本文共 4262 字,大约阅读时间需要 14 分钟。
学习交流加
- 个人qq: 1126137994
- 个人微信: liu1126137994
- 学习交流资源分享qq群: 962535112
牛客网题目链接:
文章目录
题目描述
输入一个链表,按链表值从尾到头的顺序返回一个ArrayList。
本题较为简单。有两种解法:递归和使用栈循环。
1、递归解法
递归解法,也可以有两种写法。
1.1、 递归解法一
先上代码,下面给解释:
java代码:
import java.util.ArrayList;public class Solution { ArrayList arrayList=new ArrayList ();//注意这个ArrayList必须在方法体外定义 public ArrayList printListFromTailToHead(ListNode listNode) { if(listNode!=null){ this.printListFromTailToHead(listNode.next); arrayList.add(listNode.val); } return arrayList; }} C++代码
class Solution { public: vector res;//注意这个vector必须在成员函数外定义 vector printListFromTailToHead(ListNode* head) { if(head!=nullptr){ this->printListFromTailToHead(head->next); res.push_back(head->val); } return res; }}; 分析:
这种递归的写法,可以这么想:因为想要从尾到头打印链表,那么如果此链表为空,则直接返回。如果只有一个节点,则将此节点打印。否则,递归打印头结点以后的节点,直到递归到最后一个节点,那么,因为最后一个节点后面为空,所以返回上一级调用,上一级调用后的代码为res.push_back(head->val);,此时的head刚好指向的最后的节点,将最后一个节点先放到数组。然后又返回到上一级的调用,将倒数第二个节点放到数组中。以此类推,直到将第一个节点放到数组中。
我们可以看如下图示来分析上述递归的过程:
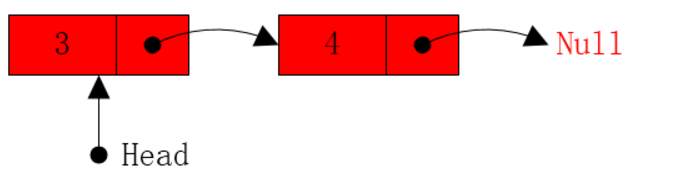
1.刚开始head指向节点1,不为空,将head指针指向下一个节点,然后递归调用函数到第2步
2.此时head依然不为空,将head指针指向下一个节点,然后递归调用函数到第3步
3.此时head依然不为空,将head指针指向下一个节点,然后递归调用函数到第4步
4.此时head依然不为空,将head指针指向下一节点,然后递归调用函数第5步
5.此时head指向空,递归结束,那么递归结束后,就需要返回到上一个递归的步骤,上一步骤是步骤4,那么执行递归语句的下一句:res.push_back(head->val) (C++代码),节点4的值放到数组中。然后再返回到步骤3,将节点3的值放入数组。以此类推,最终从后往前将所有链表节点的值放到数组中。
注意:此种递归方法中,返回数组的定义一定要放在函数体外面定义,如果放在函数体内定义,那么由于递归的层级不同,就会导致每次递归的时候都会重新定义一个数组,导致最后我们只能将第一个节点的值返回,结果肯定是错的。在下一种递归的方法中,返回数组是可以定义在函数体内的,原因见下面解释。



1.2 递归解法二
java代码:
import java.util.ArrayList;public class Solution { public ArrayList printListFromTailToHead(ListNode listNode) { ArrayList resArray = new ArrayList<>(); if(listNode != null){ if(listNode.next != null) resArray = printListFromTailToHead(listNode.next); resArray.add(listNode.val); } return resArray; }} C++代码
class Solution { public: vector printListFromTailToHead(ListNode* head) { vector res; if(head!=nullptr){ if(head->next!=nullptr) res = printListFromTailToHead(head->next); res.push_back(head->val); } return res; }}; 分析: 这种递归,实际上更好理解。首先,如果链表位空,则直接返回空数组。如果链表只有一个节点,则直接返回这个节点的值。如果这个链表不止一个节点,那么递归调用函数得到除了头结点外后面的链表,得到后面的链表的从后往前打印(放到数组)的结果,然后再将之前的头结点打印(放到数组末尾)。那么,最终得到的结果就是整个链表的从后往前打印的结果。
可以简单的以下面图示理解:
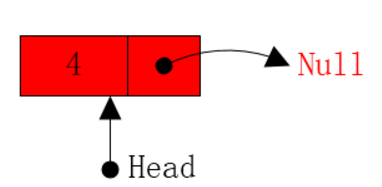
1. 刚开始,head指向头结点,它后面还有节点(具体有几个都无所谓)。将head指向下一个节点,然后递归调用函数。
2.现在是这样的,从第1步过来,该递归调用函数求现在的这个链表的从后往前打印的结果。我们把现在这剩下的具有三个节点的链表,看成一个黑匣子整体,我的函数要对这个黑匣子求解它的倒序,然后这个函数返回了该链表的倒序的结果{4,3,2}。(其实这里面有好几个递归的过程,但是我们不必将所有的递归过程想出来,只需要知道,现在我们可以将后面剩余的链表看成一个新链表,然后得到它的倒序就行)
3.得到后面的链表的倒序后,是存入数组的,最后我们再将头结点的值,放到数组末尾res.push_back(head->val);,就可以得到{4,3,2,1},这正是我们要的结果。
注意:这里的递归解法中,返回数组的定义,可以放到函数体内,也可以放到函数体外。与第一种递归的不同之处在于,这里我们可以将以下两句话,放在同一个调用栈内看待,即 res = printListFromTailToHead(head->next);这句话得到后面的链表的倒序后,就执行res.push_back(head->val);它们的执行,可以看成是在一个函数调用栈内进行的。而第一种递归调用中如果将返回数组定义在函数体内,每一个调用都是在一个新的函数调用栈,导致每一个函数栈中,都是一个新的返回数组,最终只能得到最顶层的函数栈中的数组,也就是链表的头结点的值。
2、使用栈
递归解法虽然写法简单,但是递归调用需要重新开辟函数调用栈,开销比较大。正常的解法实际上是使用栈来解决(栈这种数据结构本身就与递归有很大的联系)。
可以遍历链表,每遍历一个节点就将节点的值压入到栈中,直到遍历完链表。最后再依次将栈中的元素弹出到返回的数组中。
java代码
import java.util.Stack;import java.util.ArrayList;public class Solution { public ArrayList printListFromTailToHead(ListNode listNode) { Stack st = new Stack<>(); ListNode pListNode = listNode; while(pListNode != null){ st.push(pListNode.val); pListNode = pListNode.next; } ArrayList resArray = new ArrayList<>(); while(!st.isEmpty()){ resArray.add(st.pop()); } return resArray; }} C++代码
class Solution { public: vector printListFromTailToHead(ListNode* head) { vector res; stack st; ListNode* p = head; while(p != nullptr){ st.push(p->val); p = p->next; } int len = st.size(); for(int i = 0;i 总结
- 理解递归的精髓,上述两种递归的不一样之处
- 理解递归与栈的关系
学习探讨加:
qq:1126137994 微信:liu1126137994转载地址:https://lyy-0217.blog.csdn.net/article/details/83867750 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
