本文共 3087 字,大约阅读时间需要 10 分钟。
#环境
该教程系统环境为 Ubuntu15.04(其他版本的Linux操作系统可以借鉴) ,Hadoop版本为Hadoop2.6.0
#创建一个Hadoop的用户
在安装 Hadoop 之前,尽量创建一个专门的 Hadoop 用户,我的Hadoop用户名:hadoop,密码自己设计一个简单容易记的。

[ -m ] 使用者目录如果不在则自动创建
[ -s ] 使用 /bin/bash 作为 shell

Ubuntu将用户加入用户组和cenOS不同,要注意。()
#更新apt
sudo apt-get update
如果遇到Hash校验和不符等问题可以更换源来解决( · Linux闲谈杂记1)
#安装 SSH server、配置SSH无密码登录
SSH了解:
SSH 分 openssh-client(Ubuntu已默认安装) 与 openssh-server(sudo apt-get install openssh-server),
前者用来登录到别的机子上,后者为其他机子登录到本机。
ssh-server配置文件位于/ etc/ssh/sshd_config
启动SSH服务:
sudo /etc/init.d/ssh stop
sudo /etc/init.d/ssh start
这里我们只需要安装 openssh-server
sudo apt-get install openssh-server
然后登录到 本机
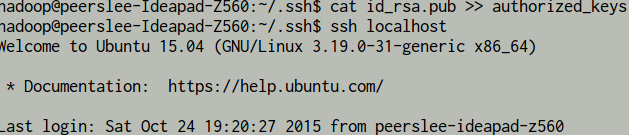
ssh localhost
exit //退出刚才的登录
利用 ssh-keygen 生成密钥,并将密钥加入到授权中:()
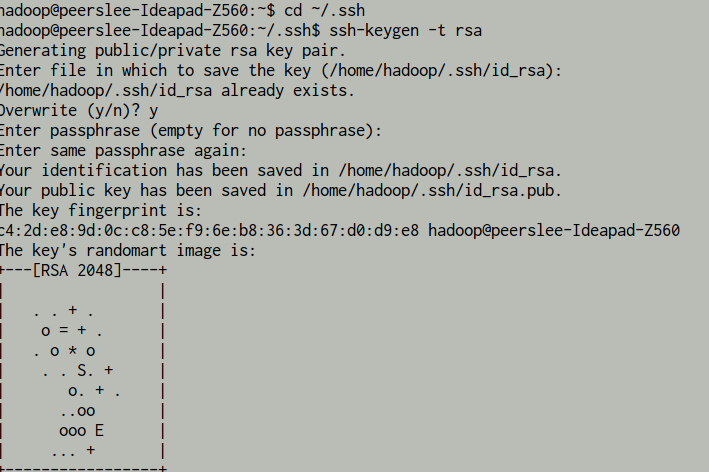
将公钥 id_rsa.pub 加入 授权 authorized_keys 中
#下载安装JDK
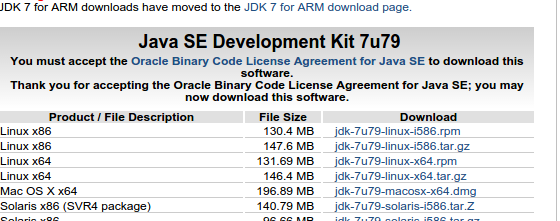
下载jdk1.7()
根据操作系统选择合适的版本(我选择的是Linux x64 ××.tar.gz)
解压到安装的位置(我解压到/usr/java/jdk××)
tar -zxvf jdk××(全名).tar.gz -C /usr/java/
tar命令
-c 压缩
-x 解压
-z (gzip)
-v 显示
-f 后面接 要处理文件的名字
-C 后面接 处理之后的目标路径
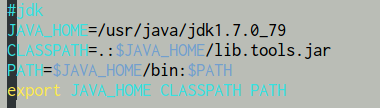
配置java环境变量(可以在/etc/profile、/etc/bashrc、/etc/environment等多个文件中配置)
vim /etc/profile
java -version

#下载安装Hadoop()
下载 hadoop××.tar.gz 这个格式的文件,这是编译好的,包含 src 的则是 Hadoop 源代码。
同时也可以下载 hadoop-2.x.y.tar.gz.mds 用来校验 hadoop××.tar.gz 的完整性。
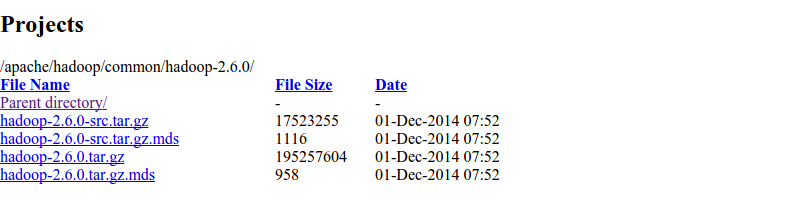
进入下载目录:(对比md5检验值)
cat./hadoop-2.6.0.tar.gz.mds| grep 'MD5'# 列出md5检验值 md5sum./hadoop-2.6.0.tar.gz| tr "a-z""A-Z"# 计算md5值,并转化为大写,方便比较


vim /usr/local/hadoop/etc/hadoop/core-site.xml2.hdfs-site.xmlhadoop.tmp.dir file:/usr/local/hadoop/tmp Abase for other temporary directories. fs.defaultFS hdfs://localhost:9000
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xmldfs.replication 1 dfs.namenode.name.dir file:/usr/local/hadoop/tmp/dfs/name dfs.datanode.data.dir file:/usr/local/hadoop/tmp/dfs/data






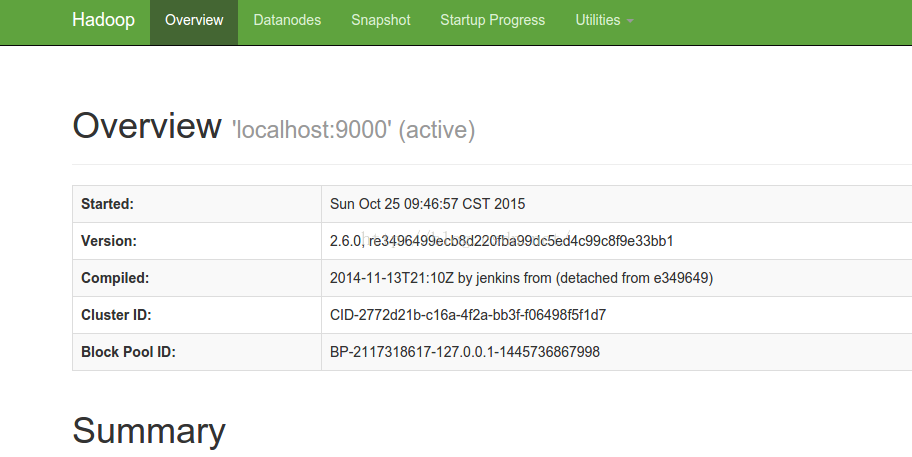






转载地址:https://lipenglin.blog.csdn.net/article/details/49305901 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
