基于sklearn的LogisticRegression二分类实践
本文使用
发布日期:2021-07-01 03:20:08
浏览次数:3
分类:技术文章
本文共 10121 字,大约阅读时间需要 33 分钟。
文章目录
sklearn的逻辑斯谛回归模型,进行二分类预测,并通过调整各种参数,对预测结果进行对比。 1. 预备知识
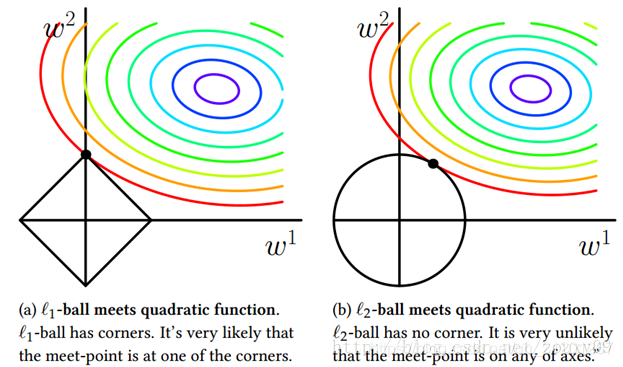
- L0 范数: ∣ ∣ X ∣ ∣ 0 = # ( i ∣ x i ≠ 0 ) ||X||_0 = \#(i|x_i\neq 0) ∣∣X∣∣0=#(i∣xi=0) 向量中非零元素个数,由于它没有一个好的数学表示,难以应用。
- L1 范数: ∣ ∣ X ∣ ∣ 1 = ∑ i = 1 n ∣ x i ∣ ||X||_1 = \sum\limits_{i=1}^n |x_i| ∣∣X∣∣1=i=1∑n∣xi∣ 表示非零元素的绝对值之和
- L2 范数: ∣ ∣ X ∣ ∣ 2 = ∑ i = 1 n x i 2 ||X||_2 = \sqrt{\sum\limits_{i=1}^n {x_i}^2} ∣∣X∣∣2=i=1∑nxi2 表示元素的平方和再开方
- 一般来说,监督学习可以看做最小化下面的目标函数: ω ∗ = arg min ω ∑ i L ( y i , f ( x i ; ω ) ) + λ Ω ( ω ) \omega^* = \argmin\limits_\omega \sum\limits_i L(y_i, f(x_i;\omega))+\lambda \Omega(\omega) ω∗=ωargmini∑L(yi,f(xi;ω))+λΩ(ω) L L L 是损失项(训练误差), Ω \Omega Ω 项是对参数 ω \omega ω 的规则化函数,去约束模型,使之尽量简单, λ \lambda λ 为系数,在sklearn的参数中 C = 1 / λ C = 1/\lambda C=1/λ。
- L1 范数是指向量中各个元素绝对值之和,也叫“稀疏规则算子”(Lasso regularization)
- L1 范数和 L0 范数可以实现稀疏(趋于产生少量特征,其他为0),L1 因具有比 L0 更好的优化求解特性而被广泛应用。
- L2 范数是指向量各元素的平方和然后求平方根
- L2 范数可以防止过拟合,提升模型的泛化能力(选择更多的特征,特征都会接近0)。
一文对模型的参数进行了说明
sklearn 中文文档
2. 实践代码
- 生成以
y=-x^2+1.5为分类线的数据集 - 为增加模型学习难度,将随机抽取的10%的数据强行赋值为正类
- 尝试通过特征的多项式升维、归一化,然后交给LR模型,训练一个分类曲线。
- 为了学习到合适的分类曲线,我们尝试了不同的参数组合
''' 遇到不熟悉的库、模块、类、函数,可以依次: 1)百度(google确实靠谱一些),如"matplotlib.pyplot",会有不错的博客供学习参考 2)"终端-->python-->import xx-->help(xx.yy)",一开始的时候这么做没啥用,但作为资深工程师是必备技能 3)试着修改一些参数,观察其输出的变化,在后面的程序中,会不断的演示这种办法'''# written by hitskyer# modified by Michael Ming on 2020.2.12import sysimport numpy as npimport matplotlib.pyplot as plt# sklearn 中文文档 https://sklearn.apachecn.org/docs/0.21.3/from sklearn.model_selection import train_test_splitfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegressionfrom sklearn import metricsdef get_parabolic_curve_data_set(n): # 设置随机数的种子,以保证每回运行程序的随机结果一致 np.random.seed(520) # 520 可以随便写 Seed must be between 0 and 2**32 - 1 # 随机生成200个样本,每个样本两维特征 # X = np.random.normal(0, 1, size=(n, 2)) # 正态分布,中心0,标准差1 # 更改X的分布(正态,均匀),看看结果有什么变化 X = np.random.uniform(-4, 4, size=(n, 2)) # 均匀分布,区间[-4,4) # 分类面(线)是y=-x^2+1.5,开口向下的抛物线,口内为1类,口外为0类 y = np.array(X[:, 0] ** 2 + X[:, 1] < 1.5, dtype=int) # 满足关系的为1,否则为0 # 加入10%的噪声数据 for _ in range(n // 10): # //为整除 y[np.random.randint(n)] = 1 return X, ydef show_data_set(X, y): plt.scatter(X[y == 0, 0], X[y == 0, 1], c='r') # 散点图,分量1,为y==0的行的0列,分量2,y==0的行的1列,c表示颜色 plt.scatter(X[y == 1, 0], X[y == 1, 1], c='b') plt.show()def PolynomialLogisticRegression(degree=2, C=1.0, penalty='l2'): # 对输入特征依次做 多项式转换、归一化转换、类别预测,可以尝试注释掉前2个操作,看看结果有什么不同 return Pipeline([ # Pipeline 可以把多个评估器链接成一个。例如特征选择、标准化和分类 # 以多项式的方式对原始特征做转换,degree次多项式 ('poly', PolynomialFeatures(degree=degree)), # 对多项式转换后的特征向量做归一化处理,例如(数据-均值)/标准差 ('std_scaler', StandardScaler()), # 用转换后的特征向量做预测,penalty是正则化约束,C正则化强度,值越小,强度大 # solver 不同的求解器擅长的规模类型差异 # 正则化 https://blog.csdn.net/zouxy09/article/details/24971995/ ('log_reg', LogisticRegression(C=C, penalty=penalty, solver="liblinear", max_iter=10000)) ])def plot_decision_boundary(x_min, x_max, y_min, y_max, pred_func): h = 0.01 # 产生网格 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # ravel将矩阵展平,np_c[a,b]将a,b按列拼在一起 Z = pred_func(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral) # 填充等高线 # 等高线参考 https://blog.csdn.net/lens___/article/details/83960810def test(X_train, X_test, y_train, y_test, degree=2, C=1.0, penalty='l2'): poly_log_reg = PolynomialLogisticRegression(degree=degree, C=C, penalty=penalty) # 训练模型 poly_log_reg.fit(X_train, y_train) # 在训练数据上做测试 predict_train = poly_log_reg.predict(X_train) sys.stdout.write("LR(degree = %d, C=%.2f, penalty=%s) Train Accuracy : %.4g\n" % ( degree, C, penalty, metrics.accuracy_score(y_train, predict_train))) # 在测试数据上做测试 predict_test = poly_log_reg.predict(X_test) score = metrics.accuracy_score(y_test, predict_test) sys.stdout.write("LR(degree = %d, C=%.2f, penalty=%s) Test Accuracy : %.4g\n" % ( degree, C, penalty, score)) print("--------------------------------------") # 展示分类边界 plot_decision_boundary(-4, 4, -4, 4, lambda x: poly_log_reg.predict(x)) plt.scatter(X_train[y_train == 0, 0], X_train[y_train == 0, 1], color='r') plt.scatter(X_train[y_train == 1, 0], X_train[y_train == 1, 1], color='b') plt.xlabel("x1") plt.ylabel("x2") plt.rcParams['font.sans-serif'] = 'SimHei' # 消除中文乱码 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 plt.title("参数:degree:%d, C:%.2f, penalty:%s -- 准确率: %.4f" % (degree, C, penalty, score)) plt.show()if __name__ == '__main__': # 随机生成200个拥有2维实数特征 且 分类面(线)为y=-x^2+1.5(换言之,x2=-x1^2+1.5)的语料 X, y = get_parabolic_curve_data_set(200) # 可以加大数据量查看对结果的影响 # 预留30%作为测试语料 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # 展示所生成的数据 show_data_set(X, y) # 测试不同的超参数组合 print("准确率高,比较恰当的模型") test(X_train, X_test, y_train, y_test, degree=2, C=1.0, penalty='l2') print("准确率高,且恰当的模型") test(X_train, X_test, y_train, y_test, degree=2, C=0.1, penalty='l2') print("准确率高,但是过拟合的模型") test(X_train, X_test, y_train, y_test, degree=20, C=1.0, penalty='l2') print("准确率低,且过拟合的模型") test(X_train, X_test, y_train, y_test, degree=20, C=0.1, penalty='l2') print("准确率高,且恰当的模型") test(X_train, X_test, y_train, y_test, degree=20, C=0.1, penalty='l1') 3. 结果对比
3.1 正态分布
当样本为正态分布时:X = np.random.normal(0, 1, size=(n, 2)) # 正态分布,中心0,标准差1
| 参数组合 | 数据(正态分布) | deg = 2, C=1.00, l2 | deg = 2, C=0.10, l2 | deg = 20, C=1.00, l2 | deg = 20, C=0.10, l2 | deg = 20, C=0.10, l1 |
|---|---|---|---|---|---|---|
| 200组数据、seed(520) | 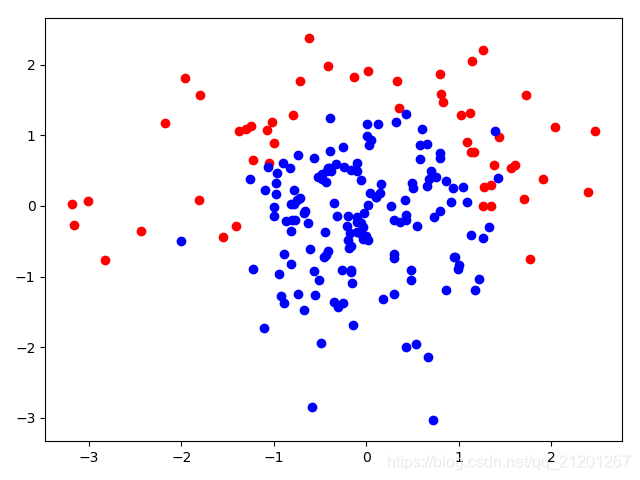 | 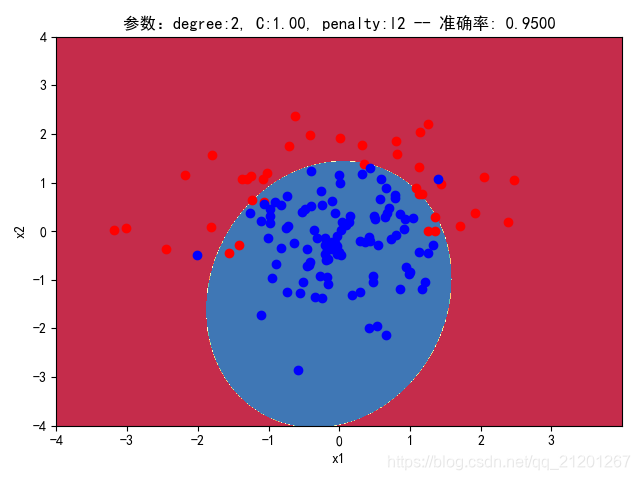 |  | 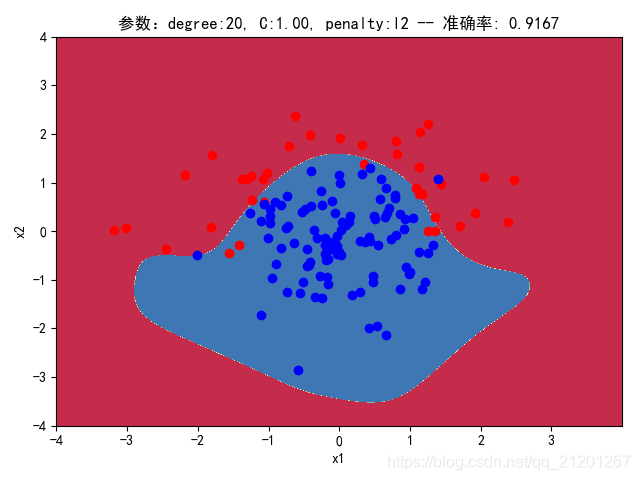 | 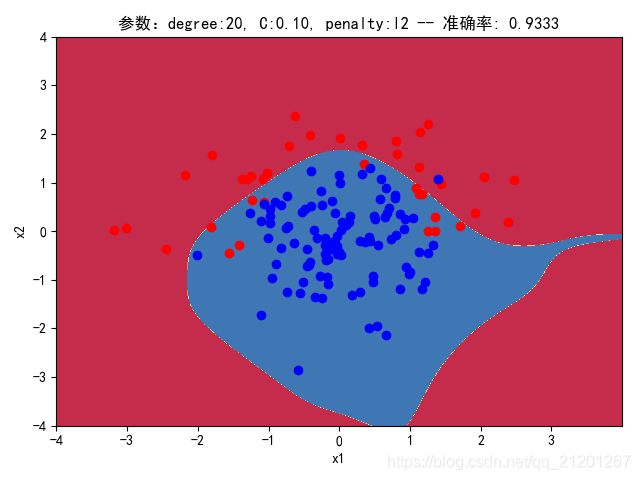 | 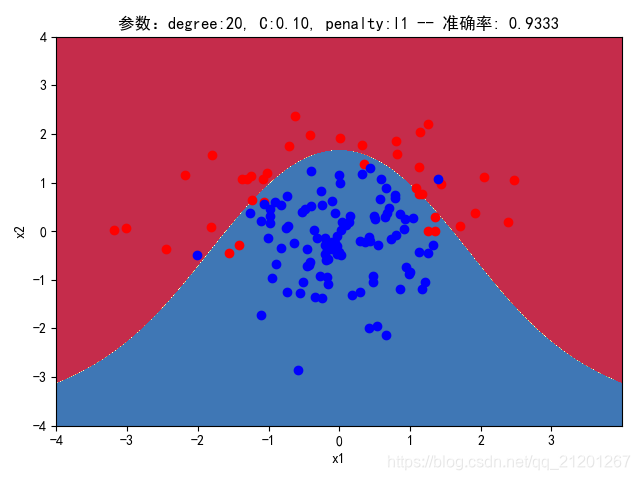 |
| 准确率 | 0.9500 | 0.9500 | 0.9167 | 0.9333 | 0.9333 | |
| 200组数据、seed(777) | 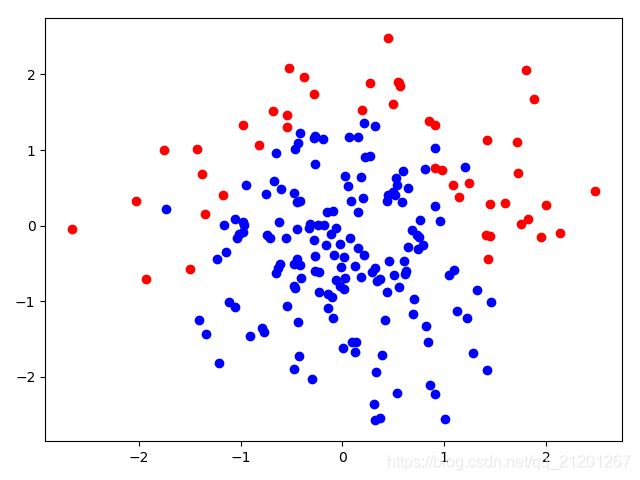 | 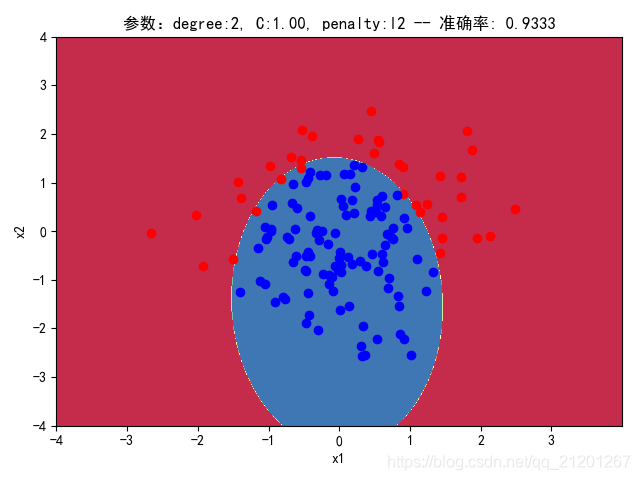 | 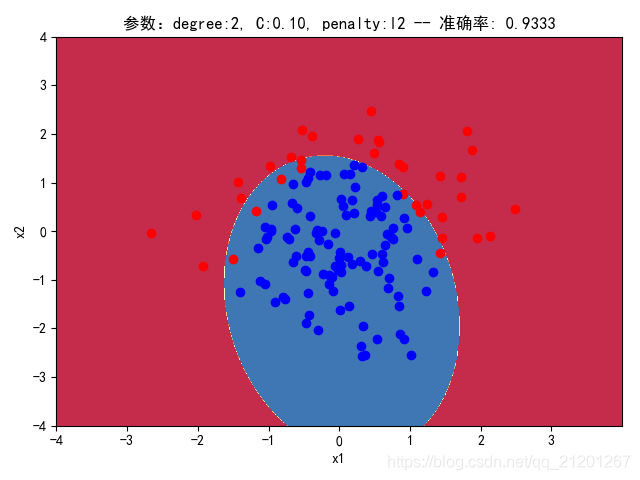 | 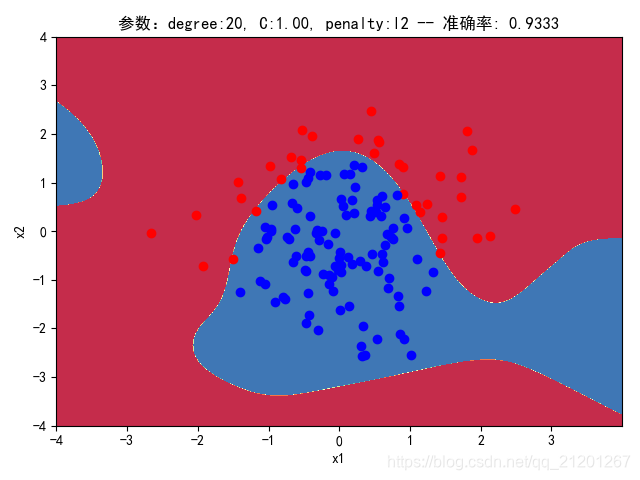 | 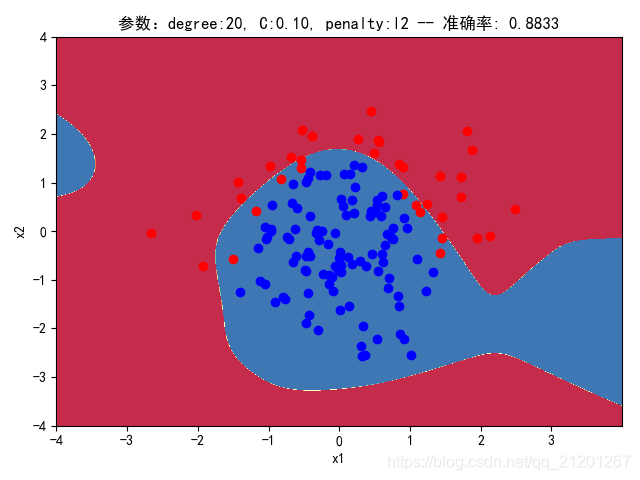 | 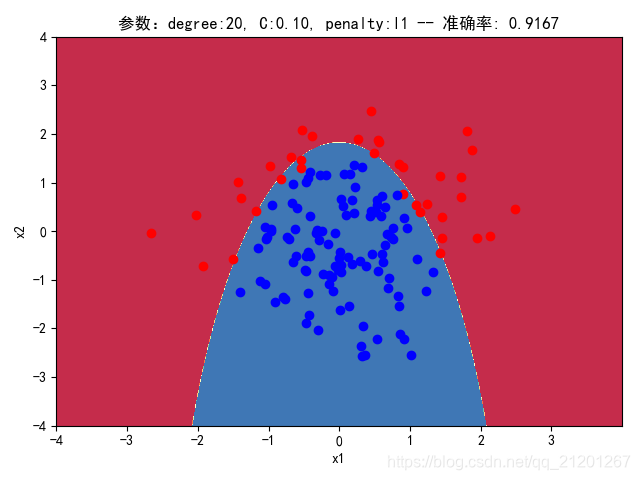 |
| 准确率 | 0.9333 | 0.9333 | 0.9333 | 0.8833 | 0.9167 | |
| 2000组数据 seed(520) | 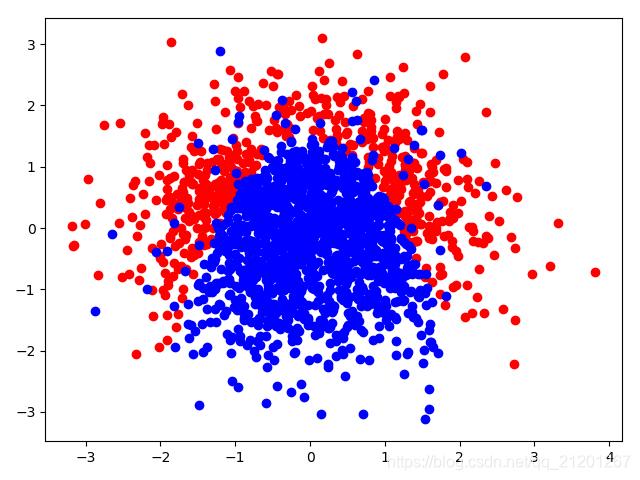 | 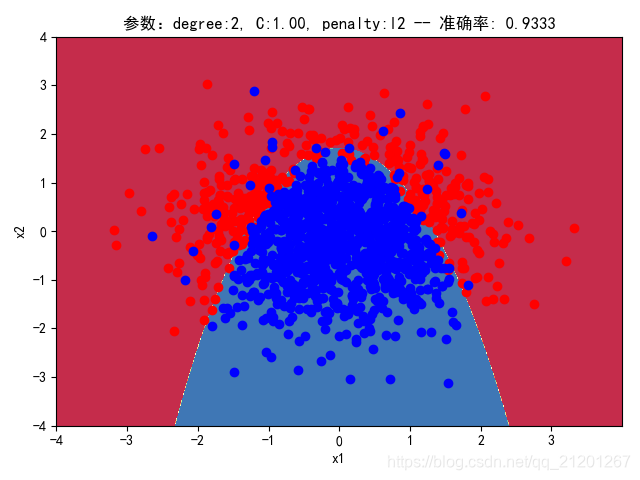 | 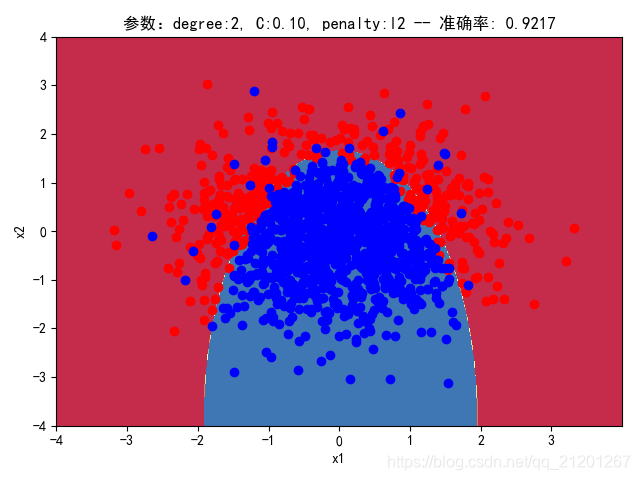 | 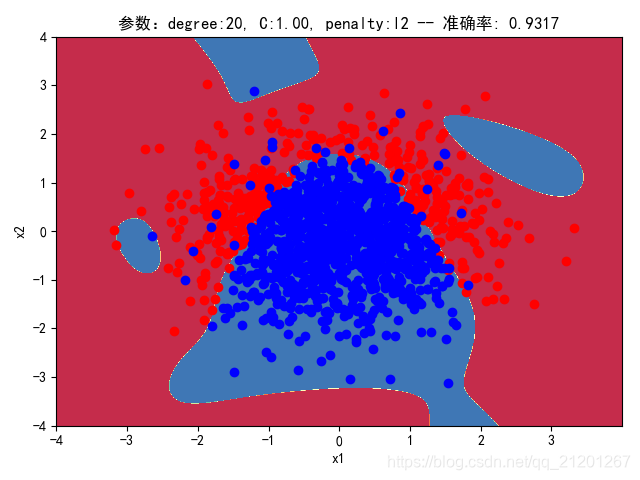 | 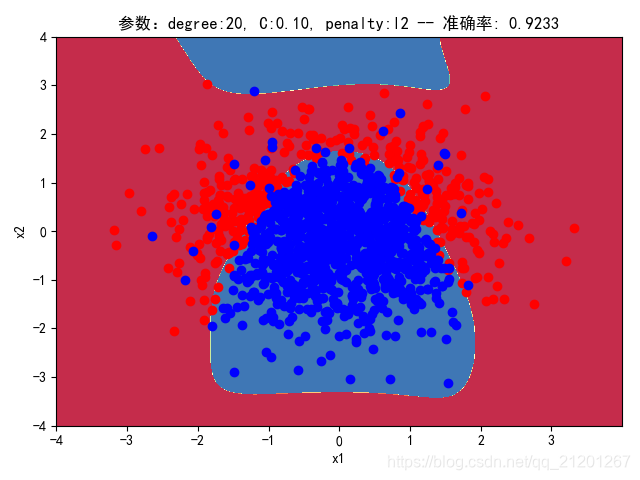 | 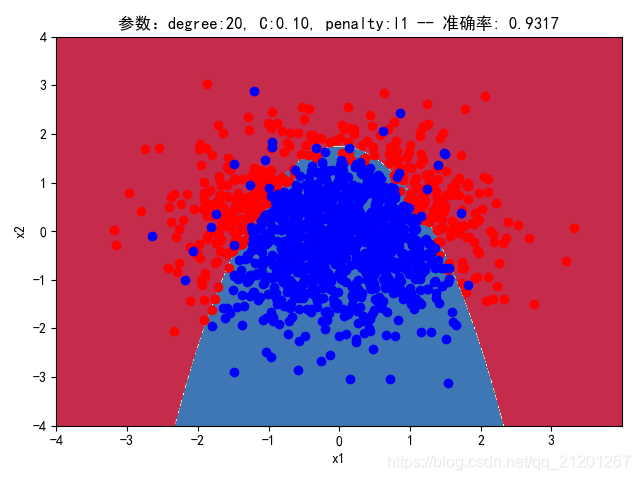 |
| 准确率 | 0.9333 | 0.9217 | 0.9317 | 0.9233 | 0.9317 | |
| 2000组数据 seed(777) | 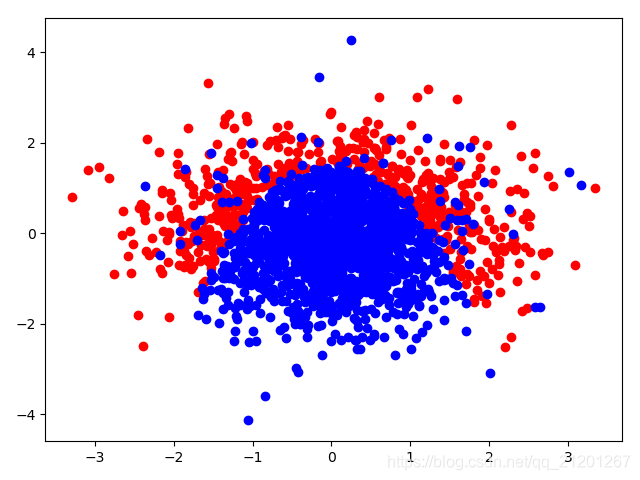 | 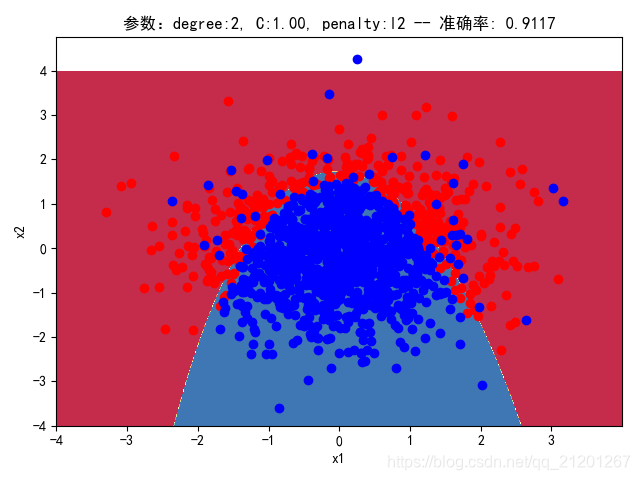 | 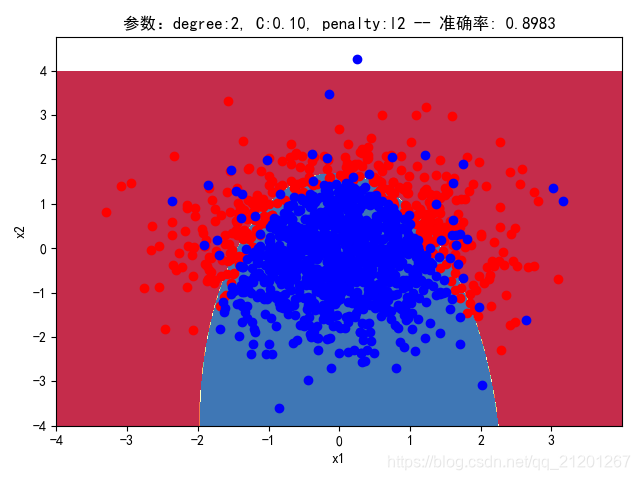 | 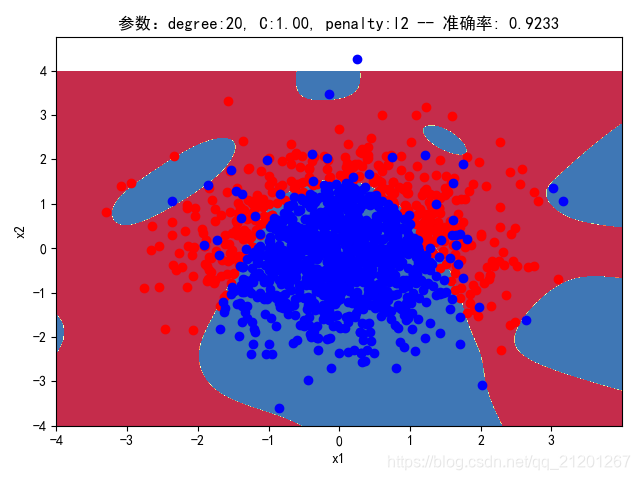 | 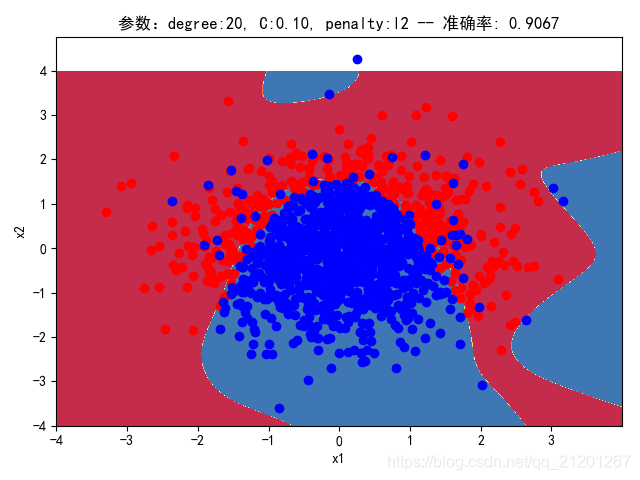 | 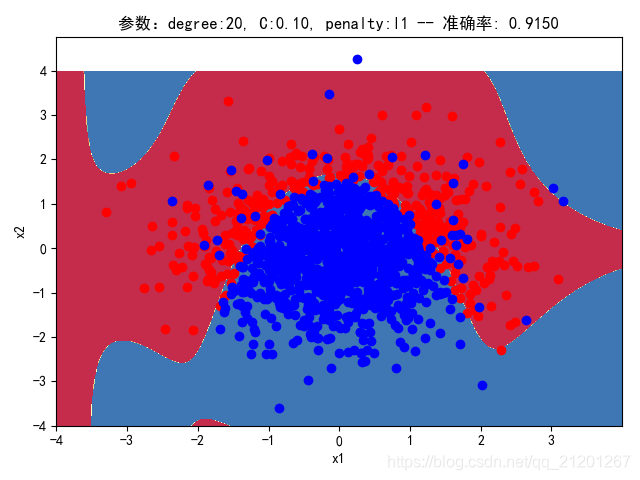 |
| 准确率 | 0.9117 | 0.8983 | 0.9233 | 0.9067 | 0.9150 |
对比可以发现:
- 对比 1,2 列,数据越密集的区域,越容易学到准确的分类边界,且容易克服噪声的影响;
- 随机种子seed不一样,产生的样本集合不同,在假设的分类模型比较接近真实分类界线(y=-x^2+1.5),随着数据增加,学习到的模型越靠谱;在假设的分类模型比真实分类界限复杂时,在数据密集区域,随着数据增多,配合上正则化,依然可以学习到更准确的模型。在数据稀释区域,模型的复杂度很高,且受噪声数据影响比较大。
- degree的增加,可以产生高阶的曲线分界
- 对比 3,4 列,C越大,正则化项作用越小,曲线会越复杂,过拟合会越严重
- 对比 4,5 列,可见,l1 正则化下的预测分界曲线可能阶数更低(非0参数更少)
- 分类线实质上是抛物线(2阶),我们用20阶去学习,首先2000组数据不一定充分,其次,由于正态分布数据集中在中心,边缘区域数据覆盖很少,所以周围区域的分类线有时候会奇形怪状,但中心区域的分类还是比较准确的
3.2 均匀分布
当样本为均匀分布时:X = np.random.uniform(-4, 4, size=(n, 2)) # 均匀分布,区间[-4,4)
| 参数组合 | 数据(均匀分布) | deg = 2, C=1.00, l2 | deg = 2, C=0.10, l2 | deg = 20, C=1.00, l2 | deg = 20, C=0.10, l2 | deg = 20, C=0.10, l1 |
|---|---|---|---|---|---|---|
| 200组数据、seed(520) | 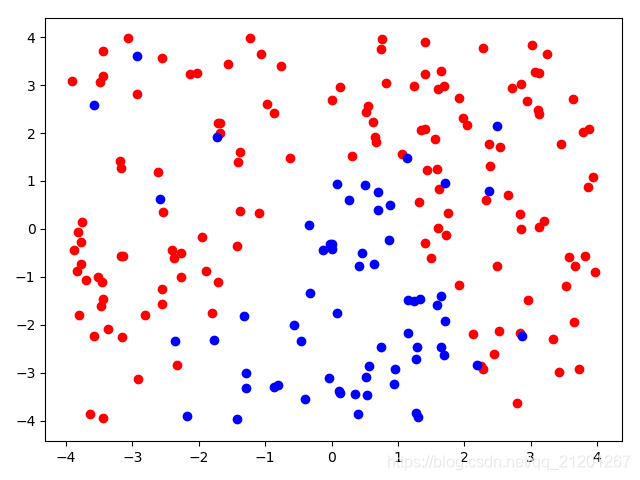 | 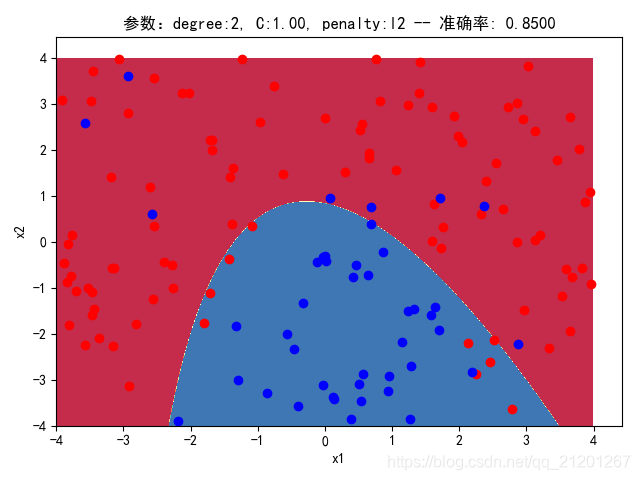 | 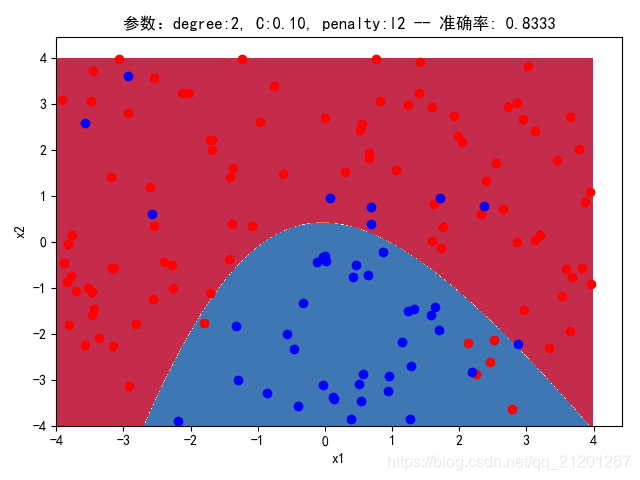 | 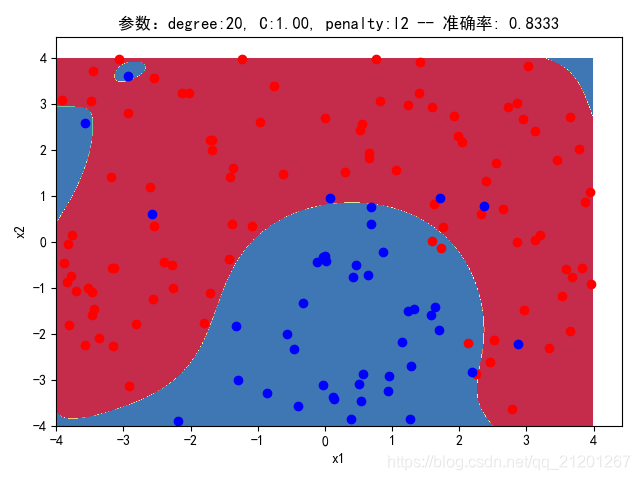 | 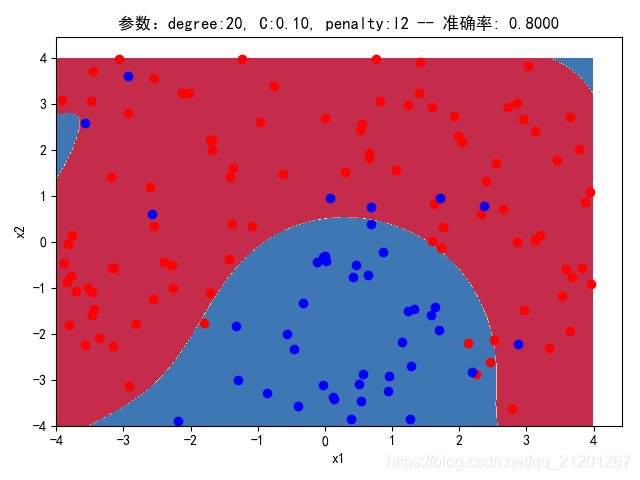 | 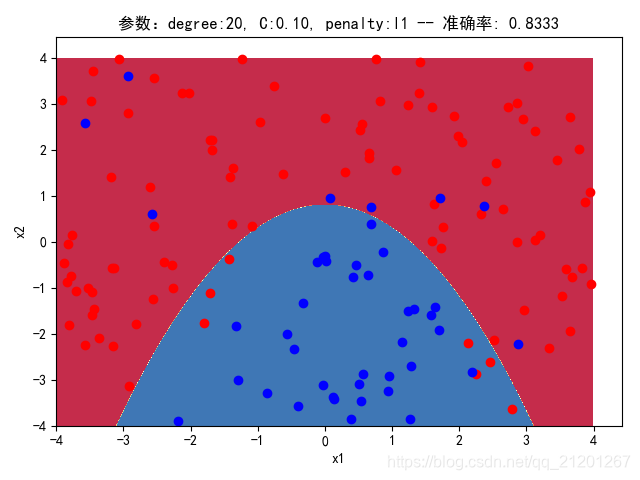 |
| 准确率 | 0.8500 | 0.8333 | 0.8333 | 0.8000 | 0.8333 | |
| 200组数据、seed(777) | 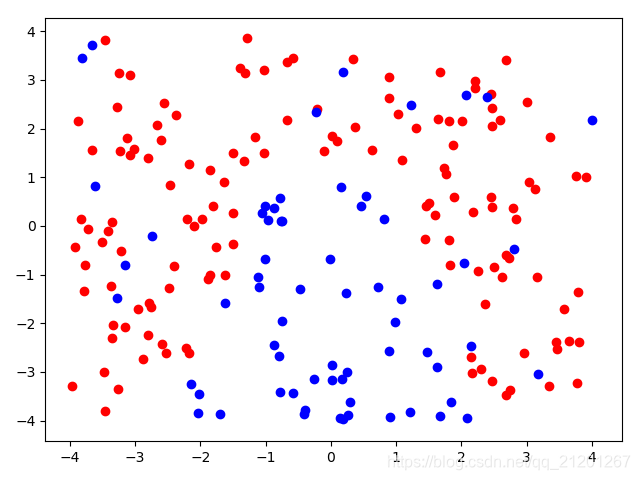 | 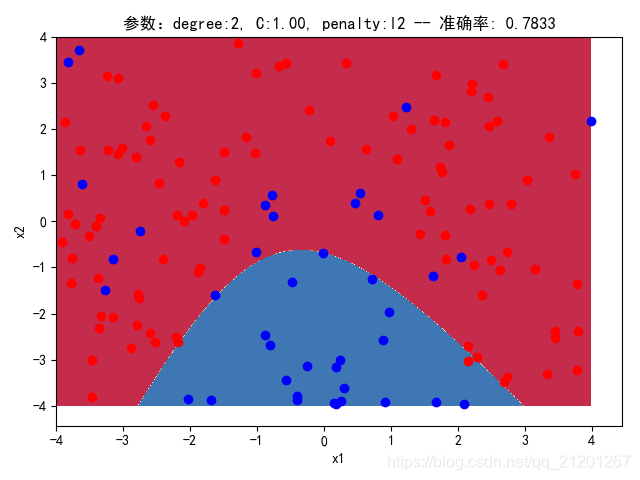 | 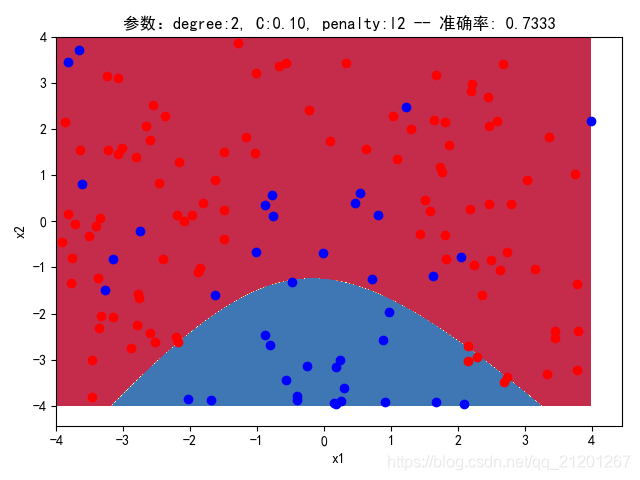 | 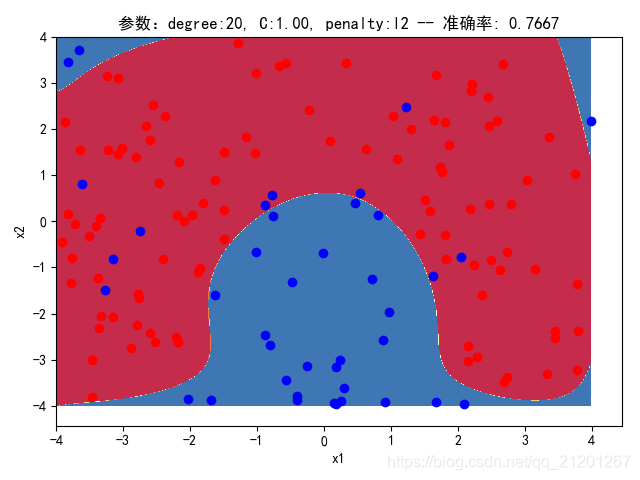 | 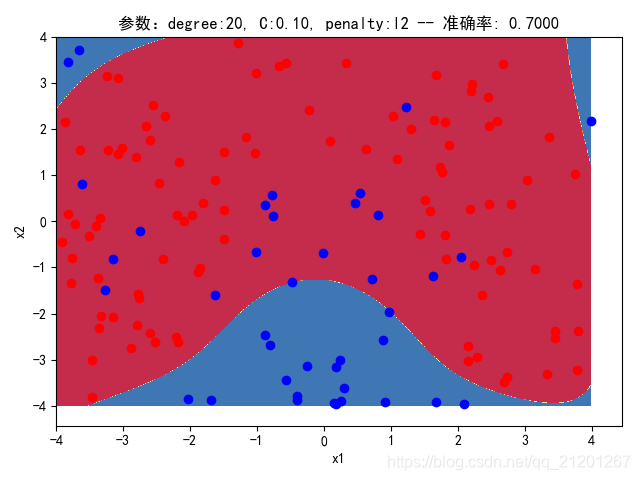 | 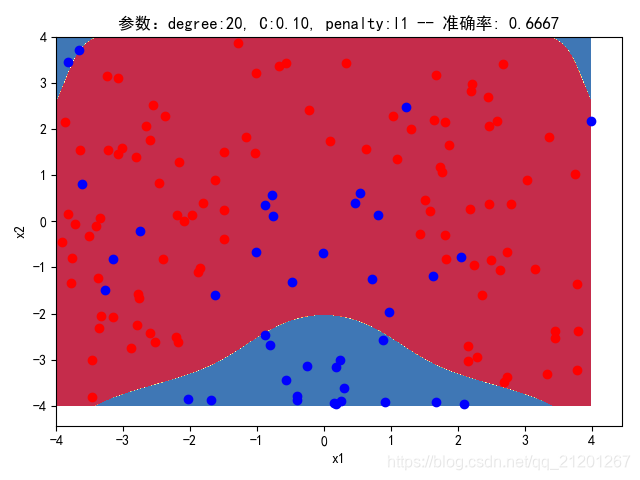 |
| 准确率 | 0.7833 | 0.7333 | 0.7667 | 0.7000 | 0.6667 | |
| 2000组数据 seed(520) | 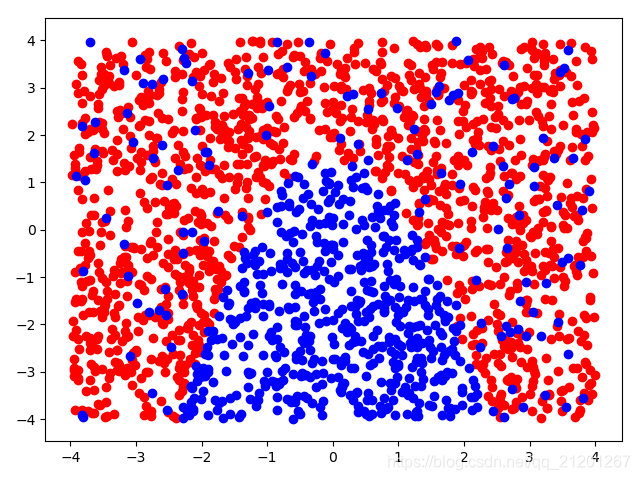 | 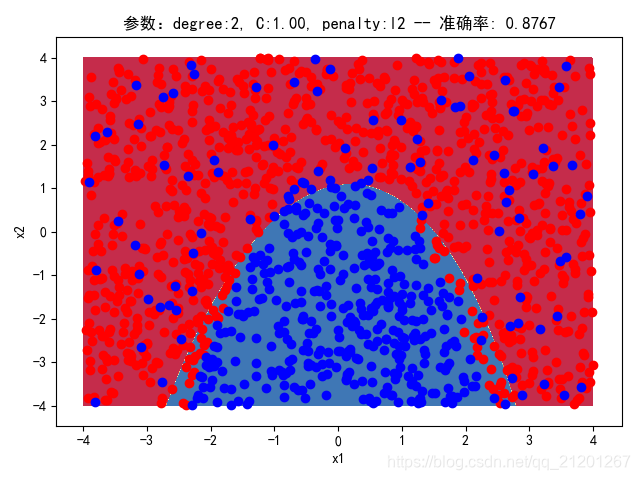 | 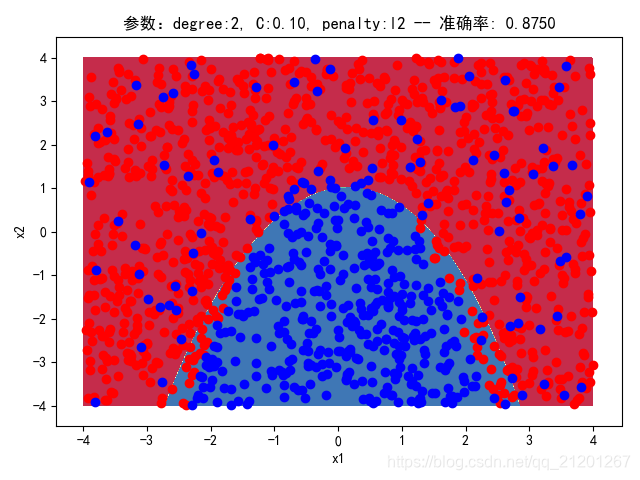 | 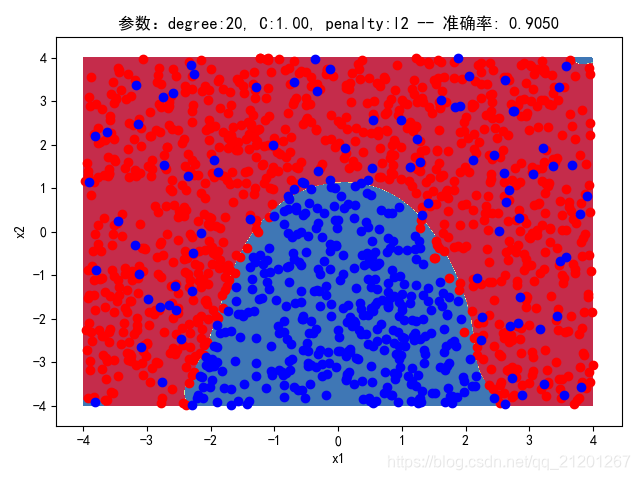 | 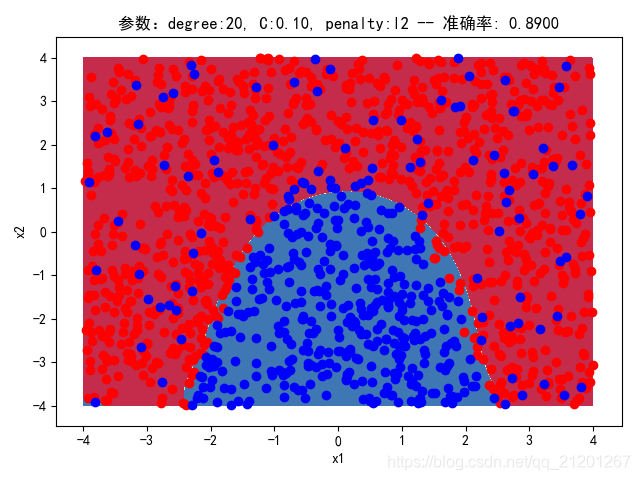 | 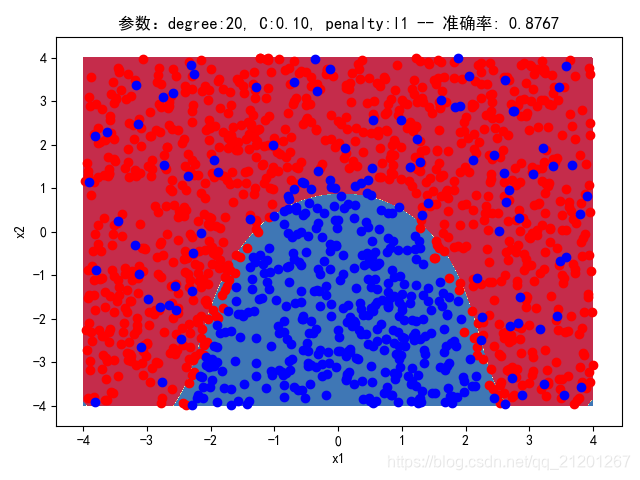 |
| 准确率 | 0.8767 | 0.8750 | 0.9050 | 0.8900 | 0.8767 | |
| 2000组数据 seed(777) | 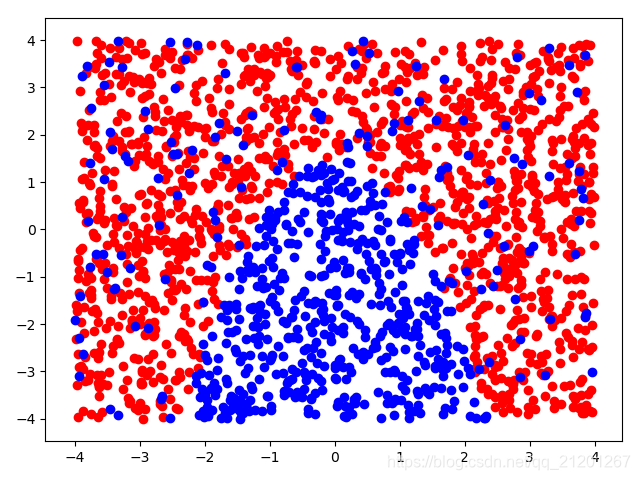 | 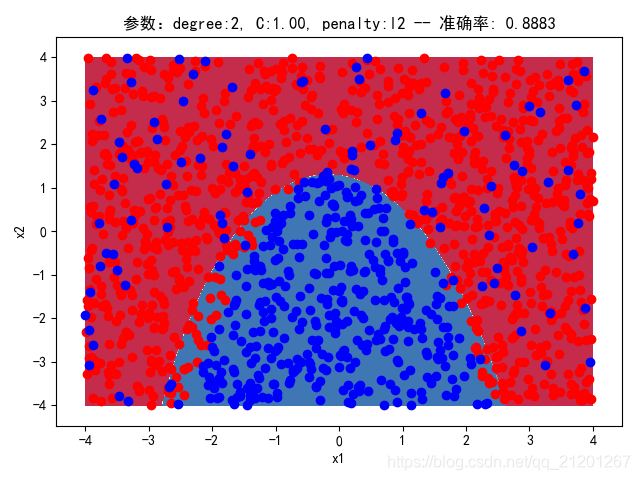 | 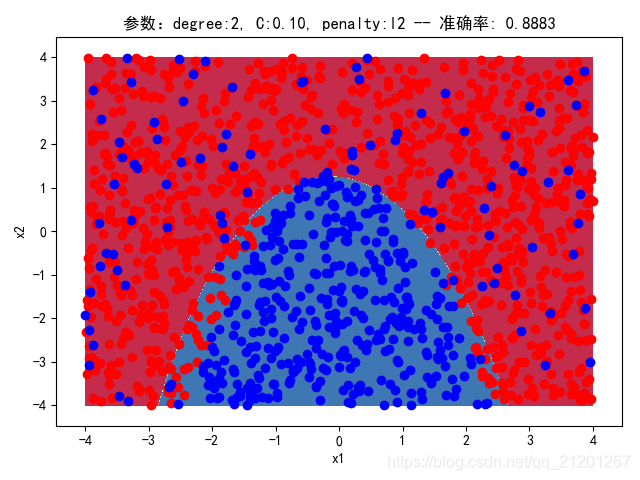 | 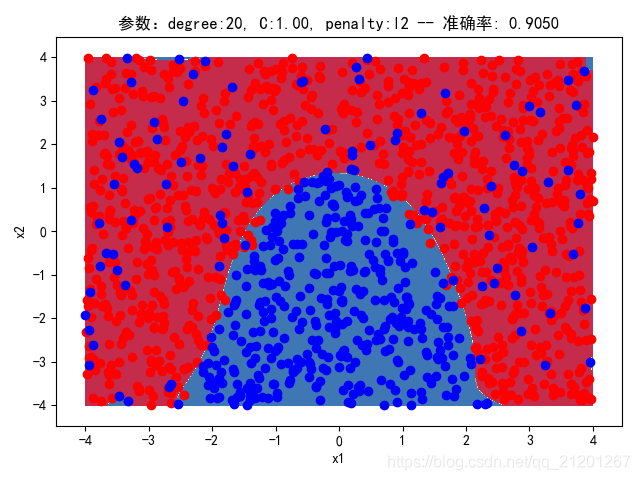 | 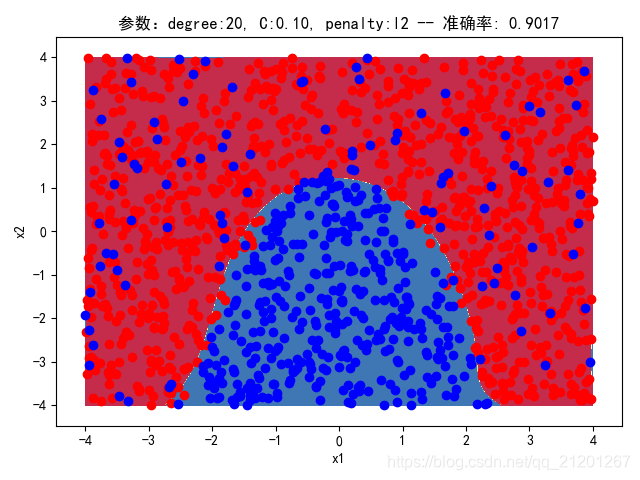 | 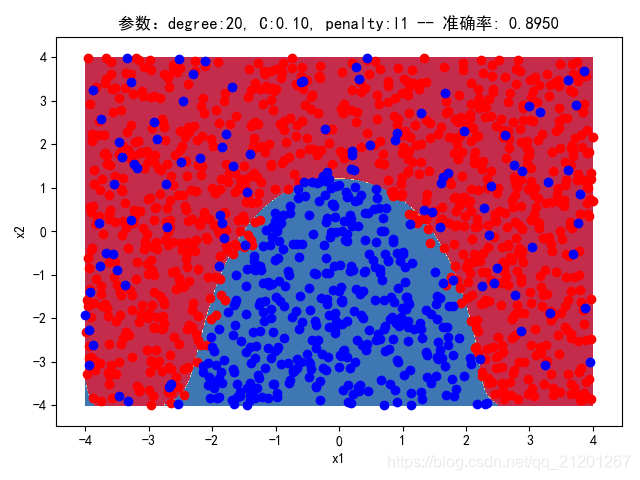 |
| 准确率 | 0.8883 | 0.8883 | 0.9050 | 0.9017 | 0.8950 |
- 由上面2大组实验(X的分布形式改变),可看出均匀分布下,2000组数据下,各组参数下分类结果均比较好
- 当数据量比较小时,结果易受到seed随机出来的样本影响(第1,2行),同时,分类效果也不好
3.3 修改Pipeline
- 管道机制实现了对机器学习全部步骤的流式化封装和管理
- 前几步是转换器(
Transformer)(如多项式转换、归一化等等),最后一步必须是估计器(Estimator)或叫分类器,输入数据经过转换器处理,输出的结果作为下一步的输入 pipeline.fit生成预测模型pipeline.predict对数据进行预测
上面实践代码里Pipeline定义了模型将要做的事情:
- a. 对数据进行 多项式转换
PolynomialFeatures(维度变化) - b. 归一化处理
StandardScaler(让异常数据不要对正常数据造成很大影响) - c. 逻辑斯谛回归
LogisticRegression(预测)
def PolynomialLogisticRegression(degree=2, C=1.0, penalty='l2'): # 对输入特征依次做多项式转换、归一化转换、类别预测 return Pipeline([ # Pipeline 可以把多个评估器链接成一个。例如特征选择、标准化和分类 # 以多项式的方式对原始特征做转换,degree次多项式 ('poly', PolynomialFeatures(degree=degree)), # 对多项式转换后的特征向量做归一化处理,例如(数据-均值)/标准差 ('std_scaler', StandardScaler()), # 用转换后的特征向量做预测,penalty是正则化约束,C正则化强度,值越小,强度大 # solver 不同的求解器擅长的规模类型差异 # 正则化 https://blog.csdn.net/zouxy09/article/details/24971995/ ('log_reg', LogisticRegression(C=C, penalty=penalty, solver="liblinear")) ]) 在均匀分布的情况下,删除a、删除b、删除a,b,查看对预测的影响
3.3.1 删除多项式转换
| 参数组合, no ploy | 数据(均匀分布) | deg = 2, C=1.00, l2 | deg = 2, C=0.10, l2 | deg = 20, C=1.00, l2 | deg = 20, C=0.10, l2 | deg = 20, C=0.10, l1 |
|---|---|---|---|---|---|---|
| 200组数据、seed(520) | 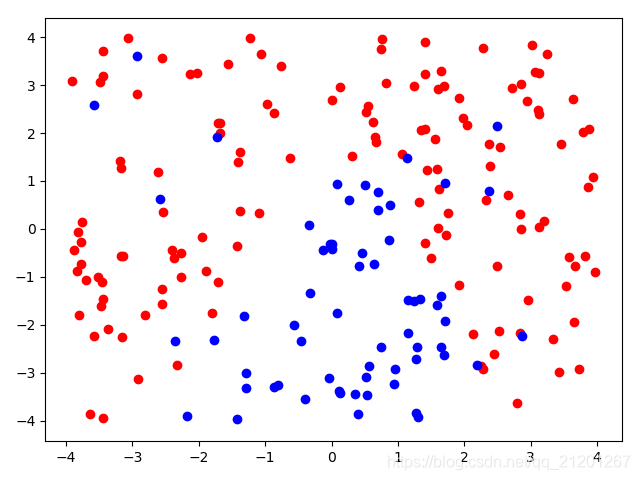 | 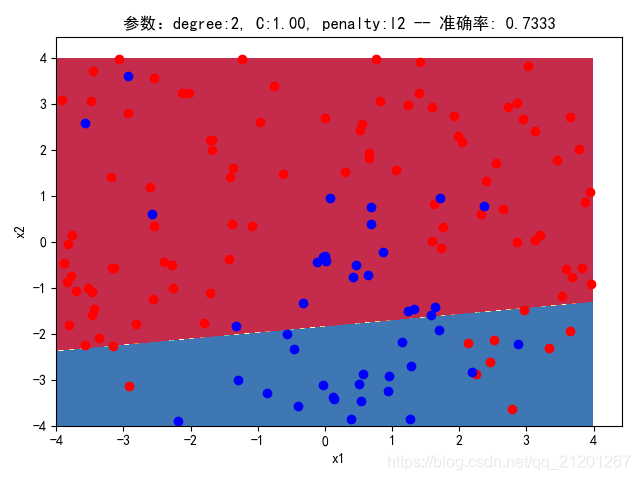 | 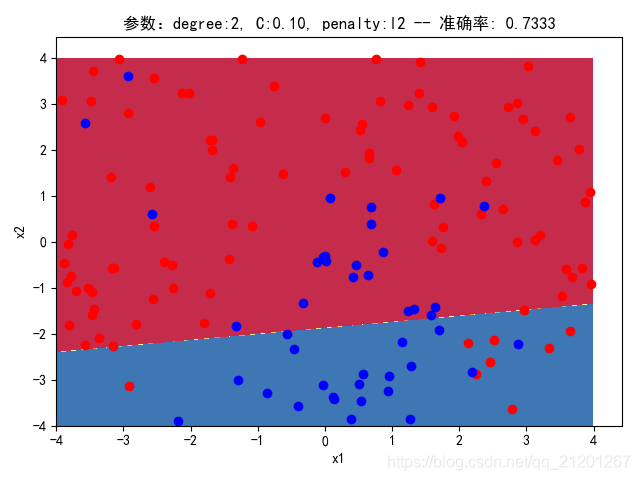 | 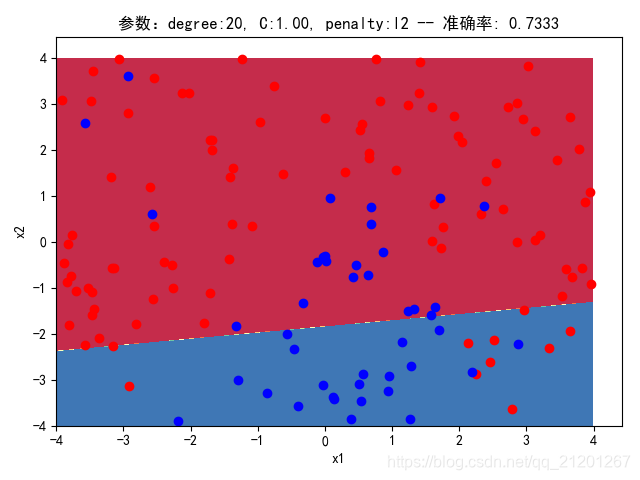 | 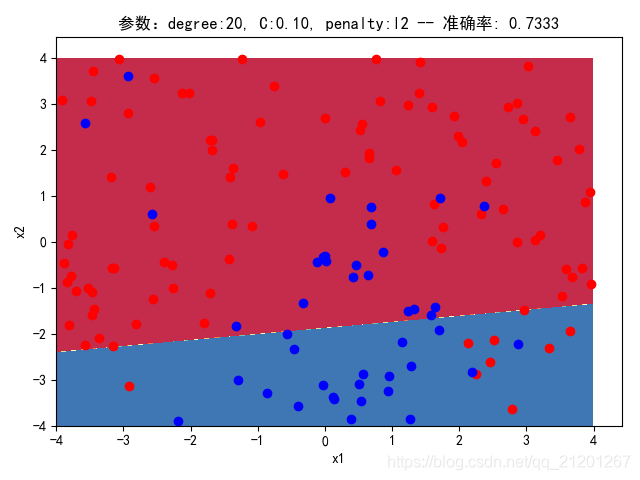 | 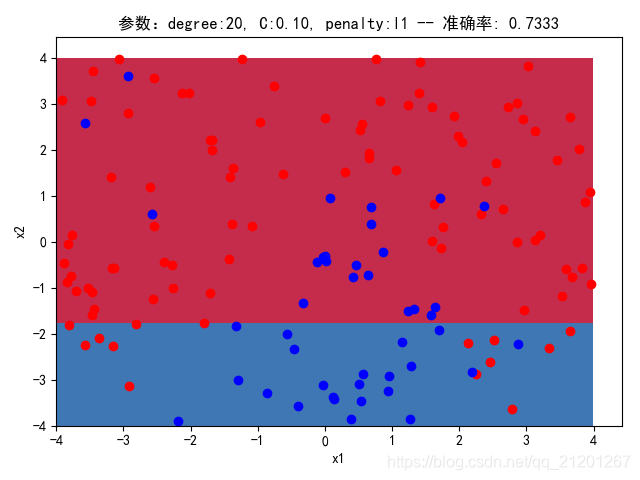 |
| 准确率 | 0.7333 | 0.7333 | 0.7333 | 0.7333 | 0.7333 | |
| 200组数据、seed(777) | 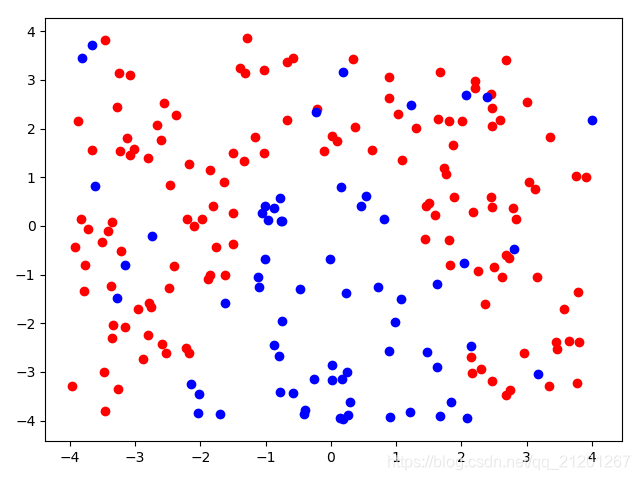 |  | 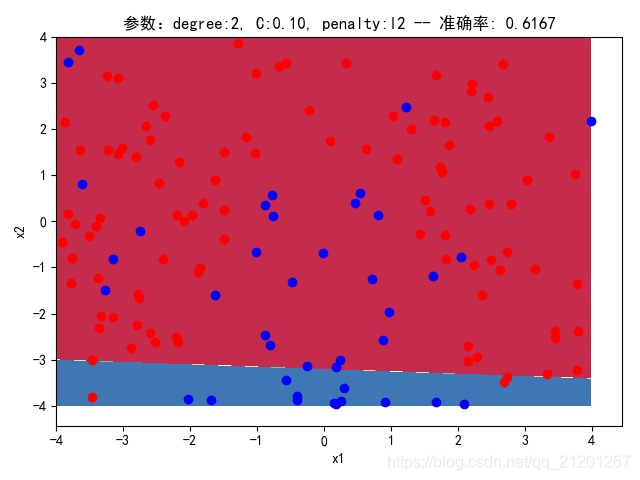 | 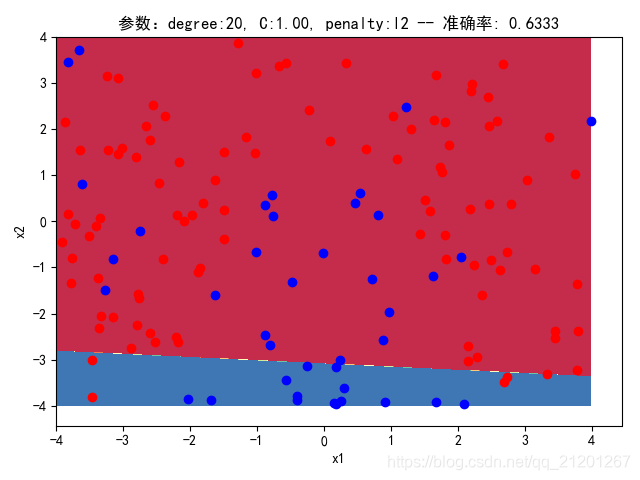 | 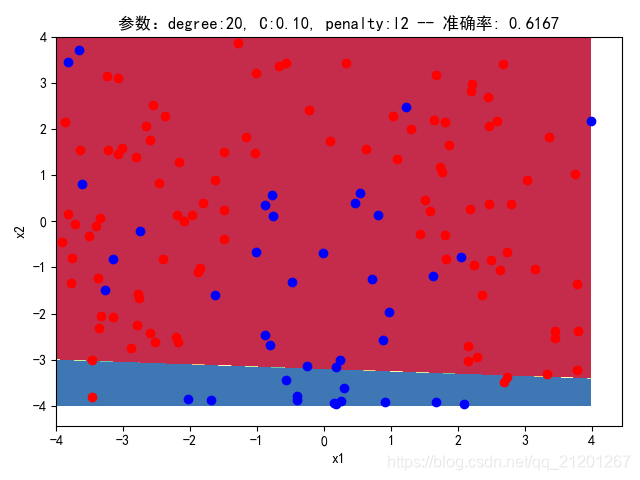 | 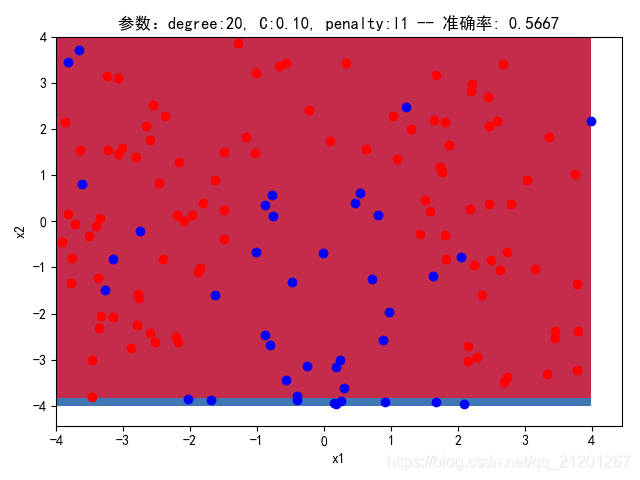 |
| 准确率 | 0.6333 | 0.6167 | 0.6333 | 0.6167 | 0.5667 | |
| 2000组数据 seed(520) | 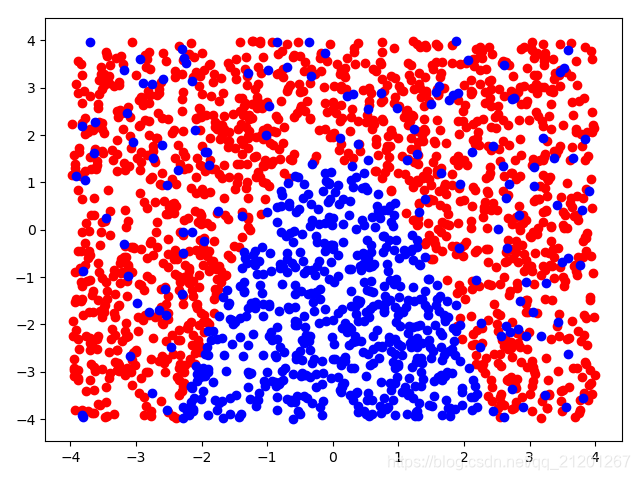 | 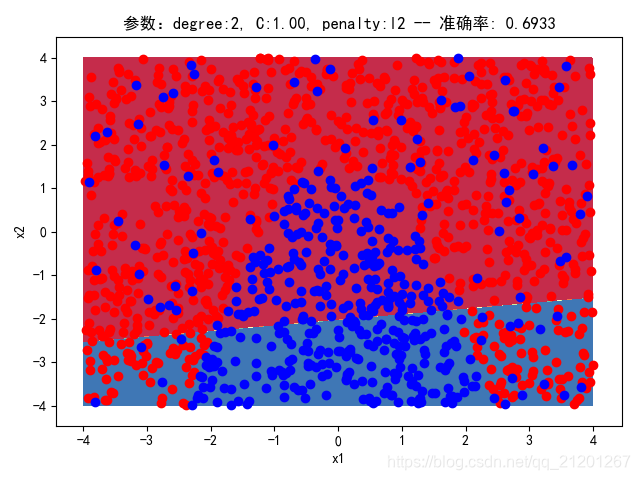 | 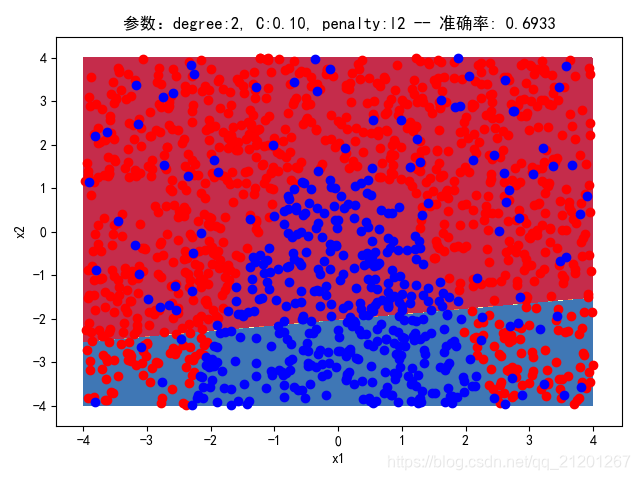 | 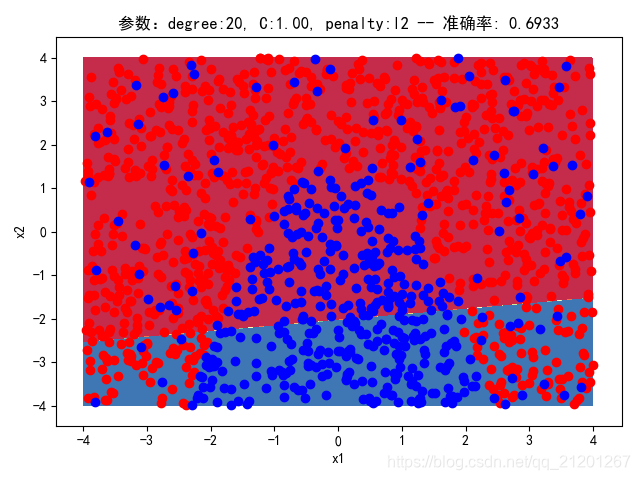 | 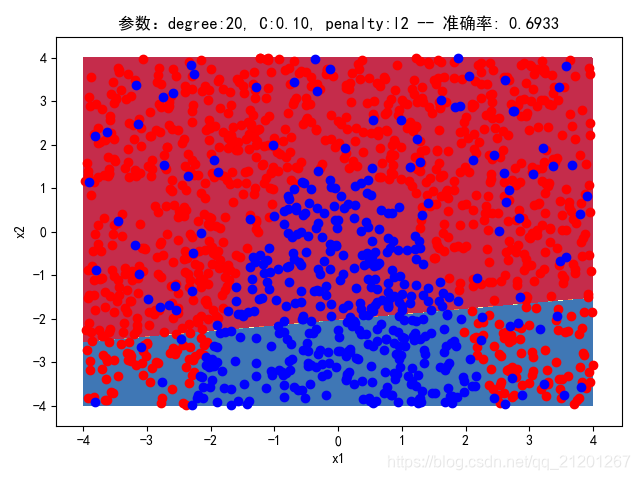 | 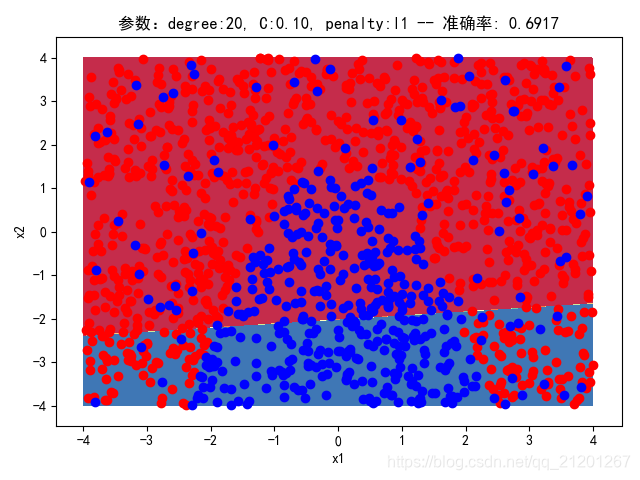 |
| 准确率 | 0.6933 | 0.6933 | 0.6933 | 0.6933 | 0.6917 | |
| 2000组数据 seed(777) | 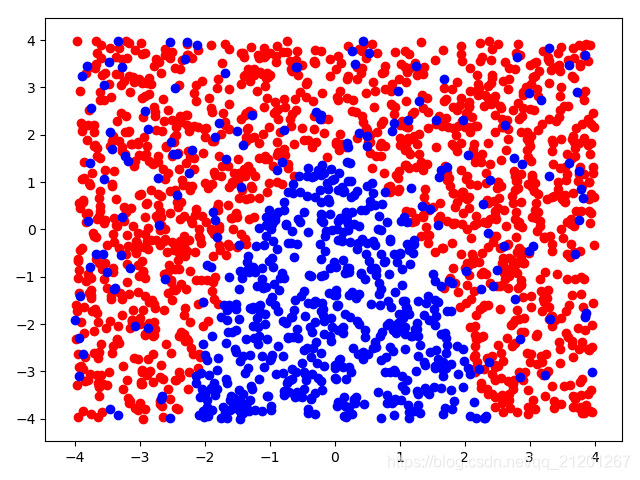 | 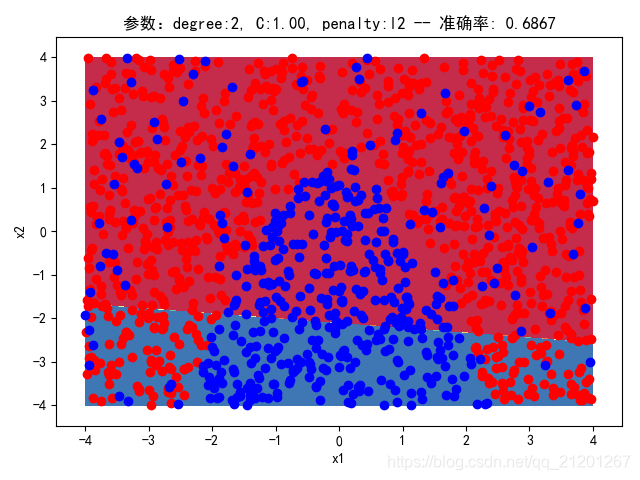 | 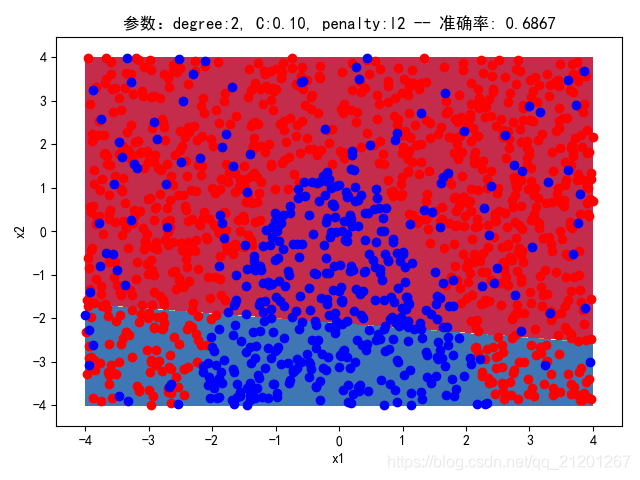 | 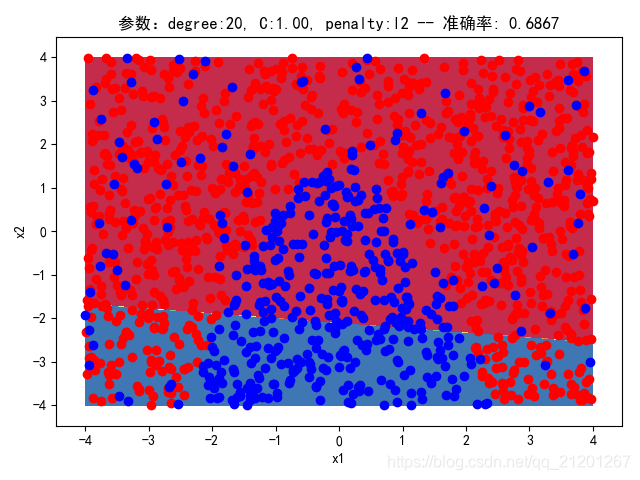 | 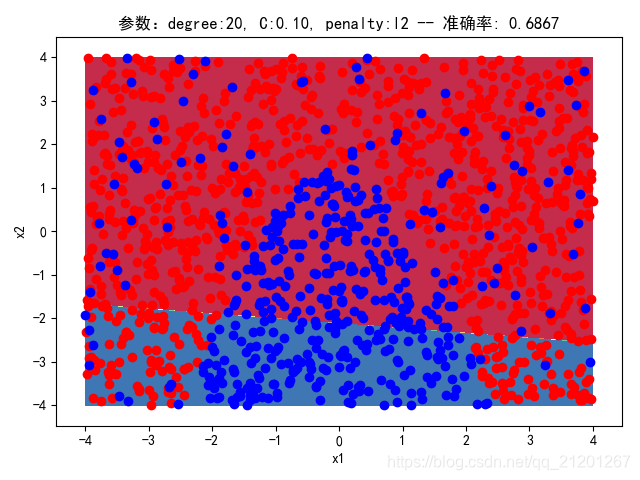 | 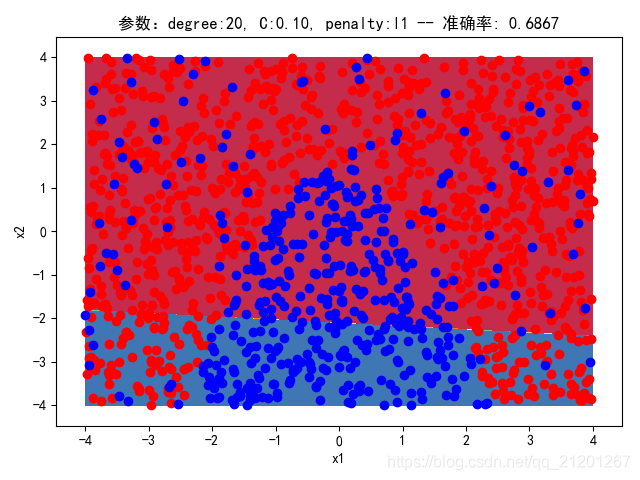 |
| 准确率 | 0.6867 | 0.6867 | 0.6867 | 0.6867 | 0.6867 |
- 可以看出在删除
ploy多项式转换项后,模型维度没有增加,保持线性 - 预测分类线为一条直线
- 预测准确率也下降很多,不管怎么调参数,效果甚微
3.3.2 删除归一化项
| 参数组合, no std_scaler | 数据(均匀分布) | deg = 2, C=1.00, l2 | deg = 2, C=0.10, l2 | deg = 20, C=1.00, l2 | deg = 20, C=0.10, l2 | deg = 20, C=0.10, l1 |
|---|---|---|---|---|---|---|
| 200组数据、seed(520) | 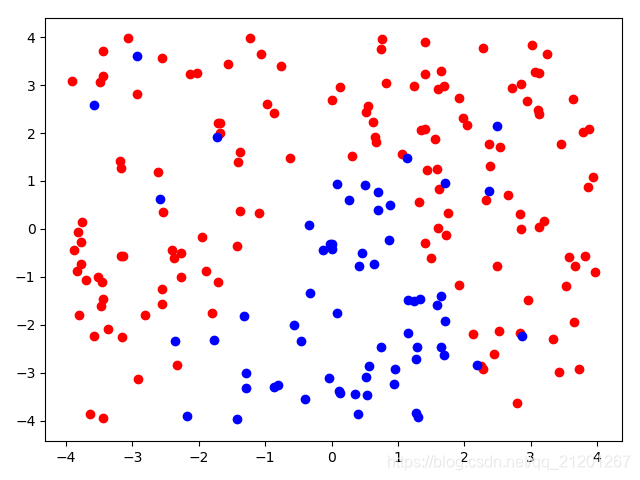 | 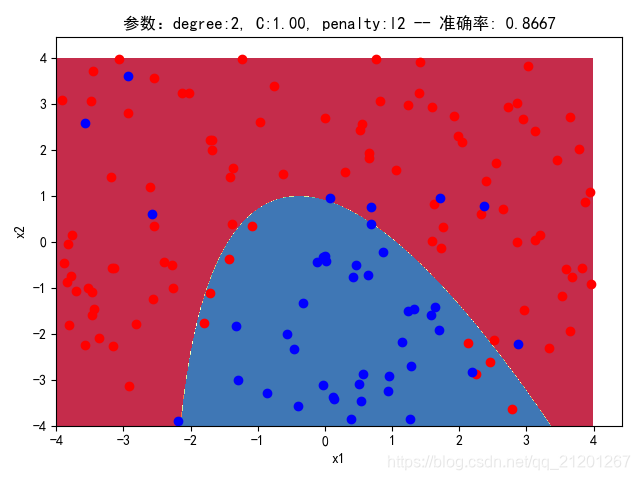 | 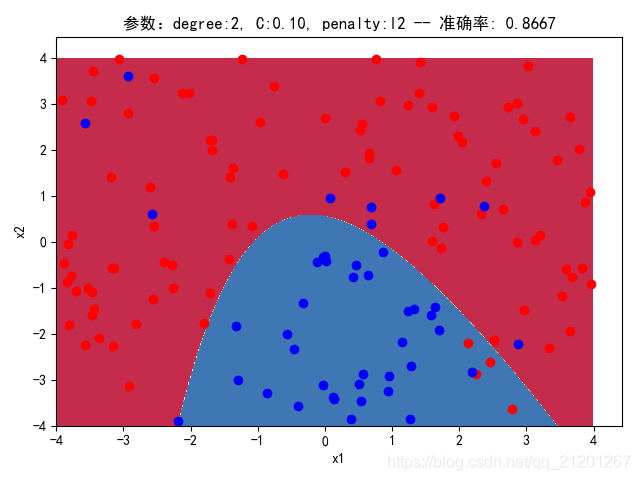 | 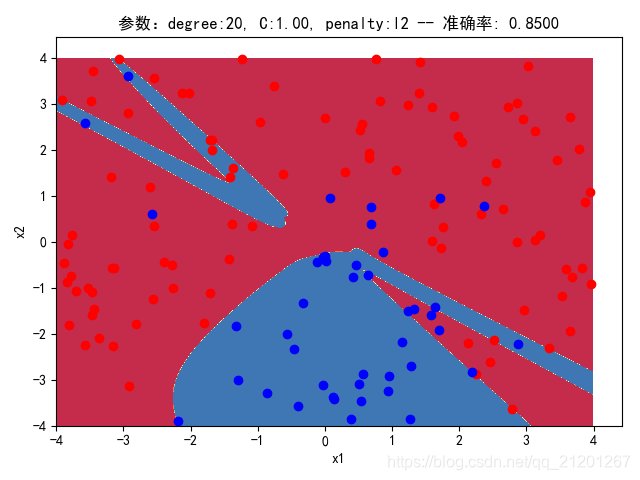 | 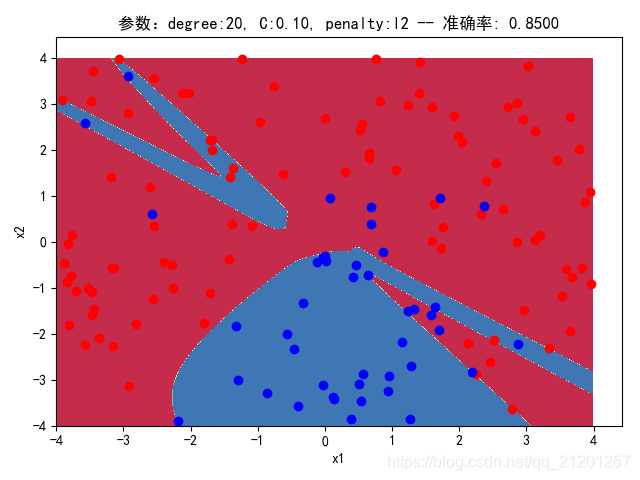 | 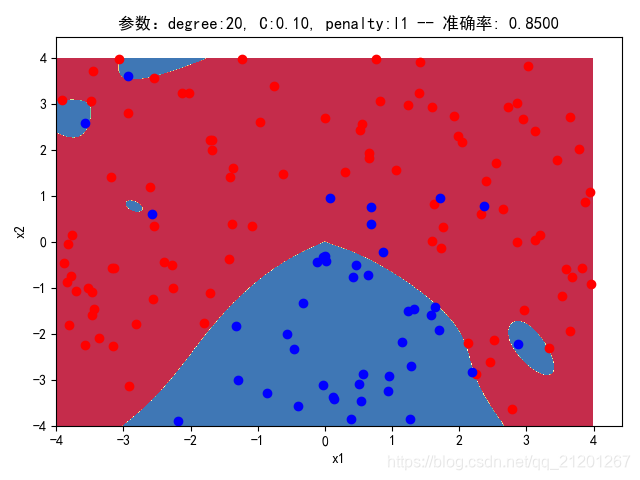 |
| 准确率 | 0.8667 | 0.8667 | 0.8500 | 0.8500 | 0.8500(Warning) | |
| 200组数据、seed(777) | 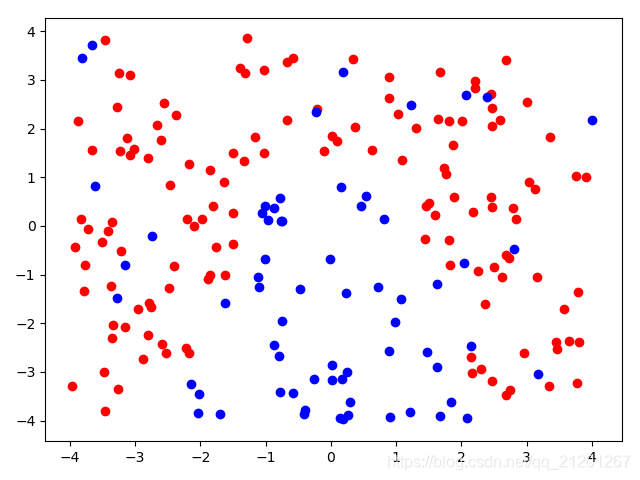 | 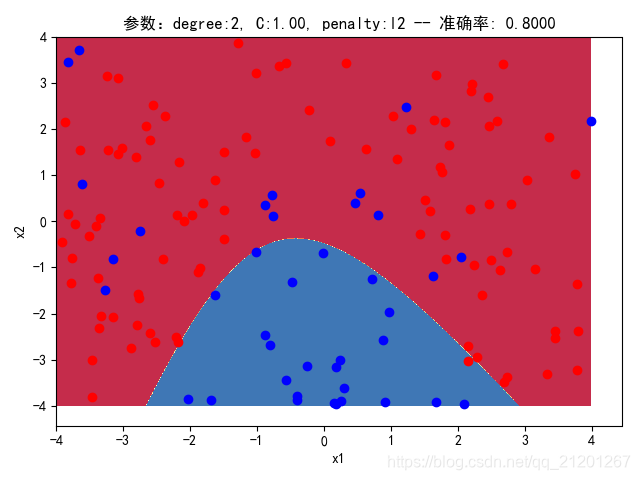 | 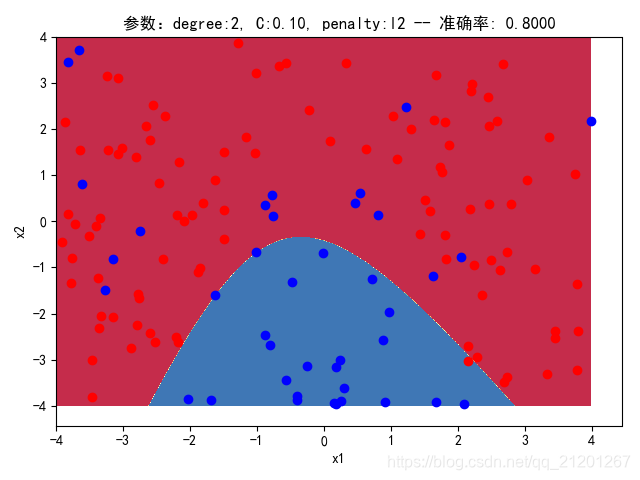 | 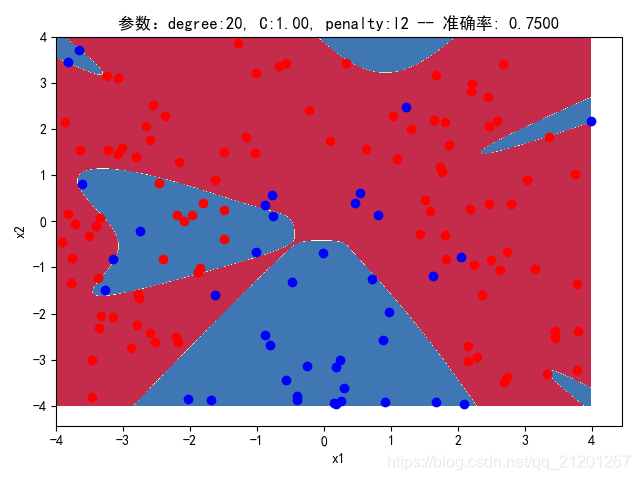 | 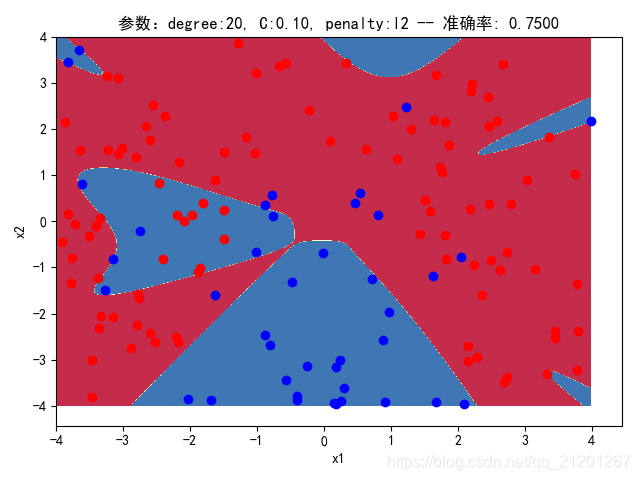 | 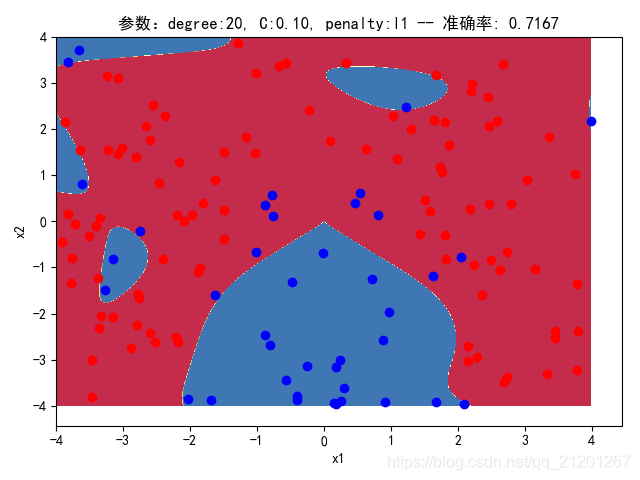 |
| 准确率 | 0.8000 | 0.8000 | 0.7500 | 0.7500 | 0.7176(Warning) | |
| 2000组数据 seed(520) | 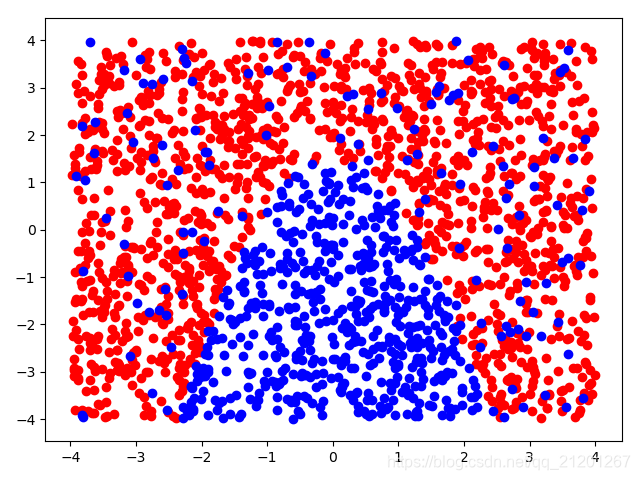 | 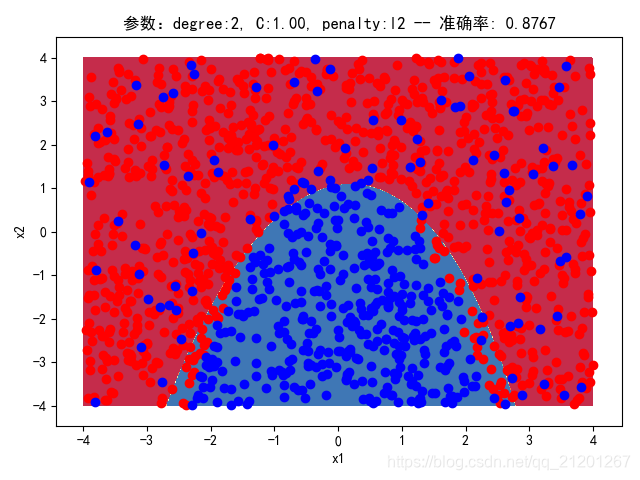 | 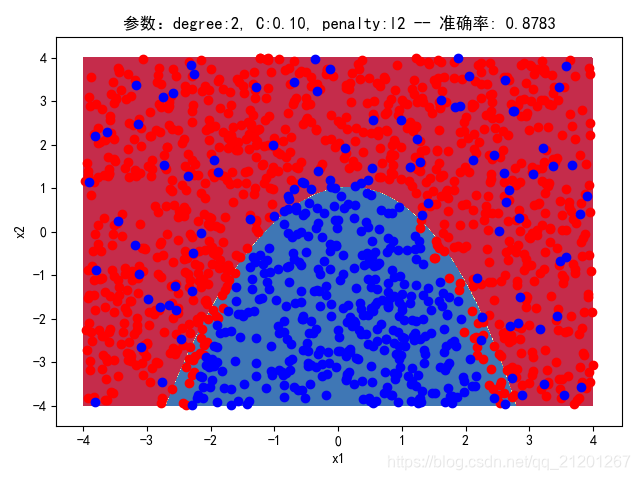 | 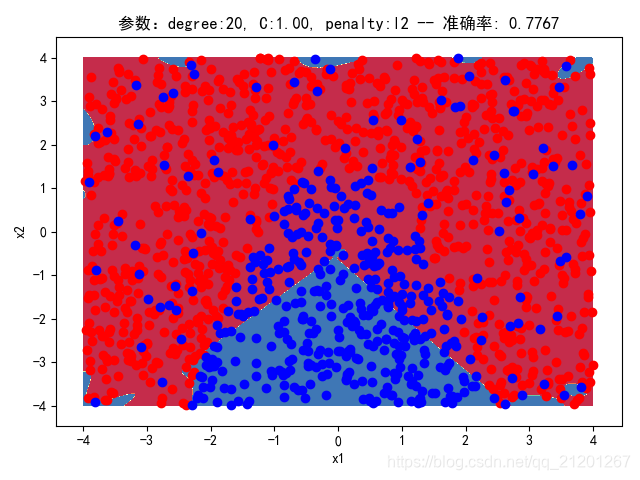 | 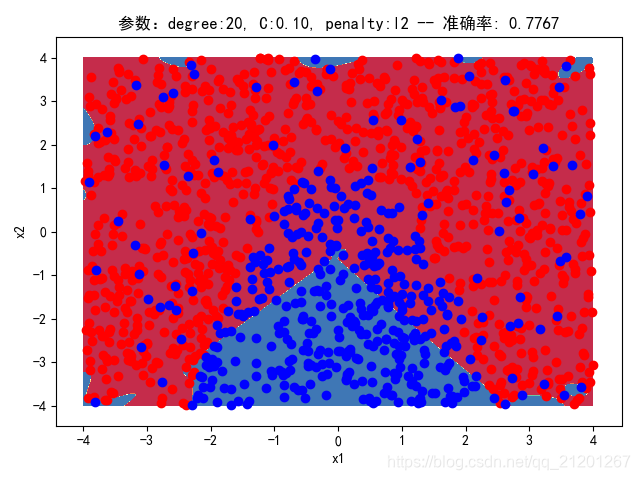 | 没跑出来 |
| 准确率 | 0.8767 | 0.8783 | 0.7767 | 0.7767 | - | |
| 2000组数据 seed(777) | 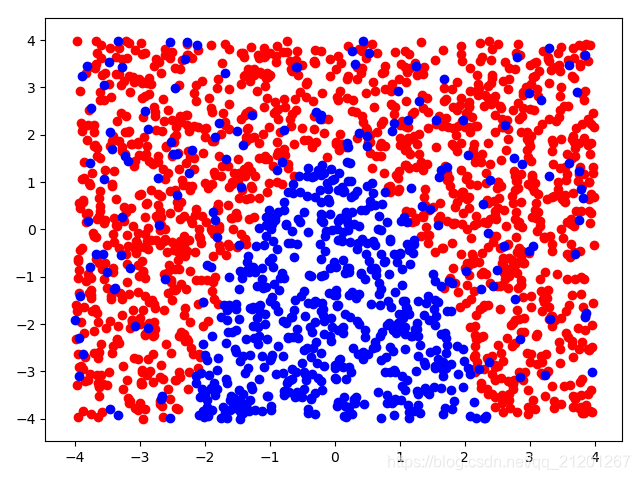 | 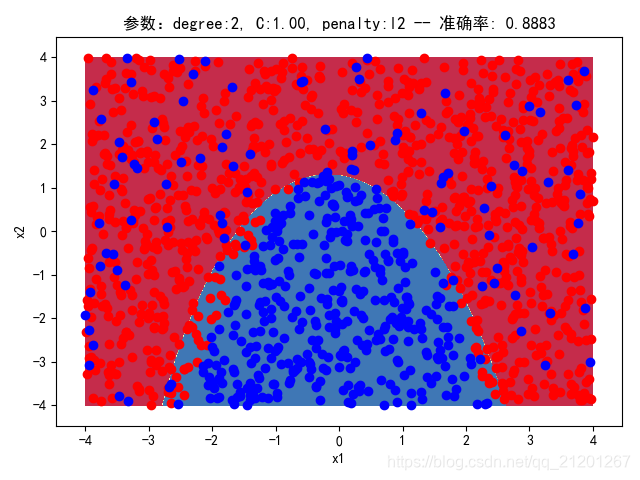 | 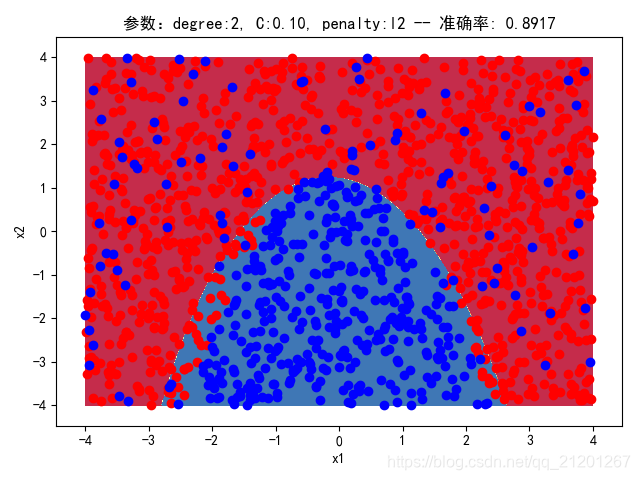 | 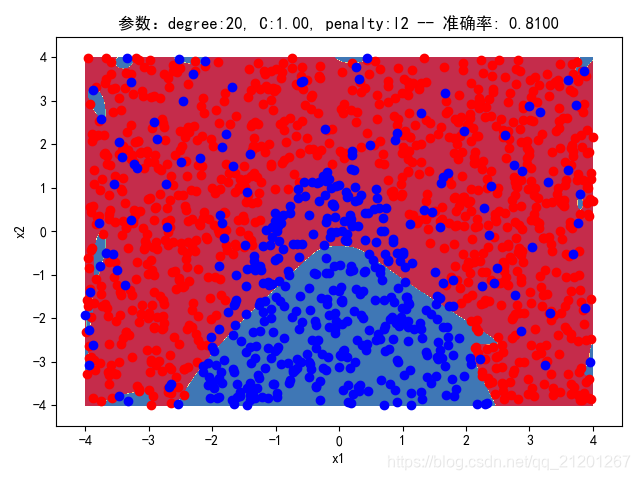 | 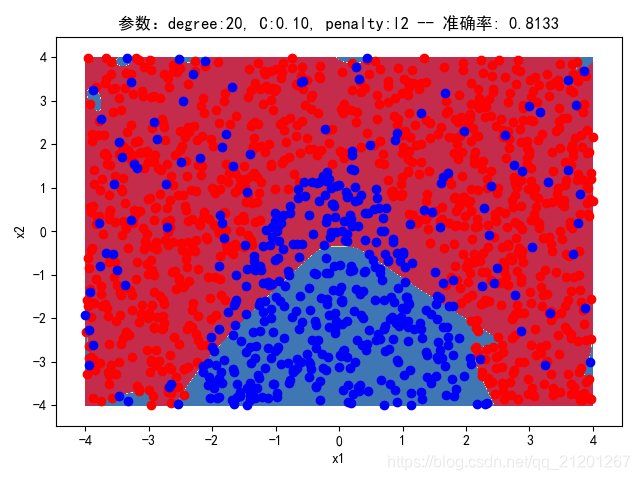 | 没跑出来 |
| 准确率 | 0.8883 | 0.8917 | 0.8100 | 0.8133 | - |
- 可以看出在2阶情况下,没有归一化,影响不是很大
- 高阶下,没有归一化,对结果影响很大(因为噪声数据下,高阶波动相当大,相当于系统不稳定,conditiona number很大)
//报的WarningConvergenceWarning: Liblinear failed to converge, increase the number of iterations. "the number of iterations.", ConvergenceWarning)
3.3.3 删除多项式转换&归一化
| 参数组合, no ploy & no scaler | 数据(均匀分布) | deg = 2, C=1.00, l2 | deg = 2, C=0.10, l2 | deg = 20, C=1.00, l2 | deg = 20, C=0.10, l2 | deg = 20, C=0.10, l1 |
|---|---|---|---|---|---|---|
| 200组数据、seed(520) | 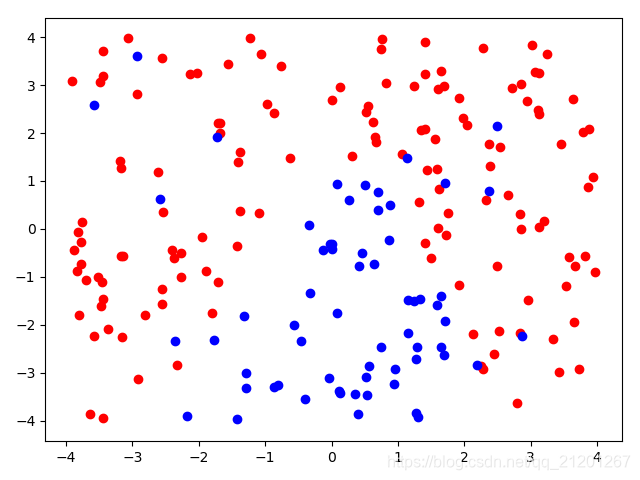 | 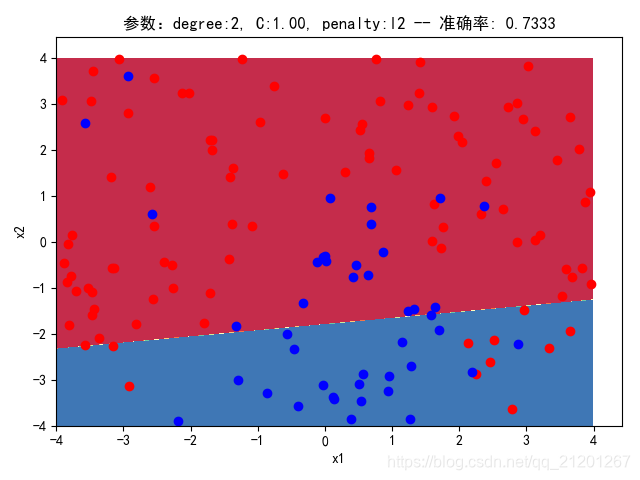 |  | 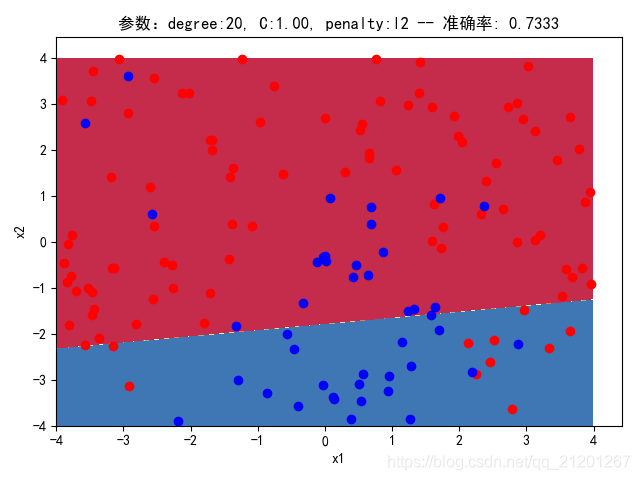 | 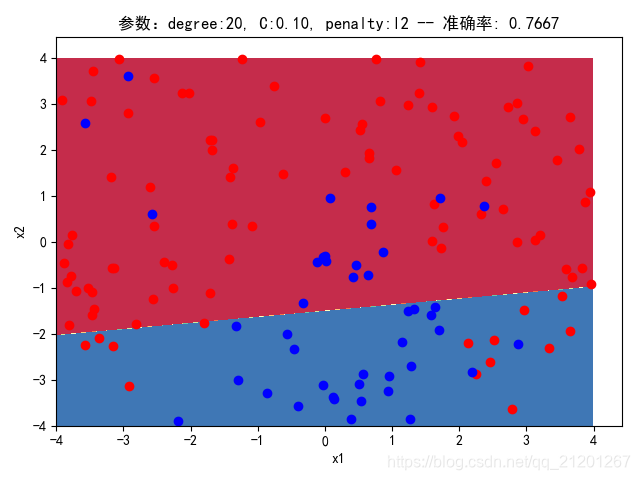 | 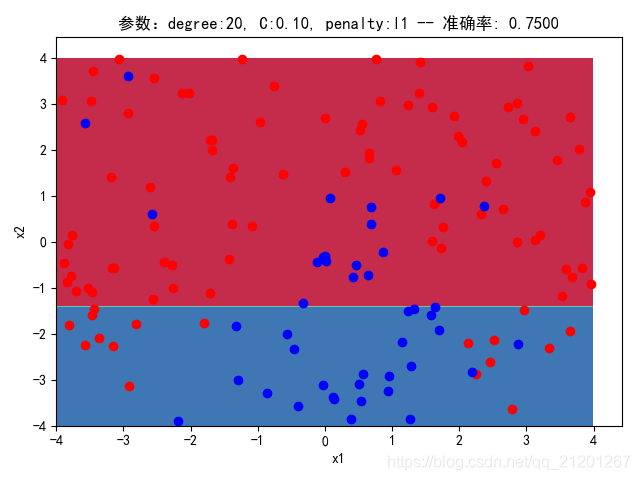 |
| 准确率 | 0.7333 | 0.7667 | 0.7333 | 0.7667 | 0.7500 | |
| 200组数据、seed(777) |  | 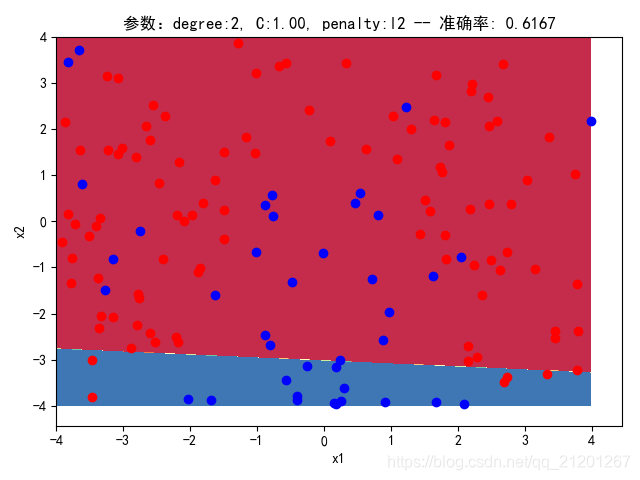 | 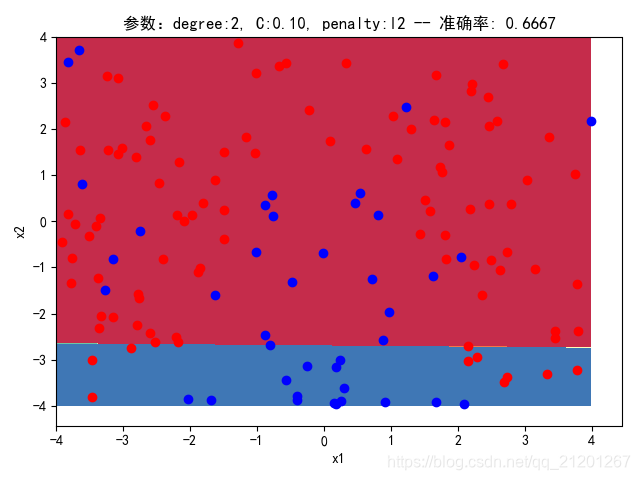 | 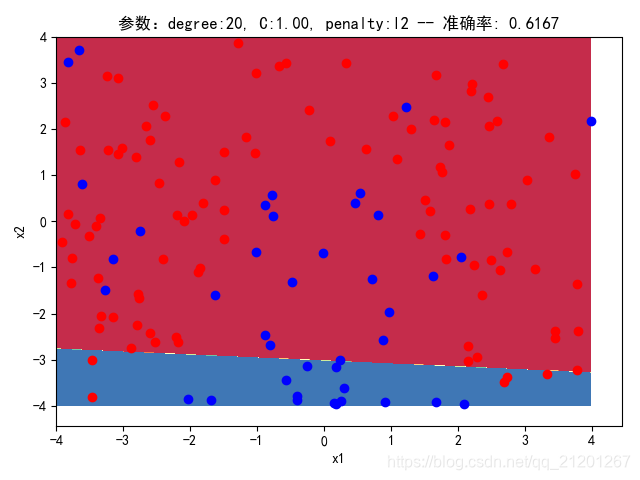 | 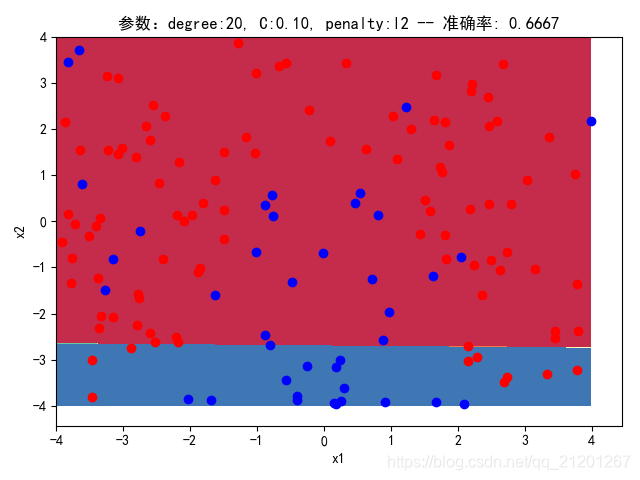 | 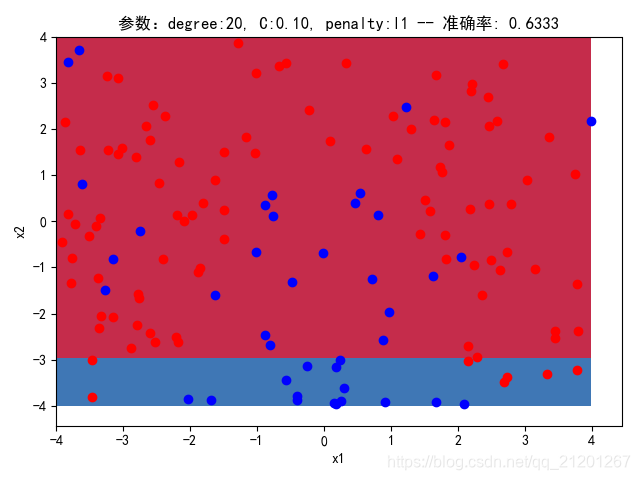 |
| 准确率 | 0.6167 | 0.6667 | 0.6167 | 0.6667 | 0.6333 | |
| 2000组数据 seed(520) | 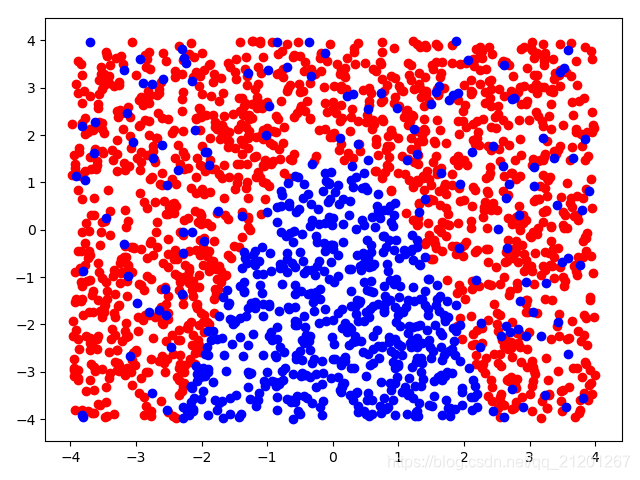 | 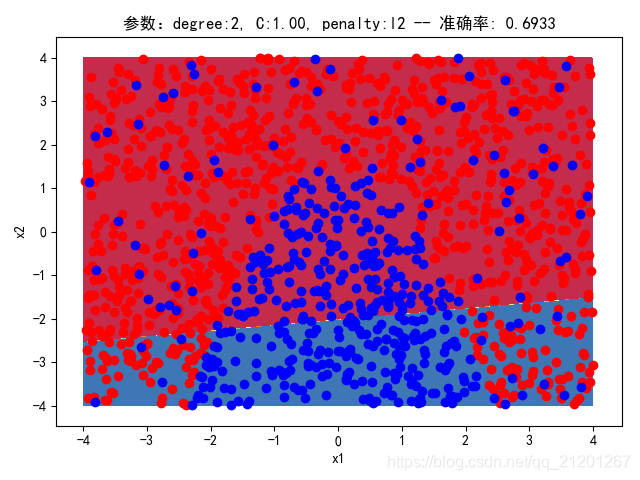 | 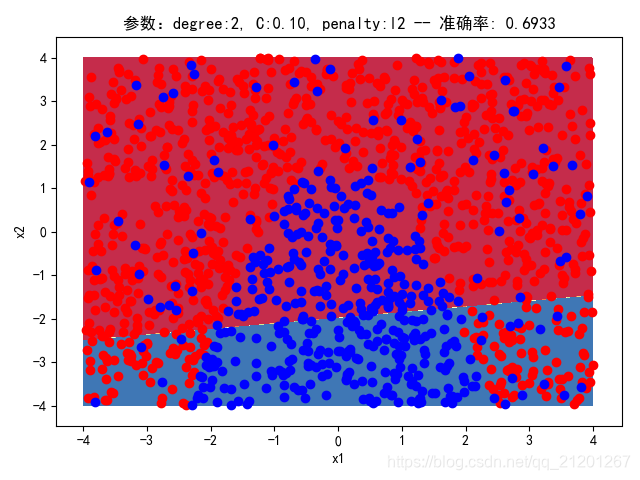 | 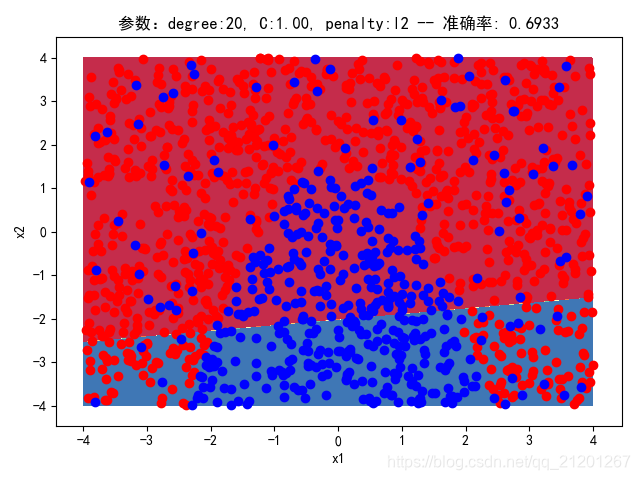 | 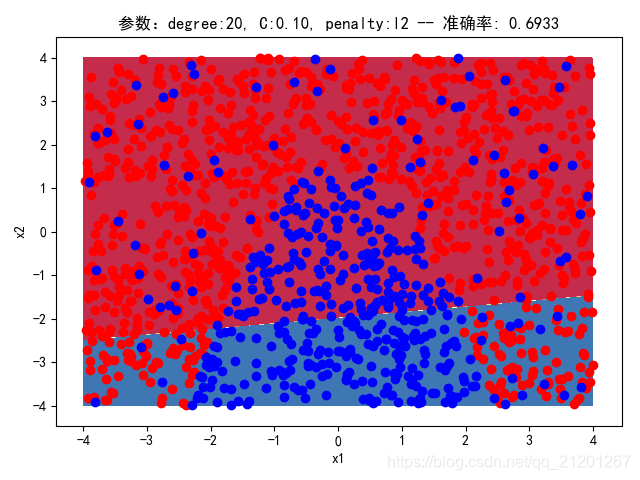 | 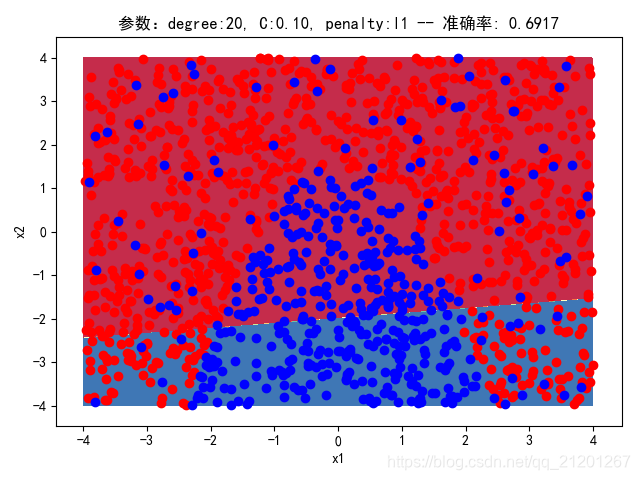 |
| 准确率 | 0.6933 | 0.6933 | 0.6933 | 0.6933 | 0.6917 | |
| 2000组数据 seed(777) | 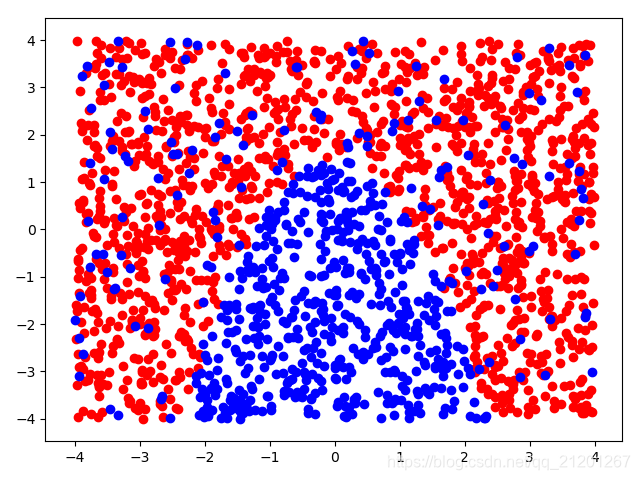 | 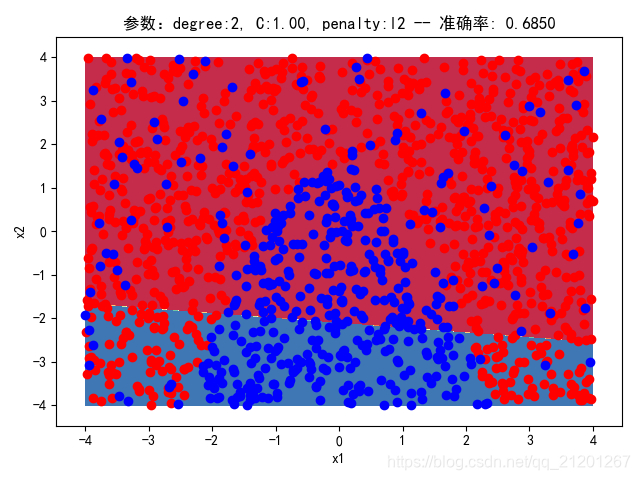 | 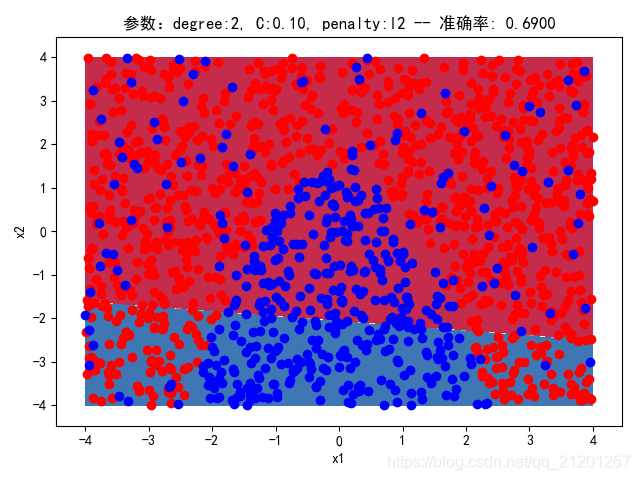 | 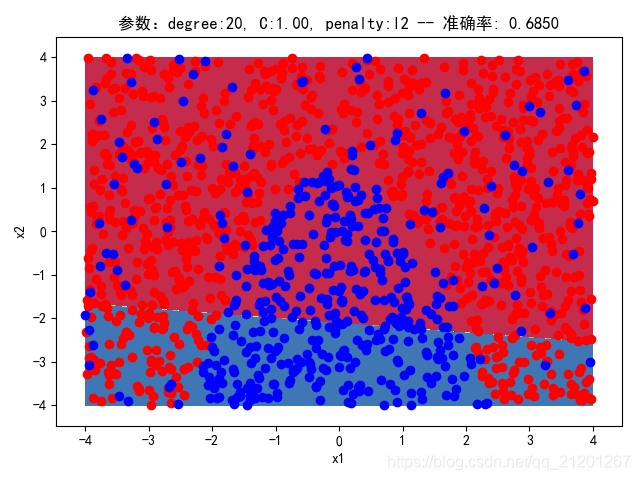 | 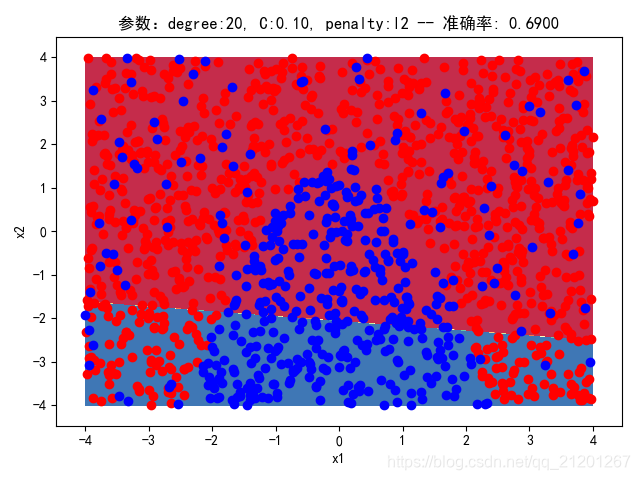 | 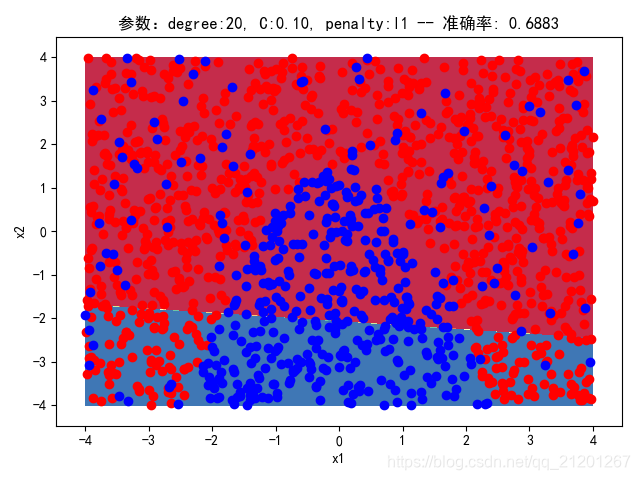 |
| 准确率 | 0.6850 | 0.6900 | 0.6850 | 0.6900 | 0.6883 |
- 没有多项式与归一化后,分类线表现为一条直线(没有多项式转换)
- 分类效果也都很差,调参效果很差
3.4 总结
- 训练数据分布对预测结果有直接影响,数据密集的地方预测较准,数据稀疏的地方,预测不准确(噪声,模型本身都有影响)
- 特征转换,有助于预测出更高阶的模型
- 归一化能够降低噪声的影响
- 加大数据规模一定程度上能够抗噪,提高模型准确率,重复区域高密度的数据一定程度以后,对模型预测也就失去了价值
4. 附
4.1 matplotlib.pyplot.contourf
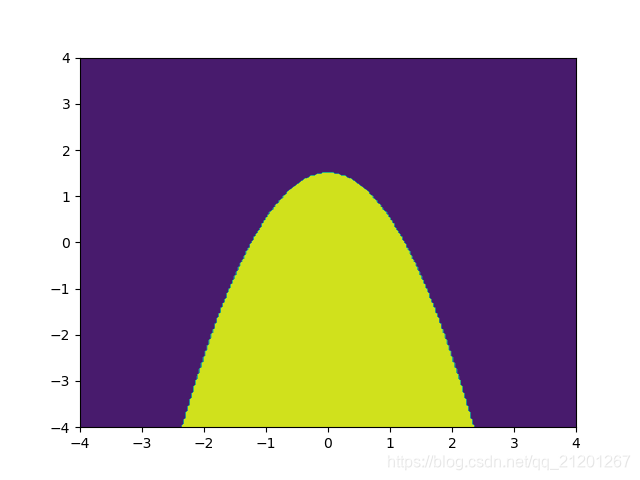
import numpy as npimport matplotlib.pyplot as plt # 计算x,y坐标对应的高度值def f(x, y): return x**2+y<1.5 # 生成x,y的数据n = 256x = np.linspace(-4, 4, n)y = np.linspace(-4, 4, n)# 把x,y数据生成mesh网格状的数据,在网格的基础上添加上高度值X, Y = np.meshgrid(x, y)# 填充等高线plt.contourf(X, Y, f(X, Y))# 显示图表plt.show()
画出 x**2+y = 1.5 的等高线如下
4.2 numpy 之 np.r_[a,b], np.c_[a,b]
np.r_np.c_用法参考下面:>>> aarray([[1, 2, 3], [7, 8, 9]])>>> barray([[4, 5, 6], [1, 2, 3]])>>> c=np.c_[a,b]>>> carray([[1, 2, 3, 4, 5, 6], [7, 8, 9, 1, 2, 3]])>>> c=np.r_[a,b]>>> carray([[1, 2, 3], [7, 8, 9], [4, 5, 6], [1, 2, 3]])>>> c=np.c_[a.ravel(),b.ravel()] # ravel()展平>>> carray([[1, 4], [2, 5], [3, 6], [7, 1], [8, 2], [9, 3]])
转载地址:https://michael.blog.csdn.net/article/details/104288855 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年05月06日 09时48分04秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
2021-05-18
2019-04-30
基础架构系列篇-NGINX部署VUE
2019-04-30
基础架构系列篇-系统centos7安装kafka
2019-04-30
在 Vue 中用 Axios 异步请求API
2019-04-30
Mysql 之主从复制
2019-04-30
【NLP学习笔记】中文分词(Word Segmentation,WS)
2019-04-30
对于时间复杂度的通俗理解
2019-04-30
如何输入多组数据并输出每组数据的和?
2019-04-30
行阶梯型矩阵
2019-04-30
JAVA学习笔记6 - 数组
2019-04-30
【学习笔记】Android Activity
2019-04-30
location区段
2019-04-30
linux内存的寻址方式
2019-04-30
how2heap-double free
2019-04-30
tf keras SimpleRNN源码解析
2019-04-30
MyBatisPlus简单入门(SpringBoot)
2019-04-30
xss-labs详解(上)1-10
2019-04-30
xss-labs详解(下)11-20
2019-04-30
攻防世界web进阶区ics-04详解
2019-04-30
Linux png转jpg (convert命令)
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311895816 位访客
访问时间: 2024-05-08 04:16:52
访问IP: 18.118.45.162
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版