本文共 4628 字,大约阅读时间需要 15 分钟。
随着云计算、容器技术的不断普及,有越来越多的人开始了解虚拟化、了解Docker。对于大多数初学者来说,他们会困惑:Docker的虚拟化是如何实现的?Docker的虚拟化与传统的虚拟化有啥区别?在Linux内核层面是如何支持Docker虚拟化的?这篇文章就学习一下Docker背后的基础技术LXC(Linux Container)。
一、介绍
LXC是一个非常著名的并且经过严格测试的底层Linux容器运行时。自2008年以来,一直处于活跃的开发状态,并在世界各地的关键生产环境中得到验证。LXC的一些核心贡献者也是帮助在Linux内核内实现各种容器化特性的人。LXC是用于访问Linux内核容器特性的用户空间接口,通过强大的API和简单的工具,Linux用户可以轻松创建和管理系统或应用程序容器。
LXC是一种内核虚拟化技术,能够提供轻量级的虚拟化,它实现了进程级的沙盒封装,能够让一些沙盒进程运行在一块相对独立的空间,能够方便的控制他们的资源调度。

LXC与Docker的区别
二、特性
为了实现Docker的虚拟化,LXC具有以下的内核特性:
1、内核命名空间(Kernel namespaces)
一个命名空间是全局系统资源的抽象封装,只对该命名空间内的进程可见,每个进程都有自己的专属资源。对这些全局资源的更改也只对命名空间内部的成员进程可见,其他进程不可见。命名空间的一个用途是实现容器。
命名空间的类型
下面的表格显示了在Linux内部的命名空间类型。表格的第二列显示了命名空间的标识,在与其他API调用时使用。第三列是这种命名空间类型所隔离的资源信息。
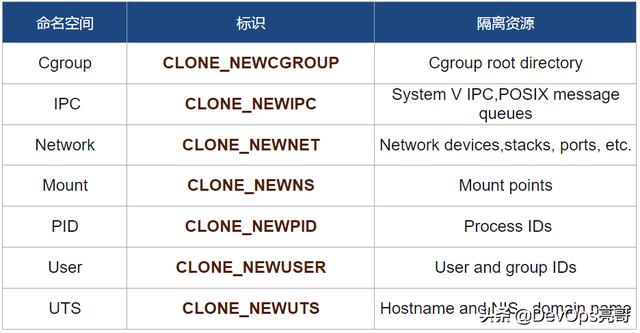
命名空间的类型
创建一个新的命名空间一般使用clone和unshare两个函数,并且需要CAP_SYS_ADMIN权限,因为在新的命名空间里,创建者需要有权限更改这些全局资源让其对后面加入命名空间的进程可见。
下面对每个命名空间进行简要介绍:
①Cgroup命名空间
Cgroup命名空间虚拟化了进程的cgroup视图,比如通过/proc/[pid]/cgroup 和/proc/[pid]/mountinfo看到的样子。每个Cgroup命名空间都有自己的cgroup根目录集。这些根目录是/proc/[pid]/cgroup文件中相应记录显示的相对位置的基点。当进程使用带有CLONE_NEWCGROUP标志的clone和unshare创建新的Cgroup命名空间时,它当前cgroups目录成为这个新命名空间的cgroup根目录。
当从/proc/[pid]/cgroup读取目标进程的cgroup成员关系时,显示在每个记录的第三字段中的路径名是该进程相对于cgroup层级根目录的相对路径。如果目标进程的cgroup目录位于该进程的cgroup命名空间的根目录之外,则路径名将显示cgroup层次结构中每个祖先基本的../条目。
②IPC命名空间
IPC命名空间隔离某些IPC资源,即系统 V IPC对象和POSIX消息队列。这些IPC对象的共同点是由文件系统路径名以为的机制标识。每个IPC命名空间都有其自己的系统V IPC标识符集和其自己的POSIX消息队列文件系统。在IPC命名空间中创建的对象对属于该命名空间的所有其他进程可见,但对其他IPC命名空间的进程不可见。
③Network命名空间
Network命名空间提供了与网络有关的系统资源的隔离,有网络设备、IPv4和IPv6协议栈、IP路由表和防火墙规则。/proc/net目录、/sys/class/net目录以及/proc/sys/net下的各种文件,端口号(Sockets)等等。
④Mount命名空间
Mount命名空间为每个该实例中的进程提供了挂载点的隔离列表。这样,每个挂载空间实例中的进程会看到不一样的目录层级。/proc/[pid]/mounts、/proc/[pid]/mountinfo和/proc/[pid]/mountstats文件的视图与PID这个进程所在的Mount命名空间是一致的。
⑤PID命名空间
PID命名空间隔离了进程ID号空间,意味着在不同PID命名空间中的进程可以有相同的PID。PID命名空间允许容器提供一些其他的功能,如挂起、恢复容器内的进程集,迁移容器到新的主机而容器内的进程ID保持一致。PID命名空间中的PID从1开始。
⑥User命名空间
User命名空间隔离与安全性相关的标识符和属性,尤其是用户ID和组ID,根目录、密钥和功能。进程的用户ID和组ID在User命名空间的内部和外部可以不同。特别是,进程可以在User命名空间之外具有普通的非特权用户ID,而同时在User命名空间内部具有0的用户ID.也就是说,该进程在该User命名空间内部有全部特权,但在User命名空间外部没有特权。
⑦UTS命名空间
UTS命名空间提供了两个系统标识符的隔离:hostname和NIS域名。这些标识符通过sethostname和setdomainname设置,通过uname,gethostname和getdomainname获取。对这些标识符的更改只对该UTS命名空间内的进程可见,其他的UTS命名空间内的进程不可见。

2、Apparmor和SELinux
①AppArmor
AppArmor(Application Armor)是Linux的一种安全软件,是SELinux的替代品。AppArmor是目前市场上最有效且易于使用的Linux应用程序安全系统。AppArmor是一个安全框架,通过强制执行良好的程序行为并防止甚至利用未知的软件漏洞,可以主动包含操作系统和应用程序免受外部或内部威胁。AppArmor安全配置文件完全定义了各种程序可以访问哪些系统资源以及具有哪些特权。AppArmor附带了许多默认策略,并且结合了高级静态分析和基于学习的工具。
AppArmor的特性包括:
1、完全整合。
2、易于部署。
3、AppArmor包括一整套控制台和基于YaST的工具,可帮助开发,部署和维护应用程序安全策略。
4、通过执行适当的应用程序行为,保护操作系统,自定义应用程序和第三方应用程序免受外部和内部威胁。
5、报告和警报。内置功能使您可以安排详细的事件报告并根据用户定义的事件配置警报。
6、子流程限制。AppArmor允许您为单个Perl和PHP脚本定义安全策略,以提高Web服务器的安全性。
②SELinux
Security-Enhanced Linux(SELinux)是一种Linux功能,能够为Linux内核提供各种安全策略。
SELinux的特性包括:
1、将策略和执行彻底分开
2、定义明确的策略接口
3、支持应用程序查询策略并执行访问控制
4、独立于特定策略和策略语言
5、独立于特定的安全标签和内容
6、内核对象和服务单独的标签和控制
7、用于提效的访问策略的缓存
8、支持策略变更
9、保护系统完整性和数据机密性的单独措施
10、非常灵活的策略
11、控制流程的初始化和继承以及程序执行
12、控制文件系统、目录、文件和打开的文件描述符
13、控制套接字、消息和网络接口
14、控制功能的使用

3、Seccomp策略
Seccomp是Linux内核提供的一种应用程序沙箱机制,Seccomp通过只允许应用程序调用指定的系统调用来达到沙箱的效果,Seccomp是用于过滤系统调用的非常有效的方法,当运行不受信的第三方程序时特别有用。
4、Chroots更改根目录
Chroot(Change root directory)更改root目录。在Linux系统中,系统默认的目录结构都是以'/',即以根(root)开始的。而在使用chroot之后,系统的目录结构将以指定的位置作为'/'位置。在经过chroot之后,系统读取到的目录和文件将不再是旧系统根下的而是新根下的目录结构和文件,这样做有3个好处:
①、增加了系统的安全性,限制了用户的权力:
在经过 chroot 之后,在新根下将访问不到旧系统的根目录结构和文件,这样就增强了系统的安全性。这个一般是在登录 (login) 前使用 chroot,以此达到用户不能访问一些特定的文件。
②、建立一个与原系统隔离的系统目录结构,方便用户的开发:
使用 chroot 后,系统读取的是新根下的目录和文件,这是一个与原系统根下文件不相关的目录结构。在这个新的环境中,可以用来测试软件的静态编译以及一些与系统不相关的独立开发。
③、切换系统的根目录位置,引导 Linux 系统启动以及急救系统等。
chroot 的作用就是切换系统的根位置,而这个作用最为明显的是在系统初始引导磁盘的处理过程中使用,从初始 RAM 磁盘 (initrd) 切换系统的根位置并执行真正的 init。另外,当系统出现一些问题时,我们也可以使用 chroot 来切换到一个临时的系统。
5、Kernel capabilities内核功能
为了执行权限检查,传统UNIX是将进程分为两类:特权进程(有效用户ID为0,称为超级用户或root)以及非特权进程(其有效用户ID为非零)特权进程会绕过所有内核权限检查,而非特权进程则要根据进程的凭据(通常是:有效的UID,有效的GID和补充组列表)接受完全的权限检查。Linux Kernel从2.2版本开始,提供了Capabilities 功能,它把特权划分成不同单元,可以只授权程序所需的权限,而非所有特权,每个功能都可以独立的启用和禁用。
6、CGroups(control groups,控制组)
Cgroups是Linux内核提供的一种机制,为系统资源管理提供一个统一的框架。可以把系统任务及其子任务整合到按资源等级划分的不同任务组内。Cgroups 可以限制、记录、隔离进程组所使用的物理资源(包括:CPU、内存、IO等),是构建Docker等一系列虚拟化管理工具的基石。Cgroup有如下四个特点:
①、Cgroups的API以一个伪文件系统的方式实现,即用户可以通过文件操作实现Cgroups的组织管理。
②、Cgroups的组织管理操作单元可以细粒度到线程级别,用户态代码也可以针对系统分配的资源创建和销毁Cgroups,从而实现资源再分配和管理。
③、所有资源管理的功能都以“subsystem(子系统)”的方式实现,接口统一。
④、子进程创建之初与其父进程处于同一个Cgroups的控制组。

三、总结
在刚开始接触Docker时,只知道Docker是也是一种虚拟机,但和传统虚拟机不同的是,Docker是操作系统级别的虚拟化。Docker与Linux内核之间究竟是如何虚拟化的?今天通过这篇文章了解了。LXC这个是虚拟化的基础,更深层次的原理就是Linux内核本身提供的多种技术能够支持实现操作系统级别的虚拟化,最终实现了Docker这种轻量级的,能够改变软件交付的容器技术。
作者:DevOps亮哥
简介:一个在微服务、DevOps、云原生领域不断积累、不断深耕的老码农,您的每一个点赞都是我继续下去的动力,欢迎关注交流。
版权:本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
转载地址:https://blog.csdn.net/weixin_35600779/article/details/112498582 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
