kaggle研究生招生(中)
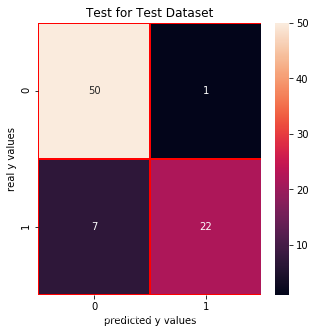
 precision_score: 0.9615384615384616 recall_score: 0.8620689655172413 f1_score: 0.9090909090909091
precision_score: 0.9615384615384616 recall_score: 0.8620689655172413 f1_score: 0.9090909090909091
发布日期:2021-07-01 02:16:48
浏览次数:3
分类:技术文章
本文共 12120 字,大约阅读时间需要 40 分钟。
上次将数据训练了模型
由于数据中的大多数候选人都有70%以上的机会,许多不成功的候选人都没有很好的预测。
df["Chance of Admit"].plot(kind = 'hist',bins = 200,figsize = (6,6))plt.title("Chance of Admit")plt.xlabel("Chance of Admit")plt.ylabel("Frequency")plt.show() 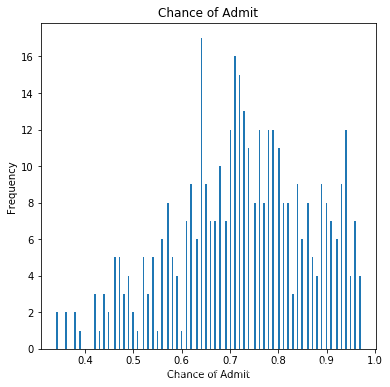
如果候选人的录取机会大于80%,则该候选人将获得1个标签。
如果候选人的录取机会小于或等于80%,则该候选人将获得0标签。# reading the datasetdf = pd.read_csv("../input/Admission_Predict.csv",sep = ",")# it may be needed in the future.serialNo = df["Serial No."].valuesdf.drop(["Serial No."],axis=1,inplace = True)y = df["Chance of Admit"].valuesx = df.drop(["Chance of Admit"],axis=1)# separating train (80%) and test (%20) setsfrom sklearn.model_selection import train_test_splitx_train, x_test,y_train, y_test = train_test_split(x,y,test_size = 0.20,random_state = 42)# normalizationfrom sklearn.preprocessing import MinMaxScalerscalerX = MinMaxScaler(feature_range=(0, 1))x_train[x_train.columns] = scalerX.fit_transform(x_train[x_train.columns])x_test[x_test.columns] = scalerX.transform(x_test[x_test.columns])y_train_01 = [1 if each > 0.8 else 0 for each in y_train]y_test_01 = [1 if each > 0.8 else 0 for each in y_test]# list to arrayy_train_01 = np.array(y_train_01)y_test_01 = np.array(y_test_01) 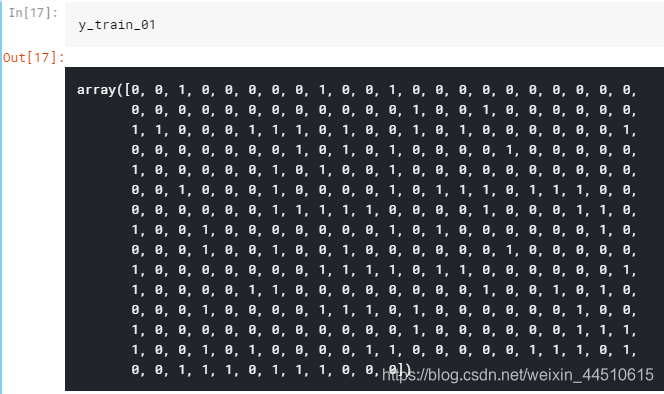
逻辑回归
from sklearn.linear_model import LogisticRegressionlrc = LogisticRegression()lrc.fit(x_train,y_train_01)print("score: ", lrc.score(x_test,y_test_01))print("real value of y_test_01[1]: " + str(y_test_01[1]) + " -> the predict: " + str(lrc.predict(x_test.iloc[[1],:])))print("real value of y_test_01[2]: " + str(y_test_01[2]) + " -> the predict: " + str(lrc.predict(x_test.iloc[[2],:])))# confusion matrixfrom sklearn.metrics import confusion_matrixcm_lrc = confusion_matrix(y_test_01,lrc.predict(x_test))# print("y_test_01 == 1 :" + str(len(y_test_01[y_test_01==1]))) # 29# cm visualizationimport seaborn as snsimport matplotlib.pyplot as pltf, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_lrc,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.title("Test for Test Dataset")plt.xlabel("predicted y values")plt.ylabel("real y values")plt.show()from sklearn.metrics import precision_score, recall_scoreprint("precision_score: ", precision_score(y_test_01,lrc.predict(x_test)))print("recall_score: ", recall_score(y_test_01,lrc.predict(x_test)))from sklearn.metrics import f1_scoreprint("f1_score: ",f1_score(y_test_01,lrc.predict(x_test))) score: 0.9
real value of y_test_01[1]: 0 -> the predict: [0] real value of y_test_01[2]: 1 -> the predict: [1]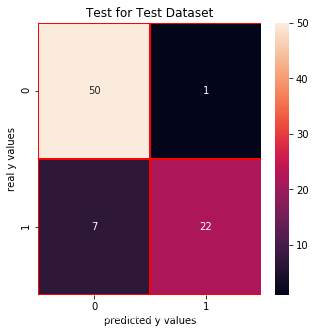
Test for Train Dataset:
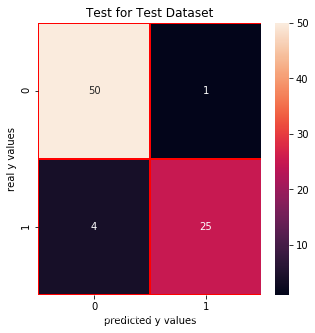
cm_lrc_train = confusion_matrix(y_train_01,lrc.predict(x_train))f, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_lrc_train,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.xlabel("predicted y values")plt.ylabel("real y values")plt.title("Test for Train Dataset")plt.show() 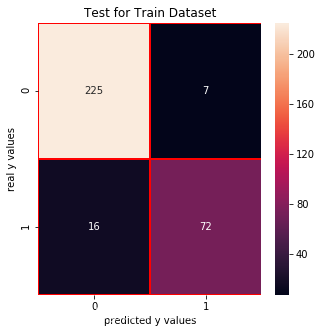
SVC
from sklearn.svm import SVCsvm = SVC(random_state = 1)svm.fit(x_train,y_train_01)print("score: ", svm.score(x_test,y_test_01))print("real value of y_test_01[1]: " + str(y_test_01[1]) + " -> the predict: " + str(svm.predict(x_test.iloc[[1],:])))print("real value of y_test_01[2]: " + str(y_test_01[2]) + " -> the predict: " + str(svm.predict(x_test.iloc[[2],:])))# confusion matrixfrom sklearn.metrics import confusion_matrixcm_svm = confusion_matrix(y_test_01,svm.predict(x_test))# print("y_test_01 == 1 :" + str(len(y_test_01[y_test_01==1]))) # 29# cm visualizationimport seaborn as snsimport matplotlib.pyplot as pltf, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_svm,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.title("Test for Test Dataset")plt.xlabel("predicted y values")plt.ylabel("real y values")plt.show()from sklearn.metrics import precision_score, recall_scoreprint("precision_score: ", precision_score(y_test_01,svm.predict(x_test)))print("recall_score: ", recall_score(y_test_01,svm.predict(x_test)))from sklearn.metrics import f1_scoreprint("f1_score: ",f1_score(y_test_01,svm.predict(x_test))) score: 0.9
real value of y_test_01[1]: 0 -> the predict: [0] real value of y_test_01[2]: 1 -> the predict: [1] precision_score: 0.9565217391304348
recall_score: 0.7586206896551724 f1_score: 0.8461538461538461Test for Train Dataset
cm_svm_train = confusion_matrix(y_train_01,svm.predict(x_train))f, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_svm_train,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.xlabel("predicted y values")plt.ylabel("real y values")plt.title("Test for Train Dataset")plt.show() 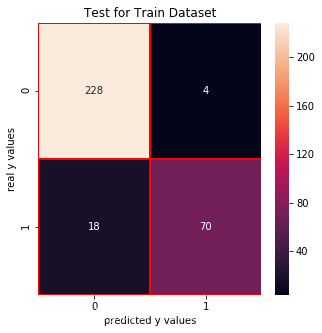
朴素贝叶斯
from sklearn.naive_bayes import GaussianNBnb = GaussianNB()nb.fit(x_train,y_train_01)print("score: ", nb.score(x_test,y_test_01))print("real value of y_test_01[1]: " + str(y_test_01[1]) + " -> the predict: " + str(nb.predict(x_test.iloc[[1],:])))print("real value of y_test_01[2]: " + str(y_test_01[2]) + " -> the predict: " + str(nb.predict(x_test.iloc[[2],:])))# confusion matrixfrom sklearn.metrics import confusion_matrixcm_nb = confusion_matrix(y_test_01,nb.predict(x_test))# print("y_test_01 == 1 :" + str(len(y_test_01[y_test_01==1]))) # 29# cm visualizationimport seaborn as snsimport matplotlib.pyplot as pltf, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_nb,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.title("Test for Test Dataset")plt.xlabel("predicted y values")plt.ylabel("real y values")plt.show()from sklearn.metrics import precision_score, recall_scoreprint("precision_score: ", precision_score(y_test_01,nb.predict(x_test)))print("recall_score: ", recall_score(y_test_01,nb.predict(x_test)))from sklearn.metrics import f1_scoreprint("f1_score: ",f1_score(y_test_01,nb.predict(x_test))) score: 0.9625
real value of y_test_01[1]: 0 -> the predict: [0] real value of y_test_01[2]: 1 -> the predict: [1]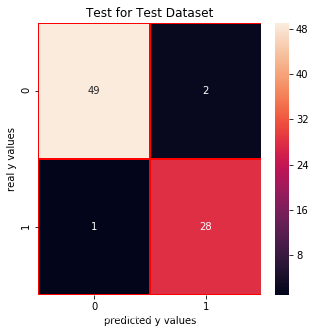
Test for Train Dataset:
cm_nb_train = confusion_matrix(y_train_01,nb.predict(x_train))f, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_nb_train,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.xlabel("predicted y values")plt.ylabel("real y values")plt.title("Test for Train Dataset")plt.show() 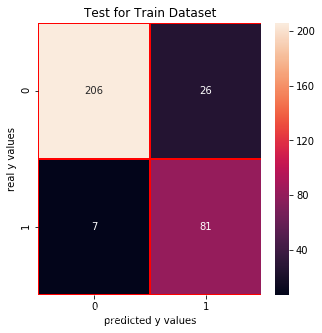
决策树
from sklearn.tree import DecisionTreeClassifierdtc = DecisionTreeClassifier()dtc.fit(x_train,y_train_01)print("score: ", dtc.score(x_test,y_test_01))print("real value of y_test_01[1]: " + str(y_test_01[1]) + " -> the predict: " + str(dtc.predict(x_test.iloc[[1],:])))print("real value of y_test_01[2]: " + str(y_test_01[2]) + " -> the predict: " + str(dtc.predict(x_test.iloc[[2],:])))# confusion matrixfrom sklearn.metrics import confusion_matrixcm_dtc = confusion_matrix(y_test_01,dtc.predict(x_test))# print("y_test_01 == 1 :" + str(len(y_test_01[y_test_01==1]))) # 29# cm visualizationimport seaborn as snsimport matplotlib.pyplot as pltf, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_dtc,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.title("Test for Test Dataset")plt.xlabel("predicted y values")plt.ylabel("real y values")plt.show()from sklearn.metrics import precision_score, recall_scoreprint("precision_score: ", precision_score(y_test_01,dtc.predict(x_test)))print("recall_score: ", recall_score(y_test_01,dtc.predict(x_test)))from sklearn.metrics import f1_scoreprint("f1_score: ",f1_score(y_test_01,dtc.predict(x_test))) score: 0.9375
real value of y_test_01[1]: 0 -> the predict: [0] real value of y_test_01[2]: 1 -> the predict: [1]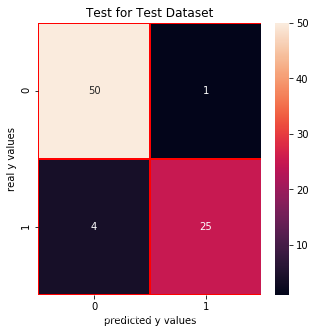
precision_score: 0.9615384615384616
recall_score: 0.8620689655172413 f1_score: 0.9090909090909091Test for Train Dataset
cm_dtc_train = confusion_matrix(y_train_01,dtc.predict(x_train))f, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_dtc_train,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.xlabel("predicted y values")plt.ylabel("real y values")plt.title("Test for Train Dataset")plt.show() 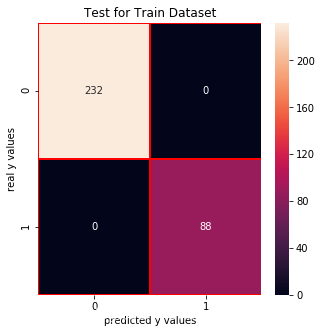
随机森林
from sklearn.ensemble import RandomForestClassifierrfc = RandomForestClassifier(n_estimators = 100,random_state = 1)rfc.fit(x_train,y_train_01)print("score: ", rfc.score(x_test,y_test_01))print("real value of y_test_01[1]: " + str(y_test_01[1]) + " -> the predict: " + str(rfc.predict(x_test.iloc[[1],:])))print("real value of y_test_01[2]: " + str(y_test_01[2]) + " -> the predict: " + str(rfc.predict(x_test.iloc[[2],:])))# confusion matrixfrom sklearn.metrics import confusion_matrixcm_rfc = confusion_matrix(y_test_01,rfc.predict(x_test))# print("y_test_01 == 1 :" + str(len(y_test_01[y_test_01==1]))) # 29# cm visualizationimport seaborn as snsimport matplotlib.pyplot as pltf, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_rfc,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.title("Test for Test Dataset")plt.xlabel("predicted y values")plt.ylabel("real y values")plt.show()from sklearn.metrics import precision_score, recall_scoreprint("precision_score: ", precision_score(y_test_01,rfc.predict(x_test)))print("recall_score: ", recall_score(y_test_01,rfc.predict(x_test)))from sklearn.metrics import f1_scoreprint("f1_score: ",f1_score(y_test_01,rfc.predict(x_test))) score: 0.9375
real value of y_test_01[1]: 0 -> the predict: [0] real value of y_test_01[2]: 1 -> the predict: [1] precision_score: 0.9615384615384616 recall_score: 0.8620689655172413 f1_score: 0.9090909090909091 Test for Train Dataset
cm_rfc_train = confusion_matrix(y_train_01,rfc.predict(x_train))f, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_rfc_train,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.xlabel("predicted y values")plt.ylabel("real y values")plt.title("Test for Train Dataset")plt.show() 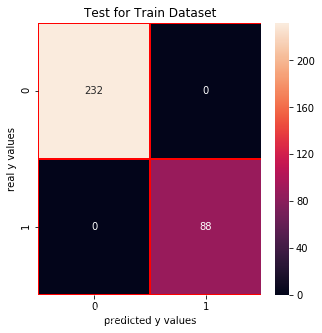
kNN
from sklearn.neighbors import KNeighborsClassifier# finding k valuescores = []for each in range(1,50): knn_n = KNeighborsClassifier(n_neighbors = each) knn_n.fit(x_train,y_train_01) scores.append(knn_n.score(x_test,y_test_01)) plt.plot(range(1,50),scores)plt.xlabel("k")plt.ylabel("accuracy")plt.show()knn = KNeighborsClassifier(n_neighbors = 3) # n_neighbors = kknn.fit(x_train,y_train_01)print("score of 3 :",knn.score(x_test,y_test_01))print("real value of y_test_01[1]: " + str(y_test_01[1]) + " -> the predict: " + str(knn.predict(x_test.iloc[[1],:])))print("real value of y_test_01[2]: " + str(y_test_01[2]) + " -> the predict: " + str(knn.predict(x_test.iloc[[2],:])))# confusion matrixfrom sklearn.metrics import confusion_matrixcm_knn = confusion_matrix(y_test_01,knn.predict(x_test))# print("y_test_01 == 1 :" + str(len(y_test_01[y_test_01==1]))) # 29# cm visualizationimport seaborn as snsimport matplotlib.pyplot as pltf, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_knn,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.title("Test for Test Dataset")plt.xlabel("predicted y values")plt.ylabel("real y values")plt.show()from sklearn.metrics import precision_score, recall_scoreprint("precision_score: ", precision_score(y_test_01,knn.predict(x_test)))print("recall_score: ", recall_score(y_test_01,knn.predict(x_test)))from sklearn.metrics import f1_scoreprint("f1_score: ",f1_score(y_test_01,knn.predict(x_test))) 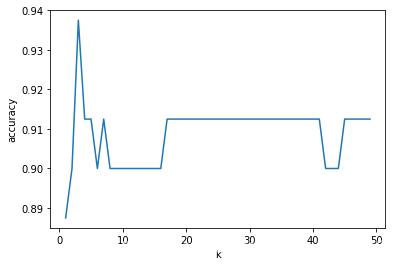
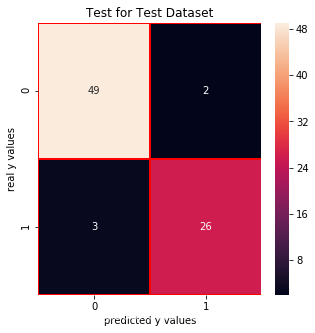
Test for Train Dataset:
cm_knn_train = confusion_matrix(y_train_01,knn.predict(x_train))f, ax = plt.subplots(figsize =(5,5))sns.heatmap(cm_knn_train,annot = True,linewidths=0.5,linecolor="red",fmt = ".0f",ax=ax)plt.xlabel("predicted y values")plt.ylabel("real y values")plt.title("Test for Train Dataset")plt.show() 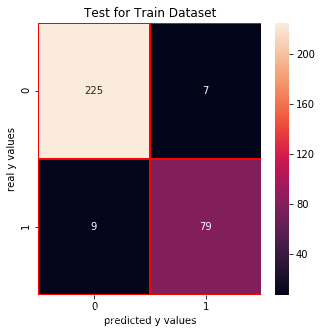
y = np.array([lrc.score(x_test,y_test_01),svm.score(x_test,y_test_01),nb.score(x_test,y_test_01),dtc.score(x_test,y_test_01),rfc.score(x_test,y_test_01),knn.score(x_test,y_test_01)])#x = ["LogisticRegression","SVM","GaussianNB","DecisionTreeClassifier","RandomForestClassifier","KNeighborsClassifier"]x = ["LogisticReg.","SVM","GNB","Dec.Tree","Ran.Forest","KNN"]plt.bar(x,y)plt.title("Comparison of Classification Algorithms")plt.xlabel("Classfication")plt.ylabel("Score")plt.show() 
转载地址:https://maoli.blog.csdn.net/article/details/92020207 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
很好
[***.229.124.182]2024年04月13日 20时52分17秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
共享收集的图像处理方面的一些资源和网站
2019-05-01
图像基本知识
2019-05-01
CMarkup
2019-05-01
网络爬虫(蜘蛛)Scrapy,Python安装!
2019-05-01
38款 流媒体服务器开源软件
2019-05-01
Using GDB in Visual Studio
2019-05-01
网络时间协议简介-----NTP(Network Time Protocol)
2019-05-01
简析STUN协议
2019-05-01
Winsock服务器内存资源管理
2019-05-01
Winsock 完成端口模型简介
2019-05-01
使用 Minidumps 和 Visual Studio .NET 进行崩溃后调试
2019-05-01
Debug 和 Release 编译方式的本质区别
2019-05-01
tomcat6.0配置根目录为自己项目的目录
2019-05-01
关于基于xfire webservice框架开发webservice的总结
2019-05-01
电脑族每天必喝的四杯茶
2019-05-01
关于几个网络编程的java开源框架
2019-05-01
linux安装jdk.tomcat,mysql 的一些记录
2019-05-01
一些js脚本
2019-05-01
String,StringBuffer, StringBuilder 的区别
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311556207 位访客
访问时间: 2024-05-07 02:09:05
访问IP: 3.145.2.184
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版