本文共 12048 字,大约阅读时间需要 40 分钟。
为什么要写这篇文章?
今儿写代码时,一位前辈看到了我满篇的if+else if,他告诉我说:尽量使用switch来代替if+else if,if+else if效率比switch低,会增加无用的判断!
年轻的我差点就信了!
那么switch和if+else if的效率问题真的就如他所言?对我来说,这真的是个很有趣的问题!
同时我也想要知道,在我们实际开发中,什么时候用switch,什么时候用if+else if合适呢?
再后来,就引发了我更多的思考,switch它到底拿着我的判断条件是怎么操作的?
人年纪大了,什么都想问个为什么,这也是我想要写这篇文章的一个动机。

你有没有想过switch内部是怎么实现的?
就以下几种switch不同值的情况来进行分析吧!
1、switch的case值是连续的。
我就先端一盘代码出来吧,switch的正常代码:
public class TestSwitch { public int testSwitch(int t) { int result= 0; switch (t) { case 0: result= 100; break; case 1: result= 200; break; case 2: result= 300; break; } return result; }} 这上面是一份很本分的switch代码,现在我们来看一下该代码在反汇编后的情况:
public class com.tang.demoapplication.TestPart.TestSwitch { public com.tang.demoapplication.TestPart.TestSwitch(); Code: 0: aload_0 //将this引用推送至栈顶,即压入栈 1: invokespecial #1 // Method java/lang/Object." ":()V 4: return public int testSwitch(int); Code: 0: iconst_0 1: istore_2 2: iload_1 3: tableswitch { // A: 0 to 2 :从栈顶中弹出元素,检查是否在[0,2]之内 0: 28 //当code=0时,跳到28的位置,返回值100 1: 34 //当code=1时,跳到34的位置,返回值200 2: 41 //当code=2时,跳到41的位置,返回值300 default: 45 // B: 如果不在[0,2]内,则程序计数器跳转到第45行 } 28: bipush 100 //将常量100压入栈顶 30: istore_2 //将栈顶元素10存入局部变量表的第3个位置上 31: goto 45 //跳转到45行 34: sipush 200 37: istore_2 //将一个数值从操作数栈存储到局部变量表 38: goto 45 41: sipush 300 44: istore_2 45: iload_2 46: ireturn} Tips:JVM字节码命令
- istore_n:将一个数值从操作数栈存储到局部变量表。 举例:istore_0 将栈顶int型数值存入第一个本地变量;lstore_0 将栈顶long型数值存入第一个本地变量,float、double同理
- iload_n:将一个局部变量加载到操作栈。 举例:iload_0将第一个int型本地变量推送至栈顶;lload_0将第一个long型本地变量推送至栈顶,float、double同理
- sipush:将一个常量加载到操作数栈
- iconst_i:将一个常量加载到操作数栈。 举例:iconst_0 将int型(0)推送至栈顶;lconst_0 将long型(0)推送至栈顶,float、double同理

你先记住上面这个 tableswitch ,它身上戏有点多。它要和下面的不连续的情况来进行对比,你才能更加深刻地感受到两者的差异!
2、switch的case值不是连续的
public class TestSwitch { public int testSwitch(int t) { int result = 0; switch (t) { case 0: result = 100; break; case 4: result = 200; break; case 9: result = 300; break; } return result ; }} 汇编结果:
public class com.tang.demoapplication.TestPart.TestSwitch { public com.tang.demoapplication.TestPart.TestSwitch(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object." ":()V 4: return public int testSwitch(int); Code: 0: iconst_0 1: istore_2 2: iload_1 3: lookupswitch { //!!注意此时是lookupswitch 0: 36 //当值为0时,跳转到36行,返回值100 4: 42 //当值为4时,跳转到42行,返回值200 9: 49 default: 53 } 36: bipush 100 38: istore_2 39: goto 53 42: sipush 200 45: istore_2 46: goto 53 49: sipush 300 52: istore_2 53: iload_2 54: ireturn} (“上面是汇编,看不懂很正常!”,我自言自语道。)
 好的,出现了,一个新名词:
好的,出现了,一个新名词:lookupswitch! 显而易见,当switch的值为有序的时候,用的是tableswitch;而当switch的值是无序的时候,用的是lookupswitch。
tableswitch
- 它会进行范围检查,检查不通过则直接执行default。如果检查通过,则执行相应的case;
- 它使用数据结构存储偏移量,可利用
下标快速定位到偏移量(因为是连续的,可以想象一下吧)。
lookupswitch
- 它是无需时会使用。当条件大面积不连续时,lookupswitch会产生大量的额外空间;
- 使用lookupswitch,会将case进行排序,然后将值拿进去
二分法查找对应的分支偏移量。
3、switch的case类型为String
public class TestSwitch { public int testSwitch(String t) { int result = 0; switch (t) { case "a": result = 100; break; case "d": result = 200; break; case "f": result = 300; break; } return result ; }} class编译结果:
public class TestSwitch { public TestSwitch() { } public int testSwitch(String t) { int result = 0; byte var4 = -1; switch(t.hashCode()) { case 97: if (t.equals("a")) { var4 = 0; } break; case 100: if (t.equals("d")) { var4 = 1; } break; case 102: if (t.equals("f")) { var4 = 2; } } switch(var4) { case 0: result = 100; break; case 1: result = 200; break; case 2: result = 300; } return result ; }} 汇编结果:
public class com.tang.demoapplication.TestPart.TestSwitch { public com.tang.demoapplication.TestPart.TestSwitch(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object." ":()V 4: return public int testSwitch(java.lang.String); Code: 0: iconst_0 1: istore_2 2: aload_1 3: astore_3 4: iconst_m1 5: istore 4 7: aload_3 8: invokevirtual #2 // Method java/lang/String.hashCode:()I 11: lookupswitch { //这里先将‘a’,'d','f'转化为hashcode 97: 44 100: 59 102: 74 default: 86 } 44: aload_3 //将第四个引用类型本地变量推送至栈顶 45: ldc #3 // String a ldc:将int, float或String型常量值从常量池中推送至栈顶 47: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z 50: ifeq 86 53: iconst_0 54: istore 4 56: goto 86 59: aload_3 60: ldc #5 // String d 62: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z 65: ifeq 86 68: iconst_1 69: istore 4 71: goto 86 74: aload_3 75: ldc #6 // String f 77: invokevirtual #4 // Method java/lang/String.equals:(Ljava/lang/Object;)Z 80: ifeq 86 83: iconst_2 84: istore 4 86: iload 4 88: tableswitch { // 0 to 2 0: 116 1: 122 2: 129 default: 133 } 116: bipush 100 118: istore_2 119: goto 133 122: sipush 200 125: istore_2 126: goto 133 129: sipush 300 132: istore_2 133: iload_2 134: ireturn} 这里你会看到:这不仅仅是只用了tableswitch或者lookupswitch,而是两者都使用到了。
 上面的代码,大家肯定有众多疑问!
上面的代码,大家肯定有众多疑问! 
-
JDK所谓的switch支持String是真的支持吗?
针对String类型的switch,实际是取得该String字符串哈希值再进行的switch。
说到底,实际JVM仍然还是不支持这种String参数的语法结构,我们可以看做是一颗语法糖。 -
class代码中,增加了
equals判断,这有啥用?这样能避免哈希冲突导致问题!
-
为何class底层会使用两个switch,明明一个就够了呀?
假设底层只有一个switch,我们来设想一个场景:
假如我们编写的代码使用100个case,且这些case都没有break。我们从上面知道,switch(String) 底层用到了equals判断。那么,在真正执行的时候,是不是就不得不执行一百次equals操作?答案是肯定的,所以,switch(String) 底层使用了两个switch,第一个switch只用于快速定位一个case,且会立马break(不管你编写的代码是否有break,它这儿都会break),第二个switch才进行具体的逻辑执行!
4、switch的case类型为枚举(enum )
public class TestSwitch { public enum TestEnum{ ENUM1,ENUM2,ENUM3 } public int testSwitch(TestEnum t) { int result = 0; switch (t) { case ENUM1: result = 100; break; case ENUM2: result = 200; break; case ENUM3: result = 300; break; } return resultNum; }} 汇编结果:
public class com.tang.demoapplication.TestPart.TestSwitch { public com.tang.demoapplication.TestPart.TestSwitch(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object." ":()V 4: return public int testSwitch(com.tang.demoapplication.TestPart.TestSwitch$TestEnum); Code: 0: iconst_0 1: istore_2 2: getstatic #2 // Field com/tang/demoapplication/TestPart/TestSwitch$1.$SwitchMap$com$tang$demoapplication$TestPart$TestSwitch$TestEnum:[I 5: aload_1 6: invokevirtual #3 // Method com/tang/demoapplication/TestPart/TestSwitch$TestEnum.ordinal:()I 9: iaload 10: tableswitch { // 1 to 3 1: 36 2: 42 3: 49 default: 53 } 36: bipush 100 38: istore_2 39: goto 53 42: sipush 200 45: istore_2 46: goto 53 49: sipush 300 52: istore_2 53: iload_2 54: ireturn} 不知道大家有没有注意到这句代码:
6: invokevirtual #3 // Method com/tang/demoapplication/TestPart/TestSwitch$TestEnum.ordinal:()I 这里面执行了ordinal(),那么这个方法是哪里来的呢?
带着问题,那我们接着往下看!
我们注意到编译该文件的时候,我们的文件多了几个class,TestSwitch1.class和TestSwitchTestEnum.class,而TestSwitch.class是毋庸置疑就有的:
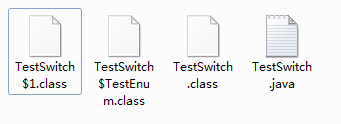 我们就看一下另外两个文件内容分别是什么吧!
我们就看一下另外两个文件内容分别是什么吧! TestSwitch$1.class:
class TestSwitch$1 { static { try { $SwitchMap$com$tang$demoapplication$TestPart$TestSwitch$TestEnum[TestEnum.ENUM1.ordinal()] = 1; } catch (NoSuchFieldError var3) { } try { $SwitchMap$com$tang$demoapplication$TestPart$TestSwitch$TestEnum[TestEnum.ENUM2.ordinal()] = 2; } catch (NoSuchFieldError var2) { } try { $SwitchMap$com$tang$demoapplication$TestPart$TestSwitch$TestEnum[TestEnum.ENUM3.ordinal()] = 3; } catch (NoSuchFieldError var1) { } }} TestSwitch$TestEnum.class(感觉这里面没什么彩蛋可以分析的):
public enum TestSwitch$TestEnum { ENUM1, ENUM2, ENUM3; private TestSwitch$TestEnum() { }} 好的,我们就先分析TestSwitch$1.class吧!
你应该注意到TestSwitch$1.class里面的ordinal()方法。那也就找到了我们反汇编内的ordinal()宿主。
也就是说:在这个TestSwitch$1.class里,声明了一个静态的数组,数组利用枚举的ordinal()值作为下标,数组中的元素依次递增。
那么该数组的作用是什么?
从汇编的代码可以看出:
- 我们首先获取到了静态数组
- 再调用枚举的
ordinal()来获取枚举值 - 再将这个值作为静态数组的下标,获取这个静态数组中的某个值
- 再使用这个值去lookupswitch或tableswitch中去寻找值。
5、switch的case为包装类型
public class TestSwitch { public int testSwitch(Byte i){ int result=0; switch (i){ case 1: result=100; break; case 2: result=200; break; case 3: result=300; break; } return result; }} 汇编结果:
public class com.tang.demoapplication.TestPart.TestSwitch { public com.tang.demoapplication.TestPart.TestSwitch(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object." ":()V 4: return public int testSwitch(java.lang.Byte); Code: 0: iconst_0 1: istore_2 2: aload_1 3: invokevirtual #2 // Method java/lang/Byte.byteValue:()B (该处的byteValue是重点!) 6: tableswitch { // 1 to 3 1: 32 2: 38 3: 45 default: 49 } 32: bipush 100 34: istore_2 35: goto 49 38: sipush 200 41: istore_2 42: goto 49 45: sipush 300 48: istore_2 49: iload_2 50: ireturn} 我们可以看到在进入tableswitch之前执行了一个byteValue()方法,该方法完成对byte的拆箱工作,然后比较byte值就行了。
switch小结
就上面的几种类型,这里进行汇总。
- 当switch值为int时:数据是连续的,使用
tableswitch进行判断;数据不是连续的,使用lookupswitch进行判断 - 当switch值为String时:现将String值转换成
hashcode,随后采用equal判断,用一个新值来进行tableswitch判断。 - 当switch值为Enum时:自动生成
SwitchMap数组,下标是枚举的ordinal()`,值是从1开始递增的整数。 - 包装类型:先进行拆箱,然后
tableswitch/lookupswitch判断。
switch和if+else if的抉择

switch,什么时候if+else if? 根据大量的实际程序测试(不考虑不同的编译器优化程度差异,假设都是最好的优化),那么switch语句击中第三个选项的时间跟if+else if语句击中第三个选项的时间相同!
击中第一,第二选项的速度if+else if语句快,击中第四以及第四之后的选项的速度switch语句快!
在实际开发中,到底你是用switch还是if+else if,其实影响没有特别大,本文纯属个人觉得有趣~
参考了大牛的博客,自己再手动来操作和观察,同时也咨询了一下小伙伴@localhost01,耗费了挺长的时间,感恩各位开路大牛。
 更多文章,请关注:开猿笔记
更多文章,请关注:开猿笔记 
转载地址:https://localhost01.blog.csdn.net/article/details/107718467 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
