本文共 3645 字,大约阅读时间需要 12 分钟。
由于目前用户使用测试计划时选择的用例数较多(1000+条),测试计划执行时间经常需要3000秒+,也就是执行一个测试计划在30min - 60min,甚至更多
准备通过执行策略优化测试计划执行的所需要的时间,提高效率
执行策略
现有的执行策略方案:
串行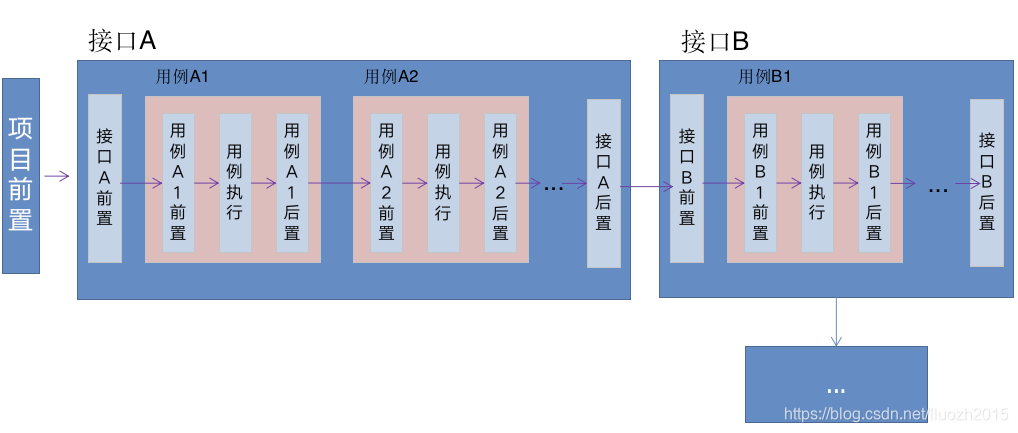 优化后执行策略方案: 并行
优化后执行策略方案: 并行 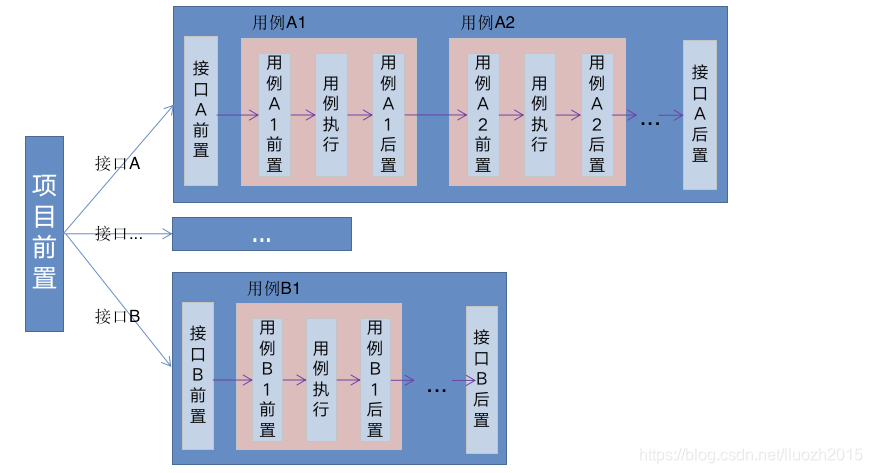
在实现并行执行策略时,有3种基本策略:
- 分布式
- 多线程
- 多进程
接下来分别看看三种基本策略
分布式
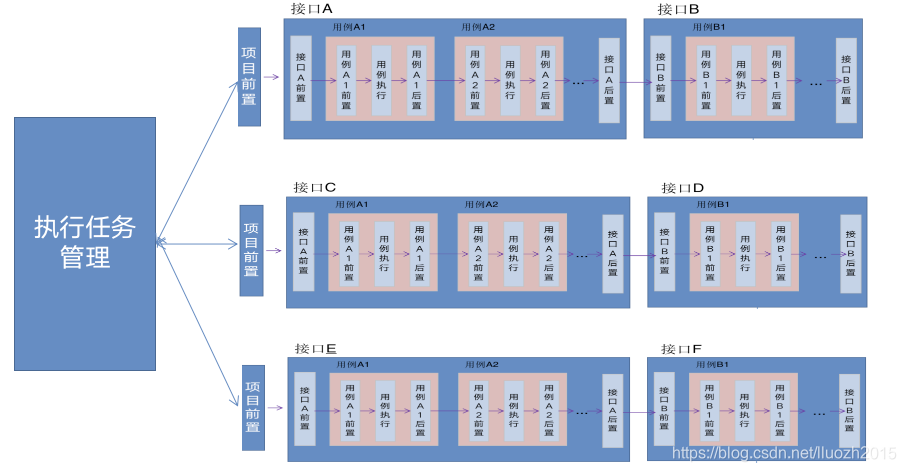
- 优势:可以无限扩展、性能最优
- 劣势:开发工作量大
多线程
1. 需要将接口执行的逻辑给抽取出来
class MyThread(threading.Thread): def __init__(self, plan_id, case_list): threading.Thread.__init__(self) self.plan_id = plan_id self.case_list = case_list def run(self): self.exec_in_case() def exec_in_case(self): """ 执行单一的用例 :return: """ # 执行接口前置条件 # TODO for case in self.case_list: """循环遍历执行接口下的用例""" # 执行用例前置条件 # TODO # 执行用例 # TODO # 执行用例后置条件 # 执行接口后置条件 # TODO # 执行结果聚合&更新聚合数据 # TODO
2. 多线程启动方式
thread_list = []# 多线程执行接口用例for in_case_list in plan_in_list: thread = MyThread(self.plan_id, in_case_list) thread_list.append(thread) thread.start()for t in thread_list: t.join()
3. 遇到了一个小坑,即join方法的使用
join所完成的工作就是线程同步,即主线程任务结束之后,进入阻塞状态,一直等待其他的子线程执行结束之后,主线程再终止在使用时,如果以方式1:
for in_case_list in plan_in_list: thread = MyThread(self.plan_id, in_case_list) thread.start() thread.join()
出现问题:各个线程按照顺序执行
如果以方式2:
for in_case_list in plan_in_list: thread = MyThread(self.plan_id, in_case_list) thread.start()
出现问题:主线程首先结束
这里普及一下守护线程的概念
线程有一个布尔属性叫做daemon,表示线程是否是守护线程,默认取否 当程序中的线程全部是守护线程时,程序才会退出。只要还存在一个非守护线程,程序就不会退出 主线程是非守护线程 所以如果子线程的daemon属性不是True,那么即使主线程结束了,子线程仍然会继续执行
4. 调试ok执行
 执行时间从2000秒+ 到 100秒内
执行时间从2000秒+ 到 100秒内 5. 失败数问题
但是出现一个严重的问题,即执行失败数暴增,为何? 这里得看看测试计划执行的一个逻辑,即数据的问题A接口将获取的值赋给了unit变量,B接口执行时也将获取的值赋给了unit变量,如果是串行执行,不会产生任何问题,但是修改为A、B接口同时执行时就会出现数据错乱的问题

因为在测试计划初始时初始化了一系列的global变量,这些变量是共用的
class HttpsGlobalVar(): # 构建信息 global buildNum # 执行的env_id global envId # 项目全局变量 global variables
需要解决这个问题需要每个线程拷贝并维护当前的global数据,由于代码历史原因,这个修改量相对较大
多进程
1. 执行逻辑
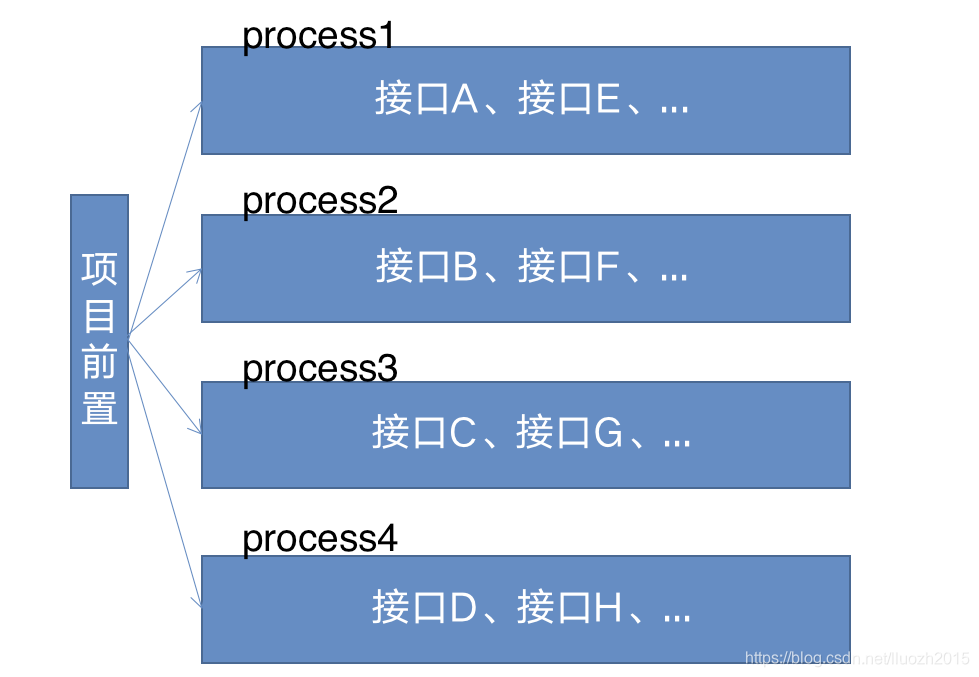
2. 接口分组执行
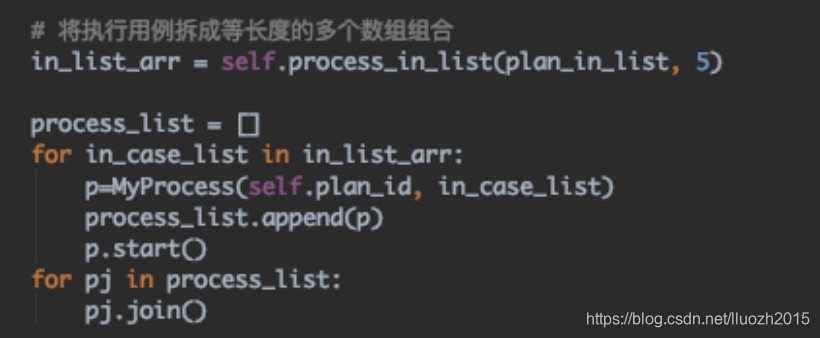 比如有20个接口,执行的进程数为5,那么将这20个接口拆分成5组,每组执行4个接口
比如有20个接口,执行的进程数为5,那么将这20个接口拆分成5组,每组执行4个接口 这样会出现一个问题,即执行效率并不是最优的,因为接口用例数不一样,而且用例执行的时间也不一样,那么很可能某个进程需要执行的时间远大于其他进程,那么整个测试计划执行的时间也会增加
3. 队列消费的模式
综上,可以使用队列消费的方式,比如所有的接口是一个队列列表,进程1、2、3、4、5都去队列列表中取数据,执行结束当前接口再去队列中消费新的一条数据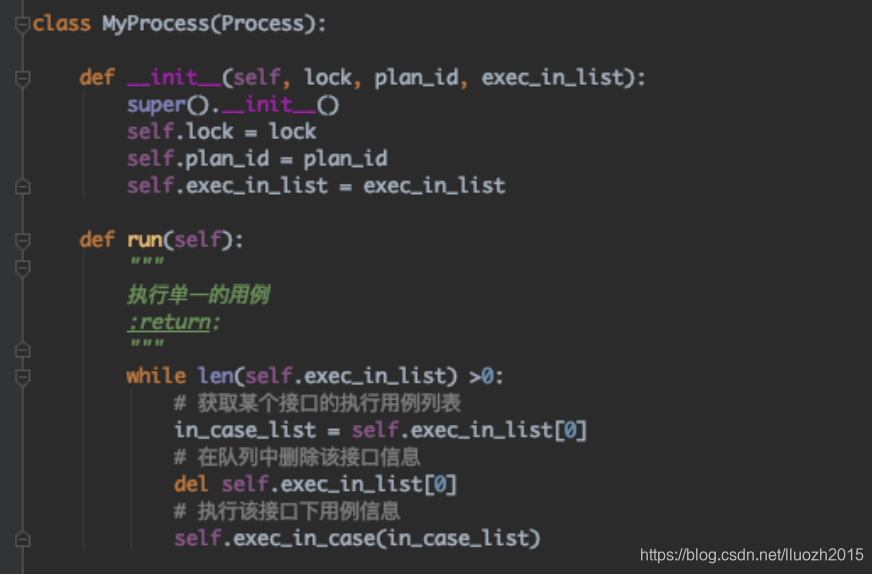 4. 聚合数据出错的问题 执行后发现聚合数据所有的概要数据都为0,但是在代码中各个进程已经对执行数据进行聚合并赋值
4. 聚合数据出错的问题 执行后发现聚合数据所有的概要数据都为0,但是在代码中各个进程已经对执行数据进行聚合并赋值 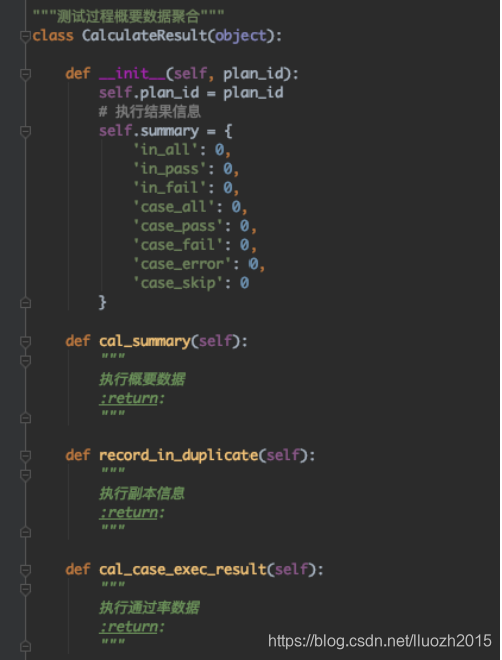 5. 进程共享数据 这里需要解决进程间数据共享的问题,下面看一个栗子
5. 进程共享数据 这里需要解决进程间数据共享的问题,下面看一个栗子 import osimport multiprocessing def func(m_value,m_arr,m_list,m_dict): m_value.value=10.78 #子进程改变数值的值,主进程跟着改变 m_arr[2]=9999 #子进程改变数组,主进程跟着改变 m_list.append(os.getpid()) m_dict[os.getpid()] = os.getpid() if __name__=="__main__": m_value=multiprocessing.Value("d",10.0) # d表示数值,主进程与子进程共享这个value,主进程与子进程都是用的同一个value m_arr=multiprocessing.Array("i",[1,2,3,4,5]) #主进程与子进程共享这个数组 m_dict=multiprocessing.Manager().dict() #主进程与子进程共享这个字典 m_list=multiprocessing.Manager().list(range(5)) #主进程与子进程共享这个List p=multiprocessing.Process(target=func,args=(m_value,m_arr,m_list,m_dict,)) p.start() p.join() ok,那我们的概要数据可以修改为
from multiprocessing import Managerself.summary = Manager().dict({ 'series_all': 0, 'series_pass': 0, 'series_fail': 0, 'case_all': 0, 'case_pass': 0, 'case_fail': 0, 'case_error': 0, 'case_skip': 0, 'series_detail': { } }) 6. 进程锁
解决了这个问题后,发现聚合的数据仍然有问题,因为可能多个进程同时修改数据导致,这里需要使用进程锁进行管理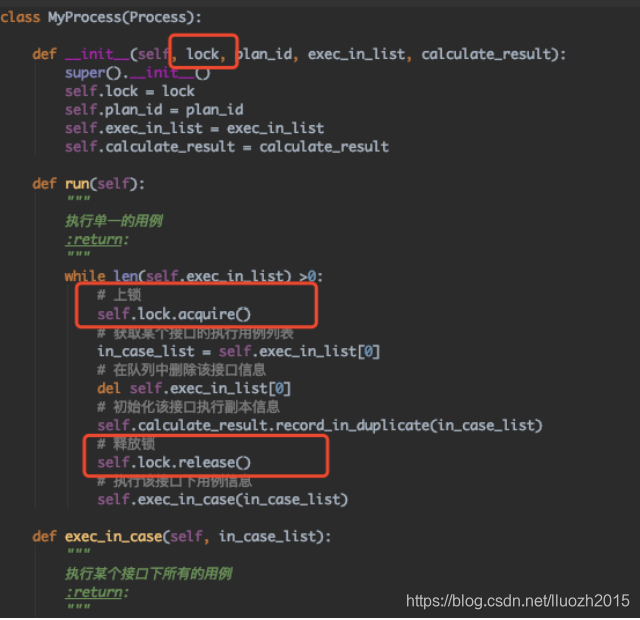
7. 执行效率倍率
修改后执行测试计划 时间从2000秒+ 降低为325秒,这里使用的是10个进程并发执行,那为什么执行时间并不是200秒+呢? 这里有主要有两个原因
时间从2000秒+ 降低为325秒,这里使用的是10个进程并发执行,那为什么执行时间并不是200秒+呢? 这里有主要有两个原因 - 时间未平均
即使使用的是队列消费的模式,但是并不是所有进程结束的时间都完全一样,并未能做到完全平均,这样执行的时间肯定会大于原执行时间/进程数 计算的时间
- 机器cpu核数
使用的是4核的机器,我们看看下图
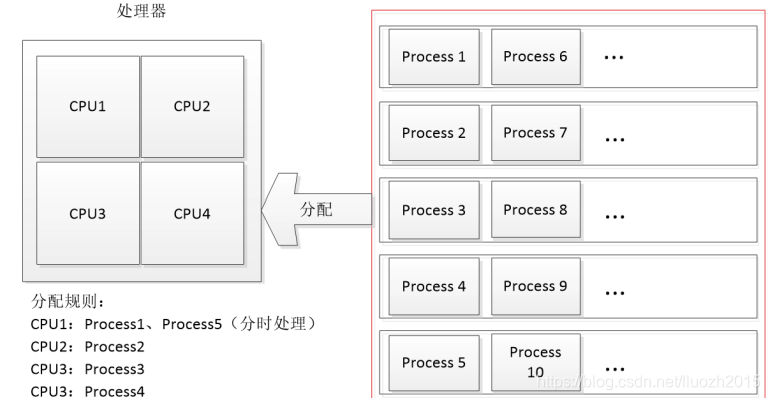 可以看出,4核的设备,即使10个进程进行并发执行,肯定也并不是10个进程完全同时执行,但是cpu允许的情况下,还是会比4个进程执行更快
可以看出,4核的设备,即使10个进程进行并发执行,肯定也并不是10个进程完全同时执行,但是cpu允许的情况下,还是会比4个进程执行更快 8. 隐藏的问题
其实还有一个隐藏的问题,比如接口A是创建某个班级,断言的方式是比较班级的个数是否增加,但是另外一个接口的前置可能就是使用接口A创建班级,这样会导致接口A的用例断言失败,目前解决的方式即特殊接口特殊处理,或者仅使用单进程执行转载地址:https://lluozh.blog.csdn.net/article/details/107860194 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
