加载器层次结构后,这是很少见的情况。
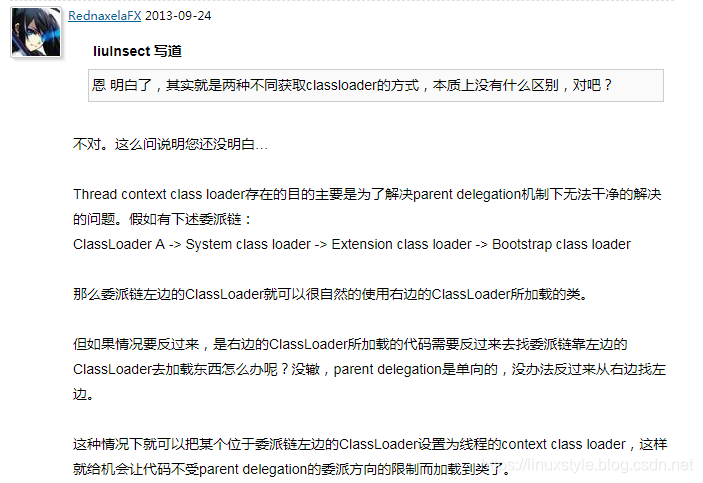
上下文类加载器提供了一个后门绕过在J2SE中介绍的类的加载委托机制。通常情况下,一个JVM中的所有类加载器被组织成一个层次结构,使得每一个类加载器(除了启动整个JVM的原始类加载器)都有一个父加载器。当被要求加载一个类时,每一个类加载器都将先委托父加载器来加载,只有父加载器都不能成功加载时当前类加载器才会加载。
有时这种加载顺序不能正常工作,通常发生在有些JVM核心代码必须动态加载由应用程序开发人员提供的资源时。以JNDI举例:它的核心内容(从J2SE1.3开始)在rt.jar中的引导类中实现了,但是这些JNDI核心类可能加载由独立厂商实现和部署在应用程序的classpath中的JNDI提供者。这个场景要求一个父类加载器(这个例子中的原始类加载器,即加载rt.jar的加载器)去加载一个在它的子类加载器(系统类加载器)中可见的类。此时通常的J2SE委托机制不能工作,解决办法是让JNDI核心类使用线程上下文加载器,从而有效建立一条与类加载器层次结构相反方向的“通道”达到正确的委托。
SPI机制
JavaSPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。具体而言:
STEP1. 定义一组接口, 假设是 autocomplete.PrefixMatcher;
STEP2. 写出接口的一个或多个实现(autocomplete.EffectiveWordMatcher, autocomplete.SimpleWordMatcher);
STEP3. 在 src/main/resources/ 下建立 /META-INF/services 目录, 新增一个以接口命名的文件 autocomplete.PrefixMatcher, 内容是要应用的实现类(autocomplete.EffectiveWordMatcher 或 autocomplete.SimpleWordMatcher 或两者);
STEP4. 使用 ServiceLoader 来加载配置文件中指定的实现。
SPI 的应用之一是可替换的插件机制。比如查看 JDBC 数据库驱动包,mysql-connector-java-5.1.18.jar 就有一个 /META-INF/services/java.sql.Driver 里面内容是 com.mysql.jdbc.Driver 。
package org.foo.demo;public interface IShout { void shout();} package org.foo.demo;import java.util.ServiceLoader;public class SPIMain { public static void main(String[] args) { ServiceLoader shouts = ServiceLoader.load(IShout.class); for (IShout s : shouts) { s.shout(); } System.out.println("Thread "+Thread.currentThread().getName()+" classloader: "+Thread.currentThread().getContextClassLoader().toString()); }} package org.foo.demo.animal;import org.foo.demo.IShout;public class Cat implements IShout { @Override public void shout() { System.out.println("喵喵"); System.out.println("Thread "+Thread.currentThread().getName()+" classloader: "+Thread.currentThread().getContextClassLoader().toString()); }} package org.foo.demo.animal;import org.foo.demo.IShout;public class Dog implements IShout { @Override public void shout() { System.out.println("旺旺"); System.out.println("Thread "+Thread.currentThread().getName()+" classloader: "+Thread.currentThread().getContextClassLoader().toString()); }} 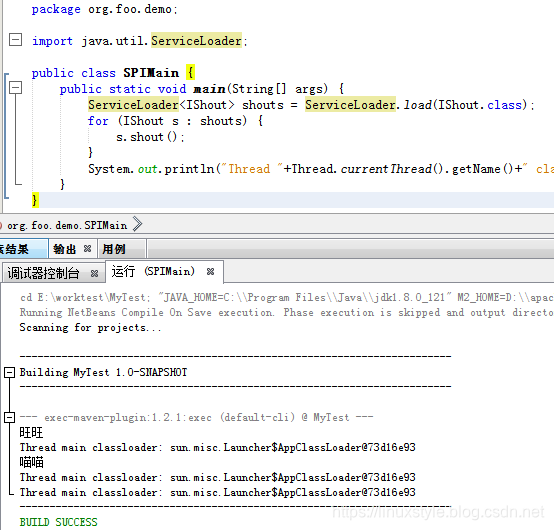
《》
优点:
使用Java SPI机制的优势是实现解耦,使得第三方服务模块的装配控制的逻辑与调用者的业务代码分离,而不是耦合在一起。应用程序可以根据实际业务情况启用框架扩展或替换框架组件。缺点:
- 虽然ServiceLoader也算是使用的延迟加载,但是基本只能通过遍历全部获取,也就是接口的实现类全部加载并实例化一遍。如果你并不想用某些实现类,它也被加载并实例化了,这就造成了浪费。获取某个实现类的方式不够灵活,只能通过Iterator形式获取,不能根据某个参数来获取对应的实现类。
- 多个并发多线程使用ServiceLoader类的实例是不安全的。
---------------------------------------------
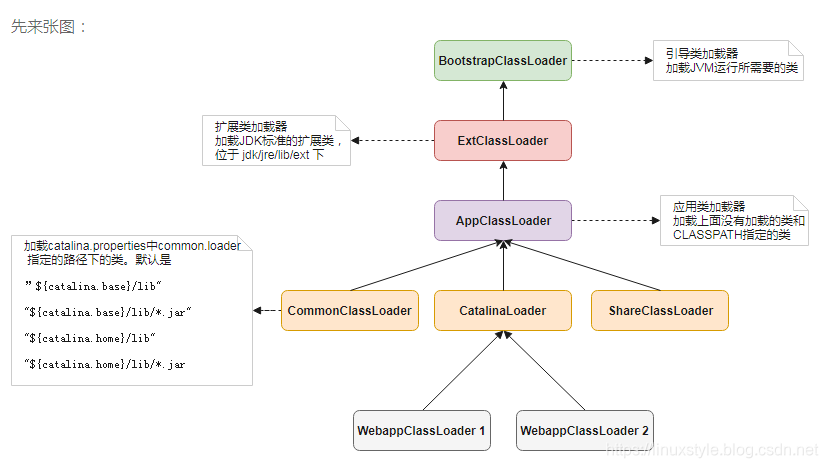
Tomcat的类加载机制是违反了双亲委托原则的,对于一些未加载的非基础类(Object,String等),各个web应用自己的类加载器(WebAppClassLoader)会优先加载,加载不到时再交给commonClassLoader走双亲委托。
对于JVM来说:
因此,按照这个过程可以想到,如果同样在CLASSPATH指定的目录中和自己工作目录中存放相同的class,会优先加载CLASSPATH目录中的文件。
1、既然 Tomcat 不遵循双亲委派机制,那么如果我自己定义一个恶意的HashMap,会不会有风险呢?
答: 显然不会有风险,如果有,Tomcat都运行这么多年了,那群Tomcat大神能不改进吗? tomcat不遵循双亲委派机制,只是自定义的classLoader顺序不同,但顶层还是相同的,
还是要去顶层请求classloader.
2、我们思考一下:Tomcat是个web容器, 那么它要解决什么问题:
1. 一个web容器可能需要部署两个应用程序,不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求同一个类库在同一个服务器只有一份,因此要保证每个应用程序的类库都是独立的,保证相互隔离。 2. 部署在同一个web容器中相同的类库相同的版本可以共享。否则,如果服务器有10个应用程序,那么要有10份相同的类库加载进虚拟机,这是扯淡的。 3. web容器也有自己依赖的类库,不能于应用程序的类库混淆。基于安全考虑,应该让容器的类库和程序的类库隔离开来。 4. web容器要支持jsp的修改,我们知道,jsp 文件最终也是要编译成class文件才能在虚拟机中运行,但程序运行后修改jsp已经是司空见惯的事情,否则要你何用? 所以,web容器需要支持 jsp 修改后不用重启。再看看我们的问题:Tomcat 如果使用默认的类加载机制行不行?
答案是不行的。为什么?我们看,第一个问题,如果使用默认的类加载器机制,那么是无法加载两个相同类库的不同版本的,默认的累加器是不管你是什么版本的,只在乎你的全限定类名,并且只有一份。第二个问题,默认的类加载器是能够实现的,因为他的职责就是保证唯一性。第三个问题和第一个问题一样。我们再看第四个问题,我们想我们要怎么实现jsp文件的热修改(楼主起的名字),jsp 文件其实也就是class文件,那么如果修改了,但类名还是一样,类加载器会直接取方法区中已经存在的,修改后的jsp是不会重新加载的。那么怎么办呢?我们可以直接卸载掉这jsp文件的类加载器,所以你应该想到了,每个jsp文件对应一个唯一的类加载器,当一个jsp文件修改了,就直接卸载这个jsp类加载器。重新创建类加载器,重新加载jsp文件。《》
《》
《》
《》
《》
《java attach机制源码阅读》
=====================
《》代码实现
所以一个class被一个ClassLoader实例加载过的话,就不能再被这个ClassLoader实例再次加载(这里的加载指的是,调用了defileClass(...)方法,重新加载字节码、解析、验证)。而系统默认的AppClassLoader加载器,他们内部会缓存加载过的class,重新加载的话,就直接取缓存。所与对于热加载的话,只能重新创建一个ClassLoader,然后再去加载已经被加载过的class文件。
GIT@OSC工程路径:
------------------
《》
Java中类的加载方式。每一个应用程序的类都会被ClassLoader加载,所以,要实现一个支持热部署的应用,我们可以对每一个用户自定义的应用程序使用一个单独的ClassLoader进行加载。然后,当某个用户自定义的应用程序发生变化的时候,我们首先销毁原来的应用,然后使用一个新的ClassLoader来加载改变之后的应用。而所有其他的应用程序不会受到一点干扰。
有了总体实现思路之后,我们可以想到如下几个需要完成的目标:
1、定义一个用户自定义应用程序的接口,这是因为,我们需要在容器应用中去加载用户自定义的应用程序。
2、我们还需要一个配置文件,让用户去配置他们的应用程序。 3、应用启动的时候,加载所有已有的用户自定义应用程序。 4、为了支持热部署,我们需要一个监听器,来监听应用发布目录中每个文件的变动。这样,当某个应用重新部署之后,我们就可以得到通知,进而进行热部署处理。要实现热部署,我们之前说过,需要一个监听器,来监听发布目录applications,这样当某个应用程序的jar文件改变时,我们可以进行热部署处理。其实,要实现目录文件改变的监听,有很多种方法,这个例子中我使用的是apache的一个开源虚拟文件系统——common-vfs。如果你对其感兴趣,你可以访问http://commons.apache.org/proper/commons-vfs/。
当某个文件改变的时候,该方法会被回调。所以,我们在这个方法中调用了ApplicationManager的reloadApplication方法,重现加载该应用程序。public void reloadApplication (String name){ IApplication oldApp = this.apps .remove(name); if(oldApp == null){ return; } oldApp.destory(); //call the destroy method in the user's application AppConfig config = this.configManager .getConfig(name); if(config == null){ return; } createApplication(getBasePath(), config); } 重新加载应用程序时,我们首先从内存中删除该应用程序,然后调用原来应用程序的destory方法,最后按照配置重新创建该应用程序实例。
为了让整个应用程序可以持续的运行而不会结束,我们修改下启动方法无限循环,300ms.
public static void main(String[] args){ Thread t = new Thread(new Runnable() { @Override public void run() { ApplicationManager manager = ApplicationManager.getInstance(); manager.init(); } }); t.start(); while(true ){ try { Thread. sleep(300); } catch (InterruptedException e) { e.printStackTrace(); } } } 当服务的提供者提供了服务接口的一种实现之后,必须根据SPI约定在 META-INF/services/目录里创建一个以服务接口命名的文件,该文件里写的就是实现该服务接口的具体实现类。当程序调用ServiceLoader的load方法的时候,ServiceLoader能够通过约定的目录找到指定的文件,并装载实例化,完成服务的发现。
JDBC中的SPI机制
回到之前的一个问题,为什么只需要下面的一行代码,再提供商不同厂商的jar包,就可以轻松创建连接了呢?
Connection conn = DriverManager.getConnection(URL, USER, PASSWORD);
DriverManager中有一个静态代码块,在调用getConnection之前就会被调用:
/** * Load the initial JDBC drivers by checking the System property * jdbc.properties and then use the {@code ServiceLoader} mechanism */ static { loadInitialDrivers(); println("JDBC DriverManager initialized"); }private static void loadInitialDrivers() { String drivers;// 1、处理系统属性jdbc.drivers配置的值 try { drivers = AccessController.doPrivileged(new PrivilegedAction () { public String run() { return System.getProperty("jdbc.drivers"); } }); } catch (Exception ex) { drivers = null; } // If the driver is packaged as a Service Provider, load it. // Get all the drivers through the classloader // exposed as a java.sql.Driver.class service. // ServiceLoader.load() replaces the sun.misc.Providers() AccessController.doPrivileged(new PrivilegedAction () { public Void run() {// 2、处理通过ServiceLoader加载的Driver类 ServiceLoader loadedDrivers = ServiceLoader.load(Driver.class); Iterator driversIterator = loadedDrivers.iterator(); /* Load these drivers, so that they can be instantiated. * It may be the case that the driver class may not be there * i.e. there may be a packaged driver with the service class * as implementation of java.sql.Driver but the actual class * may be missing. In that case a java.util.ServiceConfigurationError * will be thrown at runtime by the VM trying to locate * and load the service. * * Adding a try catch block to catch those runtime errors * if driver not available in classpath but it's * packaged as service and that service is there in classpath. */// 加载配置在META-INF/services/java.sql.Driver文件里的Driver实现类 try{ while(driversIterator.hasNext()) { driversIterator.next(); } } catch(Throwable t) { // Do nothing } return null; } }); println("DriverManager.initialize: jdbc.drivers = " + drivers); if (drivers == null || drivers.equals("")) { return; } String[] driversList = drivers.split(":"); println("number of Drivers:" + driversList.length); for (String aDriver : driversList) { try { println("DriverManager.Initialize: loading " + aDriver);// 3、加载driver类 Class.forName(aDriver, true, ClassLoader.getSystemClassLoader()); } catch (Exception ex) { println("DriverManager.Initialize: load failed: " + ex); } } } JDBC使用了SPI机制,让所有的任务都交给不同的数据库厂商各自去完成,无论是实现Driver接口,还是SPI要求的接口文件,都做到了让用户不需要关心一点细节,一行代码建立连接。
=================
以下出自尚学堂高琪课程 ,说的还是比较全面和准确的
类加载器的作用
– 将class文件字节码内容加载到内存中,并将这些静态数据转换成方法区中的运行时数据结构,在堆中生成一个代表这个类的java.lang.Class对象,作为方法区类数据的访问入口。
• 类缓存 • 标准的Java SE类加载器可以按要求查找类,但一旦某个类被加载到类加载器中,它将维持加载(缓存)一段时间。不过,JVM垃圾收集器可以回收这些Class对象。
类加载器的代理模式
• 代理模式
– 交给其他加载器来加载指定的类• 双亲委托机制 – 就是某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次追溯,直到最高的爷爷辈的,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。– 双亲委托机制是为了保证 Java 核心库的类型安全。 • 这种机制就保证不会出现用户自己能定义java.lang.Object类的情况。 – 类加载器除了用于加载类,也是安全的最基本的屏障。 • 双亲委托机制是代理模式的一种 – 并不是所有的类加载器都采用双亲委托机制。 – tomcat服务器类加载器也使用代理模式,所不同的是它是首先尝试去加载某个类,如果找不到再代理给父类加载器。 这与一般类加载器的顺序是相反的
自定义类加载器的流程:
– 1、首先检查请求的类型是否已经被这个类装载器装载到命名空间中了,如果已经装载,直接返回;否则转入步骤2
– 2、委派类加载请求给父类加载器(更准确的说应该是双亲类加载器,真个虚拟机中各种类加载器最终会呈现树状结构),如果父类加载器能够完成,则返回父类加载器加载的Class实例;否则转入步骤3 – 3、调用本类加载器的findClass(…)方法,试图获取对应的字节码,如果获取的到,则调用defineClass(…)导入类型到方法区;如果获取不到对应的字节码或者其他原因失败,返回异常给loadClass(…), loadClass(…)转抛异常,终止加载过程(注意:这里的异常种类不止一种)。 – 注意:被两个类加载器加载的同一个类,JVM不认为是相同的类。 • 文件类加载器 • 网络类加载器 • 加密解密类加载器(取反操作,DES对称加密解密)
线程上下文类加载器
双亲委托机制以及默认类加载器的问题
– 一般情况下, 保证同一个类中所关联的其他类都是由当前类的类加载器所加载的.。 比如,ClassA本身在Ext下找到,那么他里面new出来的一些类也就只能用Ext去查找了(不会低一个级别),所以有 些明明App可以找到的,却找不到了。 – JDBC API,他有实现的driven部分(mysql/sql server),我们的JDBC API都是由Boot或者Ext来载入的,但是 JDBC driver却是由Ext或者App来载入,那么就有可能找不到driver了。在Java领域中,其实只要分成这种Api+SPI( Service Provide Interface,特定厂商提供)的,都会遇到此问题。 – 常见的 SPI 有 JDBC、JCE、JNDI、JAXP 和 JBI 等。这些 SPI 的接口由 Java 核心库来提供,如 JAXP 的 SPI 接口定 义包含在 javax.xml.parsers 包中。SPI 的接口是 Java 核心库的一部分,是由引导类加载器来加载的;SPI 实现的 Java 类一般是由系统类加载器来加载的。引导类加载器是无法找到 SPI 的实现类的,因为它只加载 Java 的核心库。 • 通常当你需要动态加载资源的时候 , 你至少有三个 ClassLoader 可以选择 : – 1.系统类加载器或叫作应用类加载器 (system classloader or application classloader) – 2.当前类加载器 – 3.当前线程类加载器 • 当前线程类加载器是为了抛弃双亲委派加载链模式。 – 每个线程都有一个关联的上下文类加载器。如果你使用new Thread()方式生成新的线程,新线程将继承其父线程的上下文类加载器。
如果程序对线程上下文类加载器没有任何改动的话,程序中所有的线程将都使用系统类加载器作为上下文类加载器。
• Thread.currentThread().getContextClassLoader()public class TCCC { public static void main(String[] args) throws Exception { ClassLoader loader = TCCC.class.getClassLoader(); System.out.println(loader); ClassLoader loader2 = Thread.currentThread().getContextClassLoader(); System.out.println(loader2); Thread.currentThread().setContextClassLoader(new FileSystemClassLoader("d:/")); System.out.println(Thread.currentThread().getContextClassLoader()); Class c = (Class ) Thread.currentThread().getContextClassLoader().loadClass("com.current.www.Test"); System.out.println(c); System.out.println(c.getClassLoader()); }} TOMCAT服务器的类加载机制
• 一切都是为了安全!
– TOMCAT不能使用系统默认的类加载器。 • 如果TOMCAT跑你的WEB项目使用系统的类加载器那是相当危险的,你可以直接是无忌惮操作操作系统的各个目录了。 • 对于运行在 Java EE™容器中的 Web 应用来说,类加载器的实现方式与一般的 Java 应用有所不同。 • 每个 Web 应用都有一个对应的类加载器实例。该类加载器也使用代理模式(不同于前面说的双亲委托机制),所不同的是它是首先尝试去加载某个类,如果找不到再代理给父类加载器。这与一般类加载器的顺序是相反的但也是为了保证安全,这样核心库就不在查询范围之内。 • 为了安全TOMCAT需要实现自己的类加载器。 • 我可以限制你只能把类写在指定的地方,否则我不给你加载!转载地址:https://linuxstyle.blog.csdn.net/article/details/88412989 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
