本文共 1348 字,大约阅读时间需要 4 分钟。

文章目录
前言
前边不是讲了两篇位运算的嘛,想着把这个布隆过滤器写上,凑个整。
这篇就轻松点聊聊,不谈代码,就讲理论。
本篇基本内容来自:
https://www.jianshu.com/p/2104d11ee0a2 https://cloud.tencent.com/developer/article/1136056布隆加速器?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
为什么要用布隆过滤器?
1、相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少。
2、单纯的int型数据,可以使用上面的位图来处理,不过字符串呢?是吧。布隆过滤器数据结构!!
初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。
长这样:
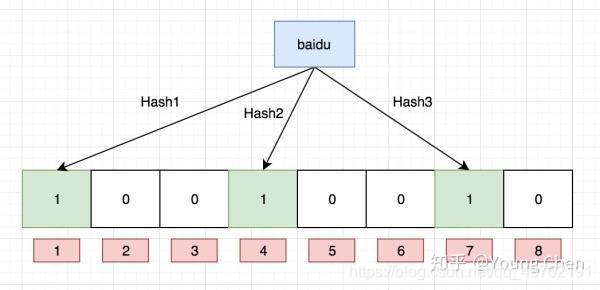
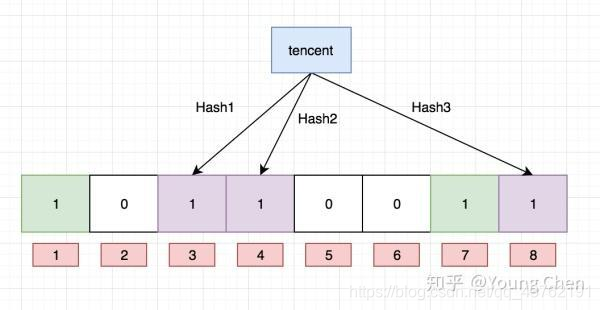
问题已经初现端倪了。当下面那个位图的饱和度越来越高,判断将要插入的字符串是否已存在就难免有失误。
但是判断那个字符串不存在那不会失误,不存在就是不存在。布隆过滤器删除数据
传统的布隆过滤器并不支持删除操作。但是名为 Counting Bloom filter 的变种可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除。
Counting Bloom Filter 的出现,解决了上述问题,它将标准 Bloom Filter 位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的 k (k 为哈希函数个数)个 Counter 的值分别加 1,删除元素时给对应的 k 个 Counter 的值分别减 1。Counting Bloom Filter 通过多占用几倍的存储空间的代价, 给 Bloom Filter 增加了删除操作。基本原理是不是很简单?看下图就能明白它和 Bloom Filter 的区别在哪。
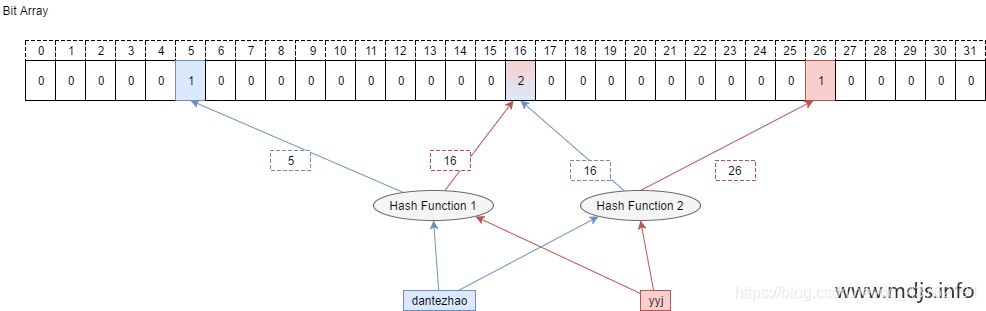
Counter 大小的选择
篇幅略长,公式略多,可以直接看原文:https://cloud.tencent.com/developer/article/1136056
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
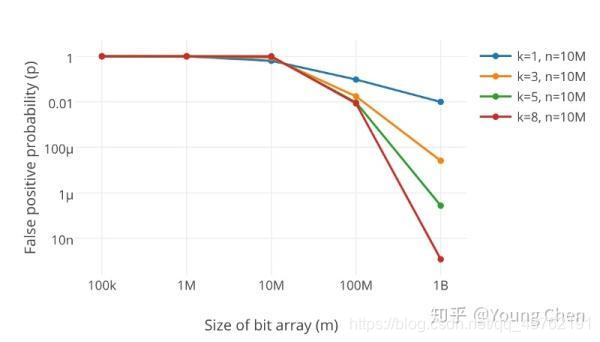
如何选择适合业务的 k 和 m 值呢,这里直接贴一个公式:
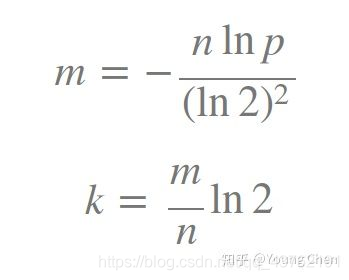
转载地址:https://lion-wu.blog.csdn.net/article/details/107270372 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
