本文共 1407 字,大约阅读时间需要 4 分钟。
#分布式计算框架 -> Map-Reduce
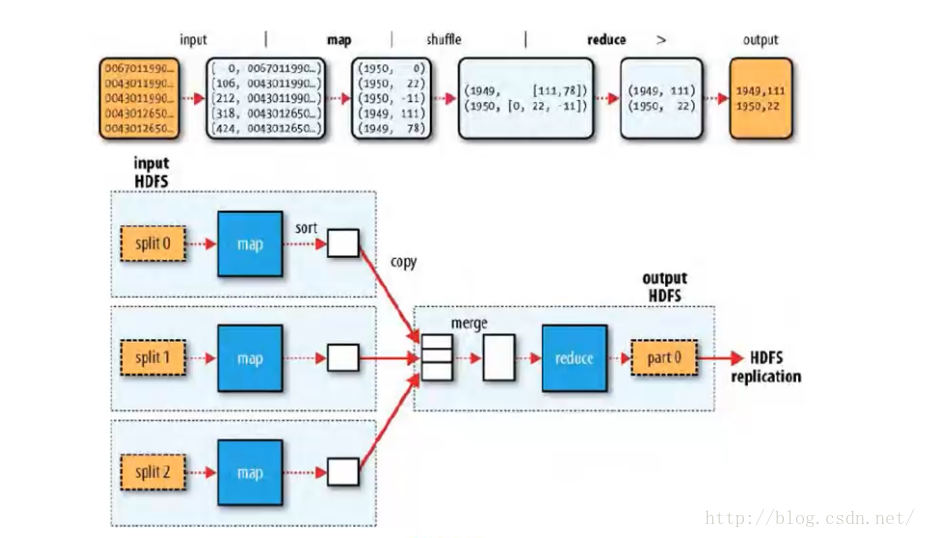
#Mapper
Map-reduce的思想就是“分而治之”
Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务” 执行 “简单的任务”
有几个含义:
1 数据或计算规模相对于原任务要大大缩小;
2 就近计算,即会被分配到存放了所需数据的节点进行计算;
3 这些小任务可以并行计算,彼此间几乎没有依赖关系
#Reducer
对map阶段的结果进行汇总
Reducer的数目由mapred-site.xml配置文件里的项目mapred.reduce.tasks决定。缺省值为1,用户可以覆盖之。
#Shuffler
mapper 和 reducer 中间的一步(不是必须存在)
将 mapper 输出按照某种 key 值重新分割 或 组合成 n 份,把符合key值的某些输出送到特定的reducer处理
简化了reducer的处理过程
#性能调优
调整reducer的数量
输入:大文件优于小文件
压缩map的输出(降低网络传输)
优化每个节点能运行的任务(mapred.tasktracker.map.tasks.maximummapred.tasktracker.reduce.tasks.maximum) (缺省值均为2)
#Map-Reduce工作机制剖析

#调度机制
缺省为队列(FIFO)作业调度
支持公平调度器
支持容器调度器
#任务执行优化
推测式执行:
1.原理:JobTracker 会根据 执行中的任务和他的副本哪个先执行,推测出该任务和副本哪个执行快,而kill掉慢者。
2.推测式执行缺省打开,通过在mapred-site.xml配置文件中设置mapred.map.tasks.speculative.execution和mapred.reduce.tasks.speculative.execution可为map任务或reduce任务开启或关闭推测式执行。
重用JVM(可以省去启动新的JVM消耗的时间):
在mapred-site.xml配置文件中设置mapred.job.reuse.jvm.num.tasks设置单个JVM上运行的最大任务数(1表示无限制)
忽略模式:(缺省关闭,用SkipBadRecord方法打开)
任务在读取数据失败2次后,会把数据位置告诉jobtracker,后者重启该任务并且在遇到所记录的坏数据时直接跳过。
#错误处理机制:
1.硬件故障(jobtracker-tasktracker故障)
jobtracker必须使用质量好的机器(尽可能减小故障的机率)
tasktracker 的故障是 jobtracker 通过心跳机制 发现的,之后jobtracker会将其从任务节点列表中删除
如果故障节点正在执行map任务,并且没有执行完成,jobtracker会让其他节点重新执行此map任务
如果故障节点正在执行 reduce 任务,并且没有执行完成,jobtracker会让其他节点继续执行此任务
2.任务失败(代码有bug、进程崩溃)
jvm自动退出,向tasktracker 父进程发送错误信息,写入logs中
tasktracker监控程序判断并标记,任务计数器减一,通过心跳信号告诉jobtracker,会重新进队列、分配、执行
当任务失败次数达到 4次,将不会再被执行,同时宣布任务失败
转载地址:https://lipenglin.blog.csdn.net/article/details/49661095 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
