本文共 3180 字,大约阅读时间需要 10 分钟。
文章目录
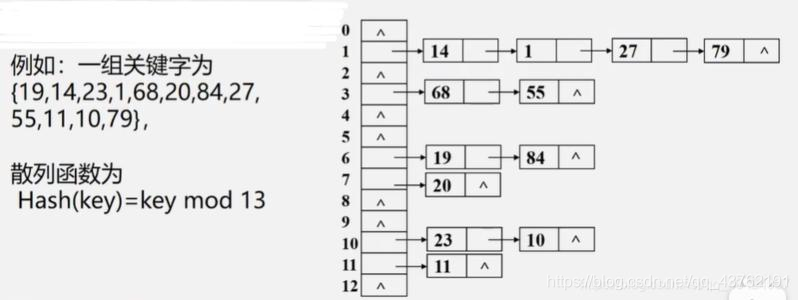
哈希散列表
需要我说一下什么是哈希表吗?上面那张图可以先看一下,然后我搬一段官方话过来。
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hashtable(key,value) 就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。(或者:把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。)
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
具体参考一下你的手机通讯录。
Hash表在海量数据处理中有着广泛应用。
我们之前的查找,都是这样一种思路:集合中拿出来一个元素,看看是否与我们要找的相等,如果不等,缩小范围,继续查找。而哈希表是完全另外一种思路:当我知道key值以后,我就可以直接计算出这个元素在集合中的位置,根本不需要一次又一次的查找!Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。
hash就是找到一种数据内容和数据存放地址之间的映射关系。
小故事
我在知乎上看到这么一个故事,觉得很不错,跟大家分享一下。
你的车停在了万达的停车场,你耍玩回来要找车,停车场太大了,不好找啊!!!
第一个办法是:你对着停车场的车一辆一辆的找。运气最差时,你搜遍楼下N辆车,发现你的车在末尾——拿术语说,这个复杂度是O(N)。
假如所有车按车牌号顺序排列,你直接往停车场中间走就行了;如果你的车牌号大于中间那辆车,那么你就往停车场后半部分的中间走,否则就往前半场走……依此类推。
这也是我们比较常用的方法了,二分查找。
那还有没有更好一点的办法呢?假设这个停车场非常非常大,大到可以给每个车牌号分配一个固定的停车位;那么只要你把自己的车牌号报给看门老头,他拎着你的衣领子往后一丢,你就“吧唧”一下掉自己车顶上了——嗯,你看,一车一位,就是这么任性。
对于前面两个方法的程序实现我就不说了吧,我们来看一下最后一个场景的程序实现:
要实现这么一个程序,需要使用一个数组,但是这个数组需要多大呢? 假设车牌号共8位,每位可以使用26个英文字母或10个阿拉伯数字,那么不同的车牌号共有36^8=2821109907456种。 用char数组,大概要3T空间吧。显然,不太现实嘛。
那么,有没有办法在得到O(1)的查找效率的同时、又不付出太大的空间代价呢?
有,就是本篇讲的哈希表了。
很简单,我们把你的车牌号看作一个8位36进制的数字;为了方便,我们可以把它转换成十进制。那么,你的车牌号就是一个不大于2821109907456的数字。现在,我们把你的车牌号除以一万,只取余数——你看,你的车牌号是不是就和0~10000之间的数字对应起来了?
很好,你的车就停在这个数字对应的停车位上,过去开就是了——O(1)的查找效率!这个“把你的车牌号映射进0~10000之间”的操作,就是所谓的“哈希”或者(当然,实践上,为了尽量减少冲突,哈希表的空间大小会尽量取质数)。但是,你发现你的车牌尾号和你的朋友的车牌尾号是一样的啊,那是不是意味着,某一个车位,要停你的车,还要停你朋友的车?
那也不太现实,那这么办呢?没错,hash可能会把不同的数据映射到同一个点上,术语称其为“碰撞”。1、实在没办法,就在你的车上方再搭建一个车位,然后把你朋友的车放上去吧。
这就是开链法。2、过去的散列函数是 (车牌号 模除 10000),发现碰撞了就换散列函数 (车牌号加1 模除 10000)试一试。
这叫“再散列法”。3、再修个小车库,碰撞了的停小车库去(小车库可以随便停,也可以搞一套别的机制)
请注意,因为冲突的存在,哈希表虽然有着优异的平均访问时间(常数访问效率!);但它的“最大访问时间”却是没有保证的——你可能一个微秒甚至几个纳秒就拿到了数据,也可能几十个毫秒了还在链表上狂奔。因此实时性要求严格的场合,用它前需要谨慎考虑。
如果我们的“键值转换数组下标的函数(也就是哈希函数)”选择不当(比如我前面提到的直接求余),就很容易使得“碰撞”频繁出现。这就对哈希函数的选择提出了要求。
但是哈希函数本身也不应该过于复杂,不然每次计算耗时太久——O(1)虽然是常数时间;但如果时间常数太长,它可能就不如O(lnN)查找算法快。
要知道,在一百万数据里面做二分法搜索,最差时也不过需要20次搜索而已;如果你的哈希函数本身需要的计算时间已经超过了这个限度,那么改用二分法显然是个更为理智的选择:不仅更快,还更省空间。
工程问题,向来是需要根据实际情况灵活选择、做出合理折衷的。
作者:invalid s
链接:https://www.zhihu.com/question/330112288/answer/744362539 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
加载因子
无论如何,哈希表中,碰撞无法绝对避免。
当碰撞发生时,就不得不使用开链表法或再散列法存储冲突数据;而这必将影响哈希表的性能。很容易想到,如果哈希表很大、里面却没存几条数据,那么它出现冲突(碰撞)的几率就会很小;反之,如果哈希表已经接近满了,那么每条新加入的数据都会产生碰撞。
哈希表实际所存数据量和哈希表最大容量之间的比值,叫做哈希表的“加载因子”。加载因子越小,冲突的概率就越低,但浪费大量空间;加载因子越高,冲突概率越大,但空间浪费就越少。这是一个需要根据工程实践灵活选择的折衷值。很多语言的hash函数库允许你主动调节这个值。一般来说,一个较为平衡的加载因子大约是0.7~0.8左右。这样既不会浪费太多空间,也不至于出现太多冲突。
哈希函数的安全
如果哈希表使用的哈希函数较为简单,对恶意的攻击者来说,他可以精心构造一大堆数据提交给你——所有这些数据散列后全都存在一个格子里。
我们前面提到过,当遇到这种冲突/碰撞时,为了避免彼此覆盖,这些数据就要存在链表中(或者再散列后存在同一个哈希表中)。当这些数据被存进链表时,对它们的访问效率将降到O(N)——因为链表搜索效率只有O(N)。之前就发生过这种攻击,包括Java在内的许多种语言全部落马。解决方案也很简单:
1、提高哈希函数复杂度,想办法加入随机性(相当于每次使用一个不同的哈希函数),避免被人轻易捕捉到弱点 2、不要用开链表法存储冲突数据,采用“再散列法”,并且使用不同的哈希函数再散列、还可以把冲突数据存入另一个表——要构造同时让两个以上不同的哈希函数冲突的攻击数据,难度就大得多了。我的困惑
我一开始想到的也是开链法,所以开头那张图也就是开链法的。
但是,开链法真的好吗? 散列表要有多少个初始位置?如果有一亿个数据的存储,二分查找一个数据要20次,哈希要比二分快,那开链法的链就不要太长了,那需要有多少个哈希节点呢?需要占用多大的存储空间? 应该是我读书少吧。资料
看一下我之前写好的两篇,就不复制粘贴过来了,有点大。
那两篇都是我在网上四处碰壁之后写的。
转载地址:https://lion-wu.blog.csdn.net/article/details/113809757 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
