本文共 3926 字,大约阅读时间需要 13 分钟。
Furion平台是一个提供并发压力、性能结果分析、容量测试及基准测试的性能平台
接下来mark以下Furion平台的架构演进一、单机模式
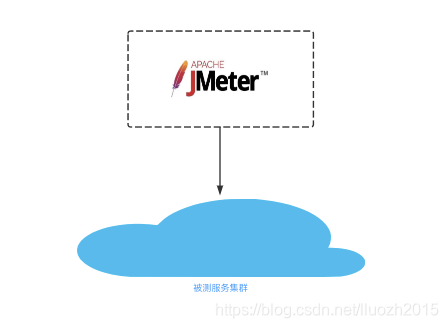
优势
- 操作简便、无需环境部署 直接使用jmeter编辑jmx文件,然后发起流量压测,
不足
-
能提供发起的压力有限
比如2c的机器在提供qps600的压力时CPU已经基本跑满 -
垂直扩容压力非线性
垂直扩容为4c甚至8c、16c,由于端口、带宽等方面的影响,能提供的压力并不是线性比例关系 -
垂直扩容成本高
二、分布式模式
服务端架构分布式设计支撑大并发业务逻辑处理,做为流量模拟客户端同样也需要分布式设计,jmeter原生提供分布式启动的方式
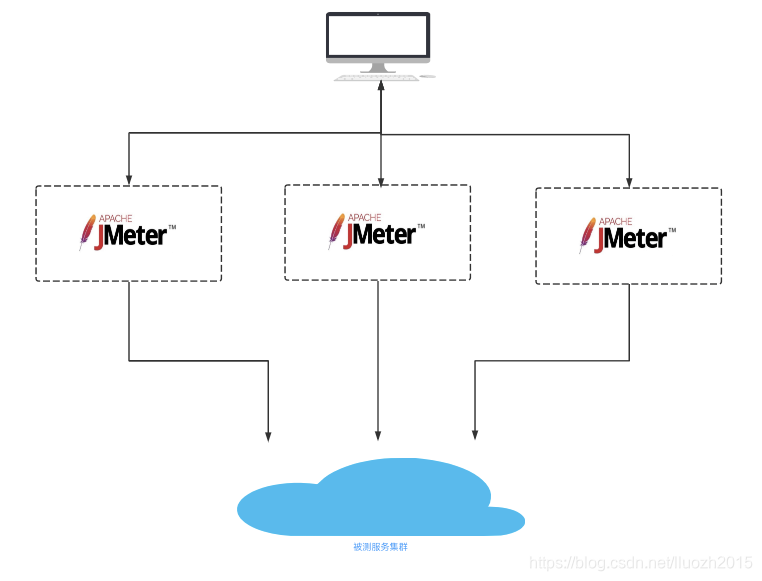
优势
- 提供高并发 根据客户端数量可以基本上线性倍数提供并发压力,且各个客户端肉鸡之间基本没有影响
不足
-
部署耗时
需要搭建部署多个Jmeter节点环境,比如若需要节点数超过100时所需的工作量巨大 -
csv文件分割同步
将csv文件分割成对应数量的文件,且上传并同步到各个客户端 -
节点异常处理
当节点异常或需要批量处理部分节点时,需要ssh登陆或者批量连接操作节点 -
监控缺乏
临时节点资源监控缺乏,排查问题相对困难
三、节点容器化
将客户端节点像服务节点一样进行容器化管理,统一部署和扩缩容
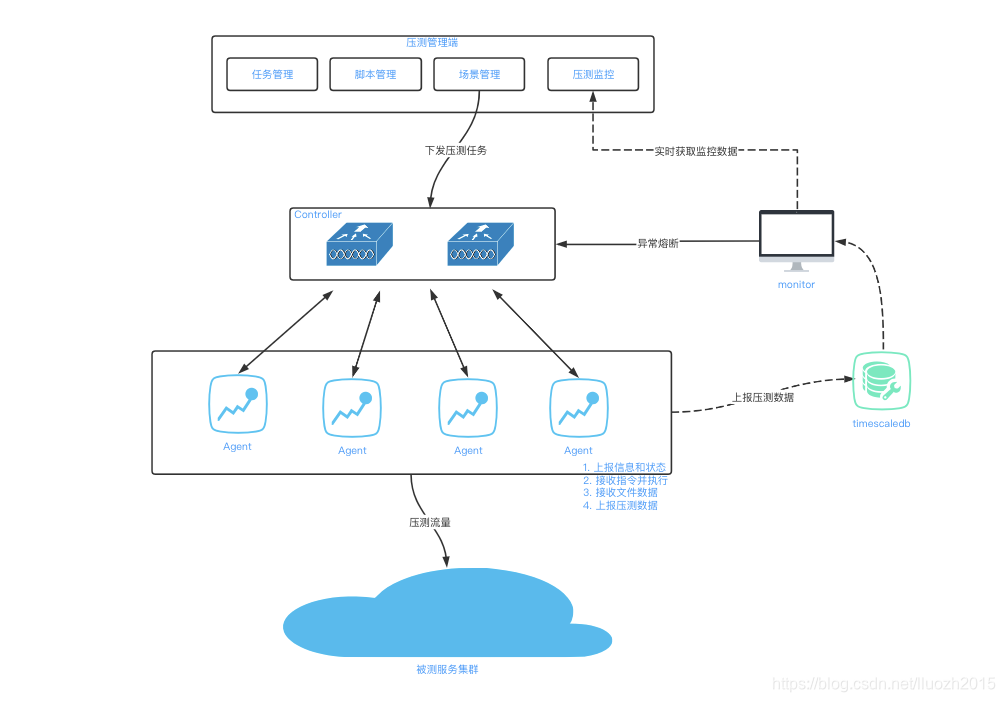
Agent和Controller通信方案选型
- 方案一 双向HTTP通信
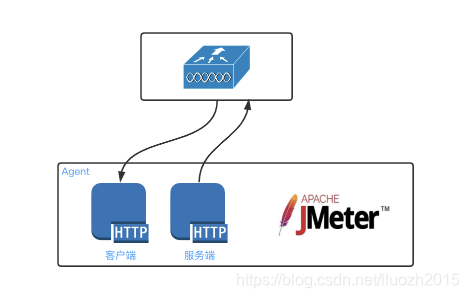
- 方案二 TCP长连接通信
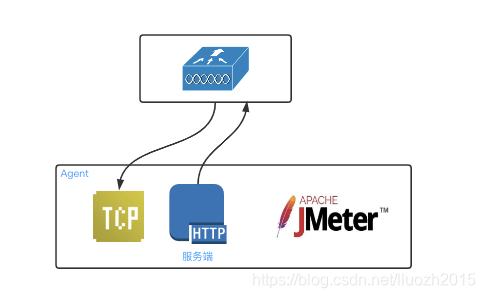
- 方案三 集成C++消息服务通信sdk
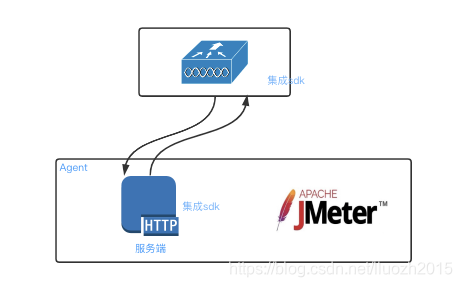
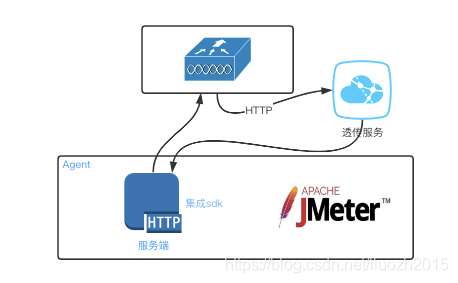
- 方案四 在集成sdk基础上增加一个透传服务进行消息的分发
结合成本和效率等方面综合考虑,最终选择方案一的通信方式
Agent代替原有的肉鸡,使用容器化管理,报告聚合使用时序数据库timescaledb,Furion平台的雏形形成
Furion主要的功能
- 任务和场景管理
- jmx脚本管理和分发
- csv脚本管理、切分和分发
- 客户端肉鸡节点管理
- 报告聚合展示
大致的流程
- 创建测试任务和场景
- 上传jmx和csv脚本
- 切分和分发脚本
- 执行测试任务
- 报告聚合展示
优势
-
节点容器化管理
方便部署和扩缩容,资源利用率高,使用效率提升 -
文件管理分发
csv文件切割和分发,处理文件效率提升 -
报告聚合
避免jmeter Controller端GUI报告展示达到一定数据量时页面经常卡顿的问题 聚合使用timescaledb,在1w qps时聚合准确性和速度ok 聚合报告展示内容丰富
不足
- 报告聚合速度 当一次压测数据量达1000w+时,报告聚合速度很长(一次聚合2min以上)
为了避免频繁聚合导致数据库扛不住,数据库表中使用一个表示聚合状态的字段管理,在定时聚合前首先判断上次聚合是否完成,已完成时进行下一次的聚合,未完成时此次聚合取消
- 发起qps上不去 在qps 4w+时,即使timescaledb升级为32核,仍出现大量的慢查询和写入性能瓶颈,因为使用的是同步上报,大量的线程卡在timescaledb数据写入,导致即使客户端扩容,qps一样上不去的问题
四、kafka数据消费
最核心的痛点问题是客户端无法发起更大的qps
制约点在于Agent发起请求后同步向
timescaledb写入数据,timescaledb的写入性能成为制约点
既然同步写入出现性能瓶颈,可以使用异步或者中间件解耦的方式解决这个问题
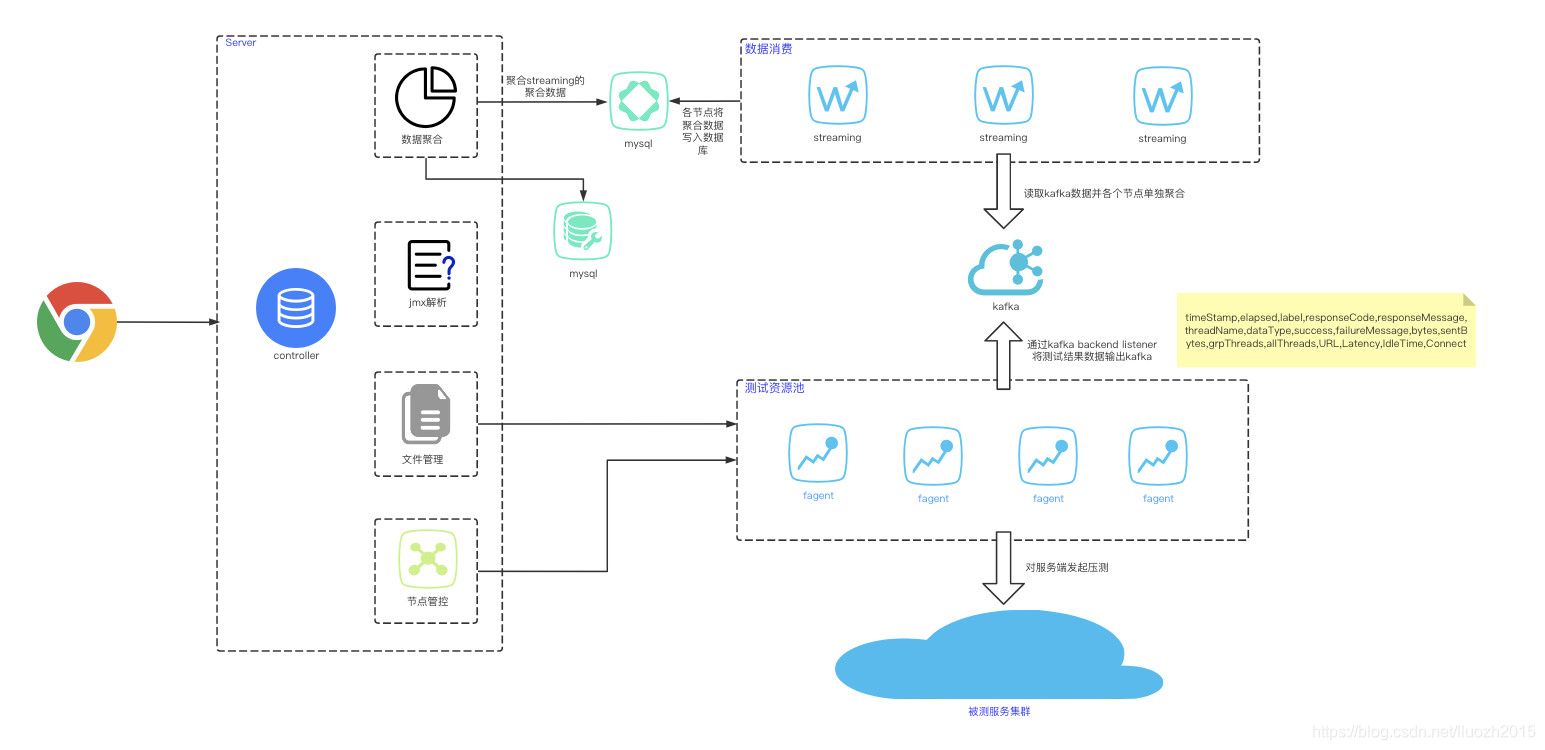
优势
-
backend listener
使用backend listener元件中二次开发的开源组件将请求的sample数据直接发送到kafka,实现报告数据异步处理 在/lib/ext目录下添加后即可使用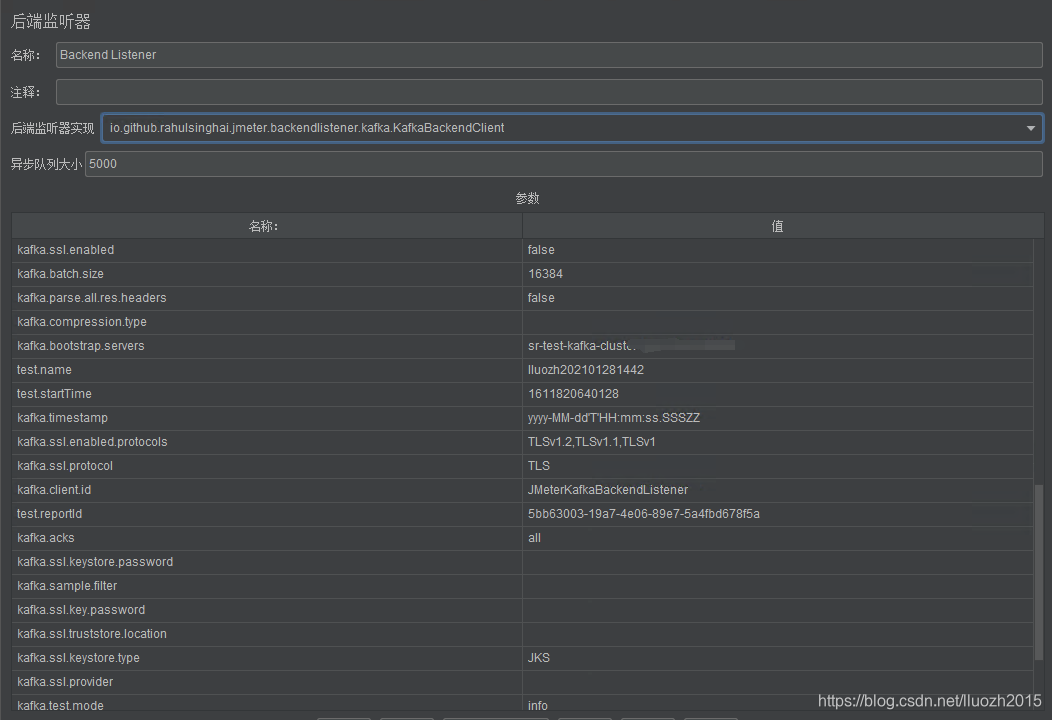
-
kafka中间件
使用高性能的kafka做为数据接收解耦组建
不足
- 报告聚合难度大 根据参数配置,jmeter-backend-listener-kafka组建将请求sample数据1M写入kafka一次,预计400条请求数据,在qps达到1w时,聚合的数据写入mysql已经达到读写的瓶颈
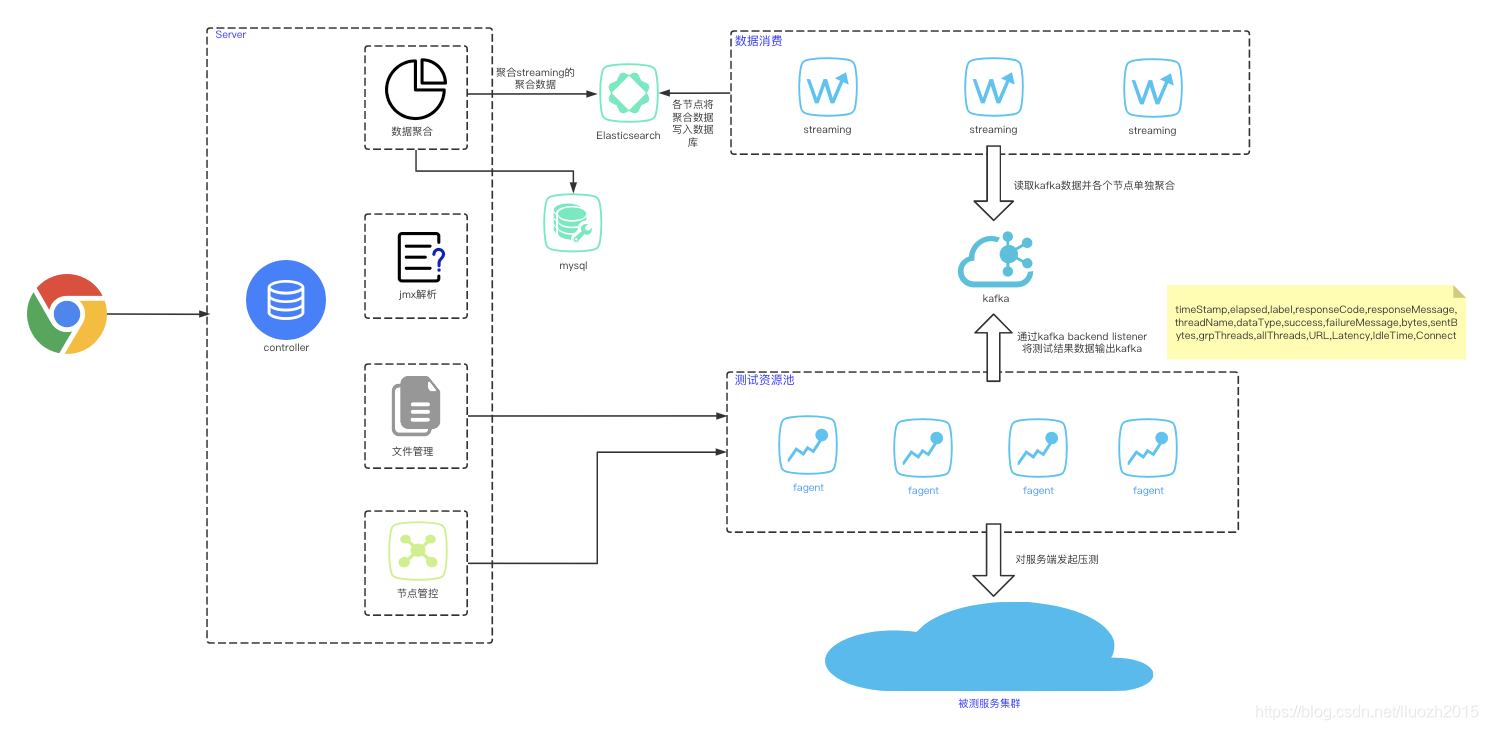
五、Elasticsearch数据写入
需要解决初步组合的数据写入的问题,首先想到的就是使用Elasticsearch替代mysql做为中间数据的存储,当然后面发现这个方案其实是欠缺考虑的
六、数据聚合
按照Furion平台的规划,需要支撑的qps 20w,报告执行10min,那么产生的数据量20w1060 = 1.2亿,单次聚合至少1.2亿条数据需要的CPU和时间是无法接受的
既然每次都一次性聚合所有的数据是不现实的,那么需要不断的聚合中间数据并累加聚合的方式
6.1 核心数据栗子
RequestStatistics
[ { "label":"lluozh", "samples":"8627", "ko":"2", "error":"0.02", "average":"572.98", "min":"88", "max":"14432", "tp90":"1327.20", "tp95":"1695.40", "tp99":"2386.20", "transactions":"0.19", "received":"5.11", "sent":"0.10" }] ResponseTimeChart
[{ "xAxis":"20:53:00","yAxis":9.05,"yAxis2":-1,"groupName":"获取上传信息","description":null},{ "xAxis":"20:58:00","yAxis":9.50,"yAxis2":-1,"groupName":"获取上传信息","description":null},{ "xAxis":"20:57:00","yAxis":9.79,"yAxis2":-1,"groupName":"获取上传信息","description":null},{ "xAxis":"20:51:00","yAxis":8.08,"yAxis2":-1,"groupName":"获取上传信息","description":null},{ "xAxis":"20:56:00","yAxis":9.60,"yAxis2":-1,"groupName":"获取上传信息","description":null},{ "xAxis":"20:54:00","yAxis":9.94,"yAxis2":-1,"groupName":"获取上传信息","description":null},{ "xAxis":"20:59:00","yAxis":9.88,"yAxis2":-1,"groupName":"获取上传信息","description":null},{ "xAxis":"20:53:00","yAxis":-1,"yAxis2":496.80,"groupName":"更新用户信息","description":null},{ "xAxis":"20:58:00","yAxis":-1,"yAxis2":512.73,"groupName":"更新用户信息","description":null},{ "xAxis":"20:57:00","yAxis":-1,"yAxis2":547.99,"groupName":"更新用户信息","description":null},{ "xAxis":"20:51:00","yAxis":-1,"yAxis2":466.45,"groupName":"更新用户信息","description":null},{ "xAxis":"20:56:00","yAxis":-1,"yAxis2":542.70,"groupName":"更新用户信息","description":null}] 6.2 数据类型
- 记录每组sample每个时刻点的响应时间sum以及count
比如:average、error等
- 记录每组sample每个时刻点的特定值响应时间
比如:min、max等
- 记录每组sample每个时刻点不同响应时间的值以及出现的频次
比如:tp90、tp95、tp99等
第1和第2种数据记录的数据量及统计方式相对简单一些,第3种数据记录的数据量庞大(比如每秒的响应时间在1ms-3000ms分布)
6.3 分布式
对于压测数据由单台设备进行计算性能同样出现瓶颈,这时候需要对于产生的数据由多台机器分布式进行计算后汇总
- 方案
将数据进行哈希计算,不同的机器处理指定哈希值的数据块,处理后再将数据进行聚合
6.4 问题
此方案从技术上可行,但是需要考虑或者说问题点在于:
-
人力成本
需要对数据进行收集、上报、哈希、遍历、汇总、聚合等等模块的实现,需要一定的开发工作量 -
资源成本
需要使用ES、Stream服务器等等硬件资源,成本较高
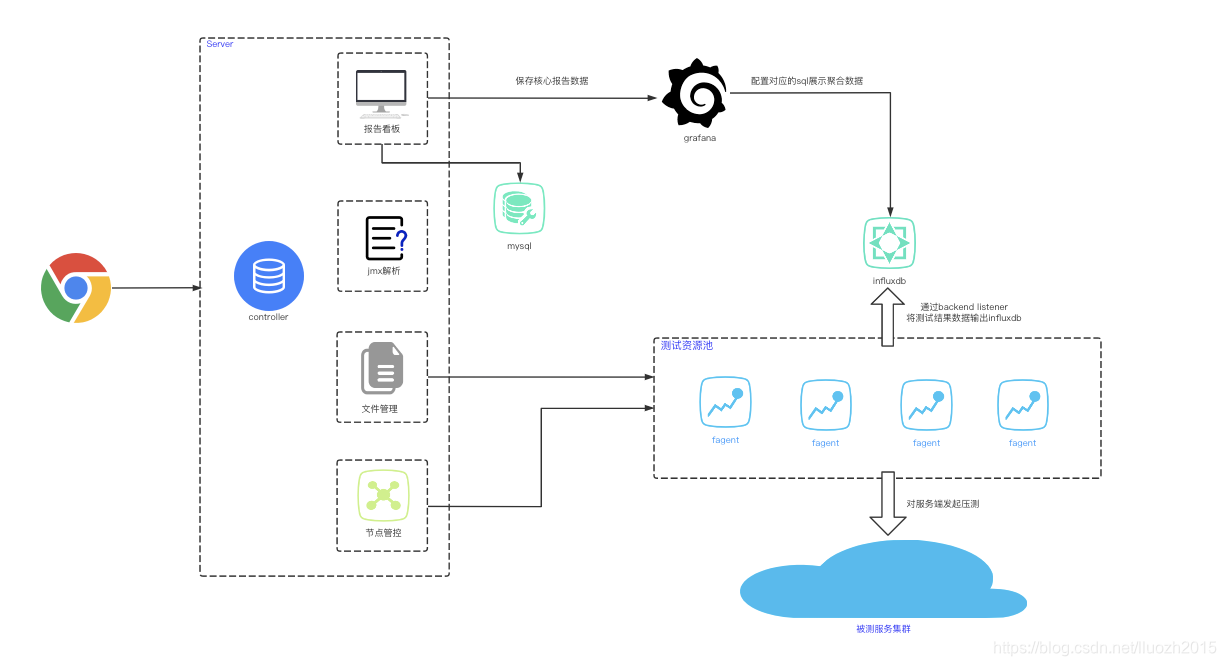
七、JMeter+Influxdb+Grafana
通过Backend Listener发送请求数据到Influxdb,然后Grafana展示报告数据,方案和数据聚合方案一致,但是极大降低人力成本和资源成本即可解决问题
转载地址:https://lluozh.blog.csdn.net/article/details/113623814 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
